 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamlining Biomedical Research with Specialized LLMs
Apr 15, 2025In this paper, we propose a novel system that integrates state-of-the-art, domain-specific large language models with advanced information retrieval techniques to deliver comprehensive and context-aware responses. Our approach facilitates seamless interaction among diverse components, enabling cross-validation of outputs to produce accurate, high-quality responses enriched with relevant data, images, tables, and other modalities. We demonstrate the system's capability to enhance response precision by leveraging a robust question-answering model, significantly improving the quality of dialogue generation. The system provides an accessible platform for real-time, high-fidelity interactions, allowing users to benefit from efficient human-computer interaction, precise retrieval, and simultaneous access to a wide range of literature and data. This dramatically improves the research efficiency of professionals in the biomedical and pharmaceutical domains and facilitates faster, more informed decision-making throughout the R\&D process. Furthermore, the system proposed in this paper is available at https://synapse-chat.patsnap.com.
Correctness Learning: Deductive Verification Guided Learning for Human-AI Collaboration
Mar 10, 2025Despite significant progress in AI and decision-making technologies in safety-critical fields, challenges remain in verifying the correctness of decision output schemes and verification-result driven design. We propose correctness learning (CL) to enhance human-AI collaboration integrating deductive verification methods and insights from historical high-quality schemes. The typical pattern hidden in historical high-quality schemes, such as change of task priorities in shared resources, provides critical guidance for intelligent agents in learning and decision-making. By utilizing deductive verification methods, we proposed patten-driven correctness learning (PDCL), formally modeling and reasoning the adaptive behaviors-or 'correctness pattern'-of system agents based on historical high-quality schemes, capturing the logical relationships embedded within these schemes. Using this logical information as guidance, we establish a correctness judgment and feedback mechanism to steer the intelligent decision model toward the 'correctness pattern' reflected in historical high-quality schemes. Extensive experiments across multiple working conditions and core parameters validate the framework's components and demonstrate its effectiveness in improving decision-making and resource optimization.
CLASH: Complementary Learning with Neural Architecture Search for Gait Recognition
Jul 04, 2024



Gait recognition, which aims at identifying individuals by their walking patterns, has achieved great success based on silhouette. The binary silhouette sequence encodes the walking pattern within the sparse boundary representation. Therefore, most pixels in the silhouette are under-sensitive to the walking pattern since the sparse boundary lacks dense spatial-temporal information, which is suitable to be represented with dense texture. To enhance the sensitivity to the walking pattern while maintaining the robustness of recognition, we present a Complementary Learning with neural Architecture Search (CLASH) framework, consisting of walking pattern sensitive gait descriptor named dense spatial-temporal field (DSTF) and neural architecture search based complementary learning (NCL). Specifically, DSTF transforms the representation from the sparse binary boundary into the dense distance-based texture, which is sensitive to the walking pattern at the pixel level. Further, NCL presents a task-specific search space for complementary learning, which mutually complements the sensitivity of DSTF and the robustness of the silhouette to represent the walking pattern effectively. Extensive experiments demonstrate the effectiveness of the proposed methods under both in-the-lab and in-the-wild scenarios. On CASIA-B, we achieve rank-1 accuracy of 98.8%, 96.5%, and 89.3% under three conditions. On OU-MVLP, we achieve rank-1 accuracy of 91.9%. Under the latest in-the-wild datasets, we outperform the latest silhouette-based methods by 16.3% and 19.7% on Gait3D and GREW, respectively.
PharmaGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jul 03, 2024



Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
PharmGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jun 26, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
Context Disentangling and Prototype Inheriting for Robust Visual Grounding
Dec 19, 2023



Visual grounding (VG) aims to locate a specific target in an image based on a given language query. The discriminative information from context is important for distinguishing the target from other objects, particularly for the targets that have the same category as others. However, most previous methods underestimate such information. Moreover, they are usually designed for the standard scene (without any novel object), which limits their generalization to the open-vocabulary scene. In this paper, we propose a novel framework with context disentangling and prototype inheriting for robust visual grounding to handle both scenes. Specifically, the context disentangling disentangles the referent and context features, which achieves better discrimination between them. The prototype inheriting inherits the prototypes discovered from the disentangled visual features by a prototype bank to fully utilize the seen data, especially for the open-vocabulary scene. The fused features, obtained by leveraging Hadamard product on disentangled linguistic and visual features of prototypes to avoid sharp adjusting the importance between the two types of features, are then attached with a special token and feed to a vision Transformer encoder for bounding box regression. Extensive experiments are conducted on both standard and open-vocabulary scenes. The performance comparisons indicate that our method outperforms the state-of-the-art methods in both scenarios. {The code is available at https://github.com/WayneTomas/TransCP.
Deep Semantic Multimodal Hashing Network for Scalable Multimedia Retrieval
Jan 09, 2019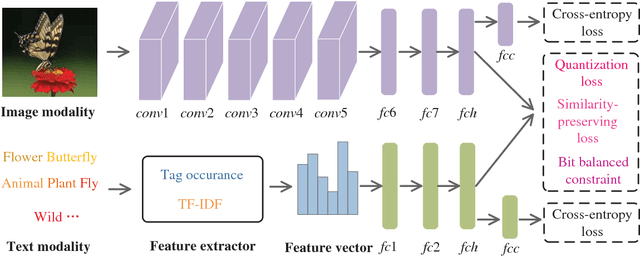
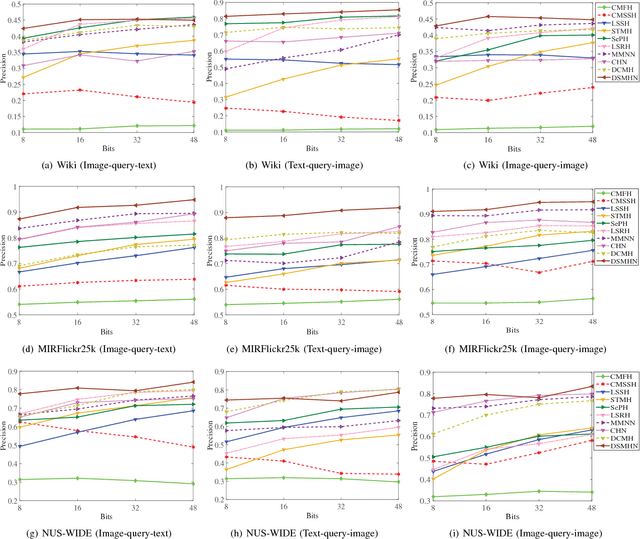
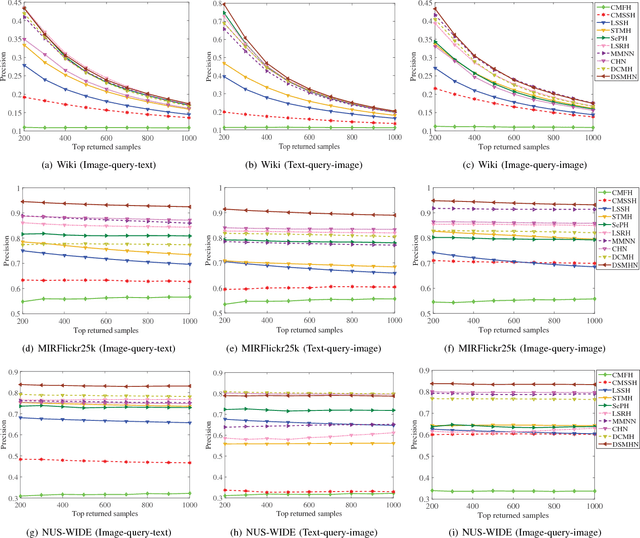
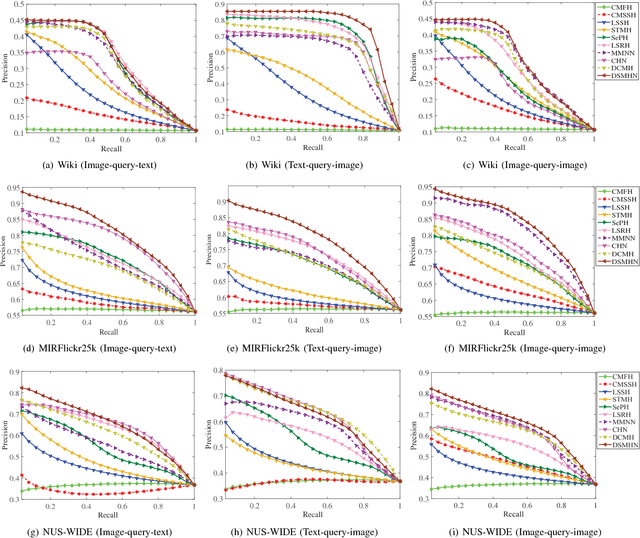
Hashing has been widely applied to multimodal retrieval on large-scale multimedia data due to its efficiency in computation and storage. Particularly, deep hashing has received unprecedented research attention in recent years, owing to its perfect retrieval performance. However, most of existing deep hashing methods learn binary hash codes by preserving the similarity relationship while without exploiting the semantic labels, which result in suboptimal binary codes. In this work, we propose a novel Deep Semantic Multimodal Hashing Network (DSMHN) for scalable multimodal retrieval. In DSMHN, two sets of modality-specific hash functions are jointly learned by explicitly preserving both the inter-modality similarities and the intra-modality semantic labels. Specifically, with the assumption that the learned hash codes should be optimal for task-specific classification, two stream networks are jointly trained to learn the hash functions by embedding the semantic labels on the resultant hash codes. Different from previous deep hashing methods, which are tied to some particular forms of loss functions, our deep hashing framework can be flexibly integrated with different types of loss functions. In addition, the bit balance property is investigated to generate binary codes with each bit having $50\%$ probability to be $1$ or $-1$. Moreover, a unified deep multimodal hashing framework is proposed to learn compact and high-quality hash codes by exploiting the feature representation learning, inter-modality similarity preserving learning, semantic label preserving learning and hash functions learning with bit balanced constraint simultaneously. We conduct extensive experiments for both unimodal and cross-modal retrieval tasks on three widely-used multimodal retrieval datasets. The experimental result demonstrates that DSMHN significantly outperforms state-of-the-art methods.
Deep Ordinal Hashing with Spatial Attention
May 07, 2018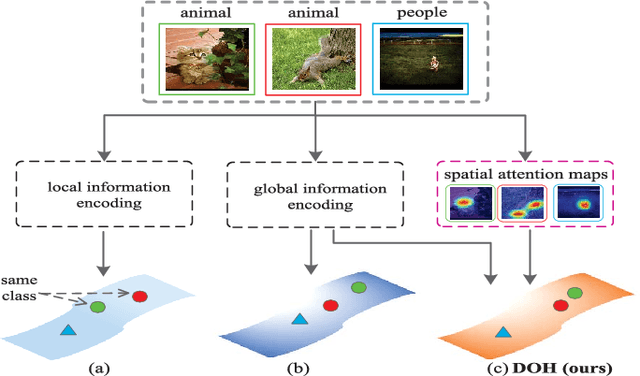
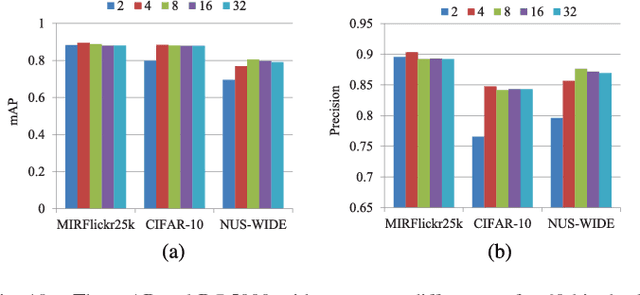
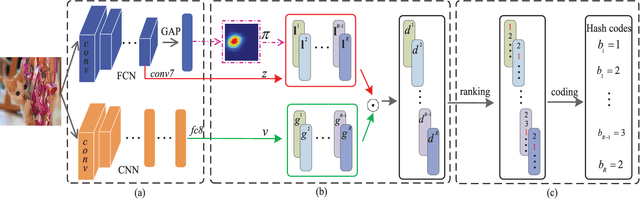
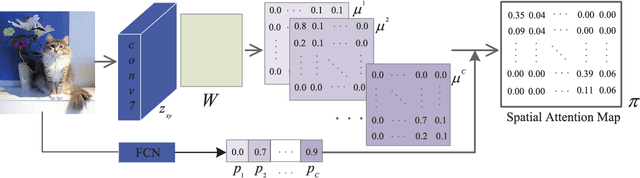
Hashing has attracted increasing research attentions in recent years due to its high efficiency of computation and storage in image retrieval. Recent works have demonstrated the superiority of simultaneous feature representations and hash functions learning with deep neural networks. However, most existing deep hashing methods directly learn the hash functions by encoding the global semantic information, while ignoring the local spatial information of images. The loss of local spatial structure makes the performance bottleneck of hash functions, therefore limiting its application for accurate similarity retrieval. In this work, we propose a novel Deep Ordinal Hashing (DOH) method, which learns ordinal representations by leveraging the ranking structure of feature space from both local and global views. In particular, to effectively build the ranking structure, we propose to learn the rank correlation space by exploiting the local spatial information from Fully Convolutional Network (FCN) and the global semantic information from the Convolutional Neural Network (CNN) simultaneously. More specifically, an effective spatial attention model is designed to capture the local spatial information by selectively learning well-specified locations closely related to target objects. In such hashing framework,the local spatial and global semantic nature of images are captured in an end-to-end ranking-to-hashing manner. Experimental results conducted on three widely-used datasets demonstrate that the proposed DOH method significantly outperforms the state-of-the-art hashing methods.