 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniForce: A Unified Latent Force Model for Robot Manipulation with Diverse Tactile Sensors
Feb 01, 2026Force sensing is essential for dexterous robot manipulation, but scaling force-aware policy learning is hindered by the heterogeneity of tactile sensors. Differences in sensing principles (e.g., optical vs. magnetic), form factors, and materials typically require sensor-specific data collection, calibration, and model training, thereby limiting generalisability. We propose UniForce, a novel unified tactile representation learning framework that learns a shared latent force space across diverse tactile sensors. UniForce reduces cross-sensor domain shift by jointly modeling inverse dynamics (image-to-force) and forward dynamics (force-to-image), constrained by force equilibrium and image reconstruction losses to produce force-grounded representations. To avoid reliance on expensive external force/torque (F/T) sensors, we exploit static equilibrium and collect force-paired data via direct sensor--object--sensor interactions, enabling cross-sensor alignment with contact force. The resulting universal tactile encoder can be plugged into downstream force-aware robot manipulation tasks with zero-shot transfer, without retraining or finetuning. Extensive experiments on heterogeneous tactile sensors including GelSight, TacTip, and uSkin, demonstrate consistent improvements in force estimation over prior methods, and enable effective cross-sensor coordination in Vision-Tactile-Language-Action (VTLA) models for a robotic wiping task. Code and datasets will be released.
General Force Sensation for Tactile Robot
Mar 02, 2025



Robotic tactile sensors, including vision-based and taxel-based sensors, enable agile manipulation and safe human-robot interaction through force sensation. However, variations in structural configurations, measured signals, and material properties create domain gaps that limit the transferability of learned force sensation across different tactile sensors. Here, we introduce GenForce, a general framework for achieving transferable force sensation across both homogeneous and heterogeneous tactile sensors in robotic systems. By unifying tactile signals into marker-based binary tactile images, GenForce enables the transfer of existing force labels to arbitrary target sensors using a marker-to-marker translation technique with a few paired data. This process equips uncalibrated tactile sensors with force prediction capabilities through spatiotemporal force prediction models trained on the transferred data. Extensive experimental results validate GenForce's generalizability, accuracy, and robustness across sensors with diverse marker patterns, structural designs, material properties, and sensing principles. The framework significantly reduces the need for costly and labor-intensive labeled data collection, enabling the rapid deployment of multiple tactile sensors on robotic hands requiring force sensing capabilities.
Haptic Stiffness Perception Using Hand Exoskeletons in Tactile Robotic Telemanipulation
Dec 03, 2024Robotic telemanipulation - the human-guided manipulation of remote objects - plays a pivotal role in several applications, from healthcare to operations in harsh environments. While visual feedback from cameras can provide valuable information to the human operator, haptic feedback is essential for accessing specific object properties that are difficult to be perceived by vision, such as stiffness. For the first time, we present a participant study demonstrating that operators can perceive the stiffness of remote objects during real-world telemanipulation with a dexterous robotic hand, when haptic feedback is generated from tactile sensing fingertips. Participants were tasked with squeezing soft objects by teleoperating a robotic hand, using two methods of haptic feedback: one based solely on the measured contact force, while the second also includes the squeezing displacement between the leader and follower devices. Our results demonstrate that operators are indeed capable of discriminating objects of different stiffness, relying on haptic feedback alone and without any visual feedback. Additionally, our findings suggest that the displacement feedback component may enhance discrimination with objects of similar stiffness.
Leveraging Tactile Sensing to Render both Haptic Feedback and Virtual Reality 3D Object Reconstruction in Robotic Telemanipulation
Dec 03, 2024



Dexterous robotic manipulator teleoperation is widely used in many applications, either where it is convenient to keep the human inside the control loop, or to train advanced robot agents. So far, this technology has been used in combination with camera systems with remarkable success. On the other hand, only a limited number of studies have focused on leveraging haptic feedback from tactile sensors in contexts where camera-based systems fail, such as due to self-occlusions or poor light conditions like smoke. This study demonstrates the feasibility of precise pick-and-place teleoperation without cameras by leveraging tactile-based 3D object reconstruction in VR and providing haptic feedback to a blindfolded user. Our preliminary results show that integrating these technologies enables the successful completion of telemanipulation tasks previously dependent on cameras, paving the way for more complex future applications.
DexSkills: Skill Segmentation Using Haptic Data for Learning Autonomous Long-Horizon Robotic Manipulation Tasks
May 06, 2024



Effective execution of long-horizon tasks with dexterous robotic hands remains a significant challenge in real-world problems. While learning from human demonstrations have shown encouraging results, they require extensive data collection for training. Hence, decomposing long-horizon tasks into reusable primitive skills is a more efficient approach. To achieve so, we developed DexSkills, a novel supervised learning framework that addresses long-horizon dexterous manipulation tasks using primitive skills. DexSkills is trained to recognize and replicate a select set of skills using human demonstration data, which can then segment a demonstrated long-horizon dexterous manipulation task into a sequence of primitive skills to achieve one-shot execution by the robot directly. Significantly, DexSkills operates solely on proprioceptive and tactile data, i.e., haptic data. Our real-world robotic experiments show that DexSkills can accurately segment skills, thereby enabling autonomous robot execution of a diverse range of tasks.
Finding safe 3D robot grasps through efficient haptic exploration with unscented Bayesian optimization and collision penalty
Feb 10, 2024Robust grasping is a major, and still unsolved, problem in robotics. Information about the 3D shape of an object can be obtained either from prior knowledge (e.g., accurate models of known objects or approximate models of familiar objects) or real-time sensing (e.g., partial point clouds of unknown objects) and can be used to identify good potential grasps. However, due to modeling and sensing inaccuracies, local exploration is often needed to refine such grasps and successfully apply them in the real world. The recently proposed unscented Bayesian optimization technique can make such exploration safer by selecting grasps that are robust to uncertainty in the input space (e.g., inaccuracies in the grasp execution). Extending our previous work on 2D optimization, in this paper we propose a 3D haptic exploration strategy that combines unscented Bayesian optimization with a novel collision penalty heuristic to find safe grasps in a very efficient way: while by augmenting the search-space to 3D we are able to find better grasps, the collision penalty heuristic allows us to do so without increasing the number of exploration steps.
* 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Robotics for poultry farming: challenges and opportunities
Nov 09, 2023

Poultry farming plays a pivotal role in addressing human food demand. Robots are emerging as promising tools in poultry farming, with the potential to address sustainability issues while meeting the increasing production needs and demand for animal welfare. This review aims to identify the current advancements, limitations and future directions of development for robotics in poultry farming by examining existing challenges, solutions and innovative research, including robot-animal interactions. We cover the application of robots in different areas, from environmental monitoring to disease control, floor eggs collection and animal welfare. Robots not only demonstrate effective implementation on farms but also hold potential for ethological research on collective and social behaviour, which can in turn drive a better integration in industrial farming, with improved productivity and enhanced animal welfare.
World Models and Predictive Coding for Cognitive and Developmental Robotics: Frontiers and Challenges
Jan 14, 2023Creating autonomous robots that can actively explore the environment, acquire knowledge and learn skills continuously is the ultimate achievement envisioned in cognitive and developmental robotics. Their learning processes should be based on interactions with their physical and social world in the manner of human learning and cognitive development. Based on this context, in this paper, we focus on the two concepts of world models and predictive coding. Recently, world models have attracted renewed attention as a topic of considerable interest in artificial intelligence. Cognitive systems learn world models to better predict future sensory observations and optimize their policies, i.e., controllers. Alternatively, in neuroscience, predictive coding proposes that the brain continuously predicts its inputs and adapts to model its own dynamics and control behavior in its environment. Both ideas may be considered as underpinning the cognitive development of robots and humans capable of continual or lifelong learning. Although many studies have been conducted on predictive coding in cognitive robotics and neurorobotics, the relationship between world model-based approaches in AI and predictive coding in robotics has rarely been discussed. Therefore, in this paper, we clarify the definitions, relationships, and status of current research on these topics, as well as missing pieces of world models and predictive coding in conjunction with crucially related concepts such as the free-energy principle and active inference in the context of cognitive and developmental robotics. Furthermore, we outline the frontiers and challenges involved in world models and predictive coding toward the further integration of AI and robotics, as well as the creation of robots with real cognitive and developmental capabilities in the future.
Visuo-Haptic Object Perception for Robots: An Overview
Mar 22, 2022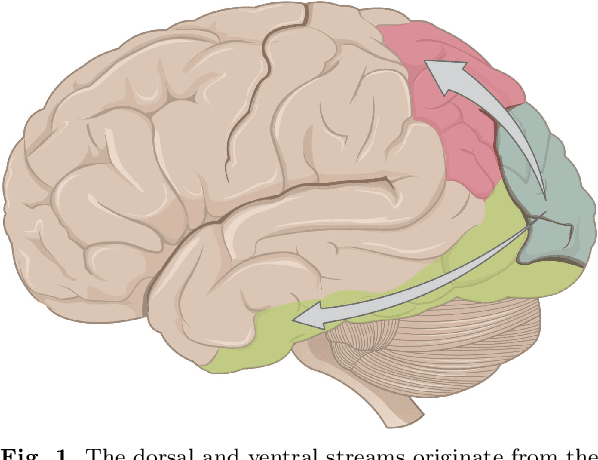
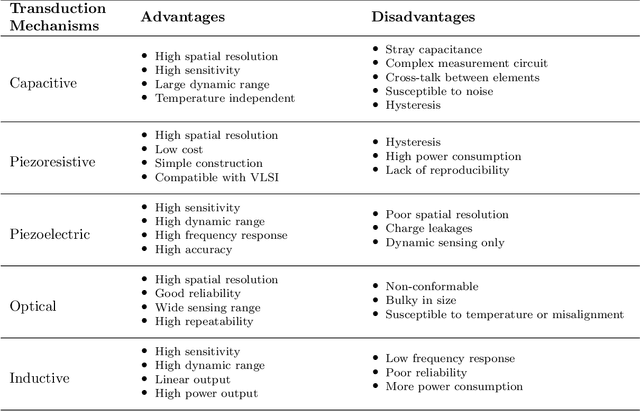
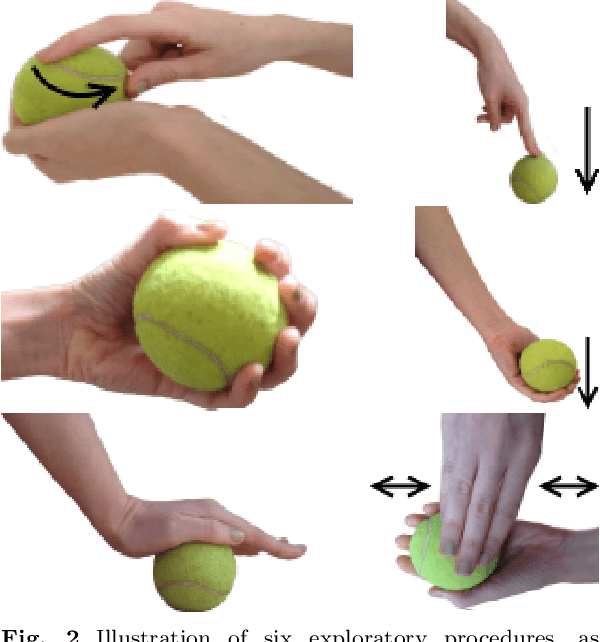
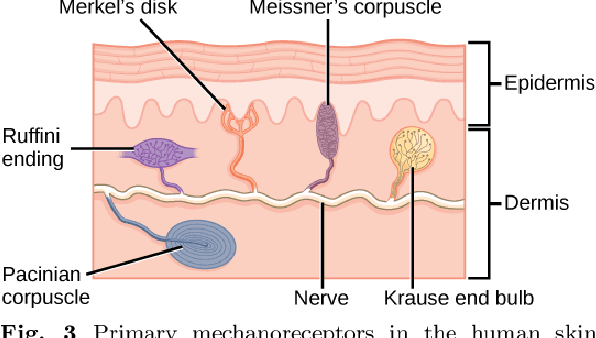
This article summarizes the current state of multimodal object perception for robotic applications. It covers aspects of biological inspiration, sensor technologies, data sets, and sensory data processing for object recognition and grasping. Firstly, the biological basis of multimodal object perception is outlined. Then the sensing technologies and data collection strategies are discussed. Next, an introduction to the main computational aspects is presented, highlighting a few representative articles for each main application area, including object recognition, object manipulation and grasping, texture recognition, and transfer learning. Finally, informed by the current advancements in each area, this article outlines promising new research directions.
Robust and fast generation of top and side grasps for unknown objects
Jul 18, 2019
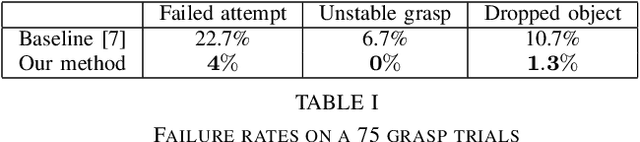
In this work, we present a geometry-based grasping algorithm that is capable of efficiently generating both top and side grasps for unknown objects, using a single view RGB-D camera, and of selecting the most promising one. We demonstrate the effectiveness of our approach on a picking scenario on a real robot platform. Our approach has shown to be more reliable than another recent geometry-based method considered as baseline [7] in terms of grasp stability, by increasing the successful grasp attempts by a factor of six.
* Extended abstract