 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiZIP: An Auto-Regressive Compression Framework for LiDAR Point Clouds
Mar 24, 2026The massive volume of data generated by LiDAR sensors in autonomous vehicles creates a bottleneck for real-time processing and vehicle-to-everything (V2X) transmission. Existing lossless compression methods often force a trade-off: industry standard algorithms (e.g., LASzip) lack adaptability, while deep learning approaches suffer from prohibitive computational costs. This paper proposes LiZIP, a lightweight, near-lossless zero-drift compression framework based on neural predictive coding. By utilizing a compact Multi-Layer Perceptron (MLP) to predict point coordinates from local context, LiZIP efficiently encodes only the sparse residuals. We evaluate LiZIP on the NuScenes and Argoverse datasets, benchmarking against GZip, LASzip, and Google Draco (configured with 24-bit quantization to serve as a high-precision geometric baseline). Results demonstrate that LiZIP consistently achieves superior compression ratios across varying environments. The proposed system achieves a 7.5%-14.8% reduction in file size compared to the industry-standard LASzip and outperforms Google Draco by 8.8%-11.3% across diverse datasets. Furthermore, the system demonstrates generalization capabilities on the unseen Argoverse dataset without retraining. Against the general purpose GZip algorithm, LiZIP achieves a reduction of 38%-48%. This efficiency offers a distinct advantage for bandwidth constrained V2X applications and large scale cloud archival.
Robot Grasping and Manipulation: A Prospective
Mar 14, 2023``A simple handshake would give them away''. This is how Anthony Hopkins' fictional character, Dr Robert Ford, summarises a particular flaw of the 2016 science-fiction \emph{Westworld}'s hosts. In the storyline, Westworld is a futuristic theme park and the hosts are autonomous robots engineered to be indistinguishable from the human guests, except for their hands that have not been perfected yet. In another classic science-fiction saga, scientists unlock the secrets of full synthetic intelligence, Skynet, by reverse engineering a futuristic hand. In both storylines, reality inspires fiction on one crucial point: designing hands and reproducing robust and reliable manipulation actions is one of the biggest challenges in robotics. Solving this problem would lead us to a new, improved era of autonomy. A century ago, the third industrial revolution brought robots into the assembly lines, changing our way of working forever. The next revolution has already started by bringing us artificial intelligence (AI) assistants, enhancing our quality of life in our jobs and everyday lives--even combating worldwide pandemics.
Toward a Framework for Adaptive ImpedancenControl of an Upper-limb Prosthesis
Sep 11, 2022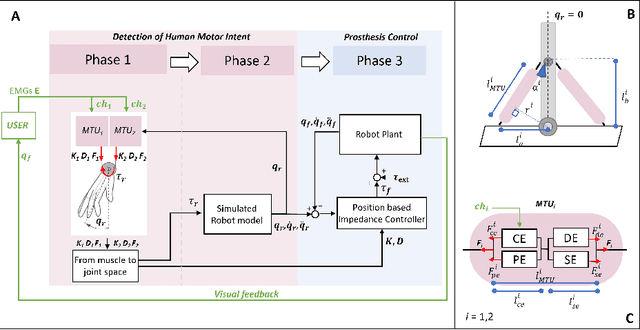
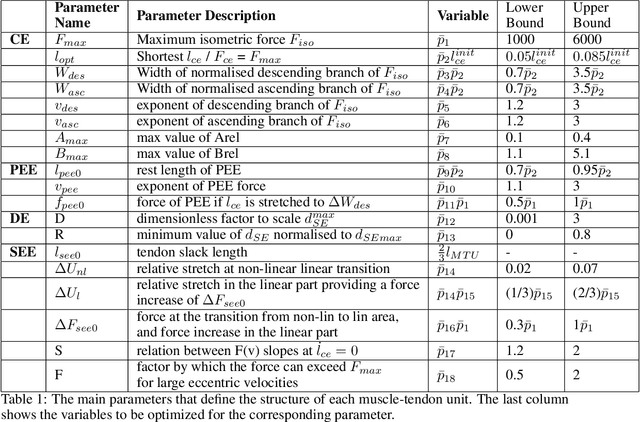
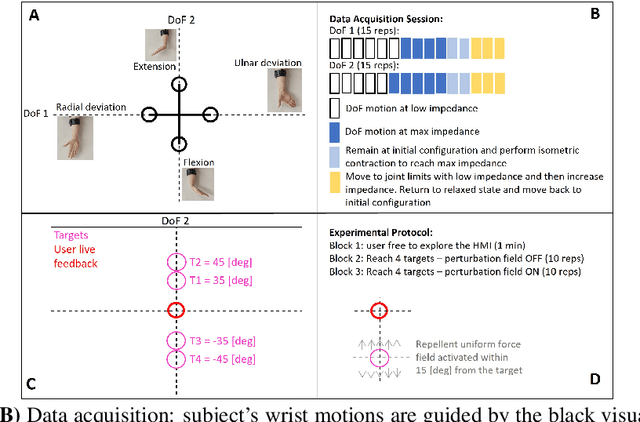
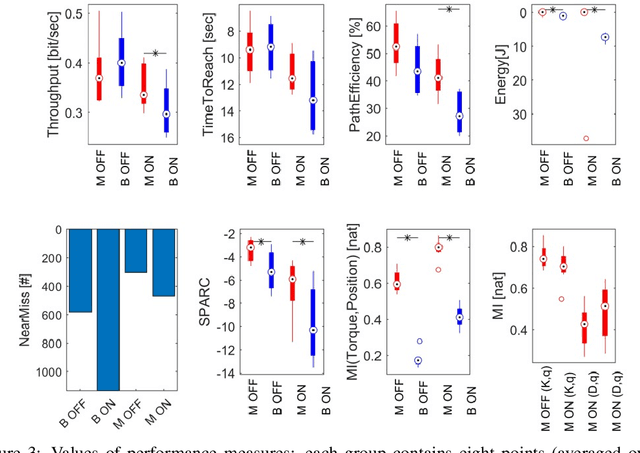
This paper describes a novel framework for a human-machine interface that can be used to control an upper-limb prosthesis. The objective is to estimate the human's motor intent from noisy surface electromyography signals and to execute the motor intent on the prosthesis (i.e., the robot) even in the presence of previously unseen perturbations. The framework includes muscle-tendon models for each degree of freedom, a method for learning the parameter values of models used to estimate the user's motor intent, and a variable impedance controller that uses the stiffness and damping values obtained from the muscle models to adapt the prosthesis' motion trajectory and dynamics. We experimentally evaluate our framework in the context of able-bodied humans using a simulated version of the human-machine interface to perform reaching tasks that primarily actuate one degree of freedom in the wrist, and consider external perturbations in the form of a uniform force field that pushes the wrist away from the target. We demonstrate that our framework provides the desired adaptive performance, and substantially improves performance in comparison with a data-driven baseline.
One-shot Learning for Autonomous Aerial Manipulation
Jun 03, 2022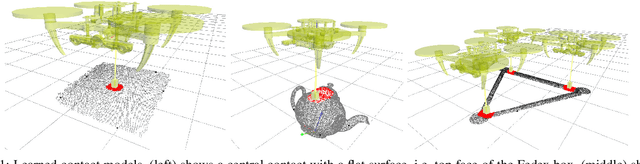
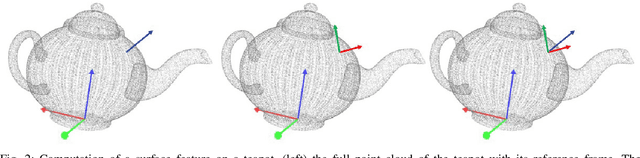
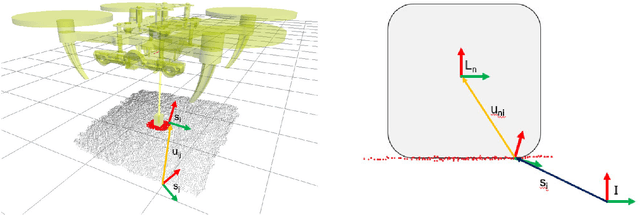
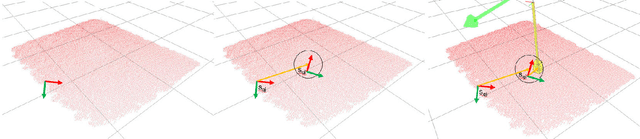
This paper is concerned with learning transferable contact models for aerial manipulation tasks. We investigate a contact-based approach for enabling unmanned aerial vehicles with cable-suspended passive grippers to compute the attach points on novel payloads for aerial transportation. This is the first time that the problem of autonomously generating contact points for such tasks has been investigated. Our approach builds on the underpinning idea that we can learn a probability density of contacts over objects' surfaces from a single demonstration. We enhance this formulation for encoding aerial transportation tasks while maintaining the one-shot learning paradigm without handcrafting task-dependent features or employing ad-hoc heuristics; the only prior is extrapolated directly from a single demonstration. Our models only rely on the geometrical properties of the payloads computed from a point cloud, and they are robust to partial views. The effectiveness of our approach is evaluated in simulation, in which one or three quadropters are requested to transport previously unseen payloads along a desired trajectory. The contact points and the quadroptors configurations are computed on-the-fly for each test by our apporach and compared with a baseline method, a modified grasp learning algorithm from the literature. Empirical experiments show that the contacts generated by our approach yield a better controllability of the payload for a transportation task. We conclude this paper with a discussion on the strengths and limitations of the presented idea, and our suggested future research directions.
Multi-Hypothesis Scan Matching through Clustering
Jan 19, 2022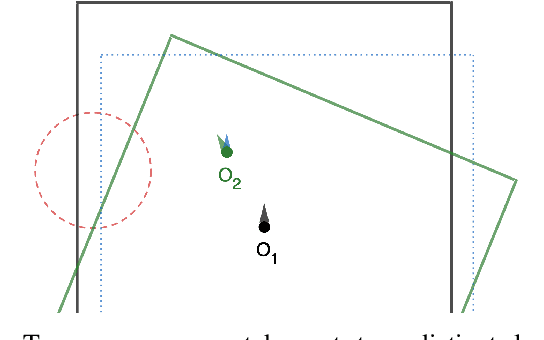
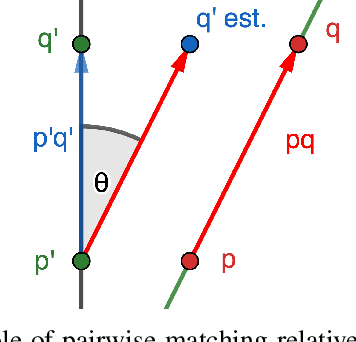
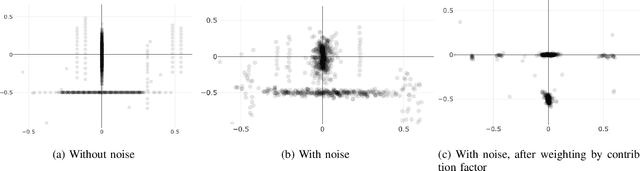
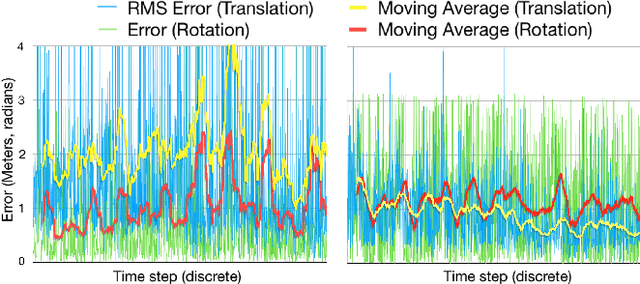
Graph-SLAM is a well-established algorithm for constructing a topological map of the environment while simultaneously attempting the localisation of the robot. It relies on scan matching algorithms to align noisy observations along robot's movements to compute an estimate of the current robot's location. We propose a fundamentally different approach to scan matching tasks to improve the estimation of roto-translation displacements and therefore the performance of the full SLAM algorithm. A Monte-Carlo approach is used to generate weighted hypotheses of the geometrical displacement between two scans, and then we cluster these hypotheses to compute the displacement that results in the best alignment. To cope with clusterization on roto-translations, we propose a novel clustering approach that robustly extends Gaussian Mean-Shift to orientations by factorizing the kernel density over the roto-translation components. We demonstrate the effectiveness of our method in an extensive set of experiments using both synthetic data and the Intel Research Lab's benchmarking datasets. The results confirms that our approach has superior performance in terms of matching accuracy and runtime computation than the state-of-the-art iterative point-based scan matching algorithms.
Dyna-T: Dyna-Q and Upper Confidence Bounds Applied to Trees
Jan 19, 2022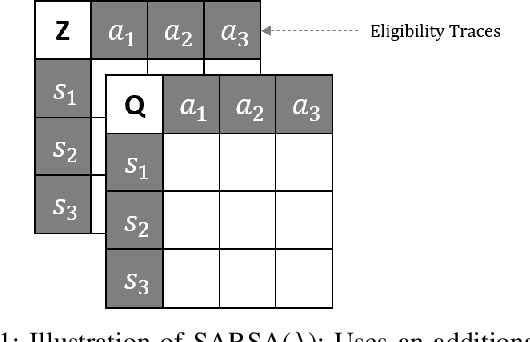
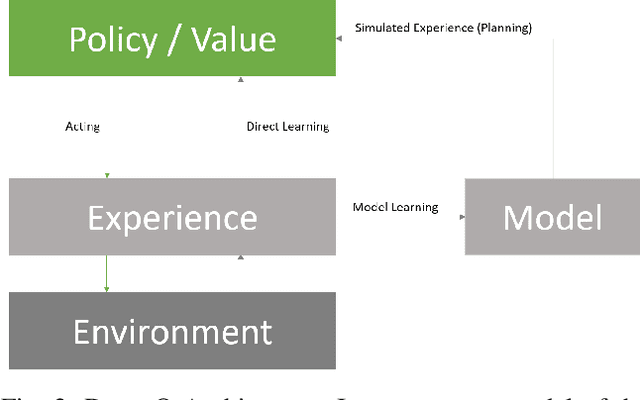
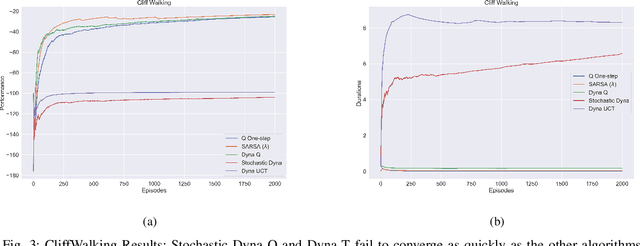
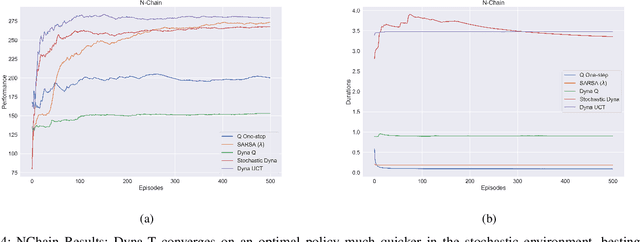
In this work we present a preliminary investigation of a novel algorithm called Dyna-T. In reinforcement learning (RL) a planning agent has its own representation of the environment as a model. To discover an optimal policy to interact with the environment, the agent collects experience in a trial and error fashion. Experience can be used for learning a better model or improve directly the value function and policy. Typically separated, Dyna-Q is an hybrid approach which, at each iteration, exploits the real experience to update the model as well as the value function, while planning its action using simulated data from its model. However, the planning process is computationally expensive and strongly depends on the dimensionality of the state-action space. We propose to build a Upper Confidence Tree (UCT) on the simulated experience and search for the best action to be selected during the on-line learning process. We prove the effectiveness of our proposed method on a set of preliminary tests on three testbed environments from Open AI. In contrast to Dyna-Q, Dyna-T outperforms state-of-the-art RL agents in the stochastic environments by choosing a more robust action selection strategy.
Direct Mutation and Crossover in Genetic Algorithms Applied to Reinforcement Learning Tasks
Jan 19, 2022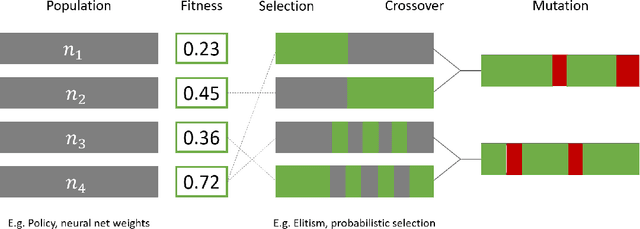
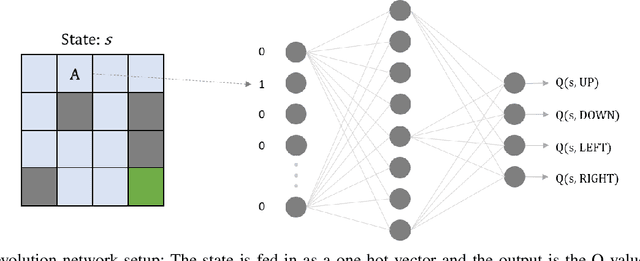
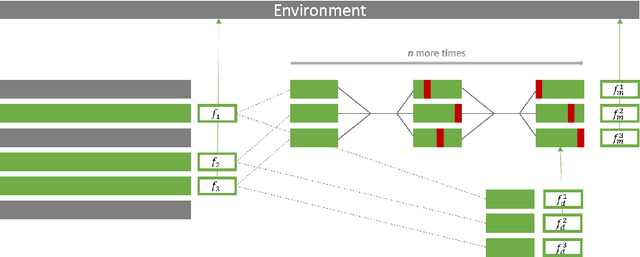
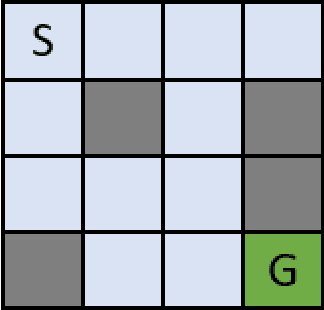
Neuroevolution has recently been shown to be quite competitive in reinforcement learning (RL) settings, and is able to alleviate some of the drawbacks of gradient-based approaches. This paper will focus on applying neuroevolution using a simple genetic algorithm (GA) to find the weights of a neural network that produce optimally behaving agents. In addition, we present two novel modifications that improve the data efficiency and speed of convergence when compared to the initial implementation. The modifications are evaluated on the FrozenLake environment provided by OpenAI gym and prove to be significantly better than the baseline approach.
Underwater Object Classification and Detection: first results and open challenges
Jan 04, 2022

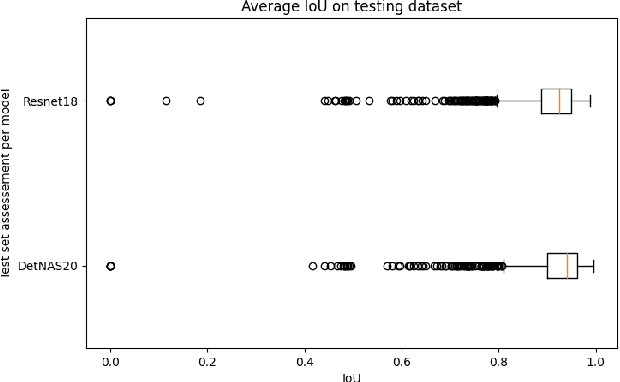
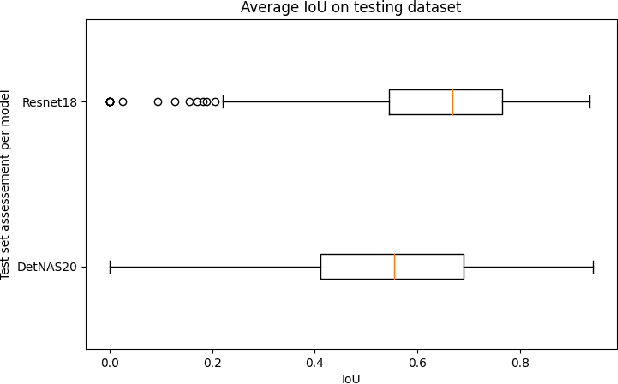
This work reviews the problem of object detection in underwater environments. We analyse and quantify the shortcomings of conventional state-of-the-art (SOTA) algorithms in the computer vision community when applied to this challenging environment, as well as providing insights and general guidelines for future research efforts. First, we assessed if pretraining with the conventional ImageNet is beneficial when the object detector needs to be applied to environments that may be characterised by a different feature distribution. We then investigate whether two-stage detectors yields to better performance with respect to single-stage detectors, in terms of accuracy, intersection of union (IoU), floating operation per second (FLOPS), and inference time. Finally, we assessed the generalisation capability of each model to a lower quality dataset to simulate performance on a real scenario, in which harsher conditions ought to be expected. Our experimental results provide evidence that underwater object detection requires searching for "ad-hoc" architectures than merely training SOTA architectures on new data, and that pretraining is not beneficial.
Learning Transferable Push Manipulation Skills in Novel Contexts
Jul 29, 2020
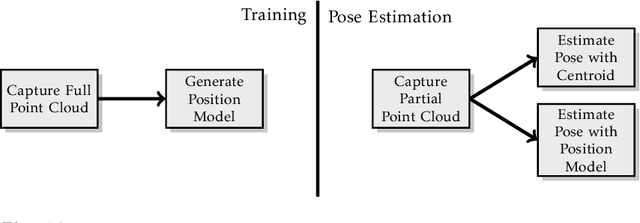
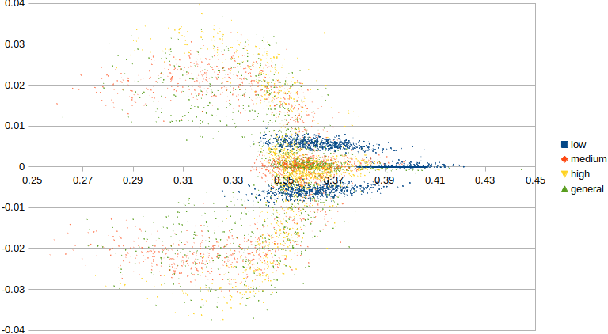
This paper is concerned with learning transferable forward models for push manipulation that can be applying to novel contexts and how to improve the quality of prediction when critical information is available. We propose to learn a parametric internal model for push interactions that, similar for humans, enables a robot to predict the outcome of a physical interaction even in novel contexts. Given a desired push action, humans are capable to identify where to place their finger on a new object so to produce a predictable motion of the object. We achieve the same behaviour by factorising the learning into two parts. First, we learn a set of local contact models to represent the geometrical relations between the robot pusher, the object, and the environment. Then we learn a set of parametric local motion models to predict how these contacts change throughout a push. The set of contact and motion models represent our internal model. By adjusting the shapes of the distributions over the physical parameters, we modify the internal model's response. Uniform distributions yield to coarse estimates when no information is available about the novel context (i.e. unbiased predictor). A more accurate predictor can be learned for a specific environment/object pair (e.g. low friction/high mass), i.e. biased predictor. The effectiveness of our approach is shown in a simulated environment in which a Pioneer 3-DX robot needs to predict a push outcome for a novel object, and we provide a proof of concept on a real robot. We train on 2 objects (a cube and a cylinder) for a total of 24,000 pushes in various conditions, and test on 6 objects encompassing a variety of shapes, sizes, and physical parameters for a total of 14,400 predicted push outcomes. Our results show that both biased and unbiased predictors can reliably produce predictions in line with the outcomes of a carefully tuned physics simulator.
Tatistical Context-Dependent Units Boundary Correction for Corpus-based Unit-Selection Text-to-Speech
Mar 05, 2020



In this study, we present an innovative technique for speaker adaptation in order to improve the accuracy of segmentation with application to unit-selection Text-To-Speech (TTS) systems. Unlike conventional techniques for speaker adaptation, which attempt to improve the accuracy of the segmentation using acoustic models that are more robust in the face of the speaker's characteristics, we aim to use only context dependent characteristics extrapolated with linguistic analysis techniques. In simple terms, we use the intuitive idea that context dependent information is tightly correlated with the related acoustic waveform. We propose a statistical model, which predicts correcting values to reduce the systematic error produced by a state-of-the-art Hidden Markov Model (HMM) based speech segmentation. Our approach consists of two phases: (1) identifying context-dependent phonetic unit classes (for instance, the class which identifies vowels as being the nucleus of monosyllabic words); and (2) building a regression model that associates the mean error value made by the ASR during the segmentation of a single speaker corpus to each class. The success of the approach is evaluated by comparing the corrected boundaries of units and the state-of-the-art HHM segmentation against a reference alignment, which is supposed to be the optimal solution. In conclusion, our work supplies a first analysis of a model sensitive to speaker-dependent characteristics, robust to defective and noisy information, and a very simple implementation which could be utilized as an alternative to either more expensive speaker-adaptation systems or of numerous manual correction sessions.
* isbn:978-88-7870-619-4