 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Discrete and Backpropagation: Straight-Through and Beyond
Apr 17, 2023Backpropagation, the cornerstone of deep learning, is limited to computing gradients solely for continuous variables. This limitation hinders various research on problems involving discrete latent variables. To address this issue, we propose a novel approach for approximating the gradient of parameters involved in generating discrete latent variables. First, we examine the widely used Straight-Through (ST) heuristic and demonstrate that it works as a first-order approximation of the gradient. Guided by our findings, we propose a novel method called ReinMax, which integrates Heun's Method, a second-order numerical method for solving ODEs, to approximate the gradient. Our method achieves second-order accuracy without requiring Hessian or other second-order derivatives. We conduct experiments on structured output prediction and unsupervised generative modeling tasks. Our results show that \ours brings consistent improvements over the state of the art, including ST and Straight-Through Gumbel-Softmax. Implementations are released at https://github.com/microsoft/ReinMax.
SoTeacher: A Student-oriented Teacher Network Training Framework for Knowledge Distillation
Jun 14, 2022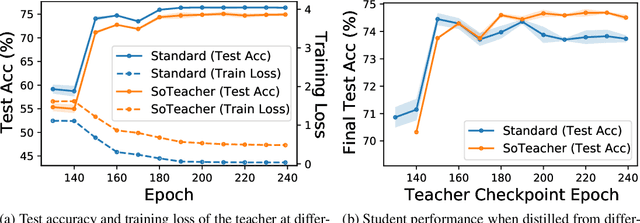
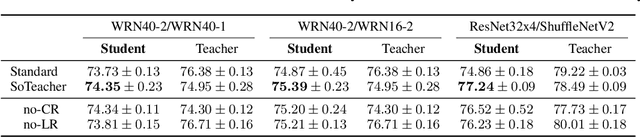
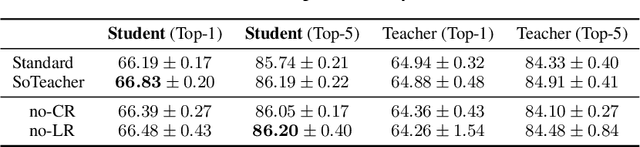
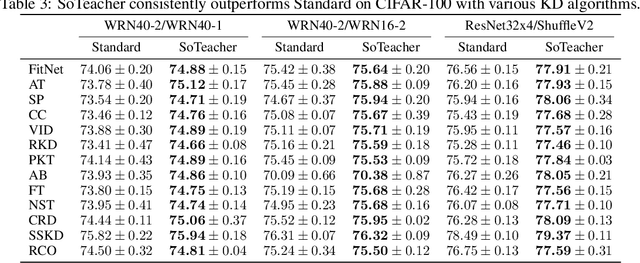
How to train an ideal teacher for knowledge distillation is still an open problem. It has been widely observed that a teacher minimizing the empirical risk not necessarily yields the best performing student, suggesting a fundamental discrepancy between the common practice in teacher network training and the distillation objective. To fill this gap, we propose a novel student-oriented teacher network training framework SoTeacher, inspired by recent findings that student performance hinges on teacher's capability to approximate the true label distribution of training samples. We theoretically established that (1) the empirical risk minimizer with proper scoring rules as loss function can provably approximate the true label distribution of training data if the hypothesis function is locally Lipschitz continuous around training samples; and (2) when data augmentation is employed for training, an additional constraint is required that the minimizer has to produce consistent predictions across augmented views of the same training input. In light of our theory, SoTeacher renovates the empirical risk minimization by incorporating Lipschitz regularization and consistency regularization. It is worth mentioning that SoTeacher is applicable to almost all teacher-student architecture pairs, requires no prior knowledge of the student upon teacher's training, and induces almost no computation overhead. Experiments on two benchmark datasets confirm that SoTeacher can improve student performance significantly and consistently across various knowledge distillation algorithms and teacher-student pairs.
PILED: An Identify-and-Localize Framework for Few-Shot Event Detection
Feb 15, 2022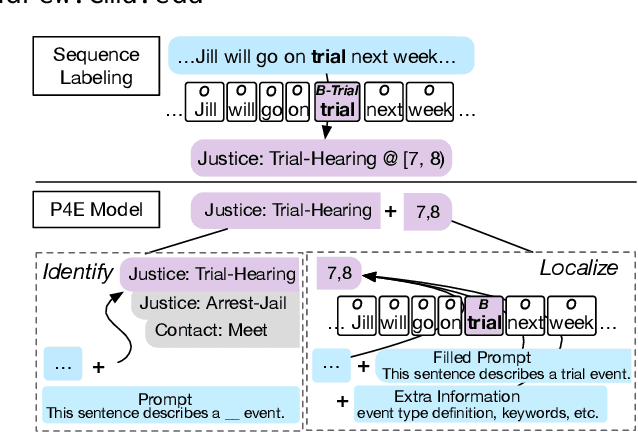
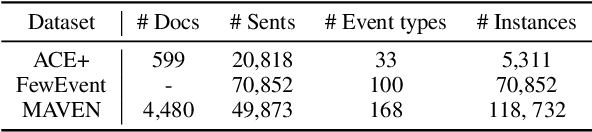
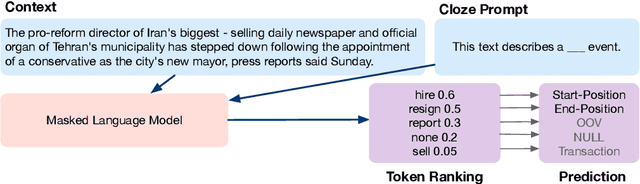
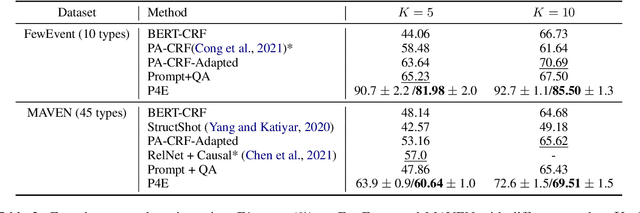
Practical applications of event extraction systems have long been hindered by their need for heavy human annotation. In order to scale up to new domains and event types, models must learn to cope with limited supervision, as in few-shot learning settings. To this end, the major challenge is to let the model master the semantics of event types, without requiring abundant event mention annotations. In our study, we employ cloze prompts to elicit event-related knowledge from pretrained language models and further use event definitions and keywords to pinpoint the trigger word. By formulating the event detection task as an identify-then-localize procedure, we minimize the number of type-specific parameters, enabling our model to quickly adapt to event detection tasks for new types. Experiments on three event detection benchmark datasets (ACE, FewEvent, MAVEN) show that our proposed method performs favorably under fully supervised settings and surpasses existing few-shot methods by 21% F1 on the FewEvent dataset and 20% on the MAVEN dataset when only 5 examples are provided for each event type.
Double Descent in Adversarial Training: An Implicit Label Noise Perspective
Oct 07, 2021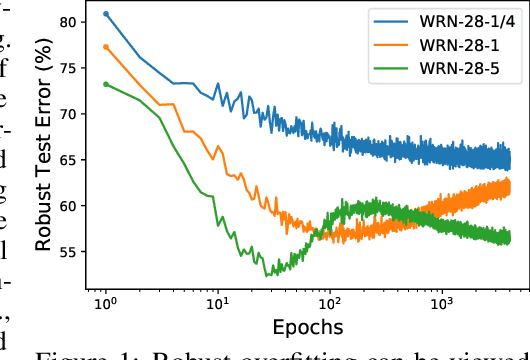
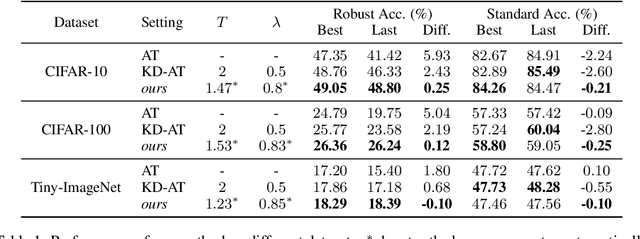
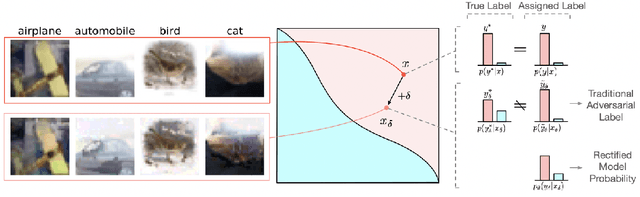
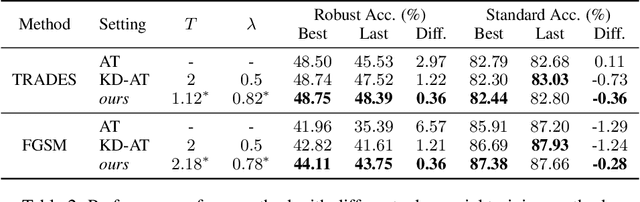
Here, we show that the robust overfitting shall be viewed as the early part of an epoch-wise double descent -- the robust test error will start to decrease again after training the model for a considerable number of epochs. Inspired by our observations, we further advance the analyses of double descent to understand robust overfitting better. In standard training, double descent has been shown to be a result of label flipping noise. However, this reasoning is not applicable in our setting, since adversarial perturbations are believed not to change the label. Going beyond label flipping noise, we propose to measure the mismatch between the assigned and (unknown) true label distributions, denoted as \emph{implicit label noise}. We show that the traditional labeling of adversarial examples inherited from their clean counterparts will lead to implicit label noise. Towards better labeling, we show that predicted distribution from a classifier, after scaling and interpolation, can provably reduce the implicit label noise under mild assumptions. In light of our analyses, we tailored the training objective accordingly to effectively mitigate the double descent and verified its effectiveness on three benchmark datasets.
Empower Distantly Supervised Relation Extraction with Collaborative Adversarial Training
Jun 21, 2021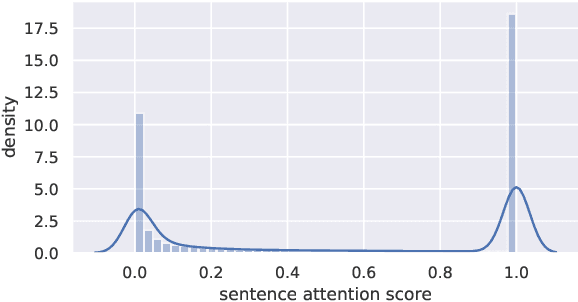
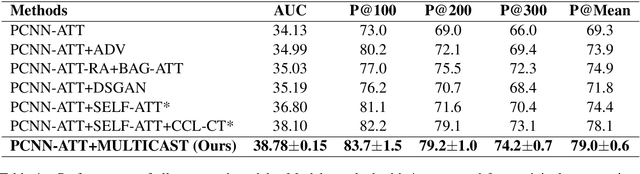
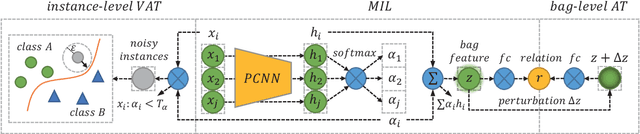
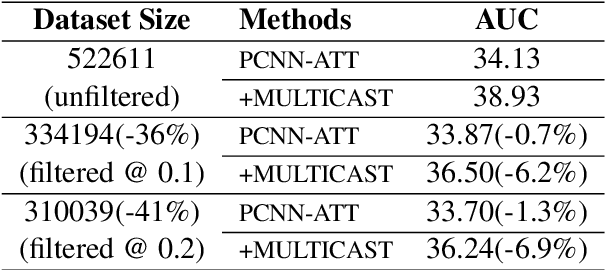
With recent advances in distantly supervised (DS) relation extraction (RE), considerable attention is attracted to leverage multi-instance learning (MIL) to distill high-quality supervision from the noisy DS. Here, we go beyond label noise and identify the key bottleneck of DS-MIL to be its low data utilization: as high-quality supervision being refined by MIL, MIL abandons a large amount of training instances, which leads to a low data utilization and hinders model training from having abundant supervision. In this paper, we propose collaborative adversarial training to improve the data utilization, which coordinates virtual adversarial training (VAT) and adversarial training (AT) at different levels. Specifically, since VAT is label-free, we employ the instance-level VAT to recycle instances abandoned by MIL. Besides, we deploy AT at the bag-level to unleash the full potential of the high-quality supervision got by MIL. Our proposed method brings consistent improvements (~ 5 absolute AUC score) to the previous state of the art, which verifies the importance of the data utilization issue and the effectiveness of our method.
Multi-head or Single-head? An Empirical Comparison for Transformer Training
Jun 17, 2021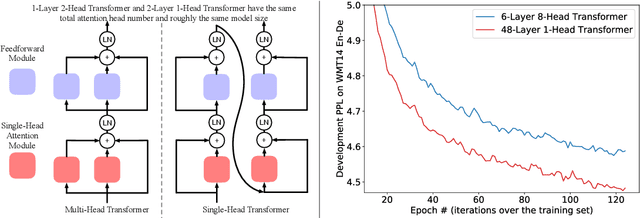
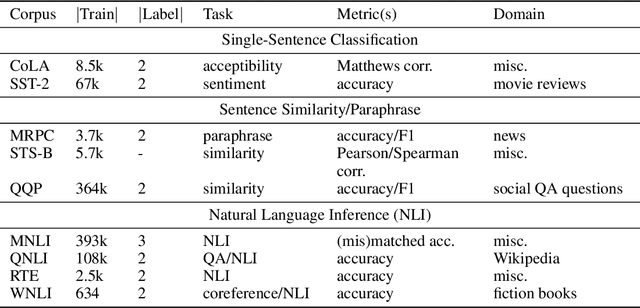


Multi-head attention plays a crucial role in the recent success of Transformer models, which leads to consistent performance improvements over conventional attention in various applications. The popular belief is that this effectiveness stems from the ability of jointly attending multiple positions. In this paper, we first demonstrate that jointly attending multiple positions is not a unique feature of multi-head attention, as multi-layer single-head attention also attends multiple positions and is more effective. Then, we suggest the main advantage of the multi-head attention is the training stability, since it has less number of layers than the single-head attention, when attending the same number of positions. For example, 24-layer 16-head Transformer (BERT-large) and 384-layer single-head Transformer has the same total attention head number and roughly the same model size, while the multi-head one is significantly shallower. Meanwhile, we show that, with recent advances in deep learning, we can successfully stabilize the training of the 384-layer Transformer. As the training difficulty is no longer a bottleneck, substantially deeper single-head Transformer achieves consistent performance improvements without tuning hyper-parameters.
UCPhrase: Unsupervised Context-aware Quality Phrase Tagging
May 28, 2021
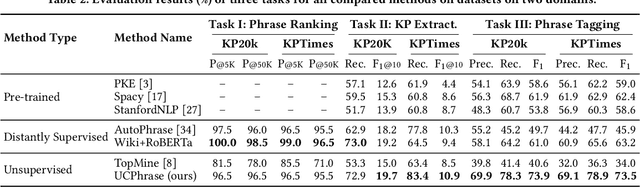
Identifying and understanding quality phrases from context is a fundamental task in text mining. The most challenging part of this task arguably lies in uncommon, emerging, and domain-specific phrases. The infrequent nature of these phrases significantly hurts the performance of phrase mining methods that rely on sufficient phrase occurrences in the input corpus. Context-aware tagging models, though not restricted by frequency, heavily rely on domain experts for either massive sentence-level gold labels or handcrafted gazetteers. In this work, we propose UCPhrase, a novel unsupervised context-aware quality phrase tagger. Specifically, we induce high-quality phrase spans as silver labels from consistently co-occurring word sequences within each document. Compared with typical context-agnostic distant supervision based on existing knowledge bases (KBs), our silver labels root deeply in the input domain and context, thus having unique advantages in preserving contextual completeness and capturing emerging, out-of-KB phrases. Training a conventional neural tagger based on silver labels usually faces the risk of overfitting phrase surface names. Alternatively, we observe that the contextualized attention maps generated from a transformer-based neural language model effectively reveal the connections between words in a surface-agnostic way. Therefore, we pair such attention maps with the silver labels to train a lightweight span prediction model, which can be applied to new input to recognize (unseen) quality phrases regardless of their surface names or frequency. Thorough experiments on various tasks and datasets, including corpus-level phrase ranking, document-level keyphrase extraction, and sentence-level phrase tagging, demonstrate the superiority of our design over state-of-the-art pre-trained, unsupervised, and distantly supervised methods.
Data Profiling for Adversarial Training: On the Ruin of Problematic Data
Feb 15, 2021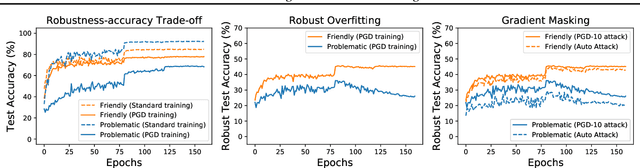



Multiple intriguing problems hover in adversarial training, including robustness-accuracy trade-off, robust overfitting, and gradient masking, posing great challenges to both reliable evaluation and practical deployment. Here, we show that these problems share one common cause -- low quality samples in the dataset. We first identify an intrinsic property of the data called problematic score and then design controlled experiments to investigate its connections with these problems. Specifically, we find that when problematic data is removed, robust overfitting and gradient masking can be largely alleviated; and robustness-accuracy trade-off is more prominent for a dataset containing highly problematic data. These observations not only verify our intuition about data quality but also open new opportunities to advance adversarial training. Remarkably, simply removing problematic data from adversarial training, while making the training set smaller, yields better robustness consistently with different adversary settings, training methods, and neural architectures.
On the Transformer Growth for Progressive BERT Training
Oct 23, 2020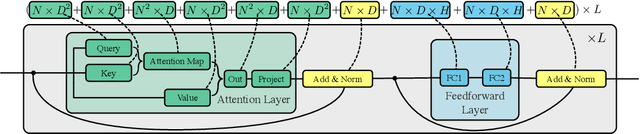
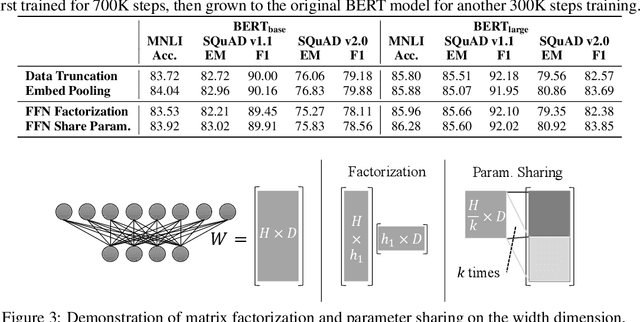
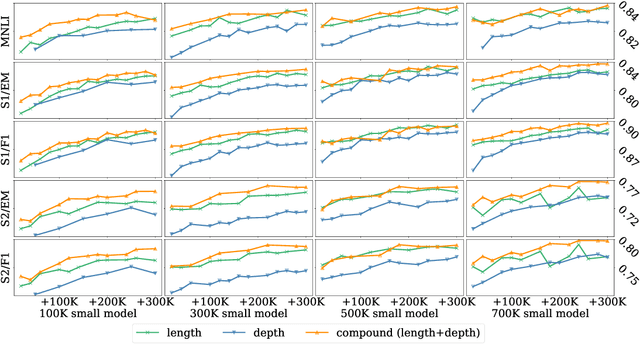
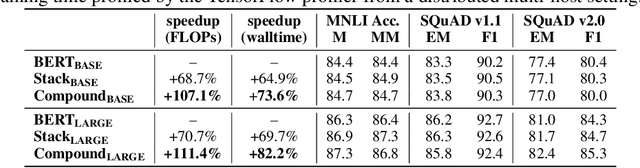
As the excessive pre-training cost arouses the need to improve efficiency, considerable efforts have been made to train BERT progressively--start from an inferior but low-cost model and gradually increase the computational complexity. Our objective is to help advance the understanding of such Transformer growth and discover principles that guide progressive training. First, we find that similar to network architecture selection, Transformer growth also favors compound scaling. Specifically, while existing methods only conduct network growth in a single dimension, we observe that it is beneficial to use compound growth operators and balance multiple dimensions (e.g., depth, width, and input length of the model). Moreover, we explore alternative growth operators in each dimension via controlled comparison to give practical guidance for operator selection. In light of our analyses, the proposed method CompoundGrow speeds up BERT pre-training by 73.6% and 82.2% for the base and large models respectively while achieving comparable performances. Code will be released for reproduction and future studies.
Overfitting or Underfitting? Understand Robustness Drop in Adversarial Training
Oct 15, 2020
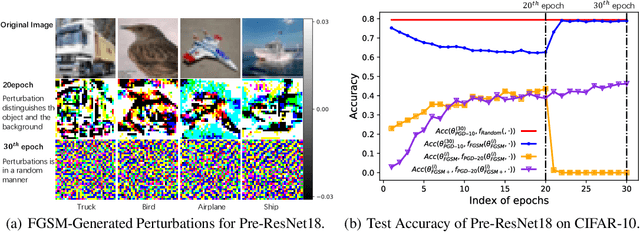
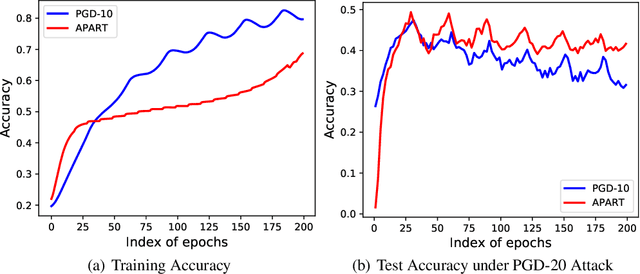
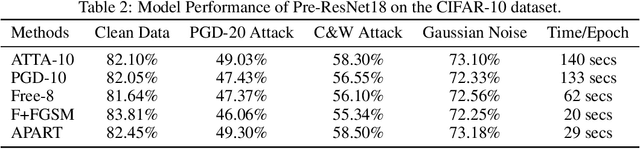
Our goal is to understand why the robustness drops after conducting adversarial training for too long. Although this phenomenon is commonly explained as overfitting, our analysis suggest that its primary cause is perturbation underfitting. We observe that after training for too long, FGSM-generated perturbations deteriorate into random noise. Intuitively, since no parameter updates are made to strengthen the perturbation generator, once this process collapses, it could be trapped in such local optima. Also, sophisticating this process could mostly avoid the robustness drop, which supports that this phenomenon is caused by underfitting instead of overfitting. In the light of our analyses, we propose APART, an adaptive adversarial training framework, which parameterizes perturbation generation and progressively strengthens them. Shielding perturbations from underfitting unleashes the potential of our framework. In our experiments, APART provides comparable or even better robustness than PGD-10, with only about 1/4 of its computational cost.