 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIG: Speaker Identification in Literature via Prompt-Based Generation
Dec 22, 2023



Identifying speakers of quotations in narratives is an important task in literary analysis, with challenging scenarios including the out-of-domain inference for unseen speakers, and non-explicit cases where there are no speaker mentions in surrounding context. In this work, we propose a simple and effective approach SIG, a generation-based method that verbalizes the task and quotation input based on designed prompt templates, which also enables easy integration of other auxiliary tasks that further bolster the speaker identification performance. The prediction can either come from direct generation by the model, or be determined by the highest generation probability of each speaker candidate. Based on our approach design, SIG supports out-of-domain evaluation, and achieves open-world classification paradigm that is able to accept any forms of candidate input. We perform both cross-domain evaluation and in-domain evaluation on PDNC, the largest dataset of this task, where empirical results suggest that SIG outperforms previous baselines of complicated designs, as well as the zero-shot ChatGPT, especially excelling at those hard non-explicit scenarios by up to 17% improvement. Additional experiments on another dataset WP further corroborate the efficacy of SIG.
A framework for mining lifestyle profiles through multi-dimensional and high-order mobility feature clustering
Dec 01, 2023



Human mobility demonstrates a high degree of regularity, which facilitates the discovery of lifestyle profiles. Existing research has yet to fully utilize the regularities embedded in high-order features extracted from human mobility records in such profiling. This study proposes a progressive feature extraction strategy that mines high-order mobility features from users' moving trajectory records from the spatial, temporal, and semantic dimensions. Specific features are extracted such as travel motifs, rhythms decomposed by discrete Fourier transform (DFT) of mobility time series, and vectorized place semantics by word2vec, respectively to the three dimensions, and they are further clustered to reveal the users' lifestyle characteristics. An experiment using a trajectory dataset of over 500k users in Shenzhen, China yields seven user clusters with different lifestyle profiles that can be well interpreted by common sense. The results suggest the possibility of fine-grained user profiling through cross-order trajectory feature engineering and clustering.
Towards Open-World Product Attribute Mining: A Lightly-Supervised Approach
May 26, 2023We present a new task setting for attribute mining on e-commerce products, serving as a practical solution to extract open-world attributes without extensive human intervention. Our supervision comes from a high-quality seed attribute set bootstrapped from existing resources, and we aim to expand the attribute vocabulary of existing seed types, and also to discover any new attribute types automatically. A new dataset is created to support our setting, and our approach Amacer is proposed specifically to tackle the limited supervision. Especially, given that no direct supervision is available for those unseen new attributes, our novel formulation exploits self-supervised heuristic and unsupervised latent attributes, which attains implicit semantic signals as additional supervision by leveraging product context. Experiments suggest that our approach surpasses various baselines by 12 F1, expanding attributes of existing types significantly by up to 12 times, and discovering values from 39% new types.
Online Coreference Resolution for Dialogue Processing: Improving Mention-Linking on Real-Time Conversations
May 21, 2022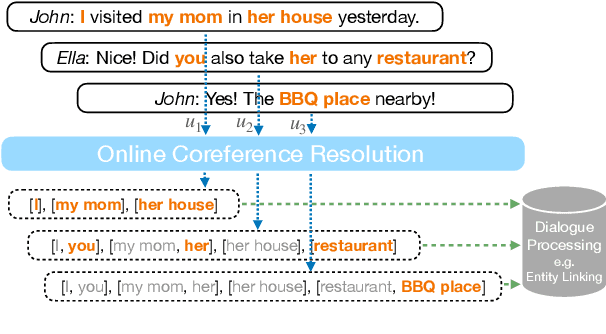
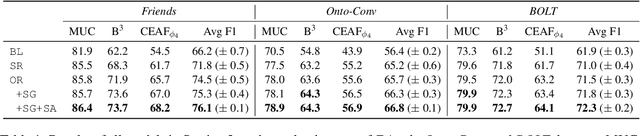
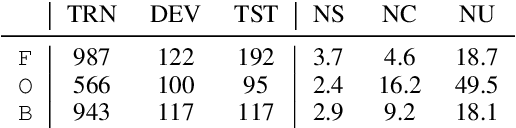
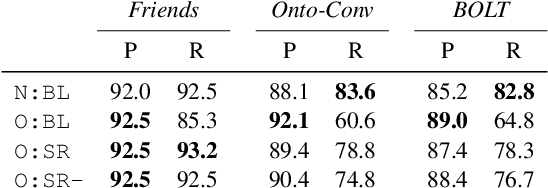
This paper suggests a direction of coreference resolution for online decoding on actively generated input such as dialogue, where the model accepts an utterance and its past context, then finds mentions in the current utterance as well as their referents, upon each dialogue turn. A baseline and four incremental-updated models adapted from the mention-linking paradigm are proposed for this new setting, which address different aspects including the singletons, speaker-grounded encoding and cross-turn mention contextualization. Our approach is assessed on three datasets: Friends, OntoNotes, and BOLT. Results show that each aspect brings out steady improvement, and our best models outperform the baseline by over 10%, presenting an effective system for this setting. Further analysis highlights the task characteristics, such as the significance of addressing the mention recall.
Number Entity Recognition
May 07, 2022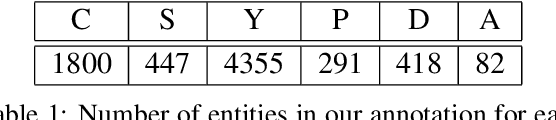
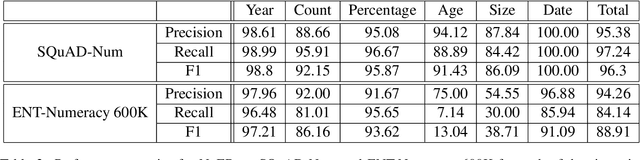

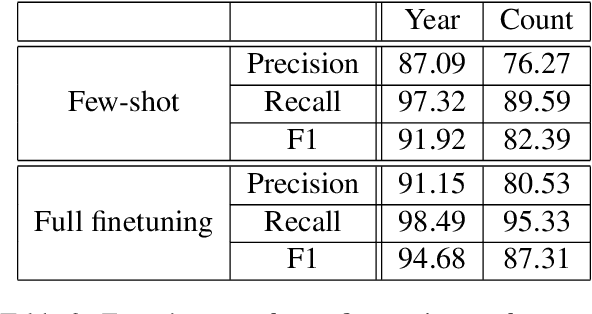
Numbers are essential components of text, like any other word tokens, from which natural language processing (NLP) models are built and deployed. Though numbers are typically not accounted for distinctly in most NLP tasks, there is still an underlying amount of numeracy already exhibited by NLP models. In this work, we attempt to tap this potential of state-of-the-art NLP models and transfer their ability to boost performance in related tasks. Our proposed classification of numbers into entities helps NLP models perform well on several tasks, including a handcrafted Fill-In-The-Blank (FITB) task and on question answering using joint embeddings, outperforming the BERT and RoBERTa baseline classification.
Modeling Task Interactions in Document-Level Joint Entity and Relation Extraction
May 04, 2022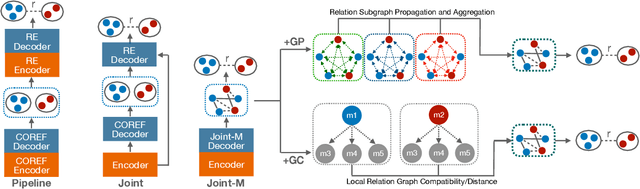
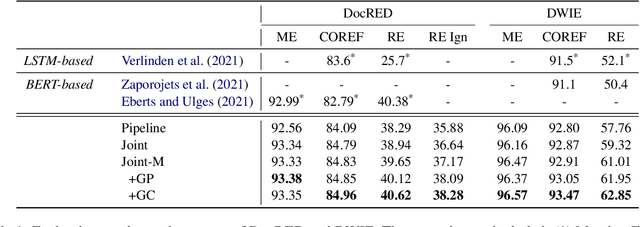


We target on the document-level relation extraction in an end-to-end setting, where the model needs to jointly perform mention extraction, coreference resolution (COREF) and relation extraction (RE) at once, and gets evaluated in an entity-centric way. Especially, we address the two-way interaction between COREF and RE that has not been the focus by previous work, and propose to introduce explicit interaction namely Graph Compatibility (GC) that is specifically designed to leverage task characteristics, bridging decisions of two tasks for direct task interference. Our experiments are conducted on DocRED and DWIE; in addition to GC, we implement and compare different multi-task settings commonly adopted in previous work, including pipeline, shared encoders, graph propagation, to examine the effectiveness of different interactions. The result shows that GC achieves the best performance by up to 2.3/5.1 F1 improvement over the baseline.
RescoreBERT: Discriminative Speech Recognition Rescoring with BERT
Feb 07, 2022
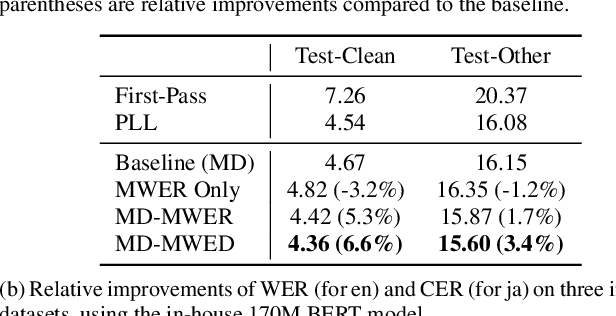

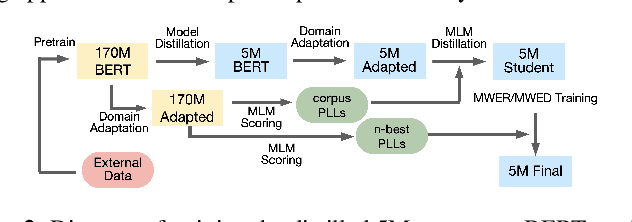
Second-pass rescoring is an important component in automatic speech recognition (ASR) systems that is used to improve the outputs from a first-pass decoder by implementing a lattice rescoring or $n$-best re-ranking. While pretraining with a masked language model (MLM) objective has received great success in various natural language understanding (NLU) tasks, it has not gained traction as a rescoring model for ASR. Specifically, training a bidirectional model like BERT on a discriminative objective such as minimum WER (MWER) has not been explored. Here we show how to train a BERT-based rescoring model with MWER loss, to incorporate the improvements of a discriminative loss into fine-tuning of deep bidirectional pretrained models for ASR. Specifically, we propose a fusion strategy that incorporates the MLM into the discriminative training process to effectively distill knowledge from a pretrained model. We further propose an alternative discriminative loss. We name this approach RescoreBERT. On the LibriSpeech corpus, it reduces WER by 6.6%/3.4% relative on clean/other test sets over a BERT baseline without discriminative objective. We also evaluate our method on an internal dataset from a conversational agent and find that it reduces both latency and WER (by 3 to 8% relative) over an LSTM rescoring model.
Zero-Shot Cross-Lingual Machine Reading Comprehension via Inter-Sentence Dependency Graph
Dec 09, 2021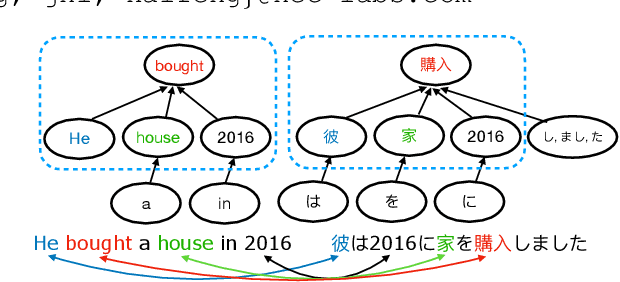
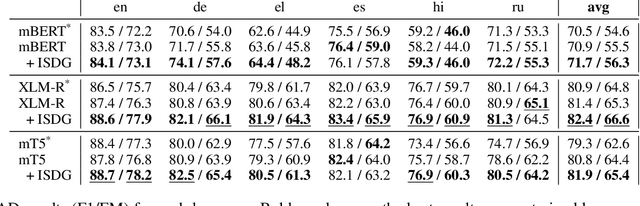
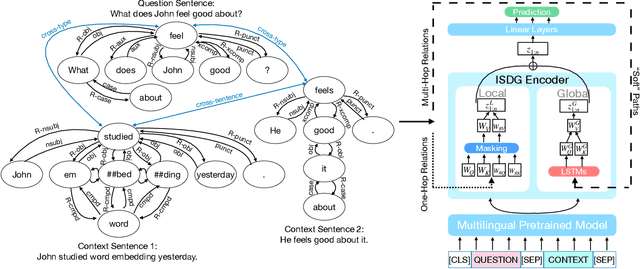
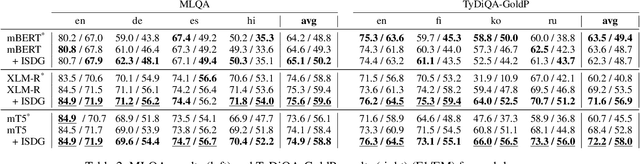
We target the task of cross-lingual Machine Reading Comprehension (MRC) in the direct zero-shot setting, by incorporating syntactic features from Universal Dependencies (UD), and the key features we use are the syntactic relations within each sentence. While previous work has demonstrated effective syntax-guided MRC models, we propose to adopt the inter-sentence syntactic relations, in addition to the rudimentary intra-sentence relations, to further utilize the syntactic dependencies in the multi-sentence input of the MRC task. In our approach, we build the Inter-Sentence Dependency Graph (ISDG) connecting dependency trees to form global syntactic relations across sentences. We then propose the ISDG encoder that encodes the global dependency graph, addressing the inter-sentence relations via both one-hop and multi-hop dependency paths explicitly. Experiments on three multilingual MRC datasets (XQuAD, MLQA, TyDiQA-GoldP) show that our encoder that is only trained on English is able to improve the zero-shot performance on all 14 test sets covering 8 languages, with up to 3.8 F1 / 5.2 EM improvement on-average, and 5.2 F1 / 11.2 EM on certain languages. Further analysis shows the improvement can be attributed to the attention on the cross-linguistically consistent syntactic path.
ELIT: Emory Language and Information Toolkit
Sep 08, 2021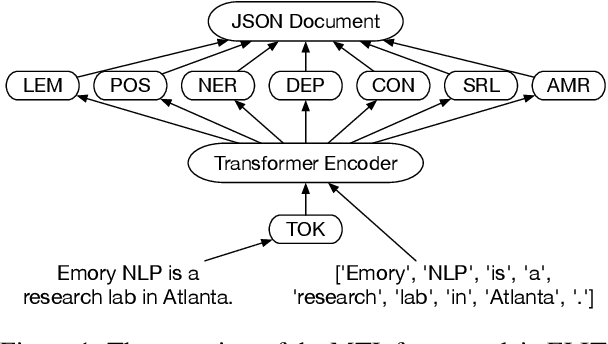
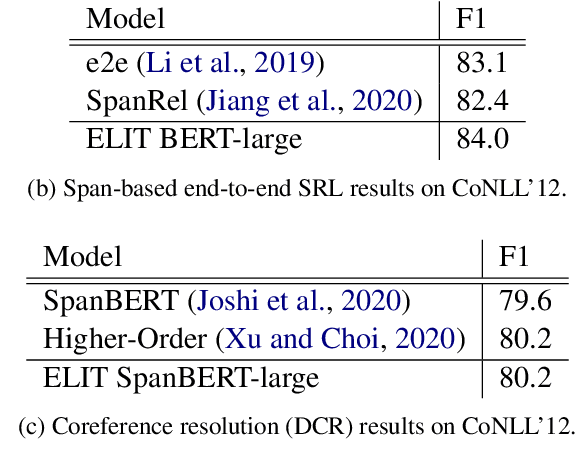

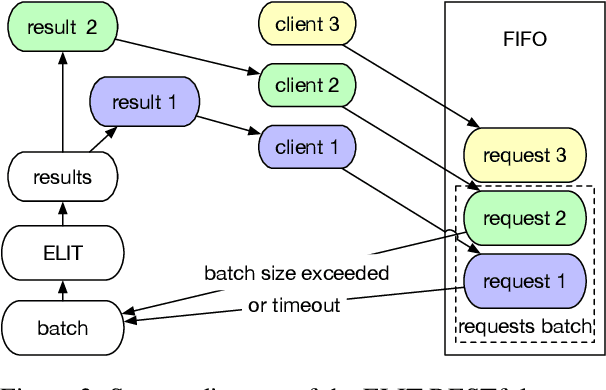
We introduce ELIT, the Emory Language and Information Toolkit, which is a comprehensive NLP framework providing transformer-based end-to-end models for core tasks with a special focus on memory efficiency while maintaining state-of-the-art accuracy and speed. Compared to existing toolkits, ELIT features an efficient Multi-Task Learning (MTL) model with many downstream tasks that include lemmatization, part-of-speech tagging, named entity recognition, dependency parsing, constituency parsing, semantic role labeling, and AMR parsing. The backbone of ELIT's MTL framework is a pre-trained transformer encoder that is shared across tasks to speed up their inference. ELIT provides pre-trained models developed on a remix of eight datasets. To scale up its service, ELIT also integrates a RESTful Client/Server combination. On the server side, ELIT extends its functionality to cover other tasks such as tokenization and coreference resolution, providing an end user with agile research experience. All resources including the source codes, documentation, and pre-trained models are publicly available at https://github.com/emorynlp/elit.
Boosting Cross-Lingual Transfer via Self-Learning with Uncertainty Estimation
Sep 01, 2021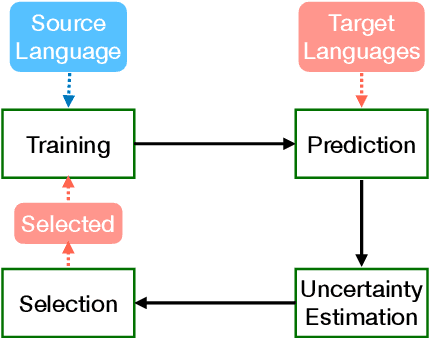
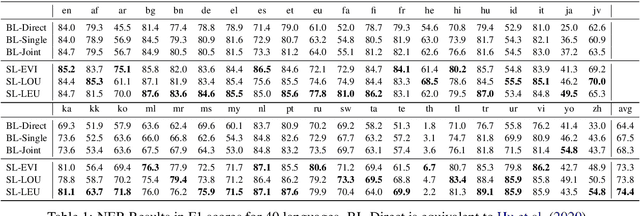
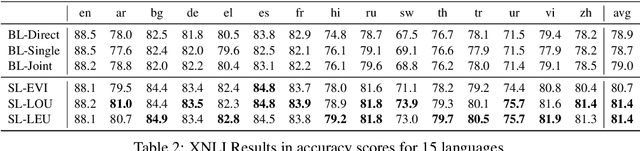
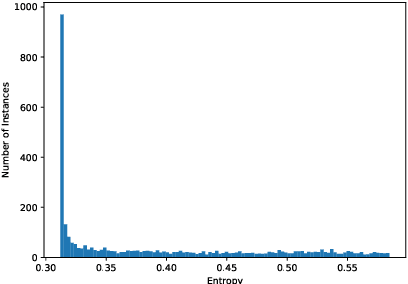
Recent multilingual pre-trained language models have achieved remarkable zero-shot performance, where the model is only finetuned on one source language and directly evaluated on target languages. In this work, we propose a self-learning framework that further utilizes unlabeled data of target languages, combined with uncertainty estimation in the process to select high-quality silver labels. Three different uncertainties are adapted and analyzed specifically for the cross lingual transfer: Language Heteroscedastic/Homoscedastic Uncertainty (LEU/LOU), Evidential Uncertainty (EVI). We evaluate our framework with uncertainties on two cross-lingual tasks including Named Entity Recognition (NER) and Natural Language Inference (NLI) covering 40 languages in total, which outperforms the baselines significantly by 10 F1 on average for NER and 2.5 accuracy score for NLI.