 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction-Based Reachability for Collision Avoidance in Autonomous Driving
Nov 24, 2020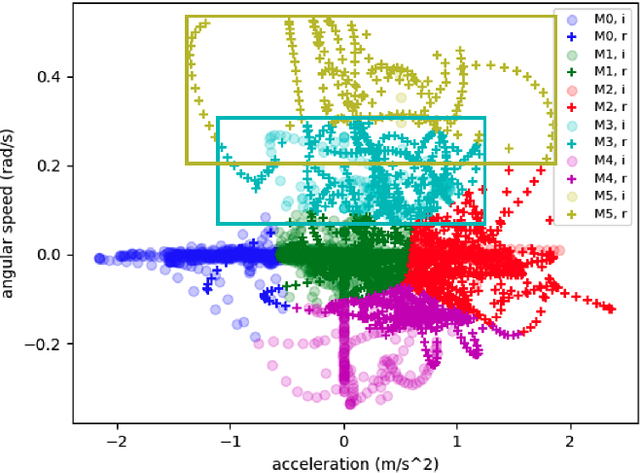
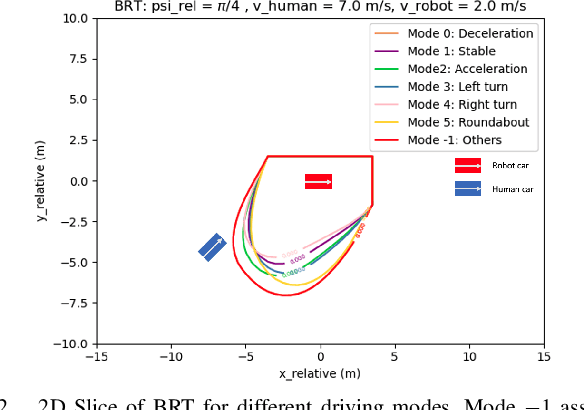
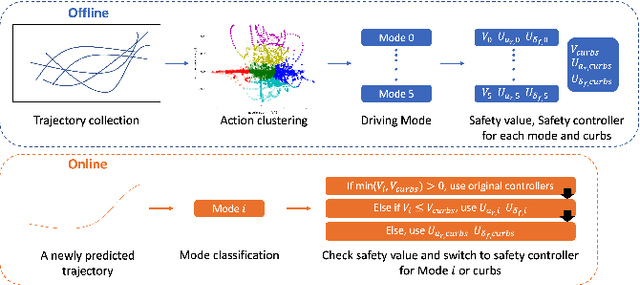
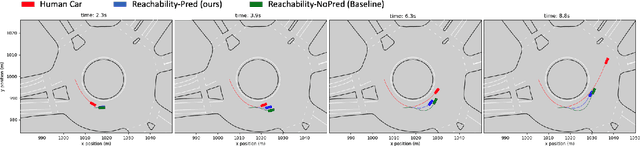
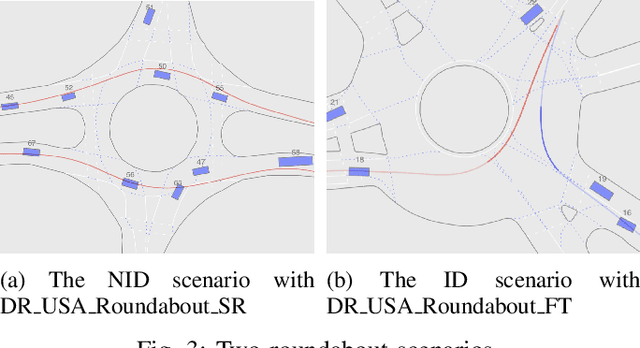
Safety is an important topic in autonomous driving since any collision may cause serious damage to people and the environment. Hamilton-Jacobi (HJ) Reachability is a formal method that verifies safety in multi-agent interaction and provides a safety controller for collision avoidance. However, due to the worst-case assumption on the car's future actions, reachability might result in too much conservatism such that the normal operation of the vehicle is largely hindered. In this paper, we leverage the power of trajectory prediction, and propose a prediction-based reachability framework for the safety controller. Instead of always assuming for the worst-case, we first cluster the car's behaviors into multiple driving modes, e.g. left turn or right turn. Under each mode, a reachability-based safety controller is designed based on a less conservative action set. For online purpose, we first utilize the trajectory prediction and our proposed mode classifier to predict the possible modes, and then deploy the corresponding safety controller. Through simulations in a T-intersection and an 8-way roundabout, we demonstrate that our prediction-based reachability method largely avoids collision between two interacting cars and reduces the conservatism that the safety controller brings to the car's original operations.
Socially-Compatible Behavior Design of Autonomous Vehicles with Verification on Real Human Data
Nov 10, 2020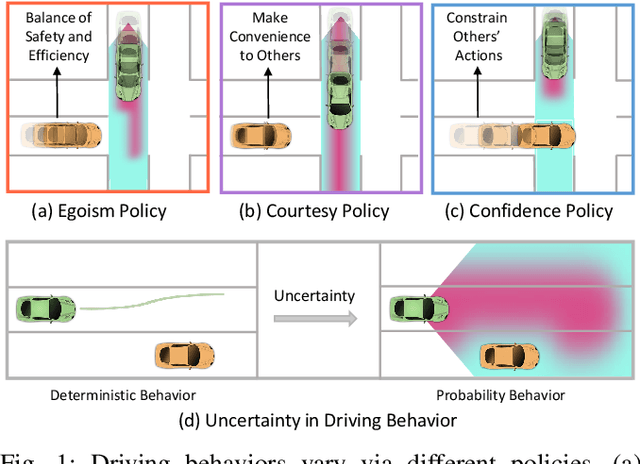
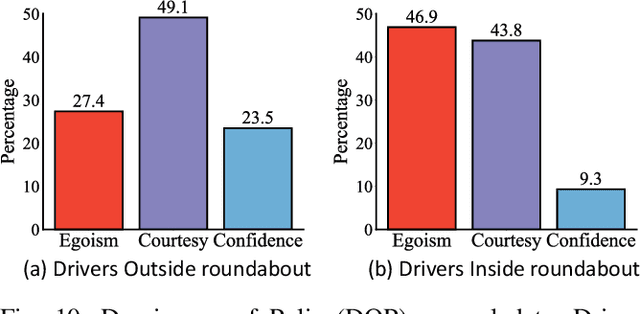
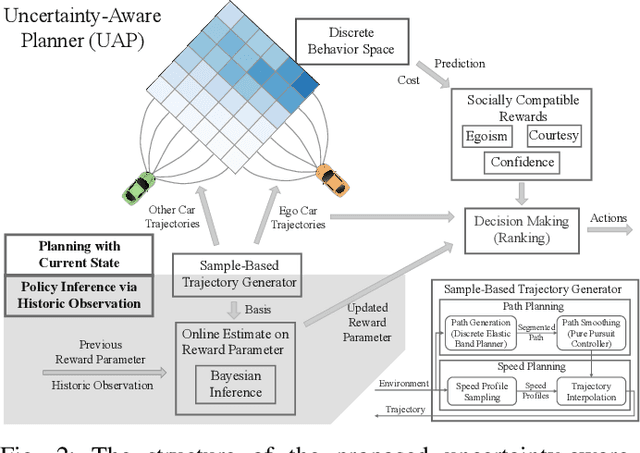
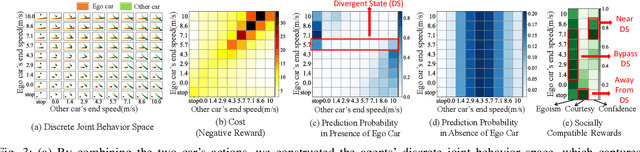
As more and more autonomous vehicles (AVs) are being deployed on public roads, designing socially compatible behaviors for them is of critical importance. Based on observations, AVs need to predict the future behaviors of other traffic participants, and be aware of the uncertainties associated with such prediction so that safe, efficient, and human-like motions can be generated. In this paper, we propose an integrated prediction and planning framework that allows the AVs to online infer the characteristics of other road users and generate behaviors optimizing not only their own rewards, but also their courtesy to others, as well as their confidence on the consequences in the presence of uncertainties. Based on the definitions of courtesy and confidence, we explore the influences of such factors on the behaviors of AVs in interactive driving scenarios. Moreover, we evaluate the proposed algorithm on naturalistic human driving data by comparing the generated behavior with the ground truth. Results show that the online inference can significantly improve the human-likeness of the generated behaviors. Furthermore, we find that human drivers show great courtesy to others, even for those without right-of-way.
IDE-Net: Interactive Driving Event and Pattern Extraction from Human Data
Nov 04, 2020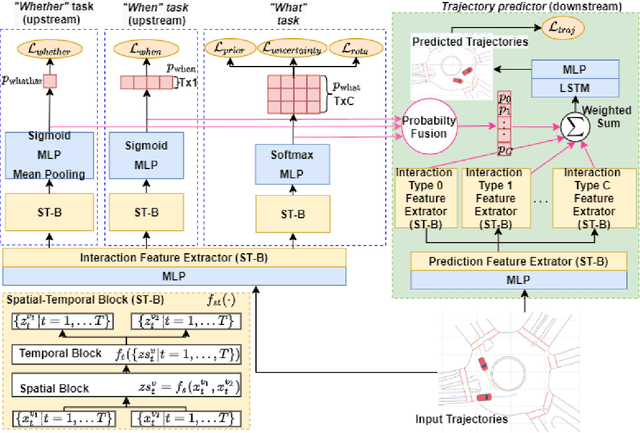

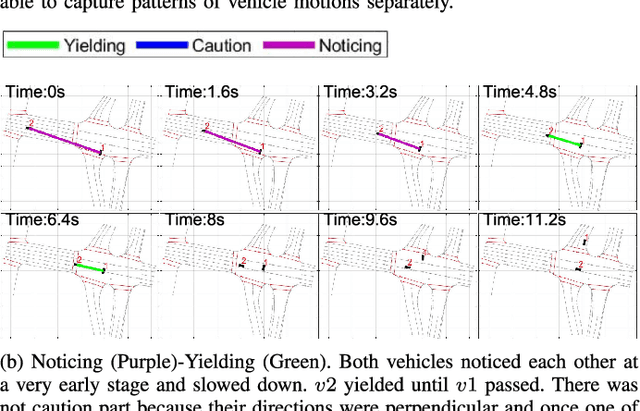
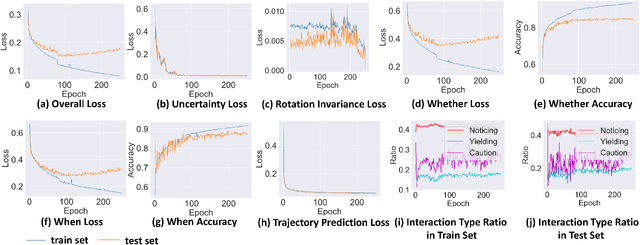
Autonomous vehicles (AVs) need to share the road with multiple, heterogeneous road users in a variety of driving scenarios. It is overwhelming and unnecessary to carefully interact with all observed agents, and AVs need to determine whether and when to interact with each surrounding agent. In order to facilitate the design and testing of prediction and planning modules of AVs, in-depth understanding of interactive behavior is expected with proper representation, and events in behavior data need to be extracted and categorized automatically. Answers to what are the essential patterns of interactions are also crucial for these motivations in addition to answering whether and when. Thus, learning to extract interactive driving events and patterns from human data for tackling the whether-when-what tasks is of critical importance for AVs. There is, however, no clear definition and taxonomy of interactive behavior, and most of the existing works are based on either manual labelling or hand-crafted rules and features. In this paper, we propose the Interactive Driving event and pattern Extraction Network (IDE-Net), which is a deep learning framework to automatically extract interaction events and patterns directly from vehicle trajectories. In IDE-Net, we leverage the power of multi-task learning and proposed three auxiliary tasks to assist the pattern extraction in an unsupervised fashion. We also design a unique spatial-temporal block to encode the trajectory data. Experimental results on the INTERACTION dataset verified the effectiveness of such designs in terms of better generalizability and effective pattern extraction. We find three interpretable patterns of interactions, bringing insights for driver behavior representation, modeling and comprehension. Both objective and subjective evaluation metrics are adopted in our analysis of the learned patterns.
Bounded Risk-Sensitive Markov Game and Its Inverse Reward Learning Problem
Sep 05, 2020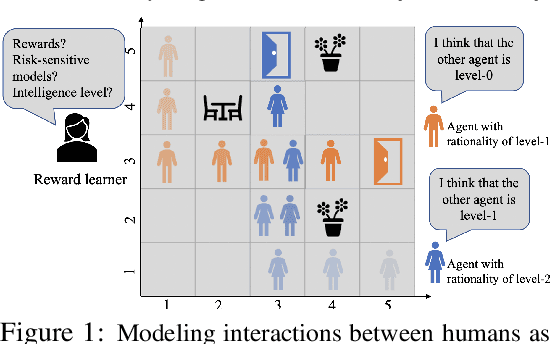

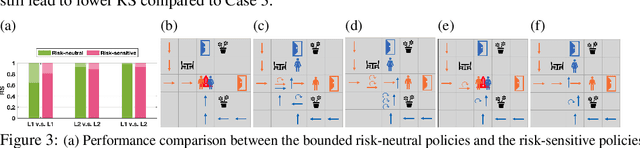

Classical game-theoretic approaches for multi-agent systems in both the forward policy learning/design problem and the inverse reward learning problem often make strong rationality assumptions: agents are perfectly rational expected utility maximizers. Specifically, the agents are risk-neutral to all uncertainties, maximize their expected rewards, and have unlimited computation resources to explore such policies. Such assumptions, however, substantially mismatch with many observed humans' behaviors such as satisficing with sub-optimal policies, risk-seeking and loss-aversion decisions. In this paper, we investigate the problem of bounded risk-sensitive Markov Game (BRSMG) and its inverse reward learning problem. Instead of assuming unlimited computation resources, we consider the influence of bounded intelligence by exploiting iterative reasoning models in BRSMG. Instead of assuming agents maximize their expected utilities (a risk-neutral measure), we consider the impact of risk-sensitive measures such as the cumulative prospect theory. Convergence analysis of BRSMG for both the forward policy learning and the inverse reward learning are established. The proposed forward policy learning and inverse reward learning algorithms in BRSMG are validated through a navigation scenario. Simulation results show that the behaviors of agents in BRSMG demonstrate both risk-averse and risk-seeking phenomena, which are consistent with observations from humans. Moreover, in the inverse reward learning task, the proposed bounded risk-sensitive inverse learning algorithm outperforms the baseline risk-neutral inverse learning algorithm.
Expressing Diverse Human Driving Behavior with Probabilistic Rewards and Online Inference
Aug 21, 2020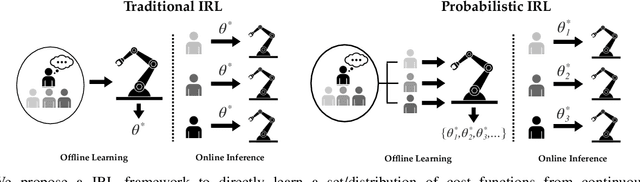
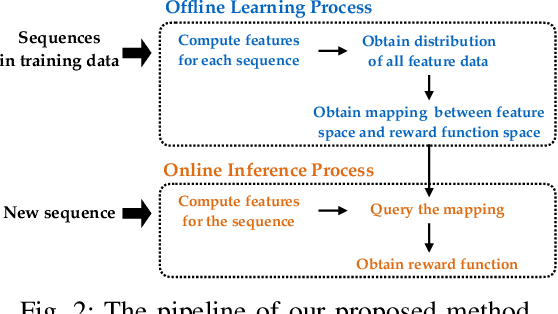
In human-robot interaction (HRI) systems, such as autonomous vehicles, understanding and representing human behavior are important. Human behavior is naturally rich and diverse. Cost/reward learning, as an efficient way to learn and represent human behavior, has been successfully applied in many domains. Most of traditional inverse reinforcement learning (IRL) algorithms, however, cannot adequately capture the diversity of human behavior since they assume that all behavior in a given dataset is generated by a single cost function.In this paper, we propose a probabilistic IRL framework that directly learns a distribution of cost functions in continuous domain. Evaluations on both synthetic data and real human driving data are conducted. Both the quantitative and subjective results show that our proposed framework can better express diverse human driving behaviors, as well as extracting different driving styles that match what human participants interpret in our user study.
Efficient Sampling-Based Maximum Entropy Inverse Reinforcement Learning with Application to Autonomous Driving
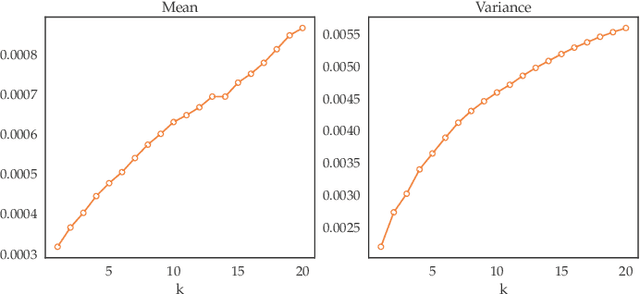
Jun 22, 2020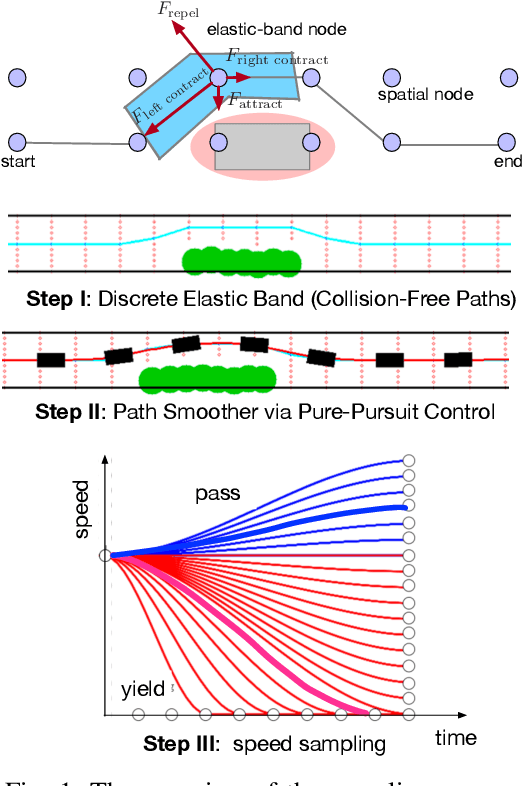
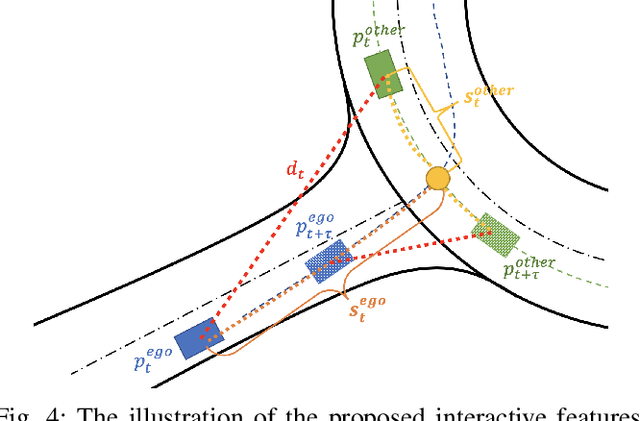
In the past decades, we have witnessed significant progress in the domain of autonomous driving. Advanced techniques based on optimization and reinforcement learning (RL) become increasingly powerful at solving the forward problem: given designed reward/cost functions, how should we optimize them and obtain driving policies that interact with the environment safely and efficiently. Such progress has raised another equally important question: \emph{what should we optimize}? Instead of manually specifying the reward functions, it is desired that we can extract what human drivers try to optimize from real traffic data and assign that to autonomous vehicles to enable more naturalistic and transparent interaction between humans and intelligent agents. To address this issue, we present an efficient sampling-based maximum-entropy inverse reinforcement learning (IRL) algorithm in this paper. Different from existing IRL algorithms, by introducing an efficient continuous-domain trajectory sampler, the proposed algorithm can directly learn the reward functions in the continuous domain while considering the uncertainties in demonstrated trajectories from human drivers. We evaluate the proposed algorithm on real driving data, including both non-interactive and interactive scenarios. The experimental results show that the proposed algorithm achieves more accurate prediction performance with faster convergence speed and better generalization compared to other baseline IRL algorithms.
Experimental Evaluation of Human Motion Prediction: Toward Safe and Efficient Human Robot Collaboration
Jan 27, 2020
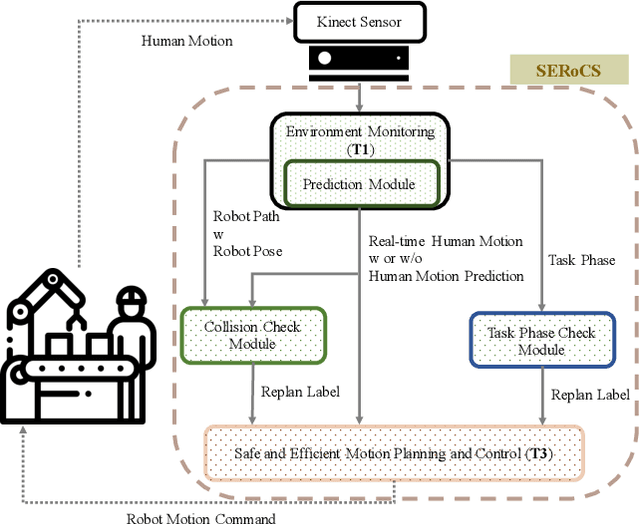
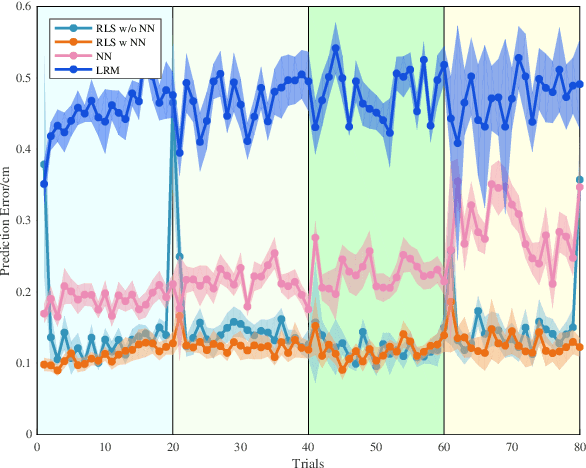
Human motion prediction is non-trivial in modern industrial settings. Accurate prediction of human motion can not only improve efficiency in human robot collaboration, but also enhance human safety in close proximity to robots. Among existing prediction models, the parameterization and identification methods of those models vary. It remains unclear what is the necessary parameterization of a prediction model, whether online adaptation of the model is necessary, and whether prediction can help improve safety and efficiency during human robot collaboration. These problems result from the difficulty to quantitatively evaluate various prediction models in a closed-loop fashion in real human-robot interaction settings. This paper develops a method to evaluate the closed-loop performance of different prediction models. In particular, we compare models with different parameterizations and models with or without online parameter adaptation. Extensive experiments were conducted on a human robot collaboration platform. The experimental results demonstrated that human motion prediction significantly enhanced the collaboration efficiency and human safety. Adaptable prediction models that were parameterized by neural networks achieved the best performance.
Multiple criteria decision-making for lane-change model
Oct 22, 2019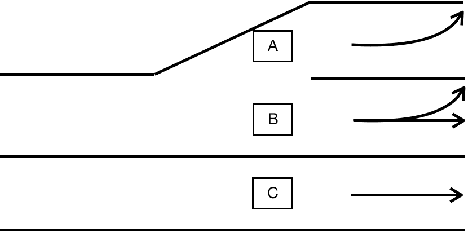
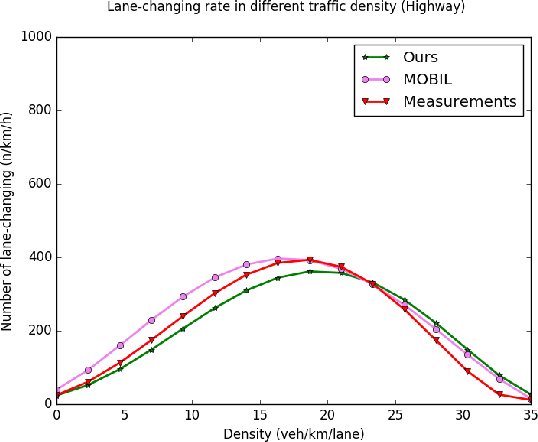
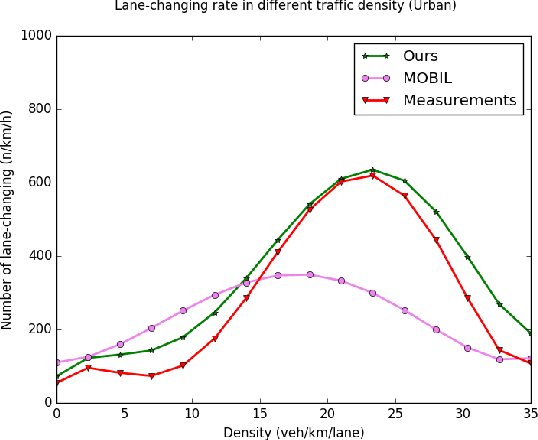
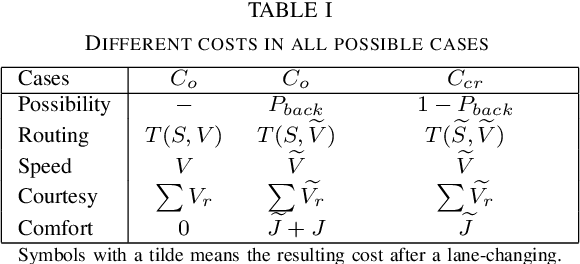
Simulation has long been an essential part of testing autonomous driving systems, but only recently has simulation been useful for building and training self-driving vehicles. Vehicle behavioural models are necessary to simulate the interactions between robot cars. This paper proposed a new method to formalize the lane-changing model in urban driving scenarios. We define human incentives from different perspectives, speed incentive, route change incentive, comfort incentive and courtesy incentive etc. We applied a decision-theoretical tool, called Multi-Criteria Decision Making (MCDM) to take these incentive policies into account. The strategy of combination is according to different driving style which varies for each driving. Thus a lane-changing decision selection algorithm is proposed. Not only our method allows for varying the motivation of lane-changing from the purely egoistic desire to a more courtesy concern, but also they can mimic drivers' state, inattentive or concentrate, which influences their driving Behaviour. We define some cost functions and calibrate the parameters with different scenarios of traffic data. Distinguishing driving styles are used to aggregate decision-makers' assessments about various criteria weightings to obtain the action drivers desire most. Our result demonstrates the proposed method can produce varied lane-changing behaviour. Unlike other lane-changing models based on artificial intelligence methods, our model has more flexible controllability.
INTERACTION Dataset: An INTERnational, Adversarial and Cooperative moTION Dataset in Interactive Driving Scenarios with Semantic Maps
Sep 30, 2019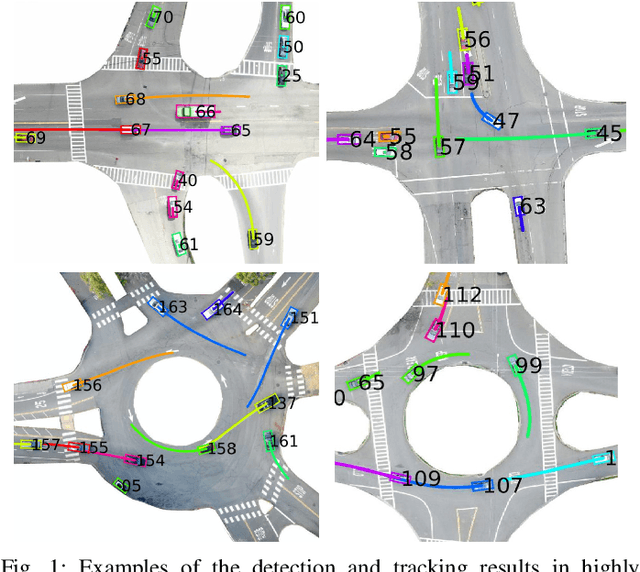
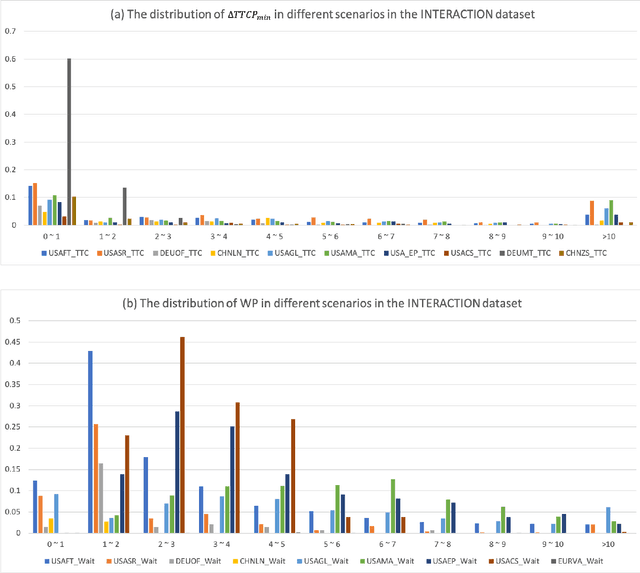
Behavior-related research areas such as motion prediction/planning, representation/imitation learning, behavior modeling/generation, and algorithm testing, require support from high-quality motion datasets containing interactive driving scenarios with different driving cultures. In this paper, we present an INTERnational, Adversarial and Cooperative moTION dataset (INTERACTION dataset) in interactive driving scenarios with semantic maps. Five features of the dataset are highlighted. 1) The interactive driving scenarios are diverse, including urban/highway/ramp merging and lane changes, roundabouts with yield/stop signs, signalized intersections, intersections with one/two/all-way stops, etc. 2) Motion data from different countries and different continents are collected so that driving preferences and styles in different cultures are naturally included. 3) The driving behavior is highly interactive and complex with adversarial and cooperative motions of various traffic participants. Highly complex behavior such as negotiations, aggressive/irrational decisions and traffic rule violations are densely contained in the dataset, while regular behavior can also be found from cautious car-following, stop, left/right/U-turn to rational lane-change and cycling and pedestrian crossing, etc. 4) The levels of criticality span wide, from regular safe operations to dangerous, near-collision maneuvers. Real collision, although relatively slight, is also included. 5) Maps with complete semantic information are provided with physical layers, reference lines, lanelet connections and traffic rules. The data is recorded from drones and traffic cameras. Statistics of the dataset in terms of number of entities and interaction density are also provided, along with some utilization examples in a variety of behavior-related research areas. The dataset can be downloaded via https://interaction-dataset.com.
Generic Prediction Architecture Considering both Rational and Irrational Driving Behaviors
Jul 23, 2019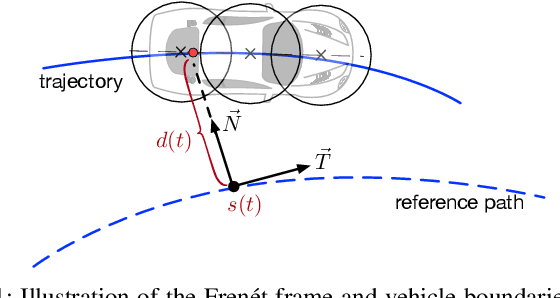

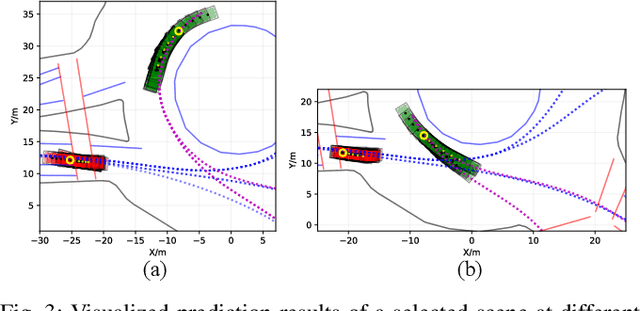
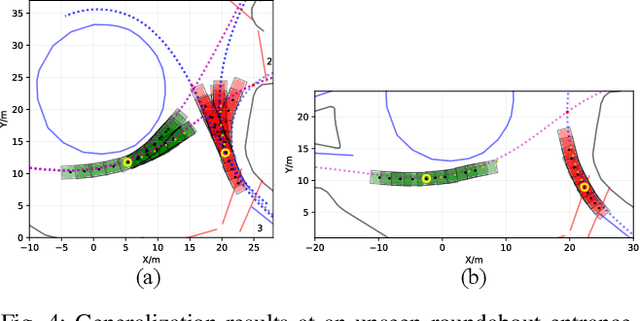
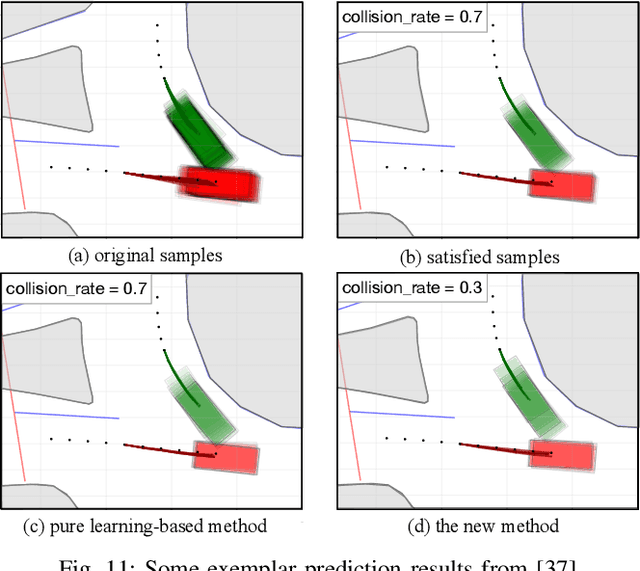
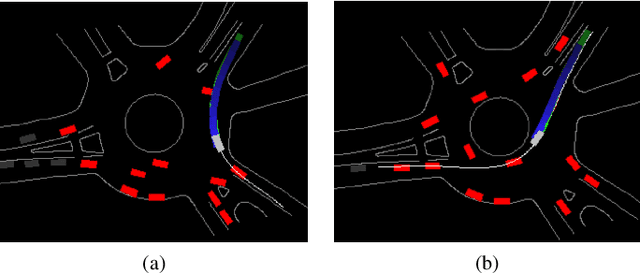
Accurately predicting future behaviors of surrounding vehicles is an essential capability for autonomous vehicles in order to plan safe and feasible trajectories. The behaviors of others, however, are full of uncertainties. Both rational and irrational behaviors exist, and the autonomous vehicles need to be aware of this in their prediction module. The prediction module is also expected to generate reasonable results in the presence of unseen and corner scenarios. Two types of prediction models are typically used to solve the prediction problem: learning-based model and planning-based model. Learning-based model utilizes real driving data to model the human behaviors. Depending on the structure of the data, learning-based models can predict both rational and irrational behaviors. But the balance between them cannot be customized, which creates challenges in generalizing the prediction results. Planning-based model, on the other hand, usually assumes human as a rational agent, i.e., it anticipates only rational behavior of human drivers. In this paper, a generic prediction architecture is proposed to address various rationalities in human behavior. We leverage the advantages from both learning-based and planning-based prediction models. The proposed approach is able to predict continuous trajectories that well-reflect possible future situations of other drivers. Moreover, the prediction performance remains stable under various unseen driving scenarios. A case study under a real-world roundabout scenario is provided to demonstrate the performance and capability of the proposed prediction architecture.