 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook into Facial Expression Domain Adaptation: Adversarial Graph Learning and A Fair Evaluation Benchmark
Aug 27, 2020

To address the problem of data inconsistencies among different facial expression recognition (FER) datasets, many cross-domain FER methods (CD-FERs) have been extensively devised in recent years. Although each declares to achieve superior performance, fair comparisons are lacking due to the inconsistent choices of the source/target datasets and feature extractors. In this work, we first analyze the performance effect caused by these inconsistent choices, and then re-implement some well-performing CD-FER and recently published domain adaptation algorithms. We ensure that all these algorithms adopt the same source datasets and feature extractors for fair CD-FER evaluations. We find that most of the current leading algorithms use adversarial learning to learn holistic domain-invariant features to mitigate domain shifts. However, these algorithms ignore local features, which are more transferable across different datasets and carry more detailed content for fine-grained adaptation. To address these issues, we integrate graph representation propagation with adversarial learning for cross-domain holistic-local feature co-adaptation by developing a novel adversarial graph representation adaptation (AGRA) framework. Specifically, it first builds two graphs to correlate holistic and local regions within each domain and across different domains, respectively. Then, it extracts holistic-local features from the input image and uses learnable per-class statistical distributions to initialize the corresponding graph nodes. Finally, two stacked graph convolution networks (GCNs) are adopted to propagate holistic-local features within each domain to explore their interaction and across different domains for holistic-local feature co-adaptation. We conduct extensive and fair evaluations on several popular benchmarks and show that the proposed AGRA framework outperforms previous state-of-the-art methods.
Efficient Crowd Counting via Structured Knowledge Transfer
Apr 26, 2020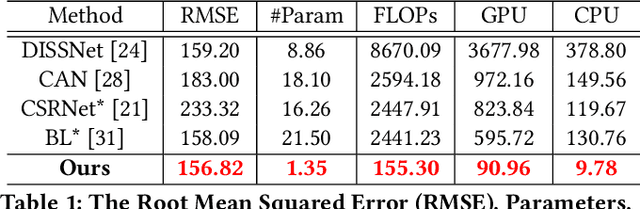
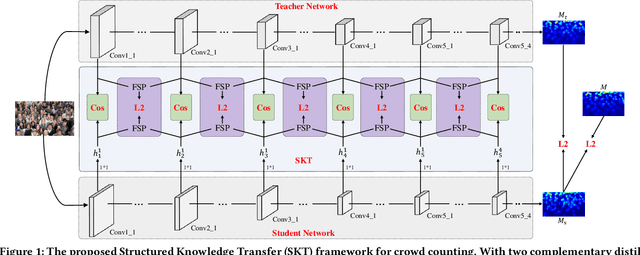

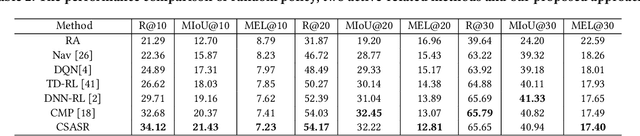
Crowd counting is an application-oriented task and its inference efficiency is crucial for real-world applications. However, most previous works relied on heavy backbone networks and required prohibitive run-time consumption, which would seriously restrict their deployment scopes and cause poor scalability. To liberate these crowd counting models, we propose a novel Structured Knowledge Transfer (SKT) framework, which fully exploits the structured knowledge of a well-trained teacher network to generate a lightweight but still highly effective student network. Specifically, it is integrated with two complementary transfer modules, including an Intra-Layer Pattern Transfer which sequentially distills the knowledge embedded in layer-wise features of the teacher network to guide feature learning of the student network and an Inter-Layer Relation Transfer which densely distills the cross-layer correlation knowledge of the teacher to regularize the student's feature evolution. In this way, our student network can derive the layer-wise and cross-layer knowledge from the teacher network to learn compact yet effective features. Extensive evaluations on three benchmarks well demonstrate the effectiveness of our SKT for extensive crowd counting models. In particular, only using around $6\%$ of the parameters and computation cost of original models, our distilled VGG-based models obtain at least 6.5$\times$ speed-up on an Nvidia 1080 GPU and even achieve state-of-the-art performance.
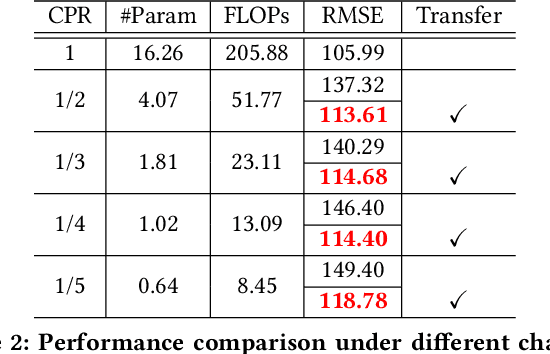
Physical-Virtual Collaboration Graph Network for Station-Level Metro Ridership Prediction
Jan 14, 2020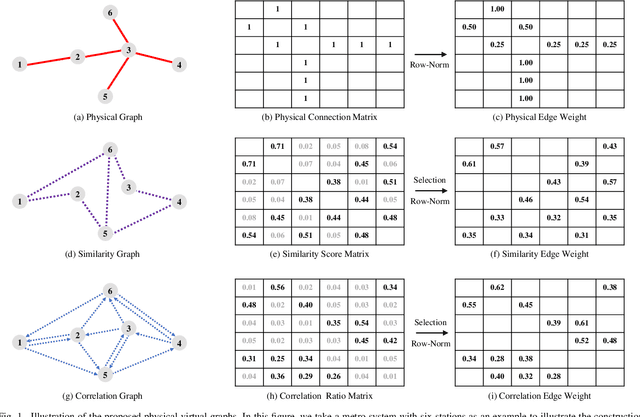
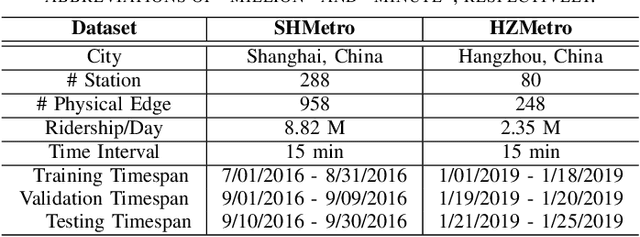
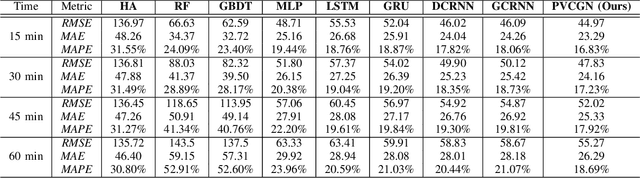
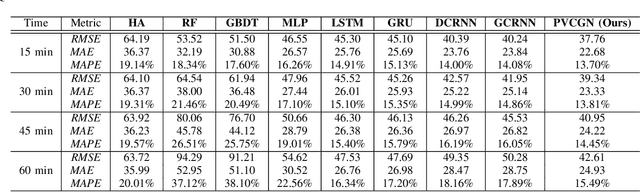
Due to the widespread applications in real-world scenarios, metro ridership prediction is a crucial but challenging task in intelligent transportation systems. However, conventional methods that either ignored the topological information of metro systems or directly learned on physical topology, can not fully explore the ridership evolution patterns. To address this problem, we model a metro system as graphs with various topologies and propose a unified Physical-Virtual Collaboration Graph Network (PVCGN), which can effectively learn the complex ridership patterns from the tailor-designed graphs. Specifically, a physical graph is directly built based on the realistic topology of the studied metro system, while a similarity graph and a correlation graph are built with virtual topologies under the guidance of the inter-station passenger flow similarity and correlation. These complementary graphs are incorporated into a Graph Convolution Gated Recurrent Unit (GC-GRU) for spatial-temporal representation learning. Further, a Fully-Connected Gated Recurrent Unit (FC-GRU) is also applied to capture the global evolution tendency. Finally, we develop a seq2seq model with GC-GRU and FC-GRU to forecast the future metro ridership sequentially. Extensive experiments on two large-scale benchmarks (e.g., Shanghai Metro and Hangzhou Metro) well demonstrate the superiority of the proposed PVCGN for station-level metro ridership prediction.
ACFM: A Dynamic Spatial-Temporal Network for Traffic Prediction
Sep 02, 2019
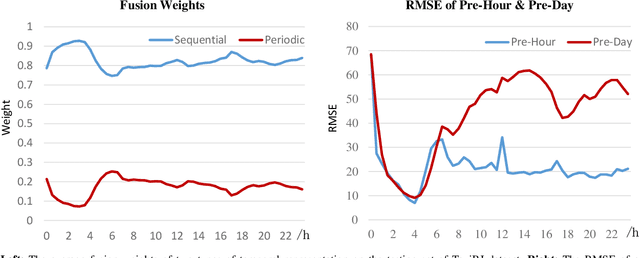
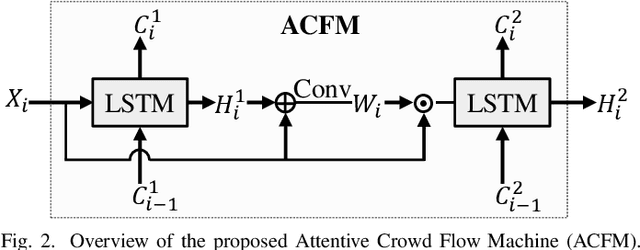
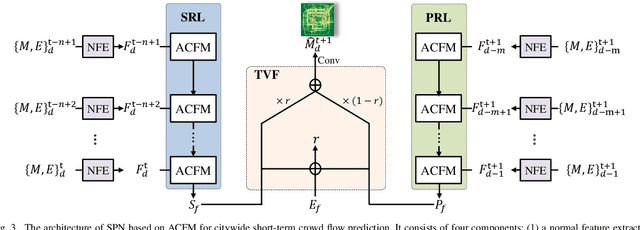
As a crucial component in intelligent transportation systems, crowd flow prediction has recently attracted widespread research interest in the field of artificial intelligence (AI) with the increasing availability of large-scale traffic mobility data. Its key challenge lies in how to integrate diverse factors (such as temporal laws and spatial dependencies) to infer the evolution trend of crowd flow. To address this problem, we propose a unified neural network called Attentive Crowd Flow Machine (ACFM), which can effectively learn the spatial-temporal feature representations of crowd flow with an attention mechanism. In particular, our ACFM is composed of two progressive ConvLSTM units connected with a convolutional layer. Specifically, the first LSTM unit takes normal crowd flow features as input and generates a hidden state at each time-step, which is further fed into the connected convolutional layer for spatial attention map inference. The second LSTM unit aims at learning the dynamic spatial-temporal representations from the attentionally weighted crowd flow features. Further, we develop two deep frameworks based on ACFM to predict citywide short-term/long-term crowd flow by adaptively incorporating the sequential and periodic data as well as other external influences. Extensive experiments on two standard benchmarks well demonstrate the superiority of the proposed method for crowd flow prediction. Moreover, to verify the generalization of our method, we also apply the customized framework to forecast the passenger pickup/dropoff demands and show its superior performance in this traffic prediction task.
Crowd Counting with Deep Structured Scale Integration Network
Aug 23, 2019


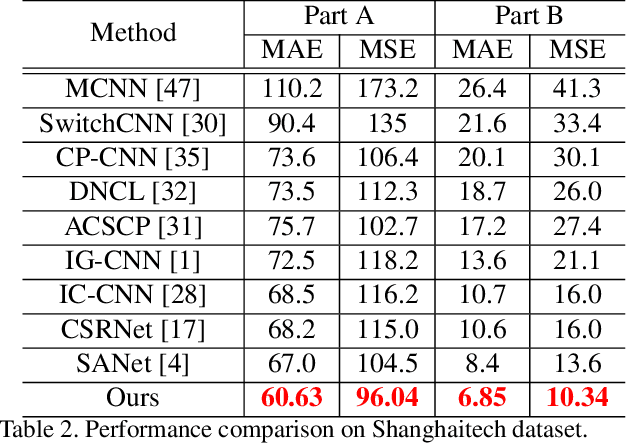
Automatic estimation of the number of people in unconstrained crowded scenes is a challenging task and one major difficulty stems from the huge scale variation of people. In this paper, we propose a novel Deep Structured Scale Integration Network (DSSINet) for crowd counting, which addresses the scale variation of people by using structured feature representation learning and hierarchically structured loss function optimization. Unlike conventional methods which directly fuse multiple features with weighted average or concatenation, we first introduce a Structured Feature Enhancement Module based on conditional random fields (CRFs) to refine multiscale features mutually with a message passing mechanism. In this module, each scale-specific feature is considered as a continuous random variable and passes complementary information to refine the features at other scales. Second, we utilize a Dilated Multiscale Structural Similarity loss to enforce our DSSINet to learn the local correlation of people's scales within regions of various size, thus yielding high-quality density maps. Extensive experiments on four challenging benchmarks well demonstrate the effectiveness of our method. Specifically, our DSSINet achieves improvements of 9.5% error reduction on Shanghaitech dataset and 24.9% on UCF-QNRF dataset against the state-of-the-art methods.
Investigation of wind pressures on tall building under interference effects using machine learning techniques
Aug 20, 2019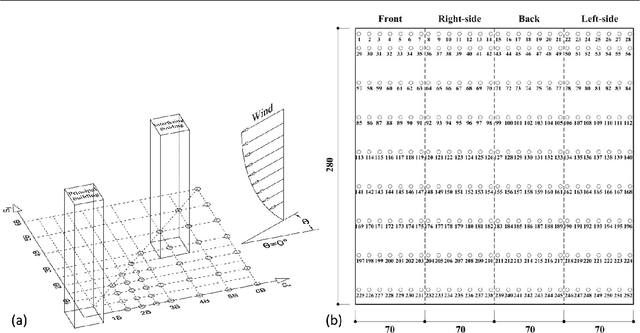
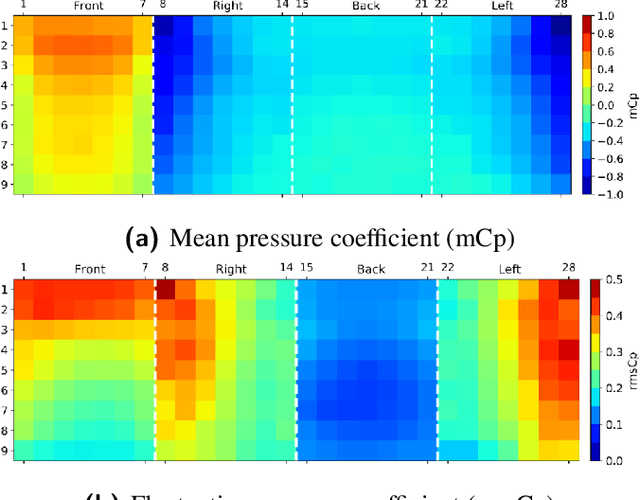
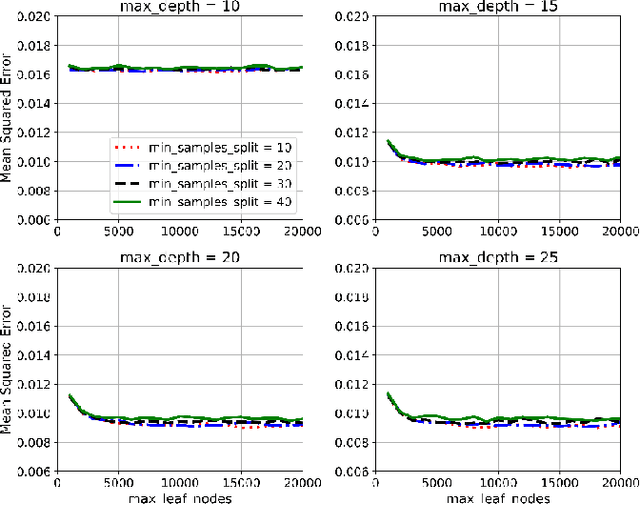
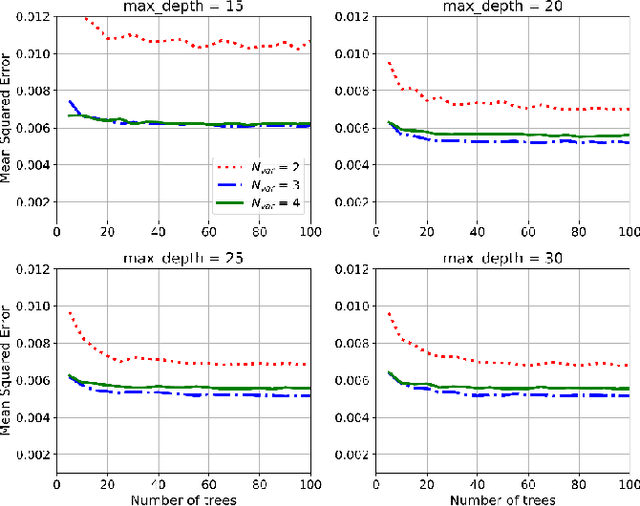
Interference effects of tall buildings have attracted numerous studies due to the boom of clusters of tall buildings in megacities. To fully understand the interference effects of buildings, it often requires a substantial amount of wind tunnel tests. Limited wind tunnel tests that only cover part of interference scenarios are unable to fully reveal the interference effects. This study used machine learning techniques to resolve the conflicting requirement between limited wind tunnel tests that produce unreliable results and a completed investigation of the interference effects that is costly and time-consuming. Four machine learning models including decision tree, random forest, XGBoost, generative adversarial networks (GANs), were trained based on 30% of a dataset to predict both mean and fluctuating pressure coefficients on the principal building. The GANs model exhibited the best performance in predicting these pressure coefficients. A number of GANs models were then trained based on different portions of the dataset ranging from 10% to 90%. It was found that the GANs model based on 30% of the dataset is capable of predicting both mean and fluctuating pressure coefficients under unseen interference conditions accurately. By using this GANs model, 70% of the wind tunnel test cases can be saved, largely alleviating the cost of this kind of wind tunnel testing study.
Contextualized Spatial-Temporal Network for Taxi Origin-Destination Demand Prediction
May 15, 2019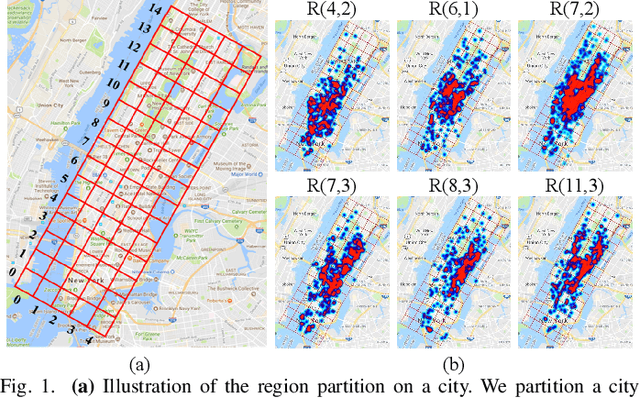
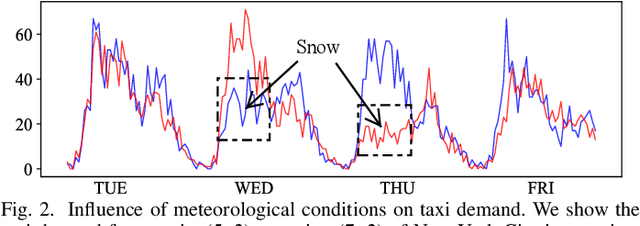
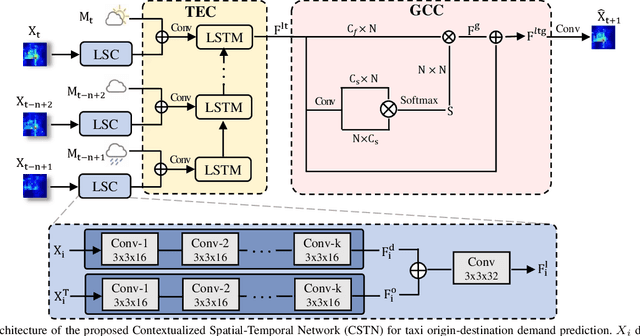
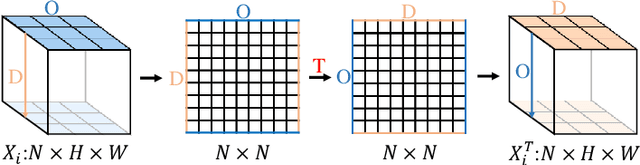
Taxi demand prediction has recently attracted increasing research interest due to its huge potential application in large-scale intelligent transportation systems. However, most of the previous methods only considered the taxi demand prediction in origin regions, but neglected the modeling of the specific situation of the destination passengers. We believe it is suboptimal to preallocate the taxi into each region based solely on the taxi origin demand. In this paper, we present a challenging and worth-exploring task, called taxi origin-destination demand prediction, which aims at predicting the taxi demand between all region pairs in a future time interval. Its main challenges come from how to effectively capture the diverse contextual information to learn the demand patterns. We address this problem with a novel Contextualized Spatial-Temporal Network (CSTN), which consists of three components for the modeling of local spatial context (LSC), temporal evolution context (TEC) and global correlation context (GCC) respectively. Firstly, an LSC module utilizes two convolution neural networks to learn the local spatial dependencies of taxi demand respectively from the origin view and the destination view. Secondly, a TEC module incorporates both the local spatial features of taxi demand and the meteorological information to a Convolutional Long Short-term Memory Network (ConvLSTM) for the analysis of taxi demand evolution. Finally, a GCC module is applied to model the correlation between all regions by computing a global correlation feature as a weighted sum of all regional features, with the weights being calculated as the similarity between the corresponding region pairs. Extensive experiments and evaluations on a large-scale dataset well demonstrate the superiority of our CSTN over other compared methods for taxi origin-destination demand prediction.
Facial Landmark Machines: A Backbone-Branches Architecture with Progressive Representation Learning
Dec 10, 2018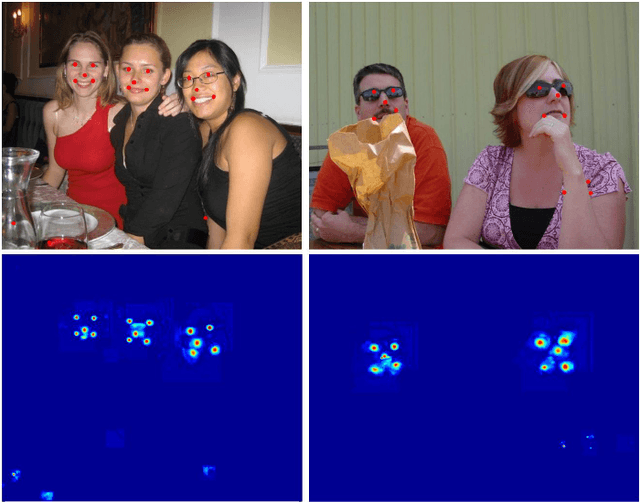
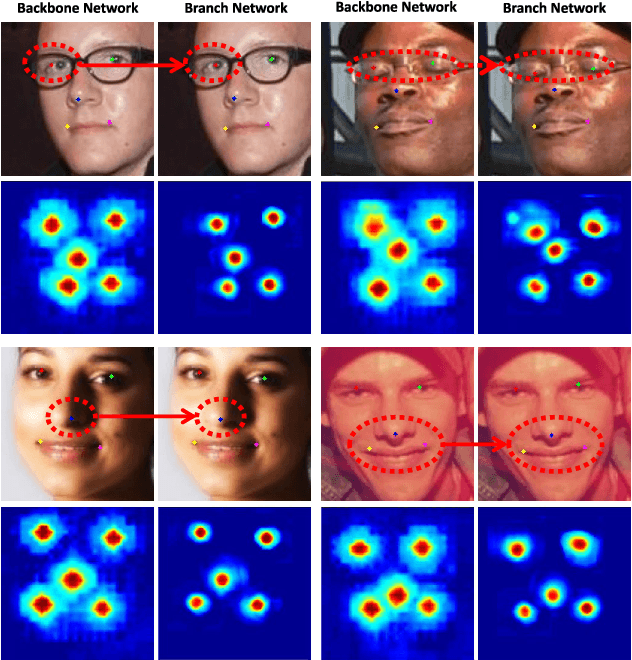
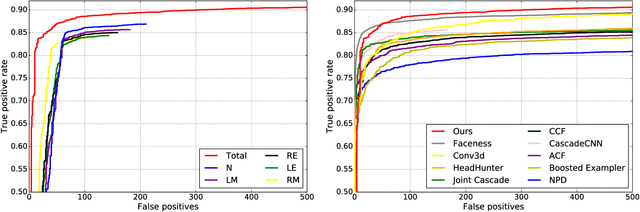
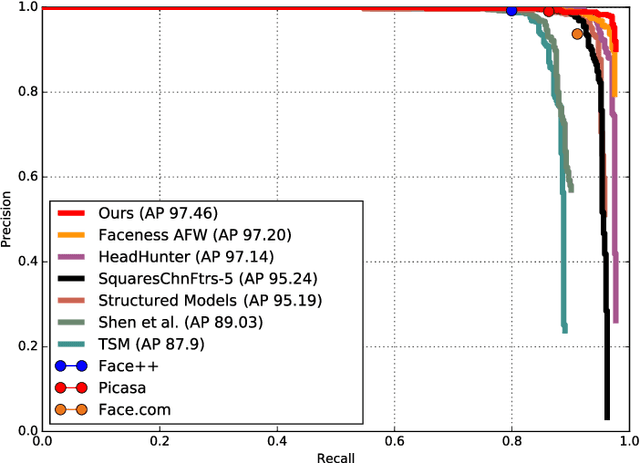
Facial landmark localization plays a critical role in face recognition and analysis. In this paper, we propose a novel cascaded backbone-branches fully convolutional neural network~(BB-FCN) for rapidly and accurately localizing facial landmarks in unconstrained and cluttered settings. Our proposed BB-FCN generates facial landmark response maps directly from raw images without any preprocessing. BB-FCN follows a coarse-to-fine cascaded pipeline, which consists of a backbone network for roughly detecting the locations of all facial landmarks and one branch network for each type of detected landmark for further refining their locations. Furthermore, to facilitate the facial landmark localization under unconstrained settings, we propose a large-scale benchmark named SYSU16K, which contains 16000 faces with large variations in pose, expression, illumination and resolution. Extensive experimental evaluations demonstrate that our proposed BB-FCN can significantly outperform the state-of-the-art under both constrained (i.e., within detected facial regions only) and unconstrained settings. We further confirm that high-quality facial landmarks localized with our proposed network can also improve the precision and recall of face detection.
Attentive Crowd Flow Machines
Sep 01, 2018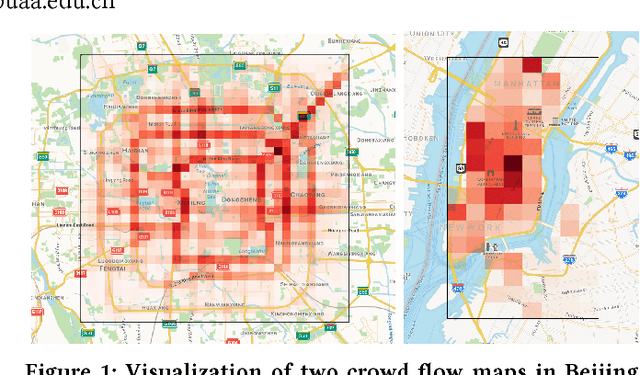
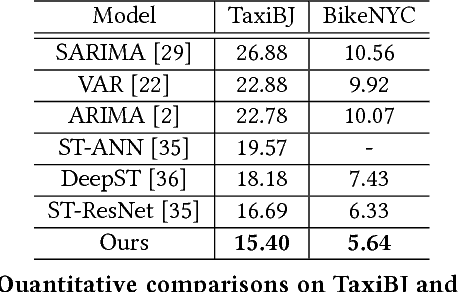
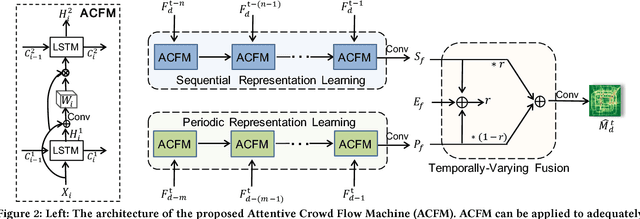
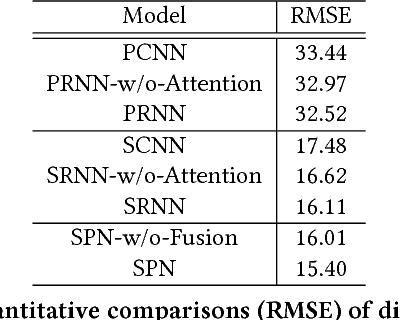
Traffic flow prediction is crucial for urban traffic management and public safety. Its key challenges lie in how to adaptively integrate the various factors that affect the flow changes. In this paper, we propose a unified neural network module to address this problem, called Attentive Crowd Flow Machine~(ACFM), which is able to infer the evolution of the crowd flow by learning dynamic representations of temporally-varying data with an attention mechanism. Specifically, the ACFM is composed of two progressive ConvLSTM units connected with a convolutional layer for spatial weight prediction. The first LSTM takes the sequential flow density representation as input and generates a hidden state at each time-step for attention map inference, while the second LSTM aims at learning the effective spatial-temporal feature expression from attentionally weighted crowd flow features. Based on the ACFM, we further build a deep architecture with the application to citywide crowd flow prediction, which naturally incorporates the sequential and periodic data as well as other external influences. Extensive experiments on two standard benchmarks (i.e., crowd flow in Beijing and New York City) show that the proposed method achieves significant improvements over the state-of-the-art methods.
Crowd Counting using Deep Recurrent Spatial-Aware Network
Jul 02, 2018
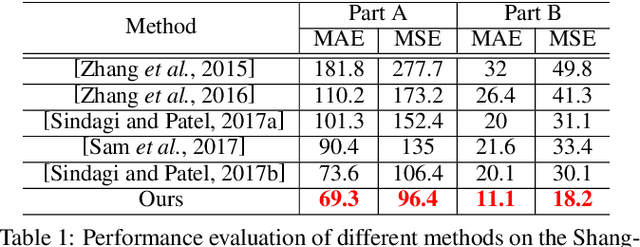
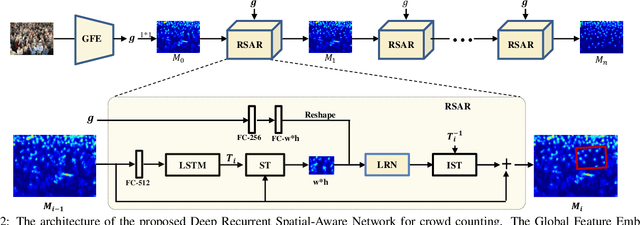
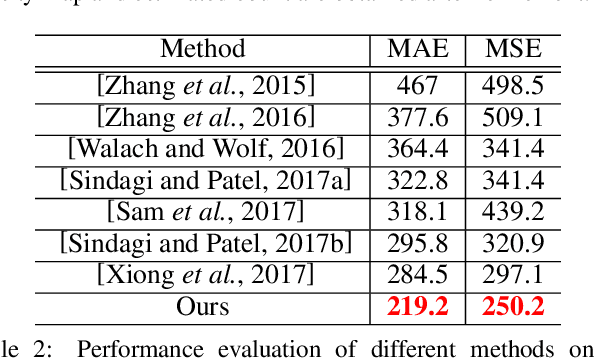
Crowd counting from unconstrained scene images is a crucial task in many real-world applications like urban surveillance and management, but it is greatly challenged by the camera's perspective that causes huge appearance variations in people's scales and rotations. Conventional methods address such challenges by resorting to fixed multi-scale architectures that are often unable to cover the largely varied scales while ignoring the rotation variations. In this paper, we propose a unified neural network framework, named Deep Recurrent Spatial-Aware Network, which adaptively addresses the two issues in a learnable spatial transform module with a region-wise refinement process. Specifically, our framework incorporates a Recurrent Spatial-Aware Refinement (RSAR) module iteratively conducting two components: i) a Spatial Transformer Network that dynamically locates an attentional region from the crowd density map and transforms it to the suitable scale and rotation for optimal crowd estimation; ii) a Local Refinement Network that refines the density map of the attended region with residual learning. Extensive experiments on four challenging benchmarks show the effectiveness of our approach. Specifically, comparing with the existing best-performing methods, we achieve an improvement of 12% on the largest dataset WorldExpo'10 and 22.8% on the most challenging dataset UCF_CC_50.