 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLitMind Dictionary: An Open-Source Online Dictionary
Apr 23, 2022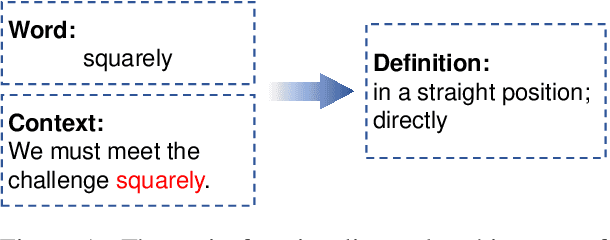
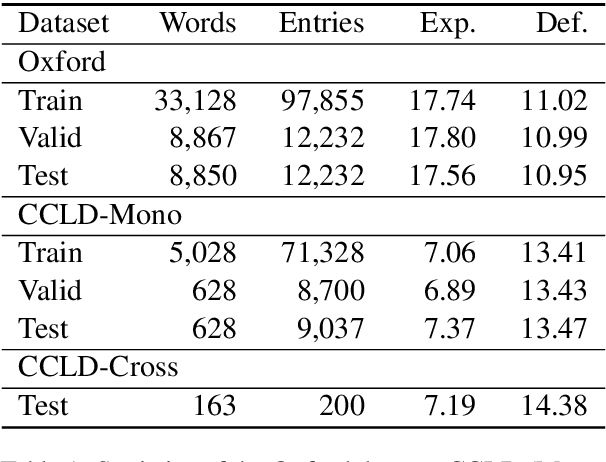
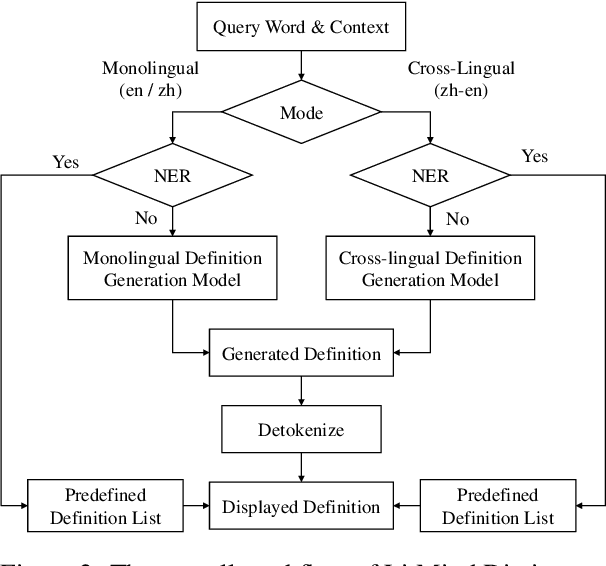
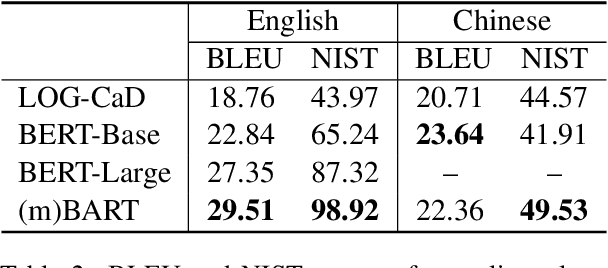
Dictionaries can help language learners to learn vocabulary by providing definitions of words. Since traditional dictionaries present word senses as discrete items in predefined inventories, they fall short of flexibility, which is required in providing specific meanings of words in particular contexts. In this paper, we introduce the LitMind Dictionary (https://dictionary.litmind.ink), an open-source online generative dictionary that takes a word and context containing the word as input and automatically generates a definition as output. Incorporating state-of-the-art definition generation models, it supports not only Chinese and English, but also Chinese-English cross-lingual queries. Moreover, it has a user-friendly front-end design that can help users understand the query words quickly and easily. All the code and data are available at https://github.com/blcuicall/litmind-dictionary.
BLCU-ICALL at SemEval-2022 Task 1: Cross-Attention Multitasking Framework for Definition Modeling
Apr 16, 2022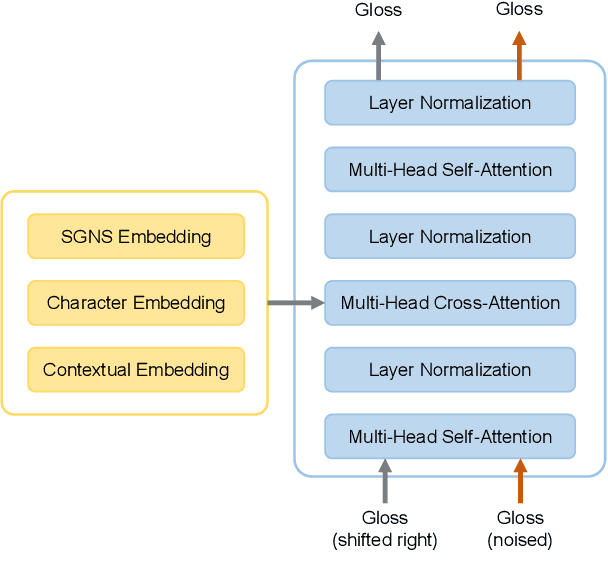
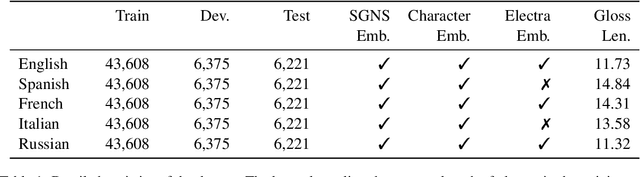
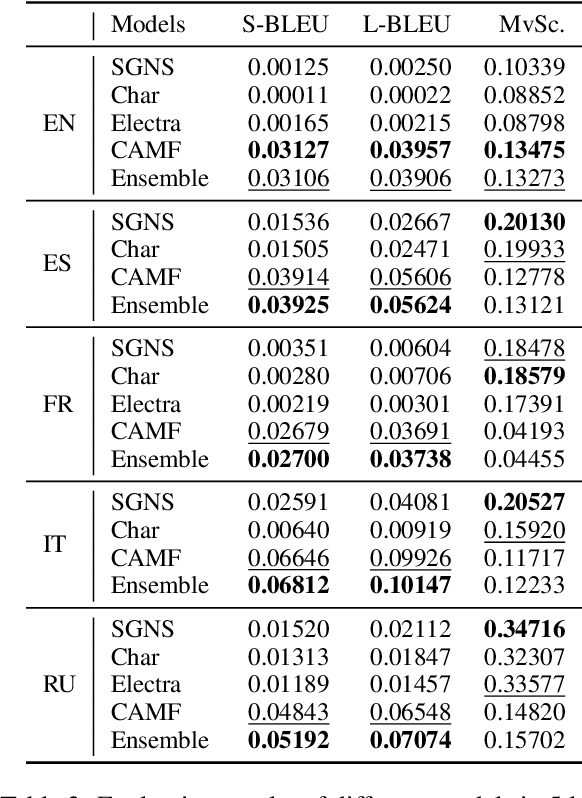
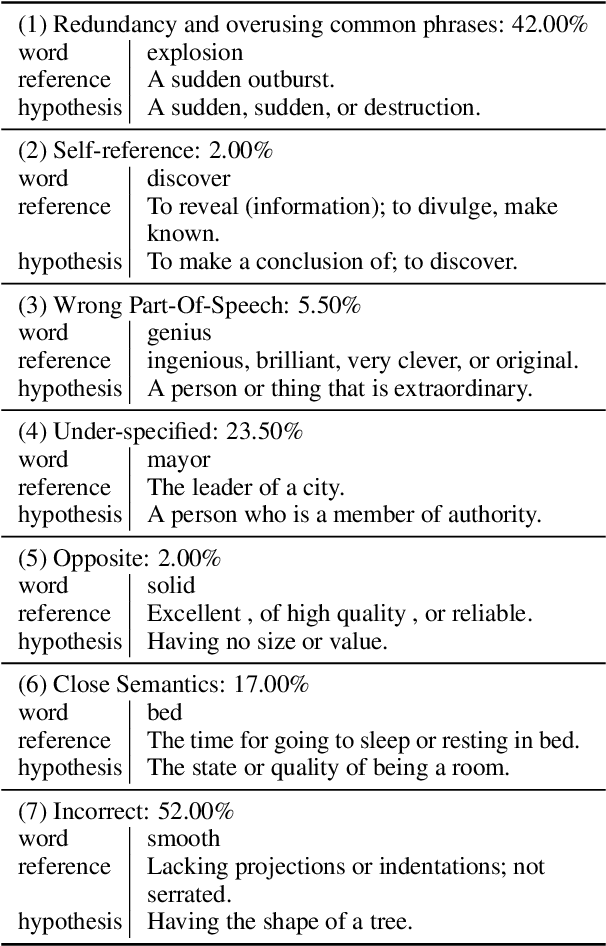
This paper describes the BLCU-ICALL system used in the SemEval-2022 Task 1 Comparing Dictionaries and Word Embeddings, the Definition Modeling subtrack, achieving 1st on Italian, 2nd on Spanish and Russian, and 3rd on English and French. We propose a transformer-based multitasking framework to explore the task. The framework integrates multiple embedding architectures through the cross-attention mechanism, and captures the structure of glosses through a masking language model objective. Additionally, we also investigate a simple but effective model ensembling strategy to further improve the robustness. The evaluation results show the effectiveness of our solution. We release our code at: https://github.com/blcuicall/SemEval2022-Task1-DM.
Multitasking Framework for Unsupervised Simple Definition Generation
Mar 24, 2022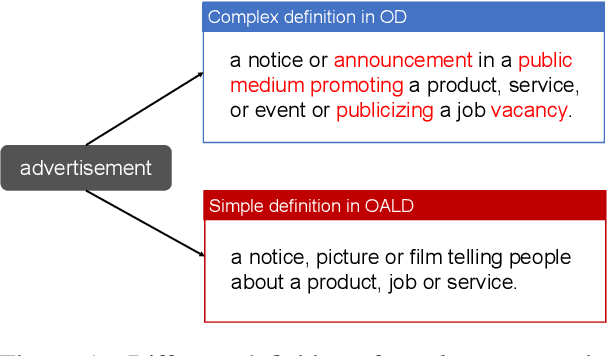
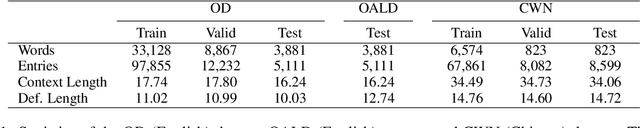
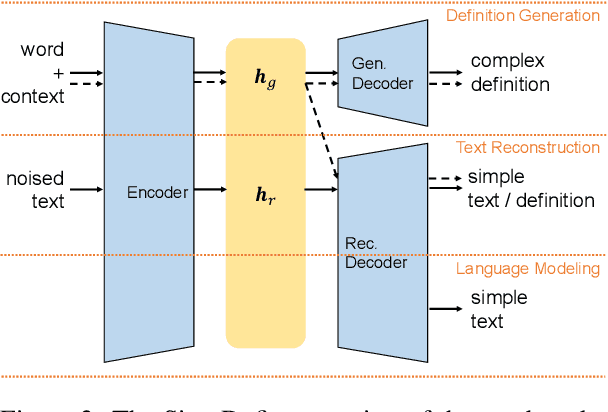
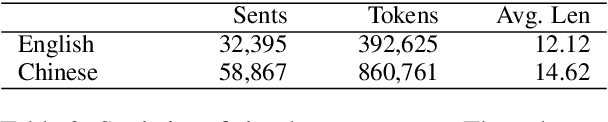
The definition generation task can help language learners by providing explanations for unfamiliar words. This task has attracted much attention in recent years. We propose a novel task of Simple Definition Generation (SDG) to help language learners and low literacy readers. A significant challenge of this task is the lack of learner's dictionaries in many languages, and therefore the lack of data for supervised training. We explore this task and propose a multitasking framework SimpDefiner that only requires a standard dictionary with complex definitions and a corpus containing arbitrary simple texts. We disentangle the complexity factors from the text by carefully designing a parameter sharing scheme between two decoders. By jointly training these components, the framework can generate both complex and simple definitions simultaneously. We demonstrate that the framework can generate relevant, simple definitions for the target words through automatic and manual evaluations on English and Chinese datasets. Our method outperforms the baseline model by a 1.77 SARI score on the English dataset, and raises the proportion of the low level (HSK level 1-3) words in Chinese definitions by 3.87%.
YACLC: A Chinese Learner Corpus with Multidimensional Annotation
Dec 30, 2021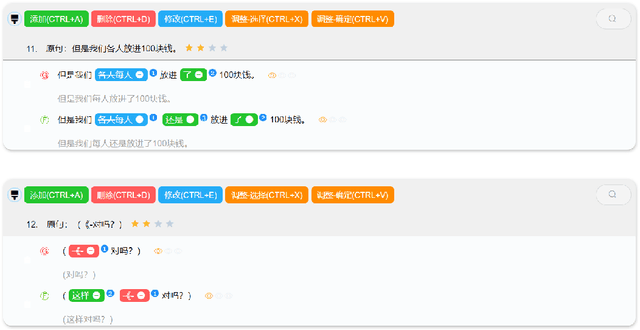
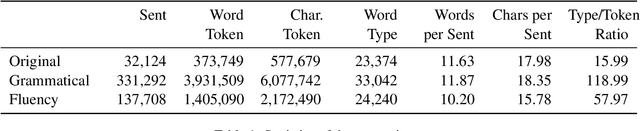
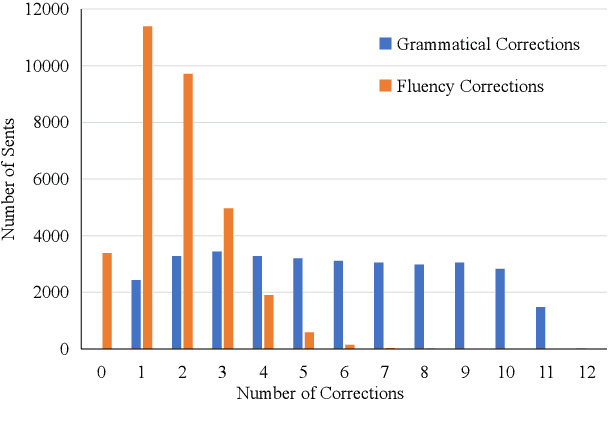
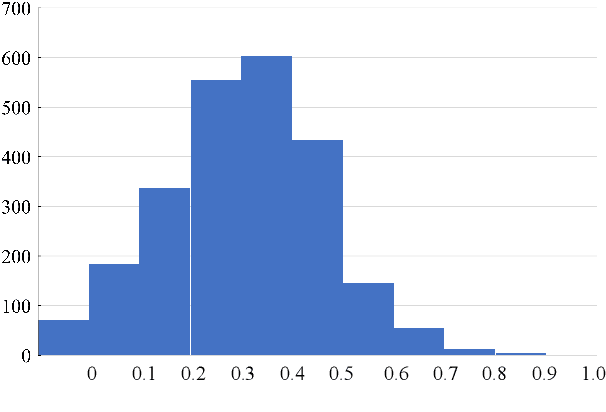
Learner corpus collects language data produced by L2 learners, that is second or foreign-language learners. This resource is of great relevance for second language acquisition research, foreign-language teaching, and automatic grammatical error correction. However, there is little focus on learner corpus for Chinese as Foreign Language (CFL) learners. Therefore, we propose to construct a large-scale, multidimensional annotated Chinese learner corpus. To construct the corpus, we first obtain a large number of topic-rich texts generated by CFL learners. Then we design an annotation scheme including a sentence acceptability score as well as grammatical error and fluency-based corrections. We build a crowdsourcing platform to perform the annotation effectively (https://yaclc.wenmind.net). We name the corpus YACLC (Yet Another Chinese Learner Corpus) and release it as part of the CUGE benchmark (http://cuge.baai.ac.cn). By analyzing the original sentences and annotations in the corpus, we found that YACLC has a considerable size and very high annotation quality. We hope this corpus can further enhance the studies on Chinese International Education and Chinese automatic grammatical error correction.
Neural Quality Estimation with Multiple Hypotheses for Grammatical Error Correction
May 10, 2021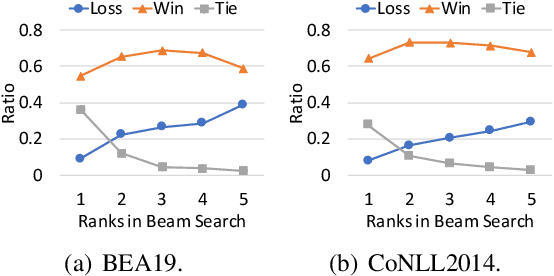
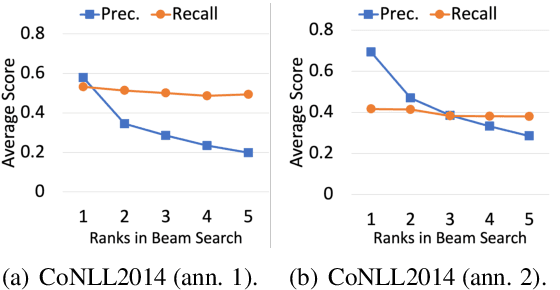

Grammatical Error Correction (GEC) aims to correct writing errors and help language learners improve their writing skills. However, existing GEC models tend to produce spurious corrections or fail to detect lots of errors. The quality estimation model is necessary to ensure learners get accurate GEC results and avoid misleading from poorly corrected sentences. Well-trained GEC models can generate several high-quality hypotheses through decoding, such as beam search, which provide valuable GEC evidence and can be used to evaluate GEC quality. However, existing models neglect the possible GEC evidence from different hypotheses. This paper presents the Neural Verification Network (VERNet) for GEC quality estimation with multiple hypotheses. VERNet establishes interactions among hypotheses with a reasoning graph and conducts two kinds of attention mechanisms to propagate GEC evidence to verify the quality of generated hypotheses. Our experiments on four GEC datasets show that VERNet achieves state-of-the-art grammatical error detection performance, achieves the best quality estimation results, and significantly improves GEC performance by reranking hypotheses. All data and source codes are available at https://github.com/thunlp/VERNet.
Few-Shot Domain Adaptation for Grammatical Error Correction via Meta-Learning
Jan 29, 2021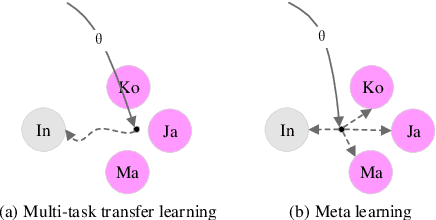
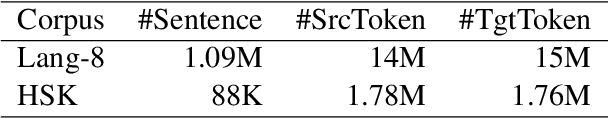
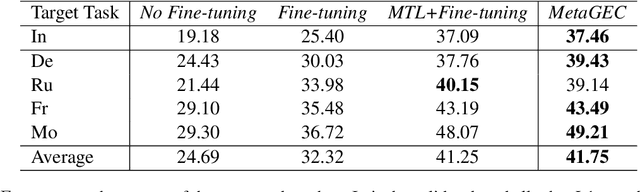
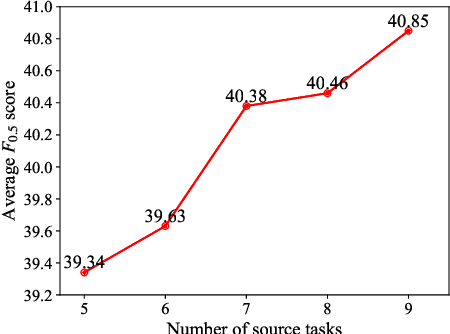
Most existing Grammatical Error Correction (GEC) methods based on sequence-to-sequence mainly focus on how to generate more pseudo data to obtain better performance. Few work addresses few-shot GEC domain adaptation. In this paper, we treat different GEC domains as different GEC tasks and propose to extend meta-learning to few-shot GEC domain adaptation without using any pseudo data. We exploit a set of data-rich source domains to learn the initialization of model parameters that facilitates fast adaptation on new resource-poor target domains. We adapt GEC model to the first language (L1) of the second language learner. To evaluate the proposed method, we use nine L1s as source domains and five L1s as target domains. Experiment results on the L1 GEC domain adaptation dataset demonstrate that the proposed approach outperforms the multi-task transfer learning baseline by 0.50 $F_{0.5}$ score on average and enables us to effectively adapt to a new L1 domain with only 200 parallel sentences.
Toward Cross-Lingual Definition Generation for Language Learners
Oct 12, 2020
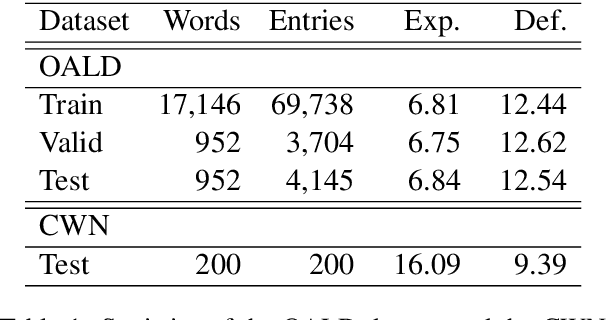
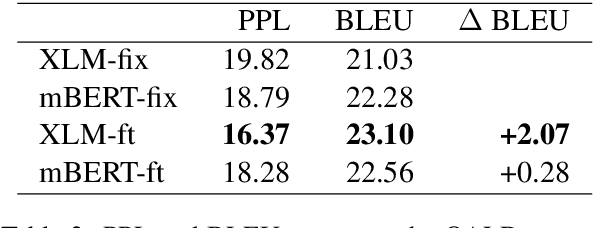
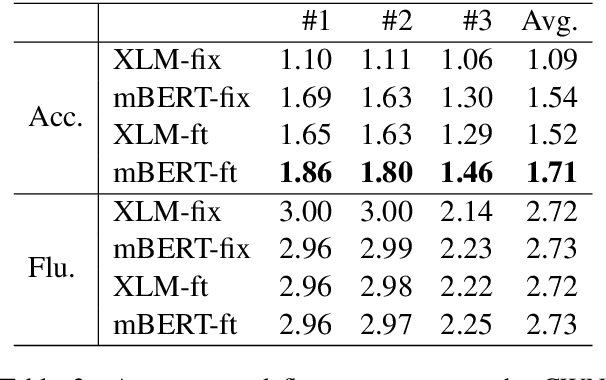
Generating dictionary definitions automatically can prove useful for language learners. However, it's still a challenging task of cross-lingual definition generation. In this work, we propose to generate definitions in English for words in various languages. To achieve this, we present a simple yet effective approach based on publicly available pretrained language models. In this approach, models can be directly applied to other languages after trained on the English dataset. We demonstrate the effectiveness of this approach on zero-shot definition generation. Experiments and manual analyses on newly constructed datasets show that our models have a strong cross-lingual transfer ability and can generate fluent English definitions for Chinese words. We further measure the lexical complexity of generated and reference definitions. The results show that the generated definitions are much simpler, which is more suitable for language learners.
Controllable Data Synthesis Method for Grammatical Error Correction
Oct 02, 2019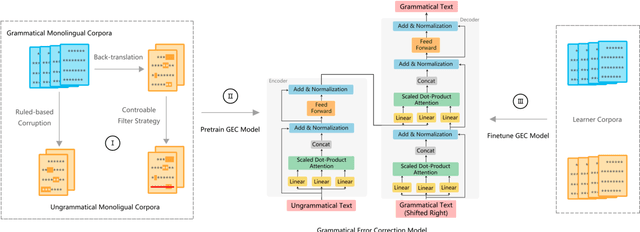


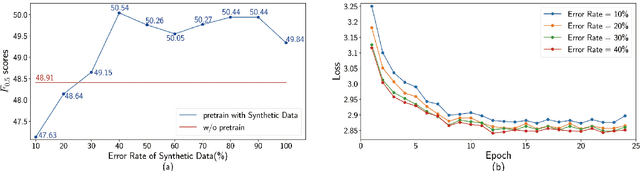
Due to the lack of parallel data in current Grammatical Error Correction (GEC) task, models based on Sequence to Sequence framework cannot be adequately trained to obtain higher performance. We propose two data synthesis methods which can control the error rate and the ratio of error types on synthetic data. The first approach is to corrupt each word in the monolingual corpus with a fixed probability, including replacement, insertion and deletion. Another approach is to train error generation models and further filtering the decoding results of the models. The experiments on different synthetic data show that the error rate is 40% and the ratio of error types is the same can improve the model performance better. Finally, we synthesize about 100 million data and achieve comparable performance as the state of the art, which uses twice as much data as we use.
Multi-task Learning for Low-resource Second Language Acquisition Modeling
Aug 25, 2019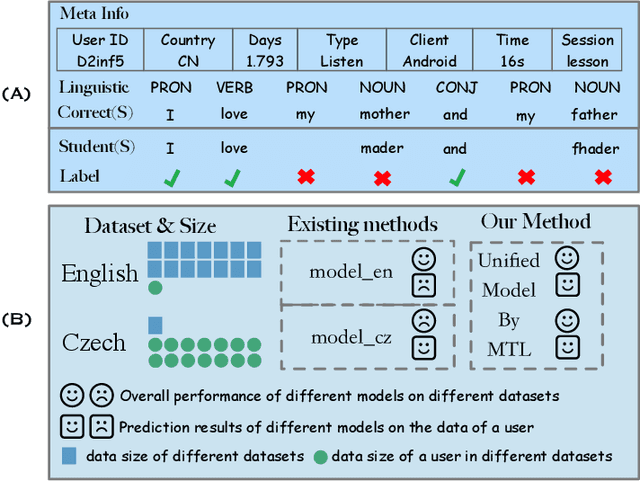
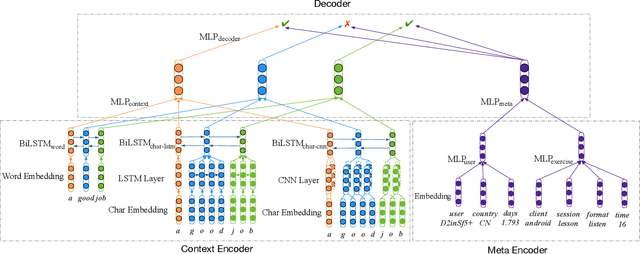
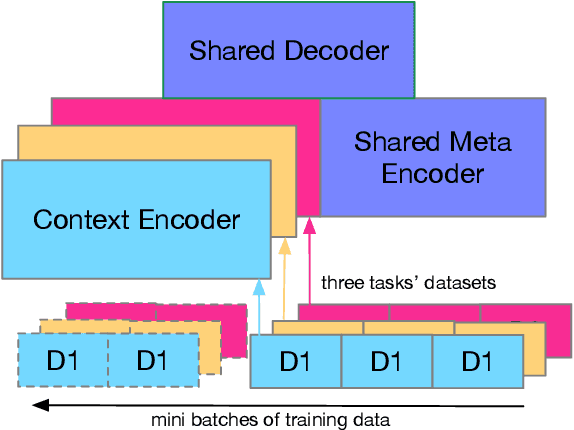
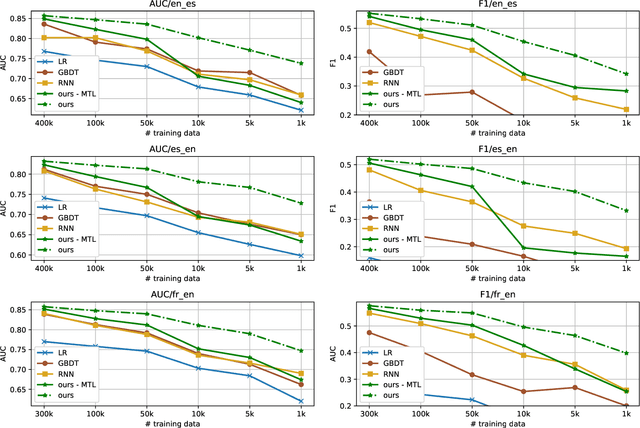
Second language acquisition (SLA) modeling is to predict whether second language learners could correctly answer the questions according to what they have learned. It is a fundamental building block of the personalized learning system and has attracted more and more attention recently. However, as far as we know, almost all existing methods cannot work well in low-resource scenarios because lacking of training data. Fortunately, there are some latent common patterns among different language-learning tasks, which gives us an opportunity to solve the low-resource SLA modeling problem. Inspired by this idea, in this paper, we propose a novel SLA modeling method, which learns the latent common patterns among different language-learning datasets by multi-task learning and are further applied to improving the prediction performance in low-resource scenarios. Extensive experiments show that the proposed method performs much better than the state-of-the-art baselines in the low-resource scenario. Meanwhile, it also obtains improvement slightly in the non-low-resource scenario.
Incorporating Sememes into Chinese Definition Modeling
May 16, 2019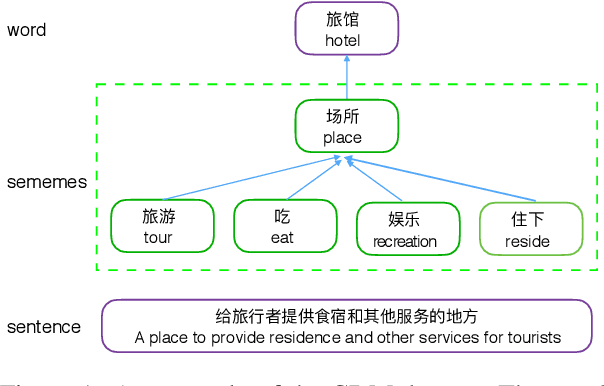
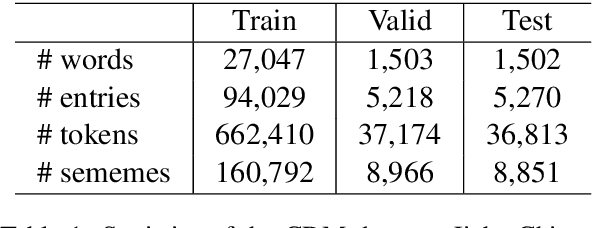
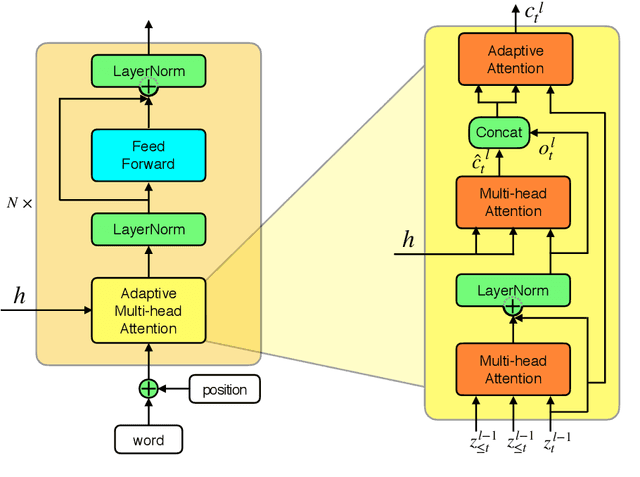
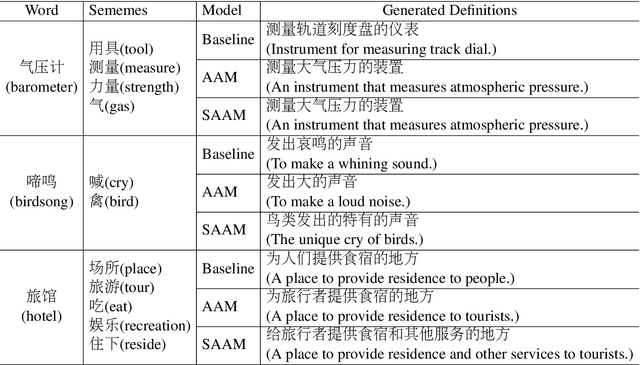
Chinese definition modeling is a challenging task that generates a dictionary definition in Chinese for a given Chinese word. To accomplish this task, we construct the Chinese Definition Modeling Corpus (CDM), which contains triples of word, sememes and the corresponding definition. We present two novel models to improve Chinese definition modeling: the Adaptive-Attention model (AAM) and the Self- and Adaptive-Attention Model (SAAM). AAM successfully incorporates sememes for generating the definition with an adaptive attention mechanism. It has the capability to decide which sememes to focus on and when to pay attention to sememes. SAAM further replaces recurrent connections in AAM with self-attention and relies entirely on the attention mechanism, reducing the path length between word, sememes and definition. Experiments on CDM demonstrate that by incorporating sememes, our best proposed model can outperform the state-of-the-art method by +6.0 BLEU.