 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGARNet: Global-Aware Multi-View 3D Reconstruction Network and the Cost-Performance Tradeoff
Nov 04, 2022Deep learning technology has made great progress in multi-view 3D reconstruction tasks. At present, most mainstream solutions establish the mapping between views and shape of an object by assembling the networks of 2D encoder and 3D decoder as the basic structure while they adopt different approaches to obtain aggregation of features from several views. Among them, the methods using attention-based fusion perform better and more stable than the others, however, they still have an obvious shortcoming -- the strong independence of each view during predicting the weights for merging leads to a lack of adaption of the global state. In this paper, we propose a global-aware attention-based fusion approach that builds the correlation between each branch and the global to provide a comprehensive foundation for weights inference. In order to enhance the ability of the network, we introduce a novel loss function to supervise the shape overall and propose a dynamic two-stage training strategy that can effectively adapt to all reconstructors with attention-based fusion. Experiments on ShapeNet verify that our method outperforms existing SOTA methods while the amount of parameters is far less than the same type of algorithm, Pix2Vox++. Furthermore, we propose a view-reduction method based on maximizing diversity and discuss the cost-performance tradeoff of our model to achieve a better performance when facing heavy input amount and limited computational cost.
LeVoice ASR Systems for the ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge
Oct 17, 2022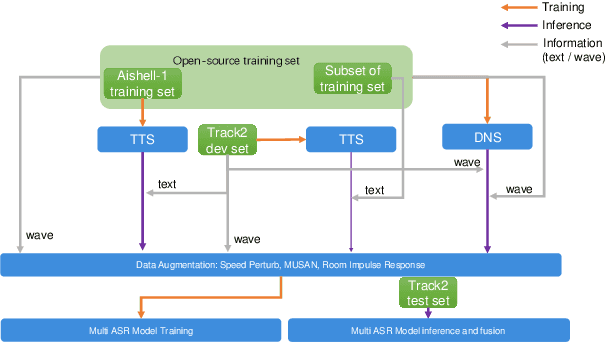
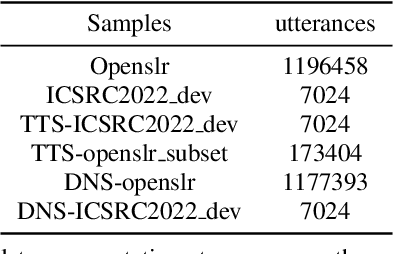
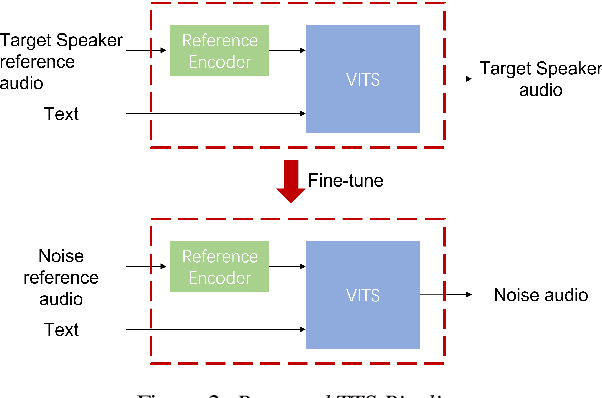
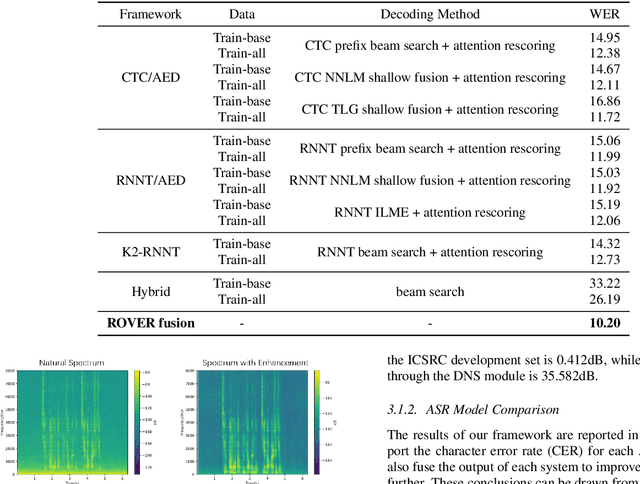
This paper describes LeVoice automatic speech recognition systems to track2 of intelligent cockpit speech recognition challenge 2022. Track2 is a speech recognition task without limits on the scope of model size. Our main points include deep learning based speech enhancement, text-to-speech based speech generation, training data augmentation via various techniques and speech recognition model fusion. We compared and fused the hybrid architecture and two kinds of end-to-end architecture. For end-to-end modeling, we used models based on connectionist temporal classification/attention-based encoder-decoder architecture and recurrent neural network transducer/attention-based encoder-decoder architecture. The performance of these models is evaluated with an additional language model to improve word error rates. As a result, our system achieved 10.2\% character error rate on the challenge test set data and ranked third place among the submitted systems in the challenge.
Unsupervised Dense Nuclei Detection and Segmentation with Prior Self-activation Map For Histology Images
Oct 14, 2022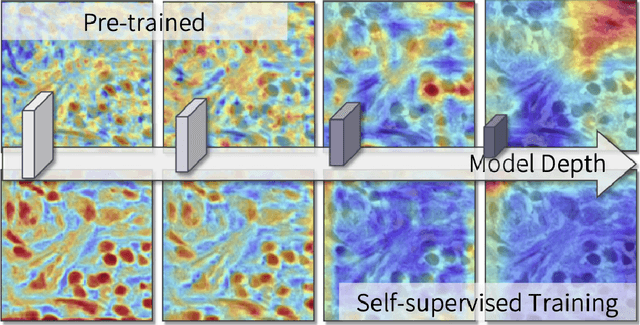
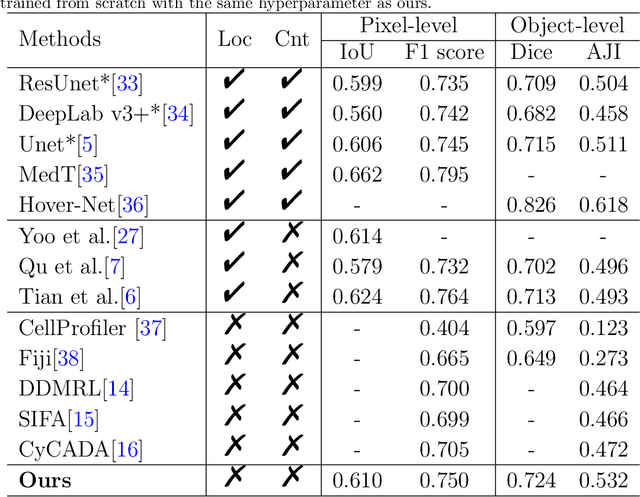
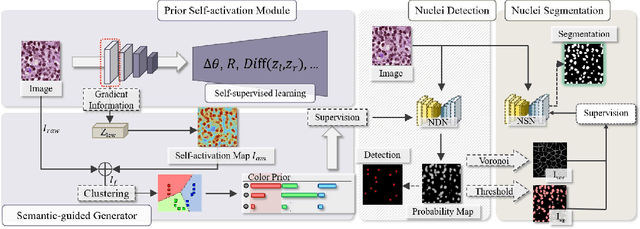

The success of supervised deep learning models in medical image segmentation relies on detailed annotations. However, labor-intensive manual labeling is costly and inefficient, especially in dense object segmentation. To this end, we propose a self-supervised learning based approach with a Prior Self-activation Module (PSM) that generates self-activation maps from the input images to avoid labeling costs and further produce pseudo masks for the downstream task. To be specific, we firstly train a neural network using self-supervised learning and utilize the gradient information in the shallow layers of the network to generate self-activation maps. Afterwards, a semantic-guided generator is then introduced as a pipeline to transform visual representations from PSM to pixel-level semantic pseudo masks for downstream tasks. Furthermore, a two-stage training module, consisting of a nuclei detection network and a nuclei segmentation network, is adopted to achieve the final segmentation. Experimental results show the effectiveness on two public pathological datasets. Compared with other fully-supervised and weakly-supervised methods, our method can achieve competitive performance without any manual annotations.
TC-SKNet with GridMask for Low-complexity Classification of Acoustic scene
Oct 05, 2022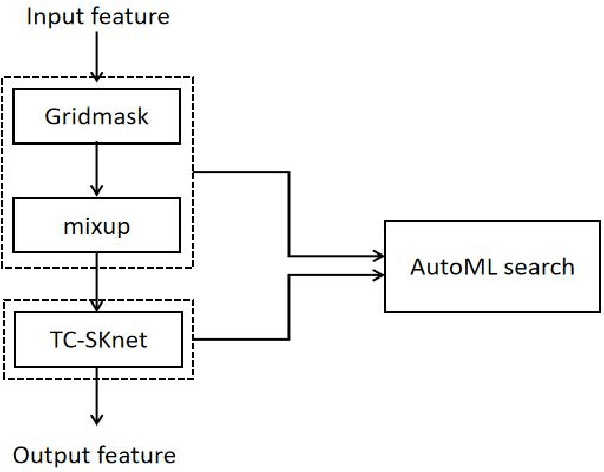

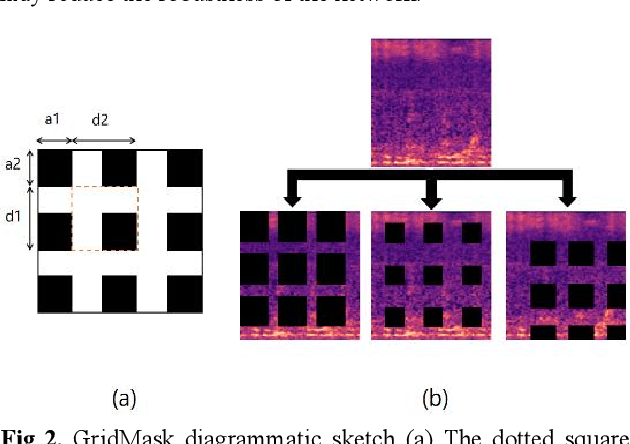
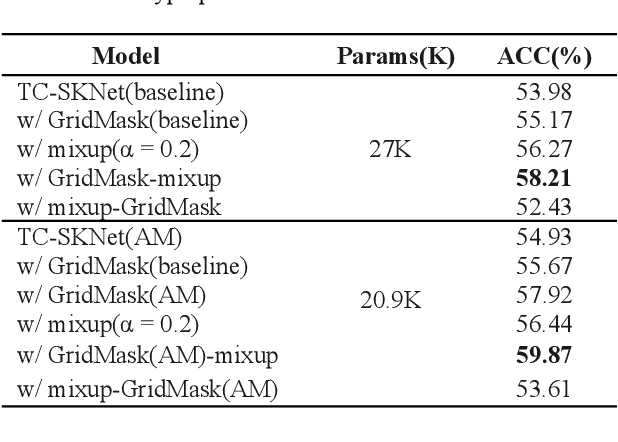
Convolution neural networks (CNNs) have good performance in low-complexity classification tasks such as acoustic scene classifications (ASCs). However, there are few studies on the relationship between the length of target speech and the size of the convolution kernels. In this paper, we combine Selective Kernel Network with Temporal-Convolution (TC-SKNet) to adjust the receptive field of convolution kernels to solve the problem of variable length of target voice while keeping low-complexity. GridMask is a data augmentation strategy by masking part of the raw data or feature area. It can enhance the generalization of the model as the role of dropout. In our experiments, the performance gain brought by GridMask is stronger than spectrum augmentation in ASCs. Finally, we adopt AutoML to search best structure of TC-SKNet and hyperparameters of GridMask for improving the classification performance. As a result, a peak accuracy of 59.87% TC-SKNet is equivalent to that of SOTA, but the parameters only use 20.9 K.
From Local to Global: Spectral-Inspired Graph Neural Networks
Sep 24, 2022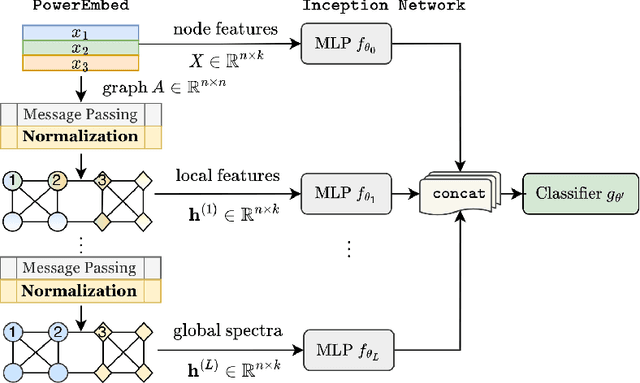
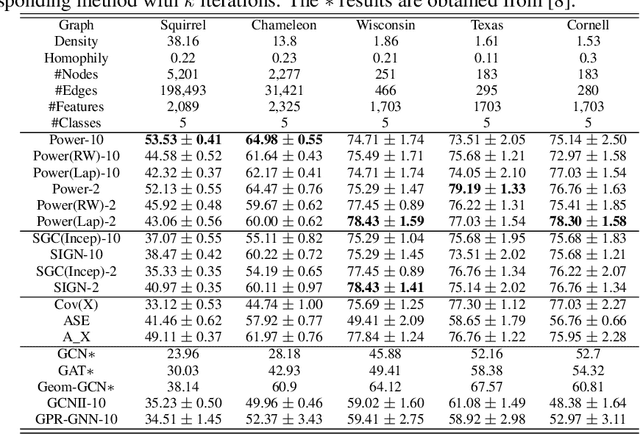
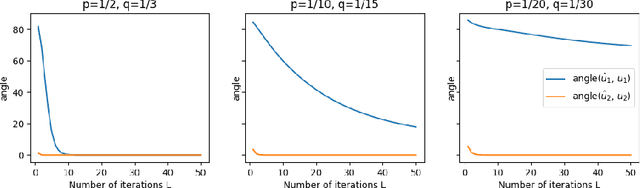
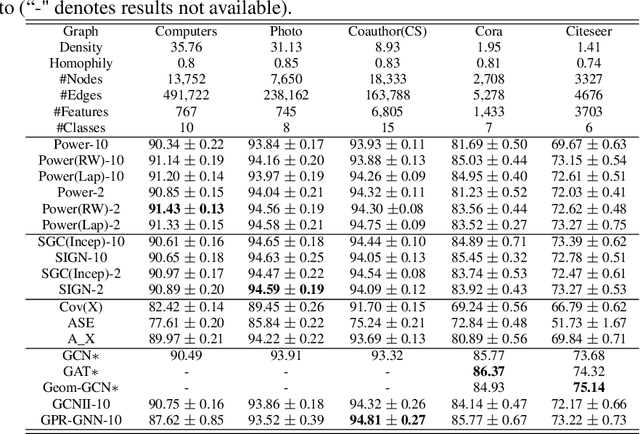
Graph Neural Networks (GNNs) are powerful deep learning methods for Non-Euclidean data. Popular GNNs are message-passing algorithms (MPNNs) that aggregate and combine signals in a local graph neighborhood. However, shallow MPNNs tend to miss long-range signals and perform poorly on some heterophilous graphs, while deep MPNNs can suffer from issues like over-smoothing or over-squashing. To mitigate such issues, existing works typically borrow normalization techniques from training neural networks on Euclidean data or modify the graph structures. Yet these approaches are not well-understood theoretically and could increase the overall computational complexity. In this work, we draw inspirations from spectral graph embedding and propose $\texttt{PowerEmbed}$ -- a simple layer-wise normalization technique to boost MPNNs. We show $\texttt{PowerEmbed}$ can provably express the top-$k$ leading eigenvectors of the graph operator, which prevents over-smoothing and is agnostic to the graph topology; meanwhile, it produces a list of representations ranging from local features to global signals, which avoids over-squashing. We apply $\texttt{PowerEmbed}$ in a wide range of simulated and real graphs and demonstrate its competitive performance, particularly for heterophilous graphs.
Adaptive Decision Making at the Intersection for Autonomous Vehicles Based on Skill Discovery
Jul 24, 2022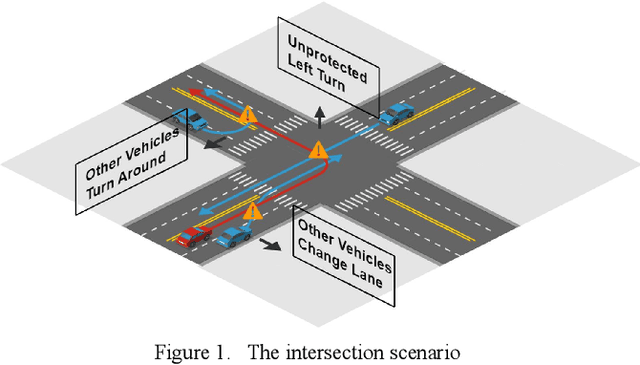
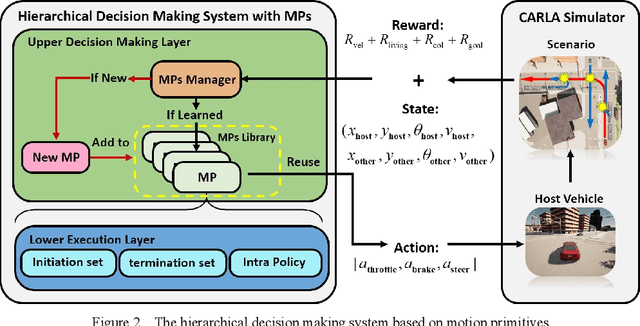
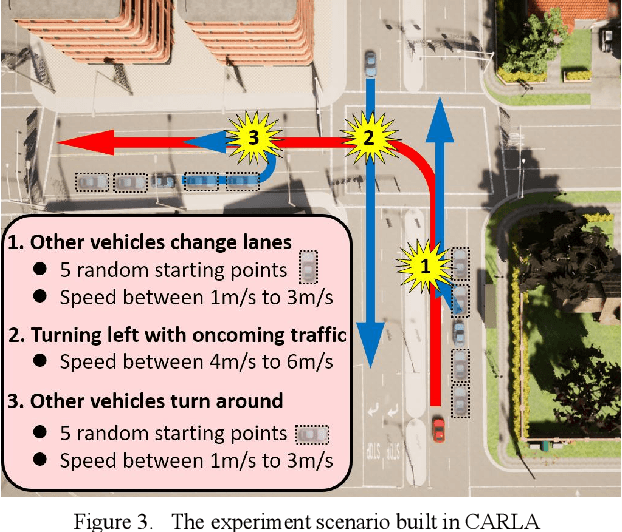
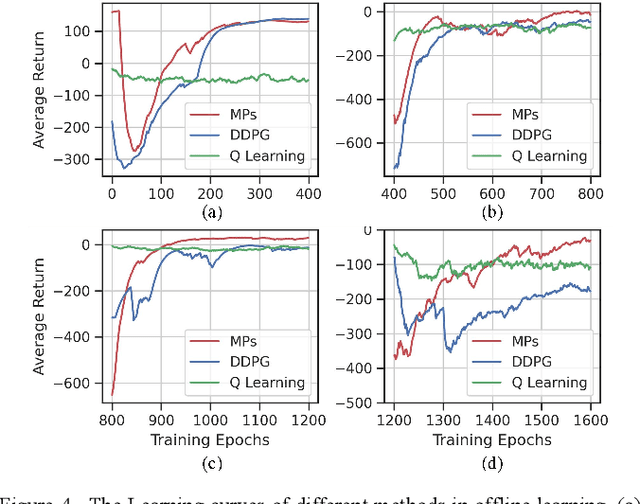
In urban environments, the complex and uncertain intersection scenarios are challenging for autonomous driving. To ensure safety, it is crucial to develop an adaptive decision making system that can handle the interaction with other vehicles. Manually designed model-based methods are reliable in common scenarios. But in uncertain environments, they are not reliable, so learning-based methods are proposed, especially reinforcement learning (RL) methods. However, current RL methods need retraining when the scenarios change. In other words, current RL methods cannot reuse accumulated knowledge. They forget learned knowledge when new scenarios are given. To solve this problem, we propose a hierarchical framework that can autonomously accumulate and reuse knowledge. The proposed method combines the idea of motion primitives (MPs) with hierarchical reinforcement learning (HRL). It decomposes complex problems into multiple basic subtasks to reduce the difficulty. The proposed method and other baseline methods are tested in a challenging intersection scenario based on the CARLA simulator. The intersection scenario contains three different subtasks that can reflect the complexity and uncertainty of real traffic flow. After offline learning and testing, the proposed method is proved to have the best performance among all methods.
End-to-end cell recognition by point annotation
Jul 01, 2022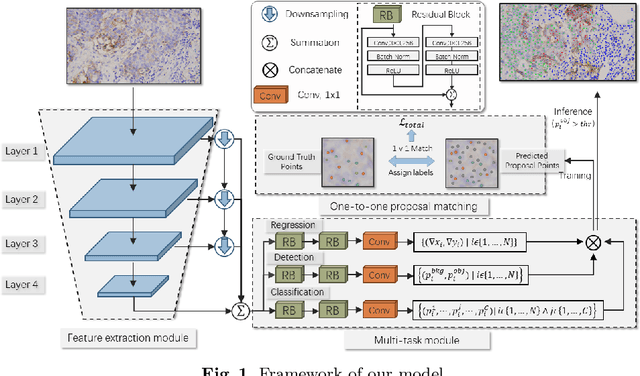
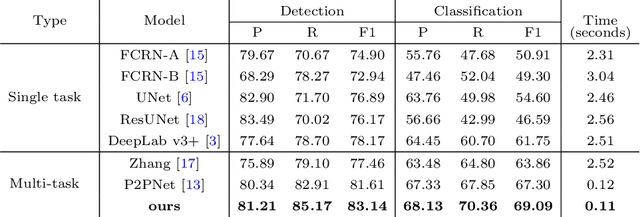

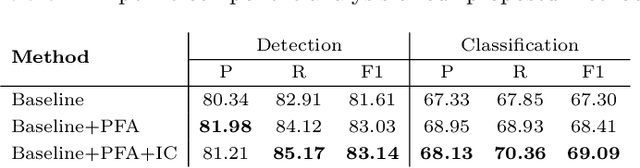
Reliable quantitative analysis of immunohistochemical staining images requires accurate and robust cell detection and classification. Recent weakly-supervised methods usually estimate probability density maps for cell recognition. However, in dense cell scenarios, their performance can be limited by pre- and post-processing as it is impossible to find a universal parameter setting. In this paper, we introduce an end-to-end framework that applies direct regression and classification for preset anchor points. Specifically, we propose a pyramidal feature aggregation strategy to combine low-level features and high-level semantics simultaneously, which provides accurate cell recognition for our purely point-based model. In addition, an optimized cost function is designed to adapt our multi-task learning framework by matching ground truth and predicted points. The experimental results demonstrate the superior accuracy and efficiency of the proposed method, which reveals the high potentiality in assisting pathologist assessments.
ChrSNet: Chromosome Straightening using Self-attention Guided Networks
Jul 01, 2022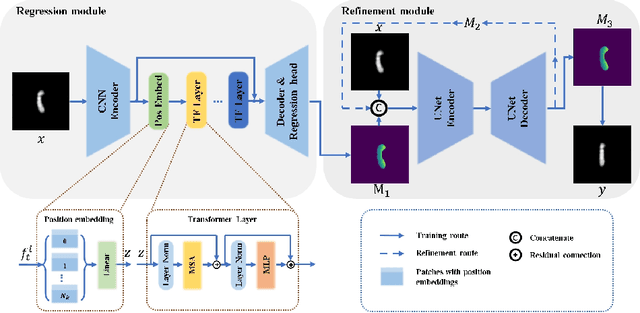

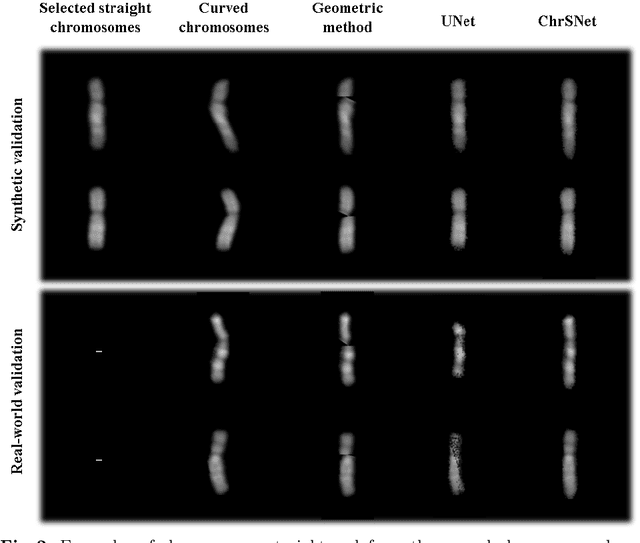
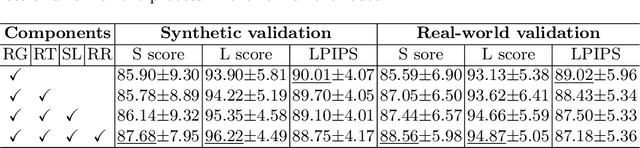
Karyotyping is an important procedure to assess the possible existence of chromosomal abnormalities. However, because of the non-rigid nature, chromosomes are usually heavily curved in microscopic images and such deformed shapes hinder the chromosome analysis for cytogeneticists. In this paper, we present a self-attention guided framework to erase the curvature of chromosomes. The proposed framework extracts spatial information and local textures to preserve banding patterns in a regression module. With complementary information from the bent chromosome, a refinement module is designed to further improve fine details. In addition, we propose two dedicated geometric constraints to maintain the length and restore the distortion of chromosomes. To train our framework, we create a synthetic dataset where curved chromosomes are generated from the real-world straight chromosomes by grid-deformation. Quantitative and qualitative experiments are conducted on synthetic and real-world data. Experimental results show that our proposed method can effectively straighten bent chromosomes while keeping banding details and length.
Benchmarking the Robustness of Deep Neural Networks to Common Corruptions in Digital Pathology
Jun 30, 2022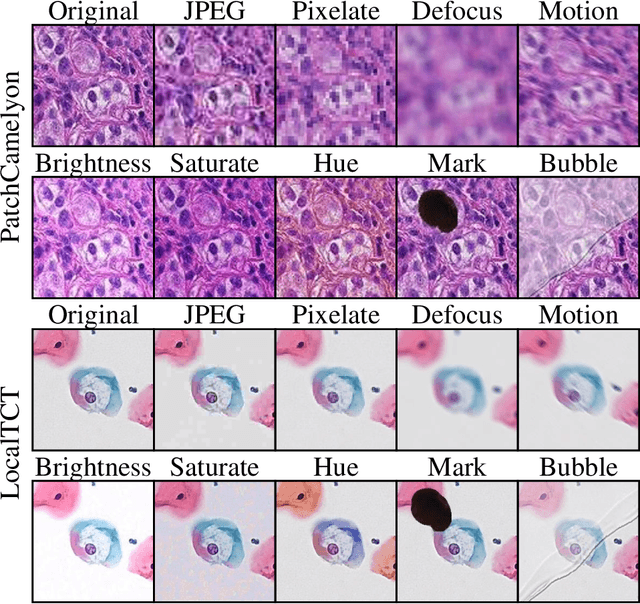
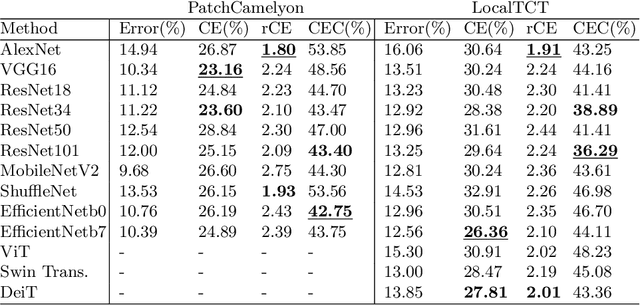

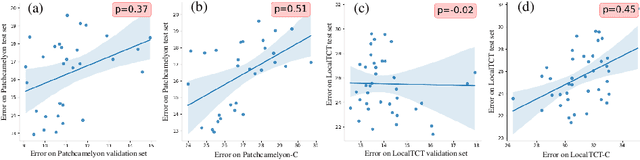
When designing a diagnostic model for a clinical application, it is crucial to guarantee the robustness of the model with respect to a wide range of image corruptions. Herein, an easy-to-use benchmark is established to evaluate how deep neural networks perform on corrupted pathology images. Specifically, corrupted images are generated by injecting nine types of common corruptions into validation images. Besides, two classification and one ranking metrics are designed to evaluate the prediction and confidence performance under corruption. Evaluated on two resulting benchmark datasets, we find that (1) a variety of deep neural network models suffer from a significant accuracy decrease (double the error on clean images) and the unreliable confidence estimation on corrupted images; (2) A low correlation between the validation and test errors while replacing the validation set with our benchmark can increase the correlation. Our codes are available on https://github.com/superjamessyx/robustness_benchmark.
Model-based Offline Imitation Learning with Non-expert Data
Jun 11, 2022


Although Behavioral Cloning (BC) in theory suffers compounding errors, its scalability and simplicity still makes it an attractive imitation learning algorithm. In contrast, imitation approaches with adversarial training typically does not share the same problem, but necessitates interactions with the environment. Meanwhile, most imitation learning methods only utilises optimal datasets, which could be significantly more expensive to obtain than its suboptimal counterpart. A question that arises is, can we utilise the suboptimal dataset in a principled manner, which otherwise would have been idle? We propose a scalable model-based offline imitation learning algorithmic framework that leverages datasets collected by both suboptimal and optimal policies, and show that its worst case suboptimality becomes linear in the time horizon with respect to the expert samples. We empirically validate our theoretical results and show that the proposed method \textit{always} outperforms BC in the low data regime on simulated continuous control domains