 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBCT: Tree-Based Feature-Aware Binning for Individual Uncertainty Calibration
Feb 09, 2022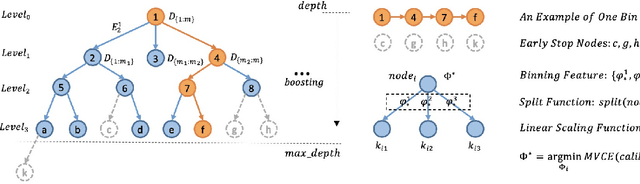
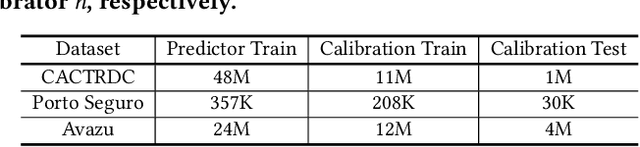
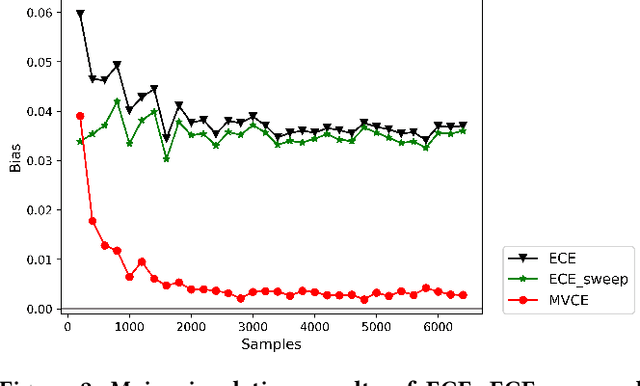
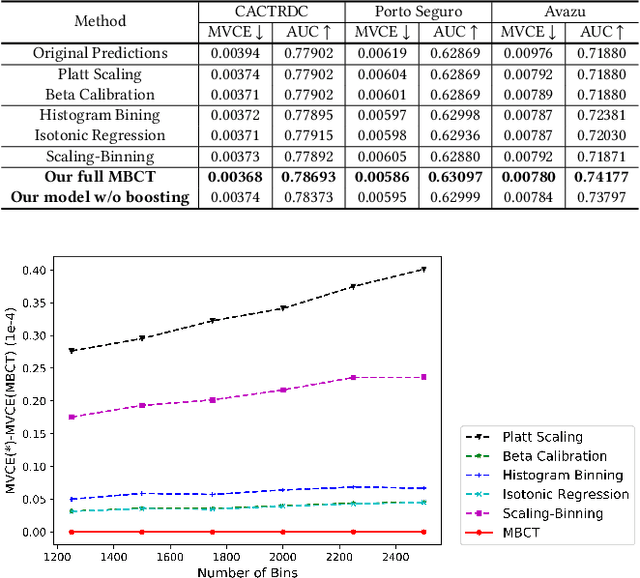
Most machine learning classifiers only concern classification accuracy, while certain applications (such as medical diagnosis, meteorological forecasting, and computation advertising) require the model to predict the true probability, known as a calibrated estimate. In previous work, researchers have developed several calibration methods to post-process the outputs of a predictor to obtain calibrated values, such as binning and scaling methods. Compared with scaling, binning methods are shown to have distribution-free theoretical guarantees, which motivates us to prefer binning methods for calibration. However, we notice that existing binning methods have several drawbacks: (a) the binning scheme only considers the original prediction values, thus limiting the calibration performance; and (b) the binning approach is non-individual, mapping multiple samples in a bin to the same value, and thus is not suitable for order-sensitive applications. In this paper, we propose a feature-aware binning framework, called Multiple Boosting Calibration Trees (MBCT), along with a multi-view calibration loss to tackle the above issues. Our MBCT optimizes the binning scheme by the tree structures of features, and adopts a linear function in a tree node to achieve individual calibration. Our MBCT is non-monotonic, and has the potential to improve order accuracy, due to its learnable binning scheme and the individual calibration. We conduct comprehensive experiments on three datasets in different fields. Results show that our method outperforms all competing models in terms of both calibration error and order accuracy. We also conduct simulation experiments, justifying that the proposed multi-view calibration loss is a better metric in modeling calibration error.
An Empirical Study on the Overlapping Problem of Open-Domain Dialogue Datasets
Jan 17, 2022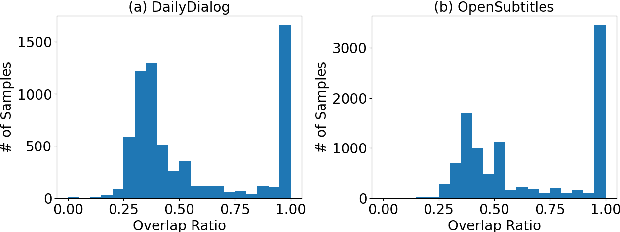

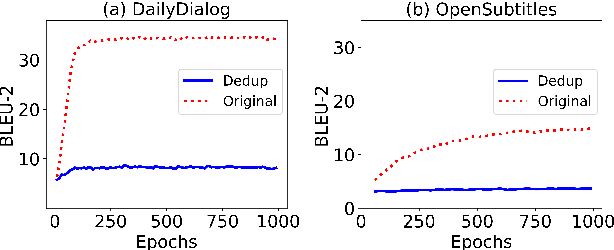

Open-domain dialogue systems aim to converse with humans through text, and its research has heavily relied on benchmark datasets. In this work, we first identify the overlapping problem in DailyDialog and OpenSubtitles, two popular open-domain dialogue benchmark datasets. Our systematic analysis then shows that such overlapping can be exploited to obtain fake state-of-the-art performance. Finally, we address this issue by cleaning these datasets and setting up a proper data processing procedure for future research.
Search and Learn: Improving Semantic Coverage for Data-to-Text Generation
Dec 06, 2021
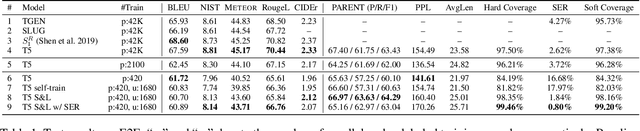
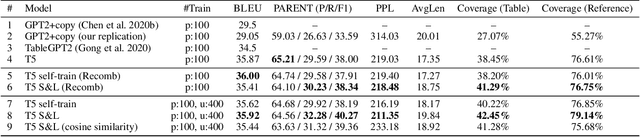

Data-to-text generation systems aim to generate text descriptions based on input data (often represented in the tabular form). A typical system uses huge training samples for learning the correspondence between tables and texts. However, large training sets are expensive to obtain, limiting the applicability of these approaches in real-world scenarios. In this work, we focus on few-shot data-to-text generation. We observe that, while fine-tuned pretrained language models may generate plausible sentences, they suffer from the low semantic coverage problem in the few-shot setting. In other words, important input slots tend to be missing in the generated text. To this end, we propose a search-and-learning approach that leverages pretrained language models but inserts the missing slots to improve the semantic coverage. We further fine-tune our system based on the search results to smooth out the search noise, yielding better-quality text and improving inference efficiency to a large extent. Experiments show that our model achieves high performance on E2E and WikiBio datasets. Especially, we cover 98.35% of input slots on E2E, largely alleviating the low coverage problem.
Non-Autoregressive Translation with Layer-Wise Prediction and Deep Supervision
Oct 14, 2021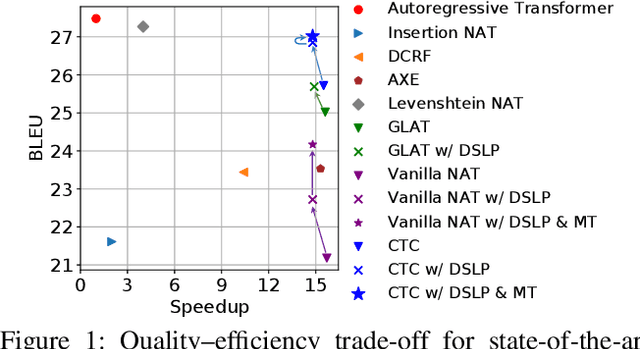
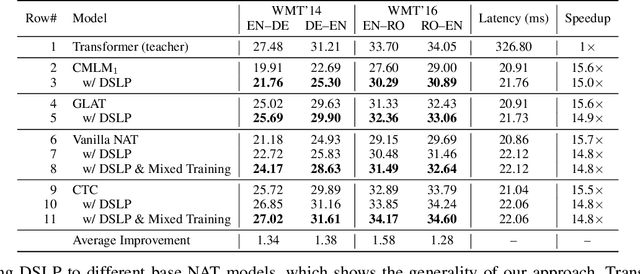
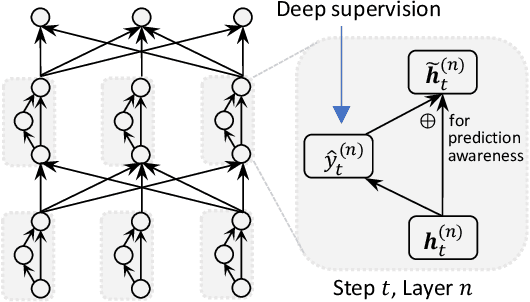
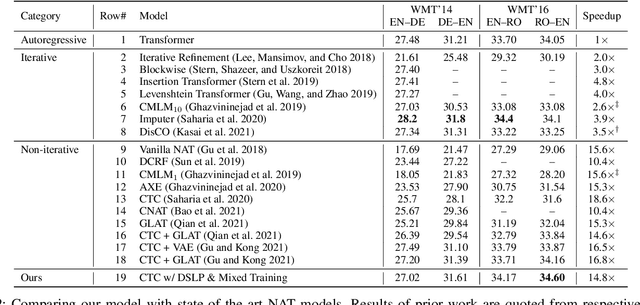
How do we perform efficient inference while retaining high translation quality? Existing neural machine translation models, such as Transformer, achieve high performance, but they decode words one by one, which is inefficient. Recent non-autoregressive translation models speed up the inference, but their quality is still inferior. In this work, we propose DSLP, a highly efficient and high-performance model for machine translation. The key insight is to train a non-autoregressive Transformer with Deep Supervision and feed additional Layer-wise Predictions. We conducted extensive experiments on four translation tasks (both directions of WMT'14 EN-DE and WMT'16 EN-RO). Results show that our approach consistently improves the BLEU scores compared with respective base models. Specifically, our best variant outperforms the autoregressive model on three translation tasks, while being 14.8 times more efficient in inference.
Simulated annealing for optimization of graphs and sequences
Oct 01, 2021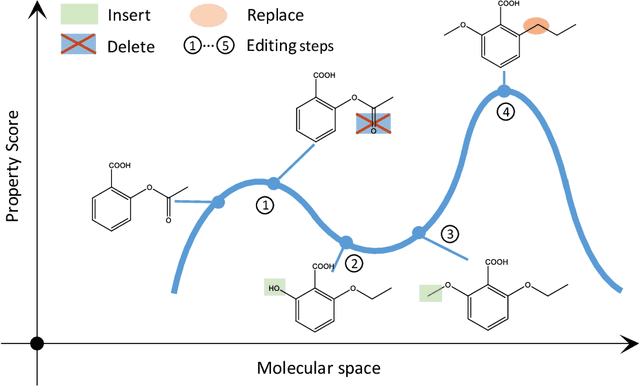
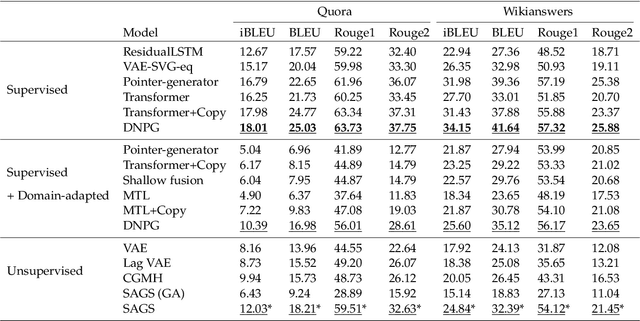
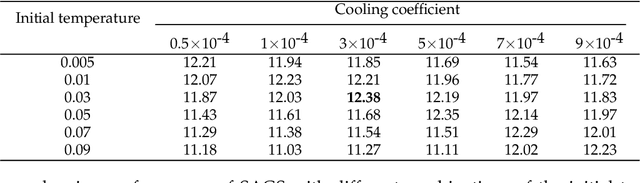
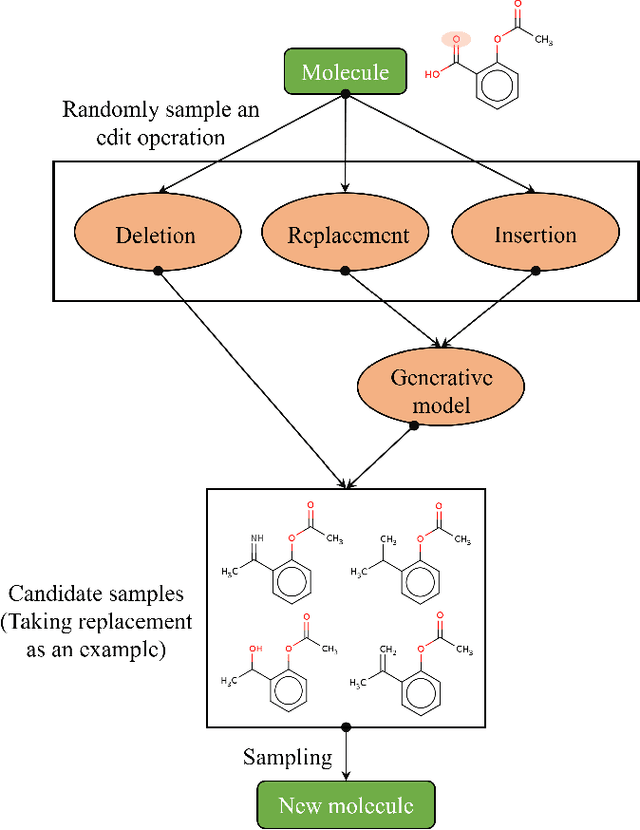
Optimization of discrete structures aims at generating a new structure with the better property given an existing one, which is a fundamental problem in machine learning. Different from the continuous optimization, the realistic applications of discrete optimization (e.g., text generation) are very challenging due to the complex and long-range constraints, including both syntax and semantics, in discrete structures. In this work, we present SAGS, a novel Simulated Annealing framework for Graph and Sequence optimization. The key idea is to integrate powerful neural networks into metaheuristics (e.g., simulated annealing, SA) to restrict the search space in discrete optimization. We start by defining a sophisticated objective function, involving the property of interest and pre-defined constraints (e.g., grammar validity). SAGS searches from the discrete space towards this objective by performing a sequence of local edits, where deep generative neural networks propose the editing content and thus can control the quality of editing. We evaluate SAGS on paraphrase generation and molecule generation for sequence optimization and graph optimization, respectively. Extensive results show that our approach achieves state-of-the-art performance compared with existing paraphrase generation methods in terms of both automatic and human evaluations. Further, SAGS also significantly outperforms all the previous methods in molecule generation.
* This article is an accepted manuscript of Neurocomputing. arXiv admin note: substantial text overlap with arXiv:1909.03588
Simulated Annealing for Emotional Dialogue Systems
Sep 22, 2021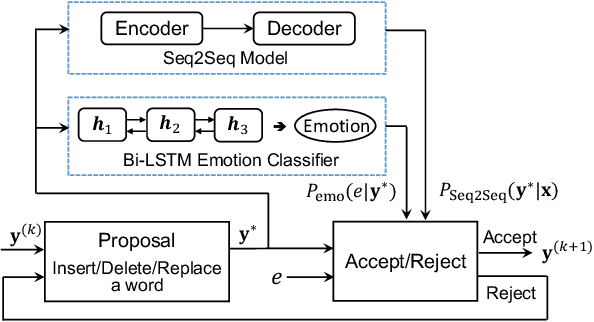
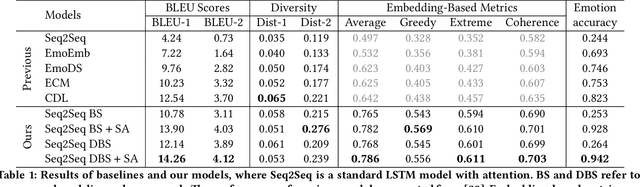
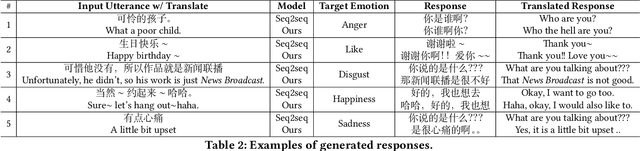
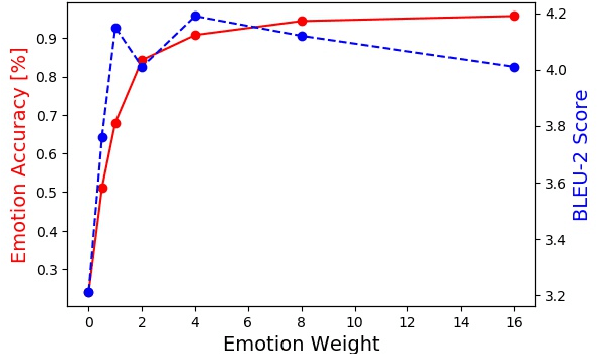
Explicitly modeling emotions in dialogue generation has important applications, such as building empathetic personal companions. In this study, we consider the task of expressing a specific emotion for dialogue generation. Previous approaches take the emotion as an input signal, which may be ignored during inference. We instead propose a search-based emotional dialogue system by simulated annealing (SA). Specifically, we first define a scoring function that combines contextual coherence and emotional correctness. Then, SA iteratively edits a general response and searches for a sentence with a higher score, enforcing the presence of the desired emotion. We evaluate our system on the NLPCC2017 dataset. Our proposed method shows 12% improvements in emotion accuracy compared with the previous state-of-the-art method, without hurting the generation quality (measured by BLEU).
Weakly Supervised Explainable Phrasal Reasoning with Neural Fuzzy Logic
Sep 18, 2021
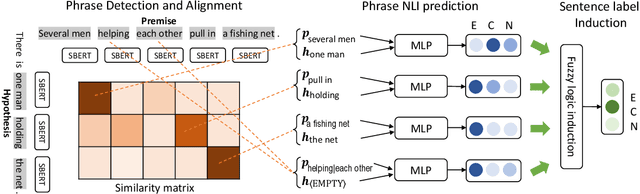
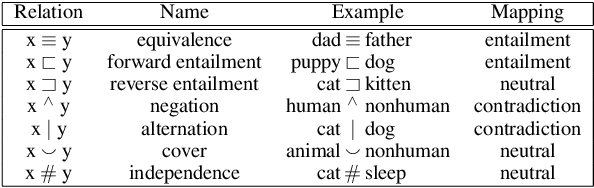

Natural language inference (NLI) aims to determine the logical relationship between two sentences among the target labels Entailment, Contradiction, and Neutral. In recent years, deep learning models have become a prevailing approach to NLI, but they lack interpretability and explainability. In this work, we address the explainability for NLI by weakly supervised logical reasoning, and propose an Explainable Phrasal Reasoning (EPR) approach. Our model first detects phrases as the semantic unit and aligns corresponding phrases. Then, the model predicts the NLI label for the aligned phrases, and induces the sentence label by fuzzy logic formulas. Our EPR is almost everywhere differentiable and thus the system can be trained end-to-end in a weakly supervised manner. We annotated a corpus and developed a set of metrics to evaluate phrasal reasoning. Results show that our EPR yields much more meaningful explanations in terms of F scores than previous studies. To the best of our knowledge, we are the first to develop a weakly supervised phrasal reasoning model for the NLI task.
Semi-Supervised and Unsupervised Sense Annotation via Translations
Jun 11, 2021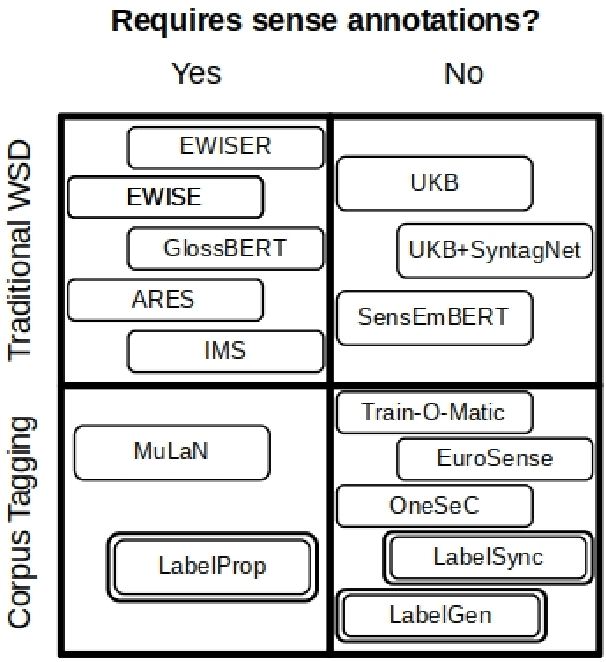
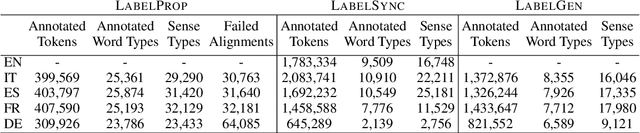
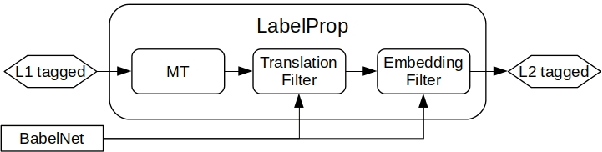
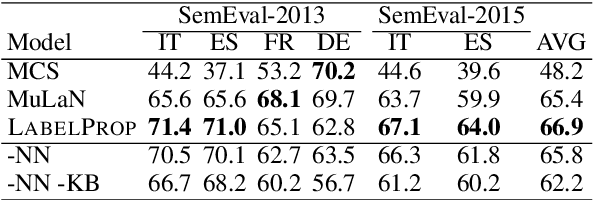
Acquisition of multilingual training data continues to be a challenge in word sense disambiguation (WSD). To address this problem, unsupervised approaches have been developed in recent years that automatically generate sense annotations suitable for training supervised WSD systems. We present three new methods to creating sense-annotated corpora, which leverage translations, parallel corpora, lexical resources, and contextual and synset embeddings. Our semi-supervised method applies machine translation to transfer existing sense annotations to other languages. Our two unsupervised methods use a knowledge-based WSD system to annotate a parallel corpus, and refine the resulting sense annotations by identifying lexical translations. We obtain state-of-the-art results on standard WSD benchmarks.
A Globally Normalized Neural Model for Semantic Parsing
Jun 07, 2021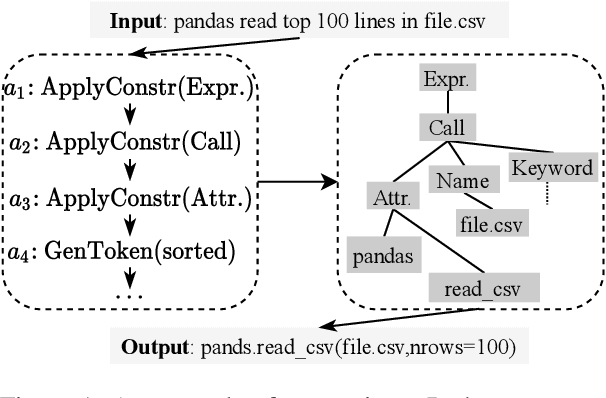
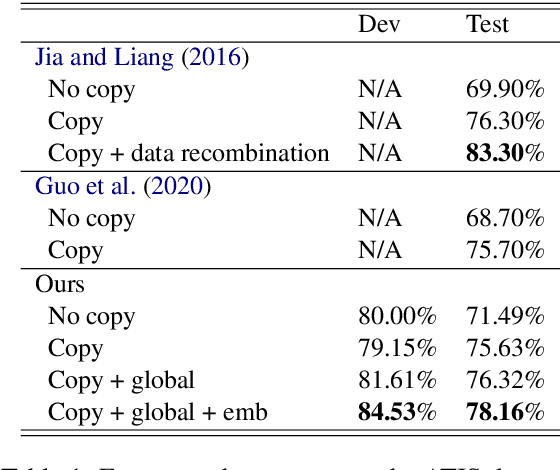
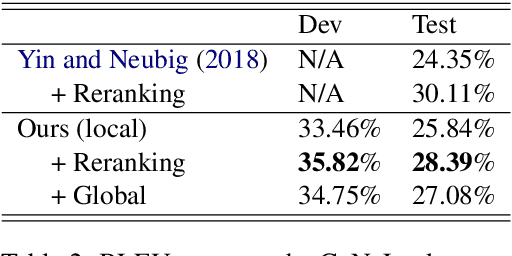

In this paper, we propose a globally normalized model for context-free grammar (CFG)-based semantic parsing. Instead of predicting a probability, our model predicts a real-valued score at each step and does not suffer from the label bias problem. Experiments show that our approach outperforms locally normalized models on small datasets, but it does not yield improvement on a large dataset.
Dynamic Labeling for Unlabeled Graph Neural Networks
Feb 23, 2021
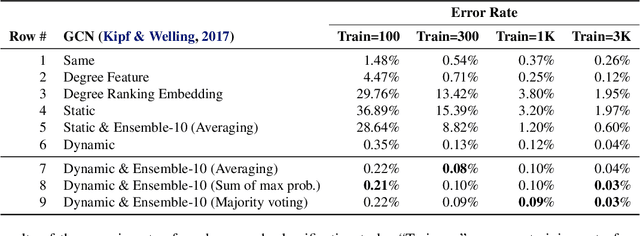
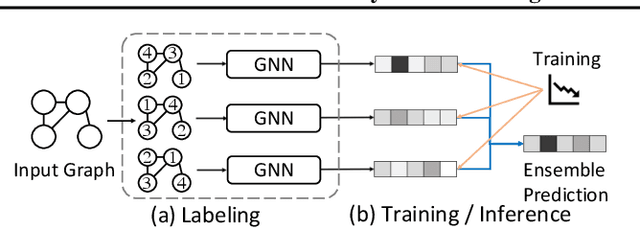
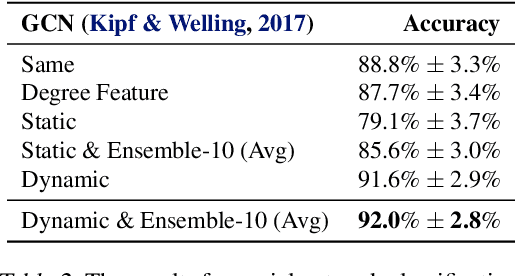
Existing graph neural networks (GNNs) largely rely on node embeddings, which represent a node as a vector by its identity, type, or content. However, graphs with unlabeled nodes widely exist in real-world applications (e.g., anonymized social networks). Previous GNNs either assign random labels to nodes (which introduces artefacts to the GNN) or assign one embedding to all nodes (which fails to distinguish one node from another). In this paper, we analyze the limitation of existing approaches in two types of classification tasks, graph classification and node classification. Inspired by our analysis, we propose two techniques, Dynamic Labeling and Preferential Dynamic Labeling, that satisfy desired properties statistically or asymptotically for each type of the task. Experimental results show that we achieve high performance in various graph-related tasks.