 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgoal Discovery for Hierarchical Dialogue Policy Learning
Sep 22, 2018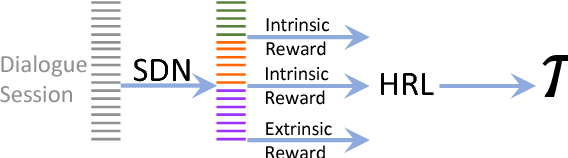
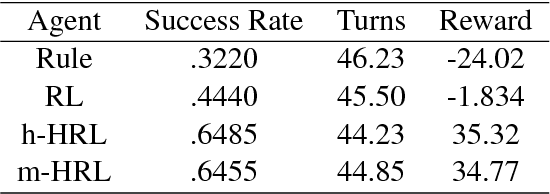
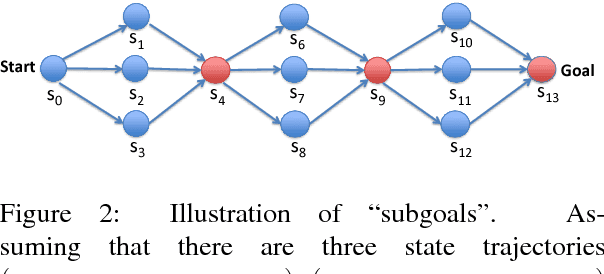

Developing agents to engage in complex goal-oriented dialogues is challenging partly because the main learning signals are very sparse in long conversations. In this paper, we propose a divide-and-conquer approach that discovers and exploits the hidden structure of the task to enable efficient policy learning. First, given successful example dialogues, we propose the Subgoal Discovery Network (SDN) to divide a complex goal-oriented task into a set of simpler subgoals in an unsupervised fashion. We then use these subgoals to learn a multi-level policy by hierarchical reinforcement learning. We demonstrate our method by building a dialogue agent for the composite task of travel planning. Experiments with simulated and real users show that our approach performs competitively against a state-of-the-art method that requires human-defined subgoals. Moreover, we show that the learned subgoals are often human comprehensible.
Neural Approaches to Conversational AI
Sep 21, 2018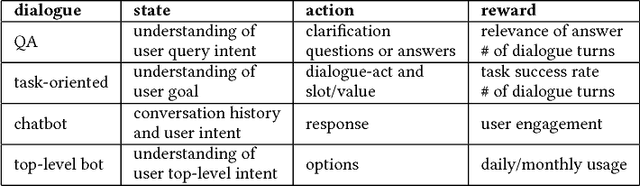
The present paper surveys neural approaches to conversational AI that have been developed in the last few years. We group conversational systems into three categories: (1) question answering agents, (2) task-oriented dialogue agents, and (3) chatbots. For each category, we present a review of state-of-the-art neural approaches, draw the connection between them and traditional approaches, and discuss the progress that has been made and challenges still being faced, using specific systems and models as case studies.
Data Poisoning Attacks in Contextual Bandits
Aug 24, 2018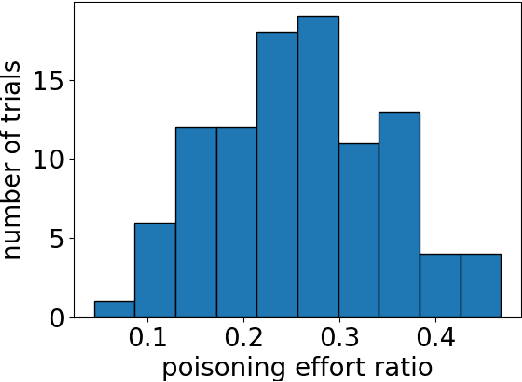



We study offline data poisoning attacks in contextual bandits, a class of reinforcement learning problems with important applications in online recommendation and adaptive medical treatment, among others. We provide a general attack framework based on convex optimization and show that by slightly manipulating rewards in the data, an attacker can force the bandit algorithm to pull a target arm for a target contextual vector. The target arm and target contextual vector are both chosen by the attacker. That is, the attacker can hijack the behavior of a contextual bandit. We also investigate the feasibility and the side effects of such attacks, and identify future directions for defense. Experiments on both synthetic and real-world data demonstrate the efficiency of the attack algorithm.
SBEED: Convergent Reinforcement Learning with Nonlinear Function Approximation
Jun 05, 2018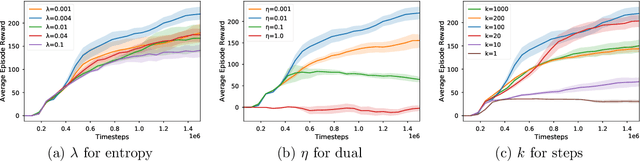
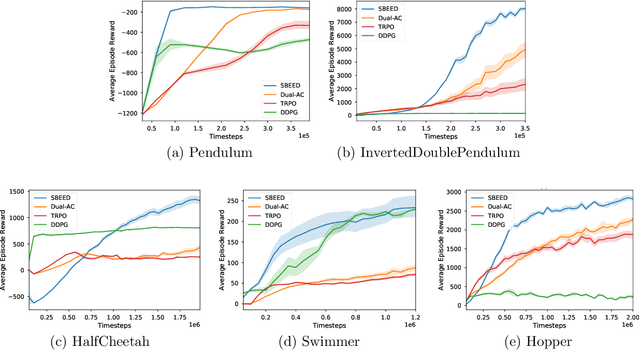
When function approximation is used, solving the Bellman optimality equation with stability guarantees has remained a major open problem in reinforcement learning for decades. The fundamental difficulty is that the Bellman operator may become an expansion in general, resulting in oscillating and even divergent behavior of popular algorithms like Q-learning. In this paper, we revisit the Bellman equation, and reformulate it into a novel primal-dual optimization problem using Nesterov's smoothing technique and the Legendre-Fenchel transformation. We then develop a new algorithm, called Smoothed Bellman Error Embedding, to solve this optimization problem where any differentiable function class may be used. We provide what we believe to be the first convergence guarantee for general nonlinear function approximation, and analyze the algorithm's sample complexity. Empirically, our algorithm compares favorably to state-of-the-art baselines in several benchmark control problems.
Scalable Bilinear $π$ Learning Using State and Action Features
Apr 27, 2018Approximate linear programming (ALP) represents one of the major algorithmic families to solve large-scale Markov decision processes (MDP). In this work, we study a primal-dual formulation of the ALP, and develop a scalable, model-free algorithm called bilinear $\pi$ learning for reinforcement learning when a sampling oracle is provided. This algorithm enjoys a number of advantages. First, it adopts (bi)linear models to represent the high-dimensional value function and state-action distributions, using given state and action features. Its run-time complexity depends on the number of features, not the size of the underlying MDPs. Second, it operates in a fully online fashion without having to store any sample, thus having minimal memory footprint. Third, we prove that it is sample-efficient, solving for the optimal policy to high precision with a sample complexity linear in the dimension of the parameter space.
Combating Reinforcement Learning's Sisyphean Curse with Intrinsic Fear
Mar 13, 2018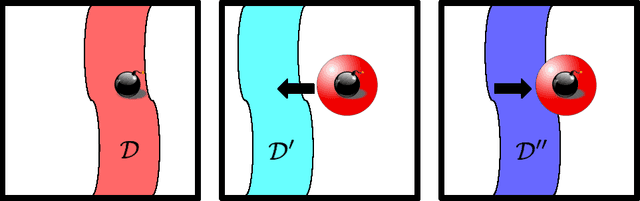
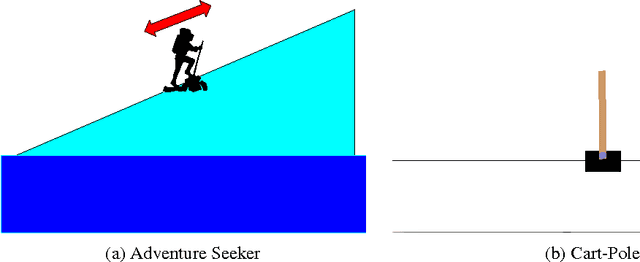
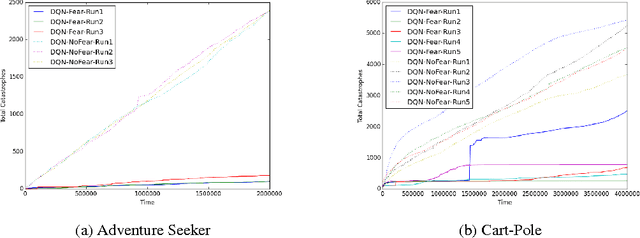
Many practical environments contain catastrophic states that an optimal agent would visit infrequently or never. Even on toy problems, Deep Reinforcement Learning (DRL) agents tend to periodically revisit these states upon forgetting their existence under a new policy. We introduce intrinsic fear (IF), a learned reward shaping that guards DRL agents against periodic catastrophes. IF agents possess a fear model trained to predict the probability of imminent catastrophe. This score is then used to penalize the Q-learning objective. Our theoretical analysis bounds the reduction in average return due to learning on the perturbed objective. We also prove robustness to classification errors. As a bonus, IF models tend to learn faster, owing to reward shaping. Experiments demonstrate that intrinsic-fear DQNs solve otherwise pathological environments and improve on several Atari games.
End-to-End Task-Completion Neural Dialogue Systems
Feb 11, 2018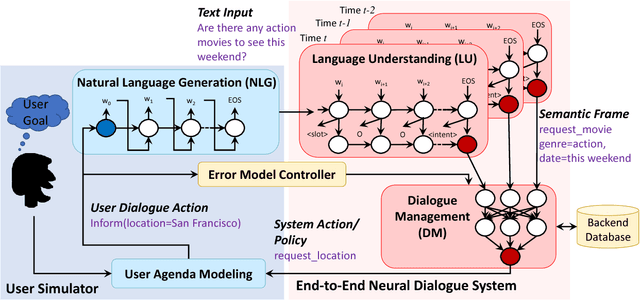
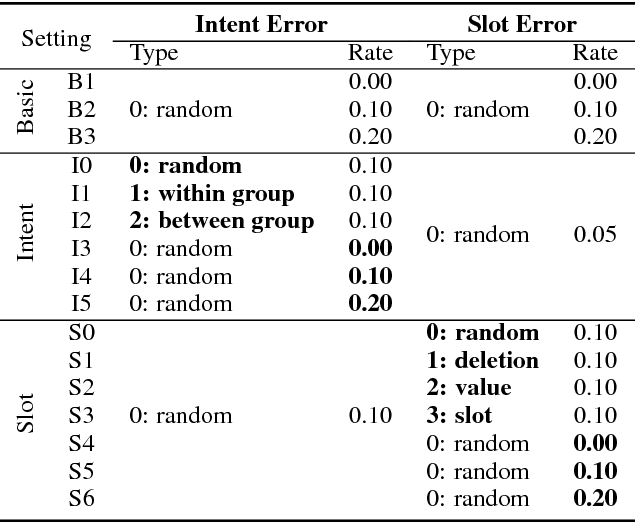
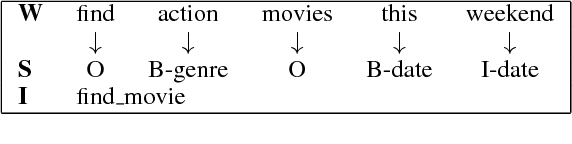

One of the major drawbacks of modularized task-completion dialogue systems is that each module is trained individually, which presents several challenges. For example, downstream modules are affected by earlier modules, and the performance of the entire system is not robust to the accumulated errors. This paper presents a novel end-to-end learning framework for task-completion dialogue systems to tackle such issues. Our neural dialogue system can directly interact with a structured database to assist users in accessing information and accomplishing certain tasks. The reinforcement learning based dialogue manager offers robust capabilities to handle noises caused by other components of the dialogue system. Our experiments in a movie-ticket booking domain show that our end-to-end system not only outperforms modularized dialogue system baselines for both objective and subjective evaluation, but also is robust to noises as demonstrated by several systematic experiments with different error granularity and rates specific to the language understanding module.
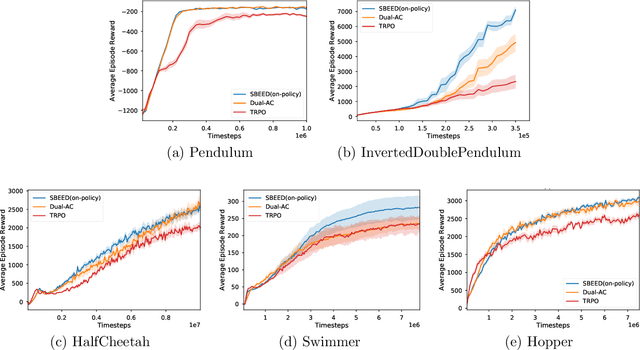
Boosting the Actor with Dual Critic
Dec 29, 2017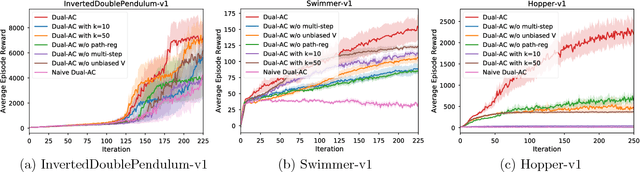
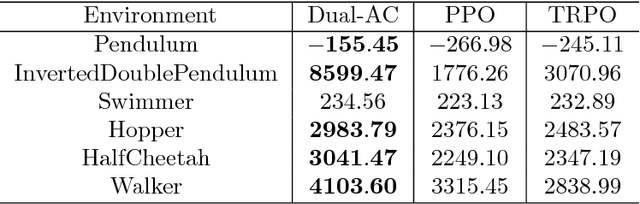
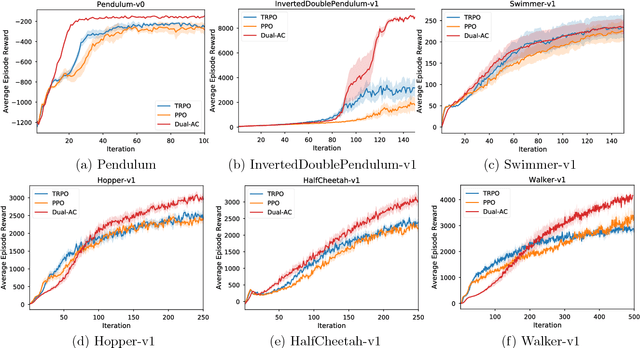
This paper proposes a new actor-critic-style algorithm called Dual Actor-Critic or Dual-AC. It is derived in a principled way from the Lagrangian dual form of the Bellman optimality equation, which can be viewed as a two-player game between the actor and a critic-like function, which is named as dual critic. Compared to its actor-critic relatives, Dual-AC has the desired property that the actor and dual critic are updated cooperatively to optimize the same objective function, providing a more transparent way for learning the critic that is directly related to the objective function of the actor. We then provide a concrete algorithm that can effectively solve the minimax optimization problem, using techniques of multi-step bootstrapping, path regularization, and stochastic dual ascent algorithm. We demonstrate that the proposed algorithm achieves the state-of-the-art performances across several benchmarks.
BBQ-Networks: Efficient Exploration in Deep Reinforcement Learning for Task-Oriented Dialogue Systems
Nov 23, 2017
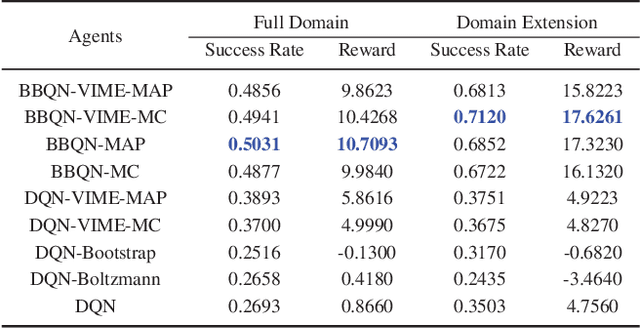
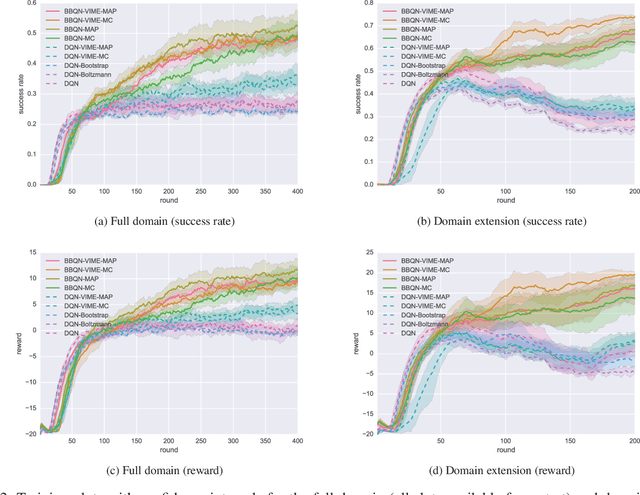
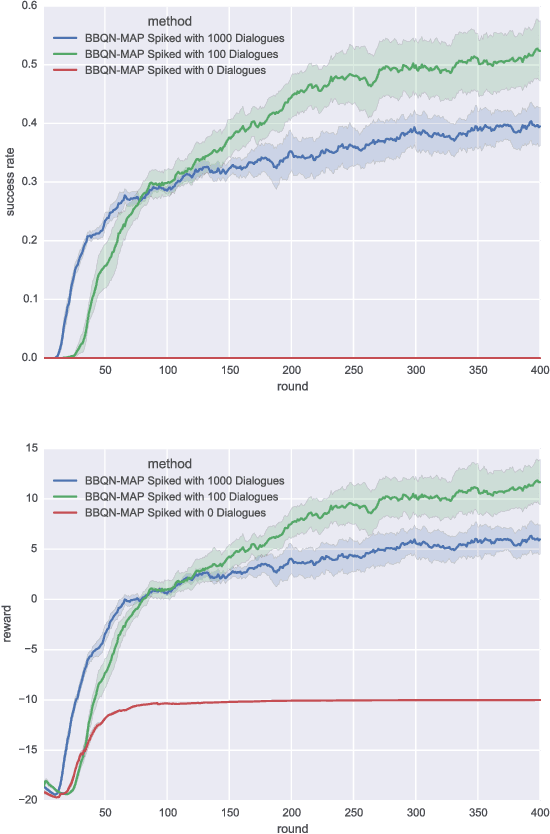
We present a new algorithm that significantly improves the efficiency of exploration for deep Q-learning agents in dialogue systems. Our agents explore via Thompson sampling, drawing Monte Carlo samples from a Bayes-by-Backprop neural network. Our algorithm learns much faster than common exploration strategies such as $\epsilon$-greedy, Boltzmann, bootstrapping, and intrinsic-reward-based ones. Additionally, we show that spiking the replay buffer with experiences from just a few successful episodes can make Q-learning feasible when it might otherwise fail.
A User Simulator for Task-Completion Dialogues
Nov 13, 2017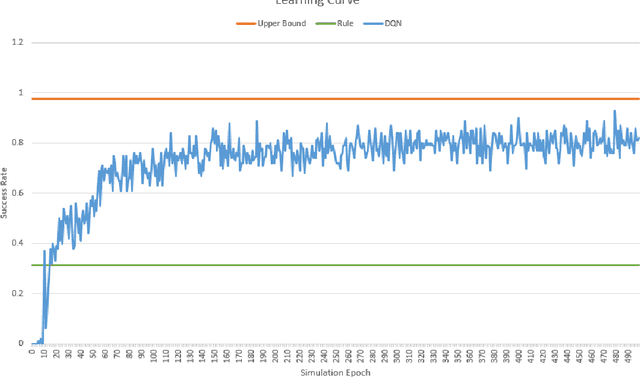

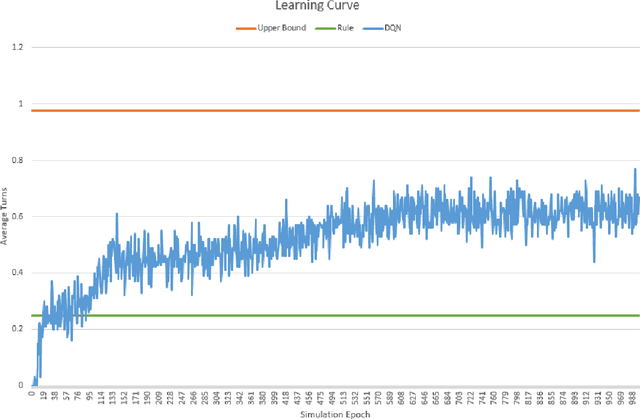

Despite widespread interests in reinforcement-learning for task-oriented dialogue systems, several obstacles can frustrate research and development progress. First, reinforcement learners typically require interaction with the environment, so conventional dialogue corpora cannot be used directly. Second, each task presents specific challenges, requiring separate corpus of task-specific annotated data. Third, collecting and annotating human-machine or human-human conversations for task-oriented dialogues requires extensive domain knowledge. Because building an appropriate dataset can be both financially costly and time-consuming, one popular approach is to build a user simulator based upon a corpus of example dialogues. Then, one can train reinforcement learning agents in an online fashion as they interact with the simulator. Dialogue agents trained on these simulators can serve as an effective starting point. Once agents master the simulator, they may be deployed in a real environment to interact with humans, and continue to be trained online. To ease empirical algorithmic comparisons in dialogues, this paper introduces a new, publicly available simulation framework, where our simulator, designed for the movie-booking domain, leverages both rules and collected data. The simulator supports two tasks: movie ticket booking and movie seeking. Finally, we demonstrate several agents and detail the procedure to add and test your own agent in the proposed framework.