 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaTreeFormer: Few Shot Domain Adaptation for Tree Counting from a Single High-Resolution Image
Feb 05, 2024



The process of estimating and counting tree density using only a single aerial or satellite image is a difficult task in the fields of photogrammetry and remote sensing. However, it plays a crucial role in the management of forests. The huge variety of trees in varied topography severely hinders tree counting models to perform well. The purpose of this paper is to propose a framework that is learnt from the source domain with sufficient labeled trees and is adapted to the target domain with only a limited number of labeled trees. Our method, termed as AdaTreeFormer, contains one shared encoder with a hierarchical feature extraction scheme to extract robust features from the source and target domains. It also consists of three subnets: two for extracting self-domain attention maps from source and target domains respectively and one for extracting cross-domain attention maps. For the latter, an attention-to-adapt mechanism is introduced to distill relevant information from different domains while generating tree density maps; a hierarchical cross-domain feature alignment scheme is proposed that progressively aligns the features from the source and target domains. We also adopt adversarial learning into the framework to further reduce the gap between source and target domains. Our AdaTreeFormer is evaluated on six designed domain adaptation tasks using three tree counting datasets, ie Jiangsu, Yosemite, and London; and outperforms the state of the art methods significantly.
FeaInfNet: Diagnosis in Medical Image with Feature-Driven Inference and Visual Explanations
Dec 04, 2023



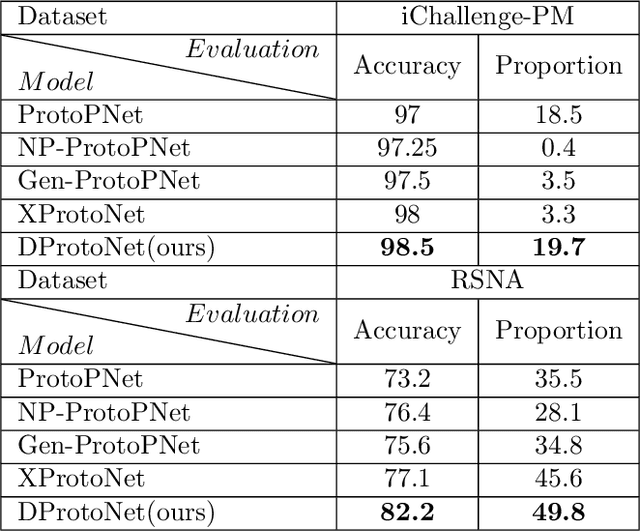
Interpretable deep learning models have received widespread attention in the field of image recognition. Due to the unique multi-instance learning of medical images and the difficulty in identifying decision-making regions, many interpretability models that have been proposed still have problems of insufficient accuracy and interpretability in medical image disease diagnosis. To solve these problems, we propose feature-driven inference network (FeaInfNet). Our first key innovation involves proposing a feature-based network reasoning structure, which is applied to FeaInfNet. The network of this structure compares the similarity of each sub-region image patch with the disease templates and normal templates that may appear in the region, and finally combines the comparison of each sub-region to make the final diagnosis. It simulates the diagnosis process of doctors to make the model interpretable in the reasoning process, while avoiding the misleading caused by the participation of normal areas in reasoning. Secondly, we propose local feature masks (LFM) to extract feature vectors in order to provide global information for these vectors, thus enhancing the expressive ability of the FeaInfNet. Finally, we propose adaptive dynamic masks (Adaptive-DM) to interpret feature vectors and prototypes into human-understandable image patches to provide accurate visual interpretation. We conducted qualitative and quantitative experiments on multiple publicly available medical datasets, including RSNA, iChallenge-PM, Covid-19, ChinaCXRSet, and MontgomerySet. The results of our experiments validate that our method achieves state-of-the-art performance in terms of classification accuracy and interpretability compared to baseline methods in medical image diagnosis. Additional ablation studies verify the effectiveness of each of our proposed components.
Mutually Guided Few-shot Learning for Relational Triple Extraction
Jun 23, 2023


Knowledge graphs (KGs), containing many entity-relation-entity triples, provide rich information for downstream applications. Although extracting triples from unstructured texts has been widely explored, most of them require a large number of labeled instances. The performance will drop dramatically when only few labeled data are available. To tackle this problem, we propose the Mutually Guided Few-shot learning framework for Relational Triple Extraction (MG-FTE). Specifically, our method consists of an entity-guided relation proto-decoder to classify the relations firstly and a relation-guided entity proto-decoder to extract entities based on the classified relations. To draw the connection between entity and relation, we design a proto-level fusion module to boost the performance of both entity extraction and relation classification. Moreover, a new cross-domain few-shot triple extraction task is introduced. Extensive experiments show that our method outperforms many state-of-the-art methods by 12.6 F1 score on FewRel 1.0 (single-domain) and 20.5 F1 score on FewRel 2.0 (cross-domain).
Hierarchical Dynamic Masks for Visual Explanation of Neural Networks
Jan 12, 2023



Saliency methods generating visual explanatory maps representing the importance of image pixels for model classification is a popular technique for explaining neural network decisions. Hierarchical dynamic masks (HDM), a novel explanatory maps generation method, is proposed in this paper to enhance the granularity and comprehensiveness of saliency maps. First, we suggest the dynamic masks (DM), which enables multiple small-sized benchmark mask vectors to roughly learn the critical information in the image through an optimization method. Then the benchmark mask vectors guide the learning of large-sized auxiliary mask vectors so that their superimposed mask can accurately learn fine-grained pixel importance information and reduce the sensitivity to adversarial perturbations. In addition, we construct the HDM by concatenating DM modules. These DM modules are used to find and fuse the regions of interest in the remaining neural network classification decisions in the mask image in a learning-based way. Since HDM forces DM to perform importance analysis in different areas, it makes the fused saliency map more comprehensive. The proposed method outperformed previous approaches significantly in terms of recognition and localization capabilities when tested on natural and medical datasets.
DProtoNet: Decoupling the inference module and the explanation module enables neural networks to have better accuracy and interpretability
Oct 15, 2022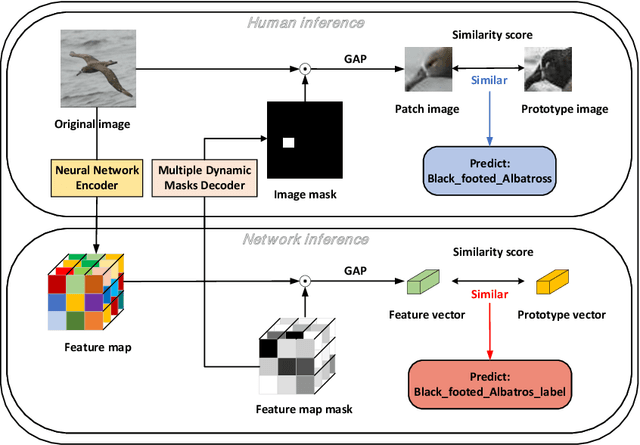
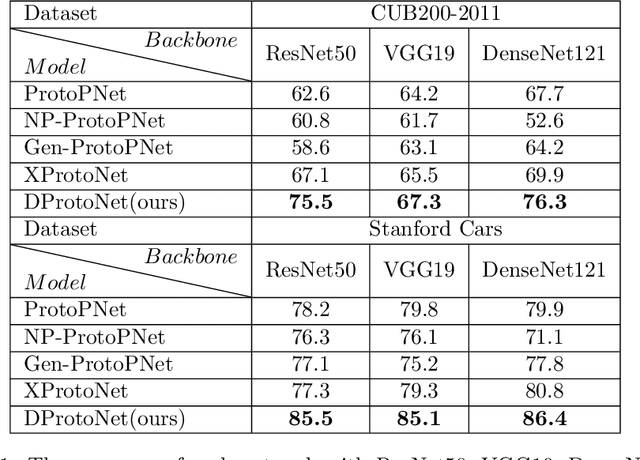
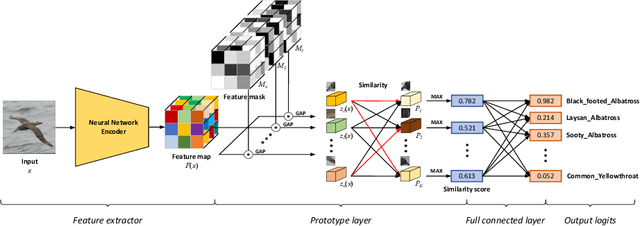
The interpretation of decisions made by neural networks is the focus of recent research. In the previous method, by modifying the architecture of the neural network, the network simulates the human reasoning process, that is, by finding the decision elements to make decisions, so that the network has the interpretability of the reasoning process. The specific interpretable architecture will limit the fitting space of the network, resulting in a decrease in the classification performance of the network, unstable convergence, and general interpretability. We propose DProtoNet (Decoupling Prototypical network), it stores the decision basis of the neural network by using feature masks, and it uses Multiple Dynamic Masks (MDM) to explain the decision basis for feature mask retention. It decouples the neural network inference module from the interpretation module, and removes the specific architectural limitations of the interpretable network, so that the decision-making architecture of the network retains the original network architecture as much as possible, making the neural network more expressive, and greatly improving the interpretability. Classification performance and interpretability of explanatory networks. We propose to replace the prototype learning of a single image with the prototype learning of multiple images, which makes the prototype robust, improves the convergence speed of network training, and makes the accuracy of the network more stable during the learning process. We test on multiple datasets, DProtoNet can improve the accuracy of recent advanced interpretable network models by 5% to 10%, and its classification performance is comparable to that of backbone networks without interpretability. It also achieves the state of the art in interpretability performance.
MDM:Visual Explanations for Neural Networks via Multiple Dynamic Mask
Jul 25, 2022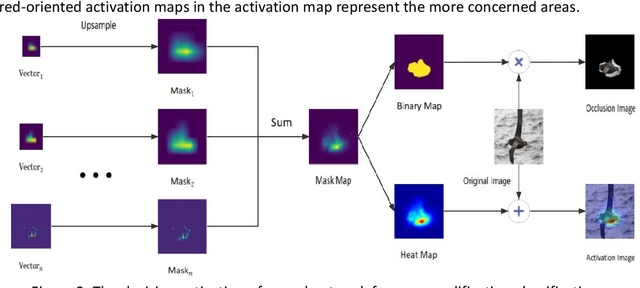

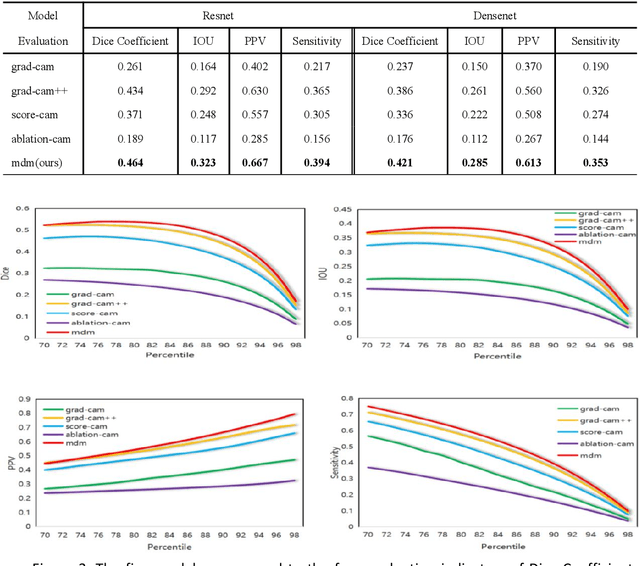

The Class Activation Maps(CAM) lookup of a neural network can tell us what regions the neural network is focusing on when making a decision.We propose an algorithm Multiple Dynamic Mask (MDM), which is a general saliency graph query method with interpretability of inference process. The algorithm is based on an assumption: when a picture is input into a trained neural network, only the activation features related to classification will affect the classification results of the neural network, and the features unrelated to classification will hardly affect the classification results of the network. MDM: A learning-based end-to-end algorithm for finding regions of interest for neural network classification.It has the following advantages: 1. It has the interpretability of the reasoning process, and the reasoning process conforms to human cognition. 2. It is universal, it can be used for any neural network and does not depend on the internal structure of the neural network. 3. The search performance is better. The algorithm is based on learning and has the ability to adapt to different data and networks. The performance is better than the method proposed in the previous paper. For the MDM saliency map search algorithm, we experimentally compared ResNet and DenseNet as the trained neural network. The recent advanced saliency map search method and the results of MDM on the performance indicators of each search effect item, the performance of MDM has reached the state of the art. We applied the MDM method to the interpretable neural network ProtoPNet and XProtoNet, which improved the model's interpretability prototype search performance. And we visualize the effect of convolutional neural architecture and Transformer architecture in saliency map search, illustrating the interpretability and generality of MDM.
Variational Transformer: A Framework Beyond the Trade-off between Accuracy and Diversity for Image Captioning
May 28, 2022
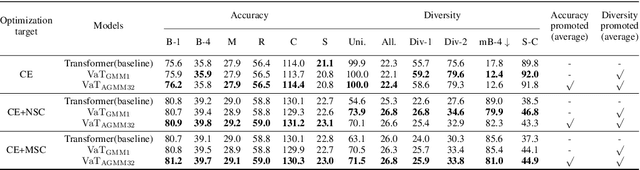
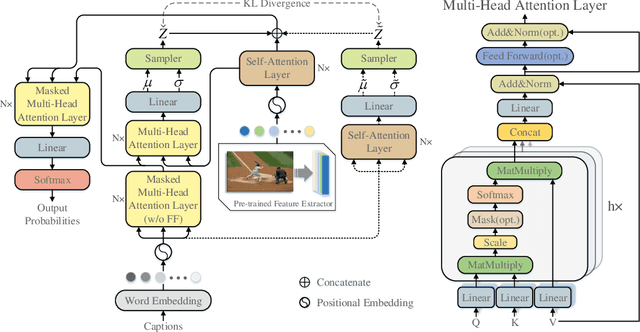
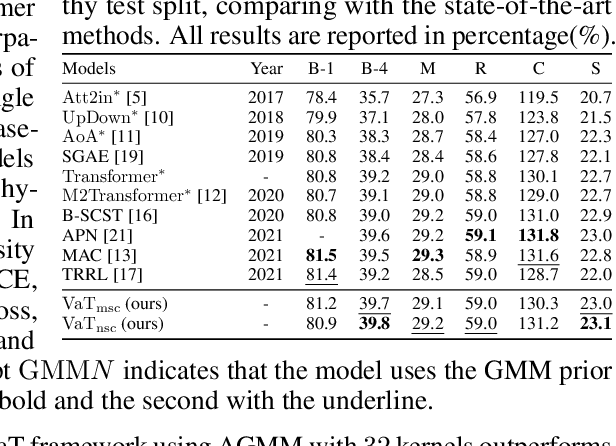
Accuracy and Diversity are two essential metrizable manifestations in generating natural and semantically correct captions. Many efforts have been made to enhance one of them with another decayed due to the trade-off gap. However, compromise does not make the progress. Decayed diversity makes the captioner a repeater, and decayed accuracy makes it a fake advisor. In this work, we exploit a novel Variational Transformer framework to improve accuracy and diversity simultaneously. To ensure accuracy, we introduce the "Invisible Information Prior" along with the "Auto-selectable GMM" to instruct the encoder to learn the precise language information and object relation in different scenes. To ensure diversity, we propose the "Range-Median Reward" baseline to retain more diverse candidates with higher rewards during the RL-based training process. Experiments show that our method achieves the simultaneous promotion of accuracy (CIDEr) and diversity (self-CIDEr), up to 1.1 and 4.8 percent, compared with the baseline. Also, our method outperforms others under the newly proposed measurement of the trade-off gap, with at least 3.55 percent promotion.
Revitalize Region Feature for Democratizing Video-Language Pre-training
Mar 19, 2022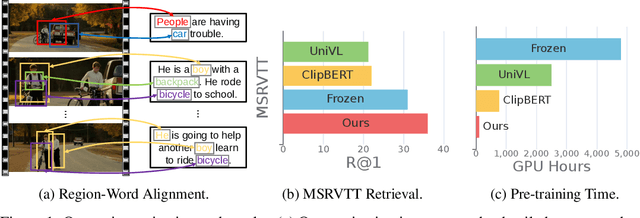
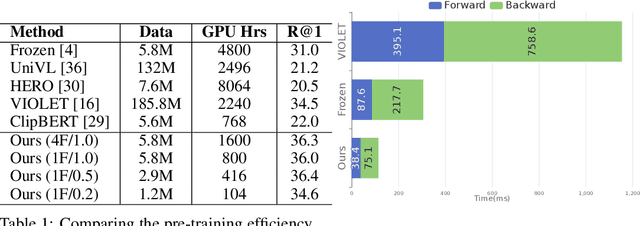
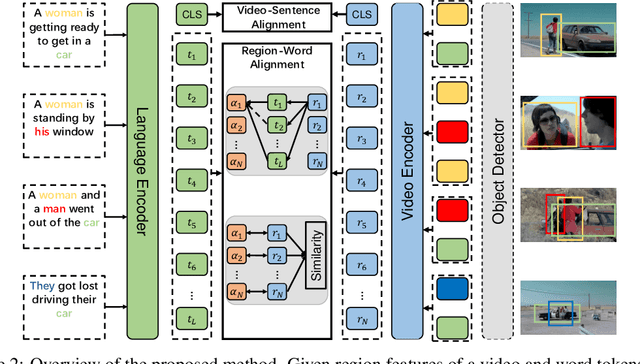

Recent dominant methods for video-language pre-training (VLP) learn transferable representations from the raw pixels in an end-to-end manner to achieve advanced performance on downstream video-language tasks. Despite the impressive results, VLP research becomes extremely expensive with the need for massive data and a long training time, preventing further explorations. In this work, we revitalize region features of sparsely sampled video clips to significantly reduce both spatial and temporal visual redundancy towards democratizing VLP research at the same time achieving state-of-the-art results. Specifically, to fully explore the potential of region features, we introduce a novel bidirectional region-word alignment regularization that properly optimizes the fine-grained relations between regions and certain words in sentences, eliminating the domain/modality disconnections between pre-extracted region features and text. Extensive results of downstream text-to-video retrieval and video question answering tasks on seven datasets demonstrate the superiority of our method on both effectiveness and efficiency, e.g., our method achieves competing results with 80\% fewer data and 85\% less pre-training time compared to the most efficient VLP method so far. The code will be available at \url{https://github.com/showlab/DemoVLP}.
Unsupervised Adaptive Semantic Segmentation with Local Lipschitz Constraint
May 27, 2021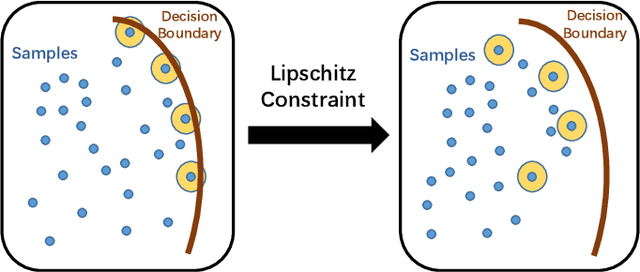
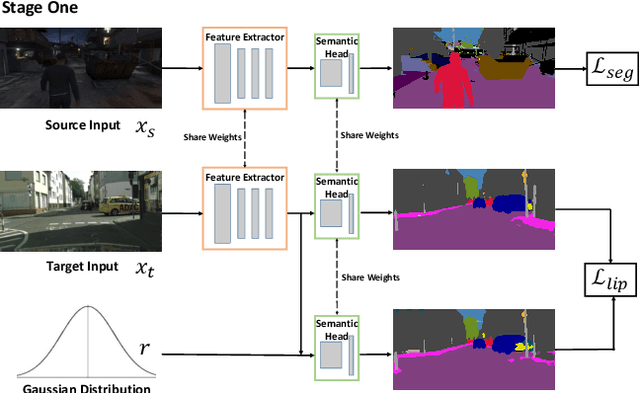
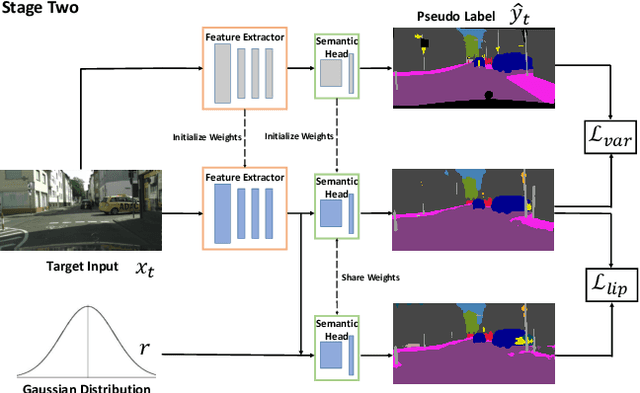

Recent advances in unsupervised domain adaptation have seen considerable progress in semantic segmentation. Existing methods either align different domains with adversarial training or involve the self-learning that utilizes pseudo labels to conduct supervised training. The former always suffers from the unstable training caused by adversarial training and only focuses on the inter-domain gap that ignores intra-domain knowledge. The latter tends to put overconfident label prediction on wrong categories, which propagates errors to more samples. To solve these problems, we propose a two-stage adaptive semantic segmentation method based on the local Lipschitz constraint that satisfies both domain alignment and domain-specific exploration under a unified principle. In the first stage, we propose the local Lipschitzness regularization as the objective function to align different domains by exploiting intra-domain knowledge, which explores a promising direction for non-adversarial adaptive semantic segmentation. In the second stage, we use the local Lipschitzness regularization to estimate the probability of satisfying Lipschitzness for each pixel, and then dynamically sets the threshold of pseudo labels to conduct self-learning. Such dynamical self-learning effectively avoids the error propagation caused by noisy labels. Optimization in both stages is based on the same principle, i.e., the local Lipschitz constraint, so that the knowledge learned in the first stage can be maintained in the second stage. Further, due to the model-agnostic property, our method can easily adapt to any CNN-based semantic segmentation networks. Experimental results demonstrate the excellent performance of our method on standard benchmarks.
Part2Whole: Iteratively Enrich Detail for Cross-Modal Retrieval with Partial Query
Mar 02, 2021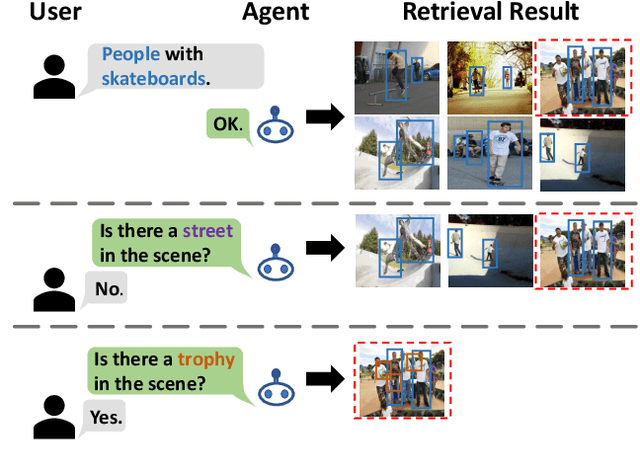

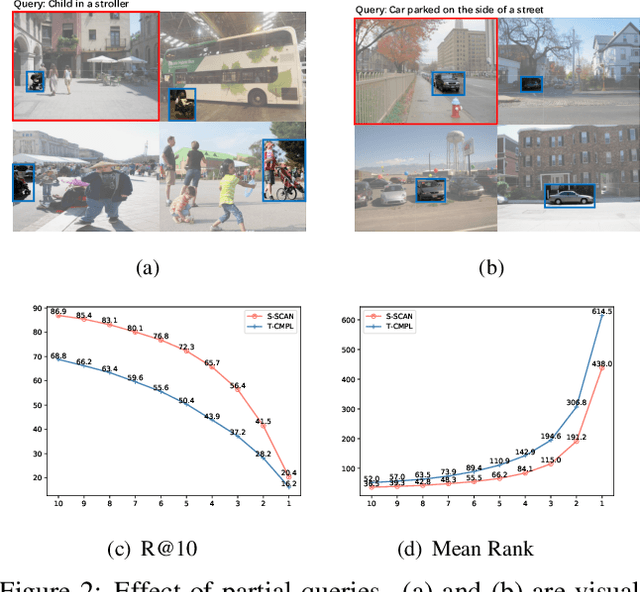
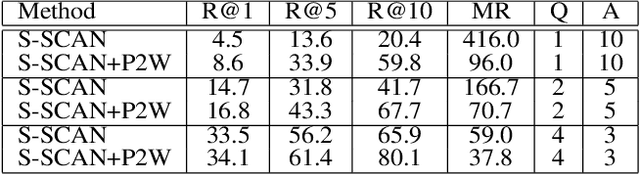
Text-based image retrieval has seen considerable progress in recent years. However, the performance of existing methods suffers in real life since the user is likely to provide an incomplete description of a complex scene, which often leads to results filled with false positives that fit the incomplete description. In this work, we introduce the partial-query problem and extensively analyze its influence on text-based image retrieval. We then propose an interactive retrieval framework called Part2Whole to tackle this problem by iteratively enriching the missing details. Specifically, an Interactive Retrieval Agent is trained to build an optimal policy to refine the initial query based on a user-friendly interaction and statistical characteristics of the gallery. Compared to other dialog-based methods that rely heavily on the user to feed back differentiating information, we let AI take over the optimal feedback searching process and hint the user with confirmation-based questions about details. Furthermore, since fully-supervised training is often infeasible due to the difficulty of obtaining human-machine dialog data, we present a weakly-supervised reinforcement learning method that needs no human-annotated data other than the text-image dataset. Experiments show that our framework significantly improves the performance of text-based image retrieval under complex scenes.