 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeSteer: Localized On-Policy Distillation for Efficient Safety Alignment
Jun 01, 2026Aligning Large Language Models (LLMs) with human values often degrades their general capabilities, termed the alignment tax. Existing methods mitigate this by balancing dual objectives, which heavily rely on massive general-purpose data or auxiliary reward models. In this paper, we argue that, because safety features are inherently sparse within the output distribution, alignment requires localized modifications rather than global trade-offs. To this end, we propose SafeSteer, which performs on-policy distillation confined to safety tokens. First, we construct a safety teacher via activation steering. Based on this teacher, we develop a safety token selection algorithm. Consequently, SafeSteer restricts the reverse KL penalty to these tokens during training to preserve general capabilities. Experimental results across diverse models show that our SafeSteer achieves a superior trade-off between safety and general capability compared with existing methods, attaining strong safety performance on seven safety benchmarks with only minimal degradation on five general capability benchmarks. Notably, SafeSteer requires only 100 harmful samples without using any general-purpose data, less than 1% of what previous baselines used, considerably reducing alignment cost. More details are on our project page at https://anjingkun.github.io/SafeSteer.
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
Apr 28, 2026Autonomous scientific research is significantly advanced thanks to the development of AI agents. One key step in this process is finding the right scientific literature, whether to explore existing knowledge for a research problem, or to acquire evidence for verifying assumptions and supporting claims. To assess AI agents' capability in driving this process, we present AutoResearchBench, a dedicated benchmark for autonomous scientific literature discovery. AutoResearchBench consists of two complementary task types: (1) Deep Research, which requires tracking down a specific target paper through a progressive, multi-step probing process, and (2) Wide Research, which requires comprehensively collecting a set of papers satisfying given conditions. Compared to previous benchmarks on agentic web browsing, AutoResearchBench is distinguished along three dimensions: it is research-oriented, calling for in-depth comprehension of scientific concepts; literature-focused, demanding fine-grained utilization of detailed information; and open-ended, involving an unknown number of qualified papers and thus requiring deliberate reasoning and search throughout. These properties make AutoResearchBench uniquely suited for evaluating autonomous research capabilities, and extraordinarily challenging. Even the most powerful LLMs, despite having largely conquered general agentic web-browsing benchmarks such as BrowseComp, achieve only 9.39% accuracy on Deep Research and 9.31% IoU on Wide Research, while many other strong baselines fall below 5%. We publicly release the dataset and evaluation pipeline to facilitate future research in this direction. We publicly release the dataset, evaluation pipeline, and code at https://github.com/CherYou/AutoResearchBench.
FlagEvalMM: A Flexible Framework for Comprehensive Multimodal Model Evaluation
Jun 10, 2025



We present FlagEvalMM, an open-source evaluation framework designed to comprehensively assess multimodal models across a diverse range of vision-language understanding and generation tasks, such as visual question answering, text-to-image/video generation, and image-text retrieval. We decouple model inference from evaluation through an independent evaluation service, thus enabling flexible resource allocation and seamless integration of new tasks and models. Moreover, FlagEvalMM utilizes advanced inference acceleration tools (e.g., vLLM, SGLang) and asynchronous data loading to significantly enhance evaluation efficiency. Extensive experiments show that FlagEvalMM offers accurate and efficient insights into model strengths and limitations, making it a valuable tool for advancing multimodal research. The framework is publicly accessible athttps://github.com/flageval-baai/FlagEvalMM.
Towards Time-Aware Distant Supervision for Relation Extraction
Mar 08, 2019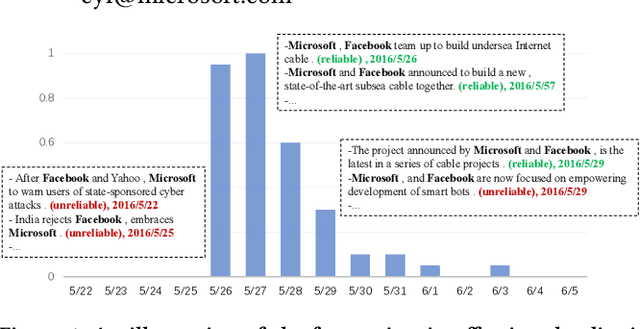
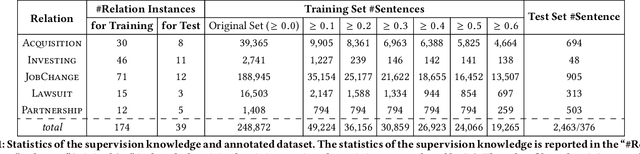
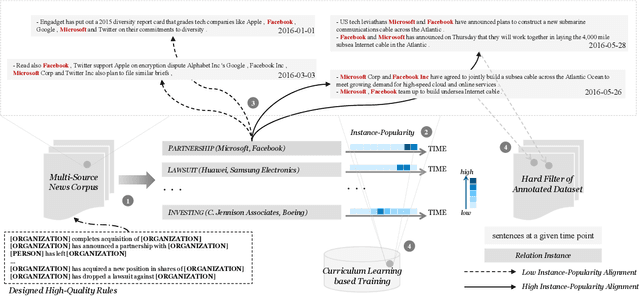
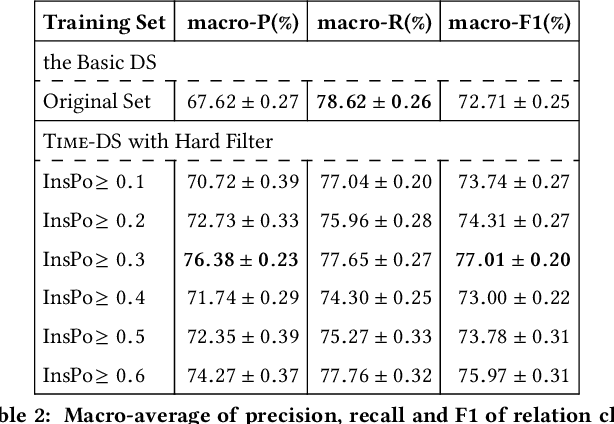
Distant supervision for relation extraction heavily suffers from the wrong labeling problem. To alleviate this issue in news data with the timestamp, we take a new factor time into consideration and propose a novel time-aware distant supervision framework (Time-DS). Time-DS is composed of a time series instance-popularity and two strategies. Instance-popularity is to encode the strong relevance of time and true relation mention. Therefore, instance-popularity would be an effective clue to reduce the noises generated through distant supervision labeling. The two strategies, i.e., hard filter and curriculum learning are both ways to implement instance-popularity for better relation extraction in the manner of Time-DS. The curriculum learning is a more sophisticated and flexible way to exploit instance-popularity to eliminate the bad effects of noises, thus get better relation extraction performance. Experiments on our collected multi-source news corpus show that Time-DS achieves significant improvements for relation extraction.
Operations Guided Neural Networks for High Fidelity Data-To-Text Generation
Sep 08, 2018
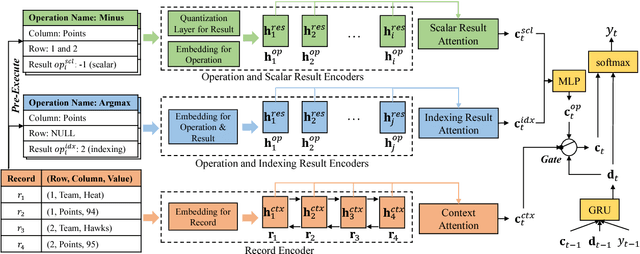
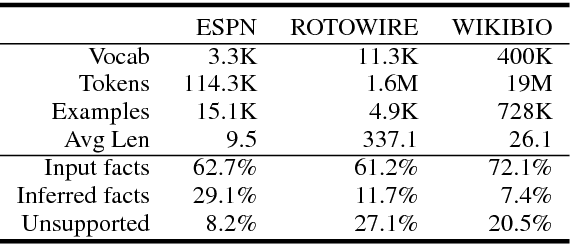

Recent neural models for data-to-text generation are mostly based on data-driven end-to-end training over encoder-decoder networks. Even though the generated texts are mostly fluent and informative, they often generate descriptions that are not consistent with the input structured data. This is a critical issue especially in domains that require inference or calculations over raw data. In this paper, we attempt to improve the fidelity of neural data-to-text generation by utilizing pre-executed symbolic operations. We propose a framework called Operation-guided Attention-based sequence-to-sequence network (OpAtt), with a specifically designed gating mechanism as well as a quantization module for operation results to utilize information from pre-executed operations. Experiments on two sports datasets show our proposed method clearly improves the fidelity of the generated texts to the input structured data.
Incorporating Consistency Verification into Neural Data-to-Document Generation
Aug 18, 2018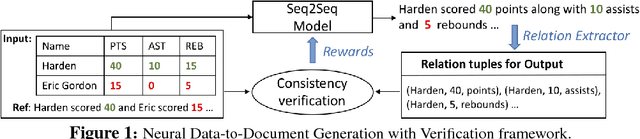
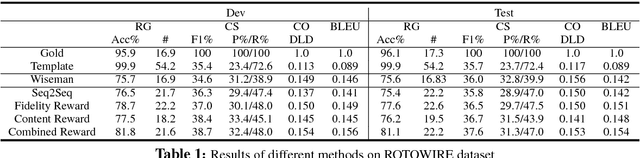
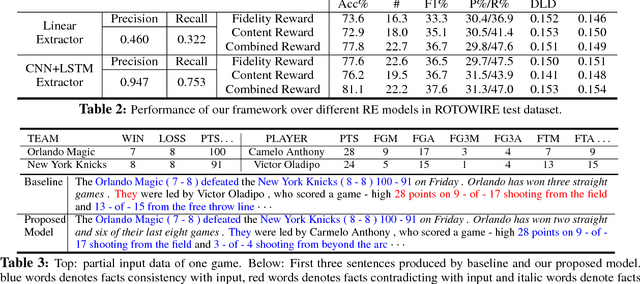
Recent neural models for data-to-document generation have achieved remarkable progress in producing fluent and informative texts. However, large proportions of generated texts do not actually conform to the input data. To address this issue, we propose a new training framework which attempts to verify the consistency between the generated texts and the input data to guide the training process. To measure the consistency, a relation extraction model is applied to check information overlaps between the input data and the generated texts. The non-differentiable consistency signal is optimized via reinforcement learning. Experimental results on a recently released challenging dataset ROTOWIRE show improvements from our framework in various metrics.