 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Graph Anatomy Geometry-Integrated Network for Pancreatic Mass Segmentation, Diagnosis, and Quantitative Patient Management
Dec 08, 2020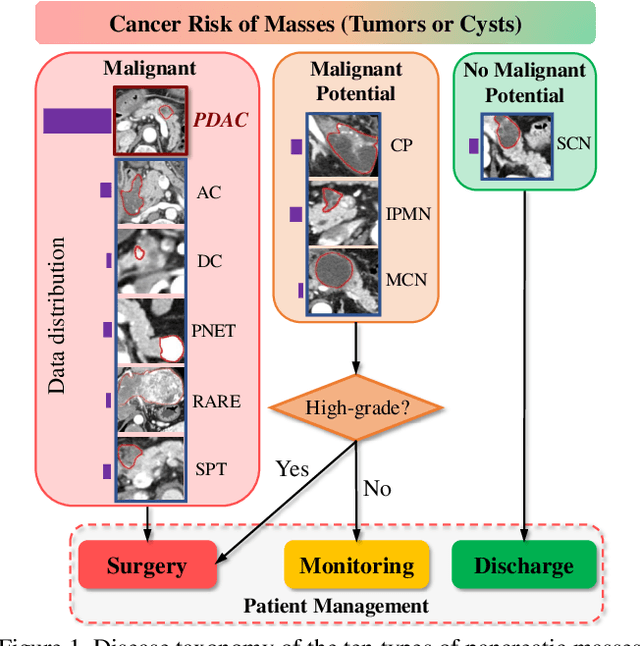

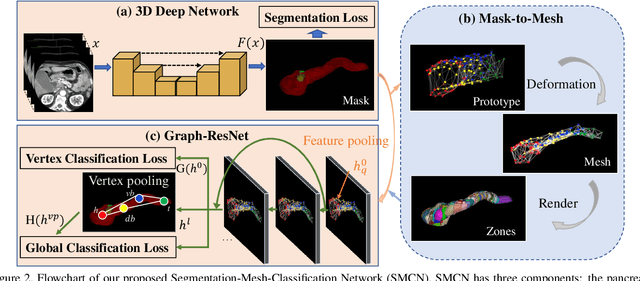

The pancreatic disease taxonomy includes ten types of masses (tumors or cysts)[20,8]. Previous work focuses on developing segmentation or classification methods only for certain mass types. Differential diagnosis of all mass types is clinically highly desirable [20] but has not been investigated using an automated image understanding approach. We exploit the feasibility to distinguish pancreatic ductal adenocarcinoma (PDAC) from the nine other nonPDAC masses using multi-phase CT imaging. Both image appearance and the 3D organ-mass geometry relationship are critical. We propose a holistic segmentation-mesh-classification network (SMCN) to provide patient-level diagnosis, by fully utilizing the geometry and location information, which is accomplished by combining the anatomical structure and the semantic detection-by-segmentation network. SMCN learns the pancreas and mass segmentation task and builds an anatomical correspondence-aware organ mesh model by progressively deforming a pancreas prototype on the raw segmentation mask (i.e., mask-to-mesh). A new graph-based residual convolutional network (Graph-ResNet), whose nodes fuse the information of the mesh model and feature vectors extracted from the segmentation network, is developed to produce the patient-level differential classification results. Extensive experiments on 661 patients' CT scans (five phases per patient) show that SMCN can improve the mass segmentation and detection accuracy compared to the strong baseline method nnUNet (e.g., for nonPDAC, Dice: 0.611 vs. 0.478; detection rate: 89% vs. 70%), achieve similar sensitivity and specificity in differentiating PDAC and nonPDAC as expert radiologists (i.e., 94% and 90%), and obtain results comparable to a multimodality test [20] that combines clinical, imaging, and molecular testing for clinical management of patients.
Self-supervised Learning of Pixel-wise Anatomical Embeddings in Radiological Images
Dec 04, 2020
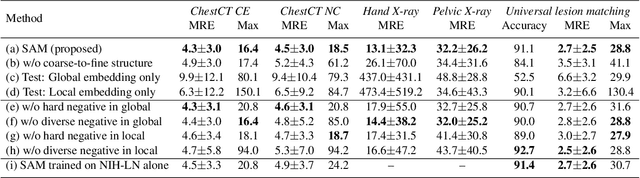
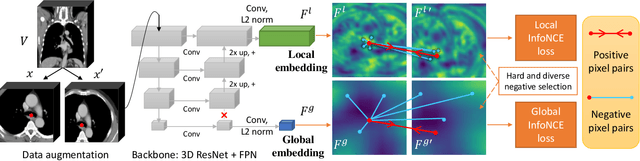
Radiological images such as computed tomography (CT) and X-rays render anatomy with intrinsic structures. Being able to reliably locate the same anatomical or semantic structure across varying images is a fundamental task in medical image analysis. In principle it is possible to use landmark detection or semantic segmentation for this task, but to work well these require large numbers of labeled data for each anatomical structure and sub-structure of interest. A more universal approach would discover the intrinsic structure from unlabeled images. We introduce such an approach, called Self-supervised Anatomical eMbedding (SAM). SAM generates semantic embeddings for each image pixel that describes its anatomical location or body part. To produce such embeddings, we propose a pixel-level contrastive learning framework. A coarse-to-fine strategy ensures both global and local anatomical information are encoded. Negative sample selection strategies are designed to enhance the discriminability among different body parts. Using SAM, one can label any point of interest on a template image, and then locate the same body part in other images by simple nearest neighbor searching. We demonstrate the effectiveness of SAM in multiple tasks with 2D and 3D image modalities. On a chest CT dataset with 19 landmarks, SAM outperforms widely-used registration algorithms while being 200 times faster. On two X-ray datasets, SAM, with only one labeled template image, outperforms supervised methods trained on 50 labeled images. We also apply SAM on whole-body follow-up lesion matching in CT and obtain an accuracy of 91%.
Contour Transformer Network for One-shot Segmentation of Anatomical Structures
Dec 02, 2020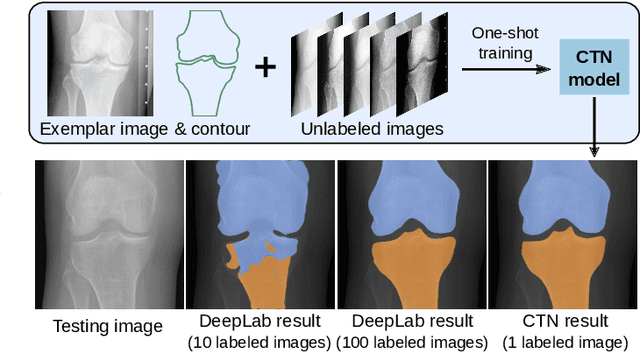
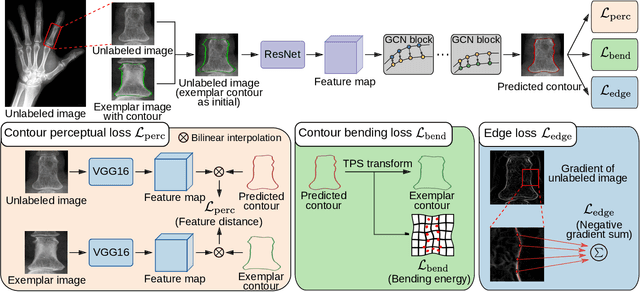
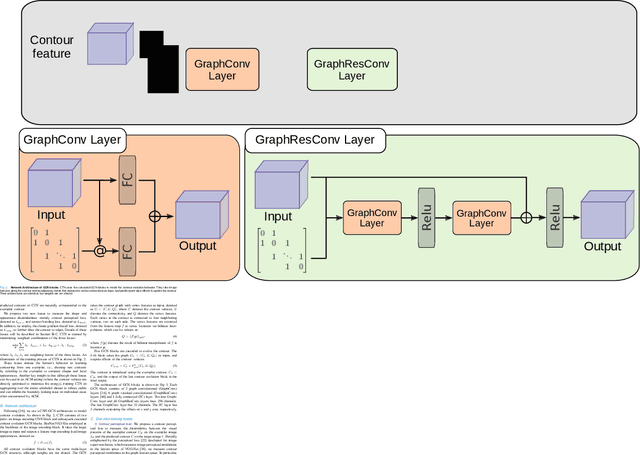
Accurate segmentation of anatomical structures is vital for medical image analysis. The state-of-the-art accuracy is typically achieved by supervised learning methods, where gathering the requisite expert-labeled image annotations in a scalable manner remains a main obstacle. Therefore, annotation-efficient methods that permit to produce accurate anatomical structure segmentation are highly desirable. In this work, we present Contour Transformer Network (CTN), a one-shot anatomy segmentation method with a naturally built-in human-in-the-loop mechanism. We formulate anatomy segmentation as a contour evolution process and model the evolution behavior by graph convolutional networks (GCNs). Training the CTN model requires only one labeled image exemplar and leverages additional unlabeled data through newly introduced loss functions that measure the global shape and appearance consistency of contours. On segmentation tasks of four different anatomies, we demonstrate that our one-shot learning method significantly outperforms non-learning-based methods and performs competitively to the state-of-the-art fully supervised deep learning methods. With minimal human-in-the-loop editing feedback, the segmentation performance can be further improved to surpass the fully supervised methods.
Learning from Multiple Datasets with Heterogeneous and Partial Labels for Universal Lesion Detection in CT
Sep 05, 2020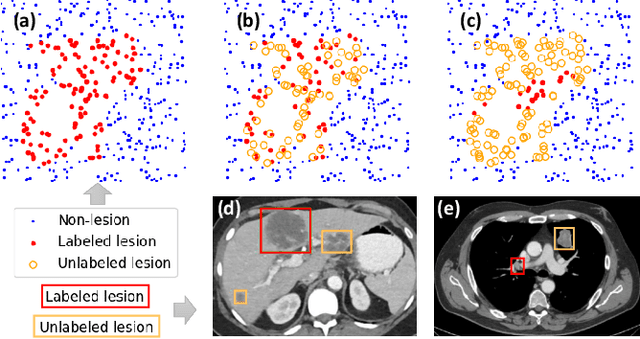
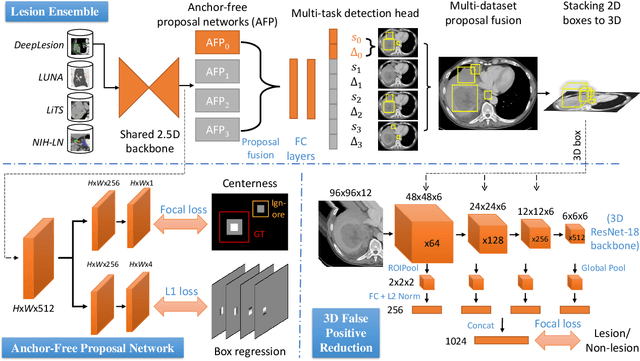
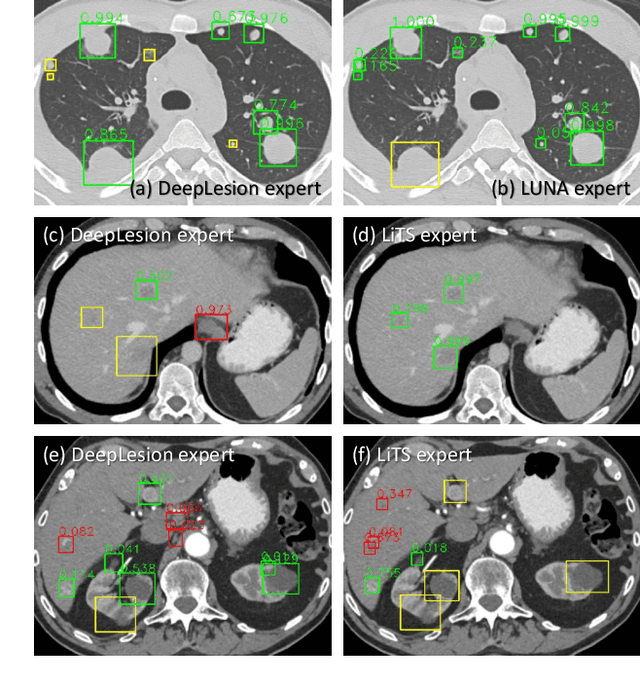
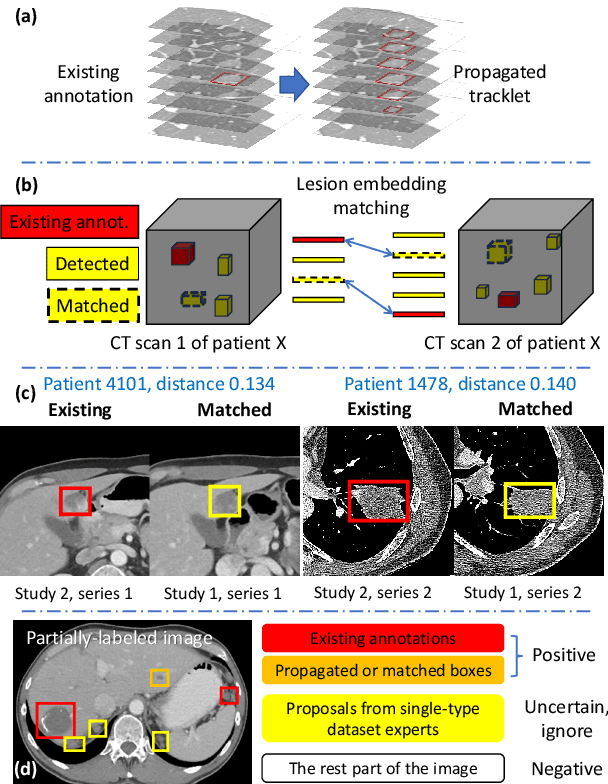
Large-scale datasets with high-quality labels are desired for training accurate deep learning models. However, due to annotation costs, medical imaging datasets are often either partially-labeled or small. For example, DeepLesion is a large-scale CT image dataset with lesions of various types, but it also has many unlabeled lesions (missing annotations). When training a lesion detector on a partially-labeled dataset, the missing annotations will generate incorrect negative signals and degrade performance. Besides DeepLesion, there are several small single-type datasets, such as LUNA for lung nodules and LiTS for liver tumors. Such datasets have heterogeneous label scopes, i.e., different lesion types are labeled in different datasets with other types ignored. In this work, we aim to tackle the problem of heterogeneous and partial labels, and develop a universal lesion detection algorithm to detect a comprehensive variety of lesions. First, we build a simple yet effective lesion detection framework named Lesion ENSemble (LENS). LENS can efficiently learn from multiple heterogeneous lesion datasets in a multi-task fashion and leverage their synergy by feature sharing and proposal fusion. Next, we propose strategies to mine missing annotations from partially-labeled datasets by exploiting clinical prior knowledge and cross-dataset knowledge transfer. Finally, we train our framework on four public lesion datasets and evaluate it on 800 manually-labeled sub-volumes in DeepLesion. On this challenging task, our method brings a relative improvement of 49% compared to the current state-of-the-art approach.
User-Guided Domain Adaptation for Rapid Annotation from User Interactions: A Study on Pathological Liver Segmentation
Sep 05, 2020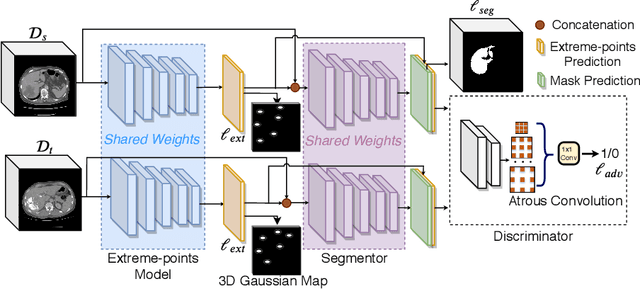
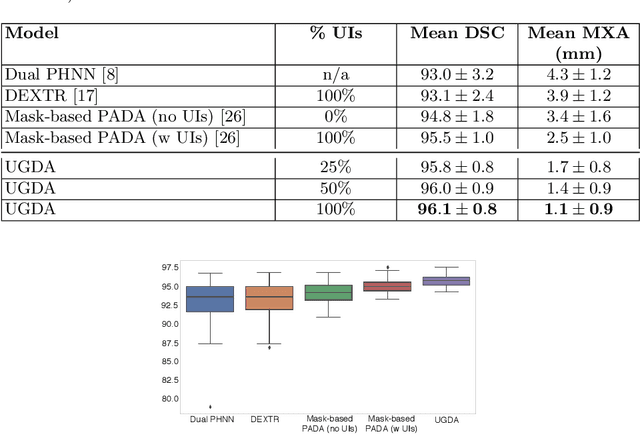


Mask-based annotation of medical images, especially for 3D data, is a bottleneck in developing reliable machine learning models. Using minimal-labor user interactions (UIs) to guide the annotation is promising, but challenges remain on best harmonizing the mask prediction with the UIs. To address this, we propose the user-guided domain adaptation (UGDA) framework, which uses prediction-based adversarial domain adaptation (PADA) to model the combined distribution of UIs and mask predictions. The UIs are then used as anchors to guide and align the mask prediction. Importantly, UGDA can both learn from unlabelled data and also model the high-level semantic meaning behind different UIs. We test UGDA on annotating pathological livers using a clinically comprehensive dataset of 927 patient studies. Using only extreme-point UIs, we achieve a mean (worst-case) performance of 96.1%(94.9%), compared to 93.0% (87.0%) for deep extreme points (DEXTR). Furthermore, we also show UGDA can retain this state-of-the-art performance even when only seeing a fraction of available UIs, demonstrating an ability for robust and reliable UI-guided segmentation with extremely minimal labor demands.
Deep Volumetric Universal Lesion Detection using Light-Weight Pseudo 3D Convolution and Surface Point Regression
Aug 30, 2020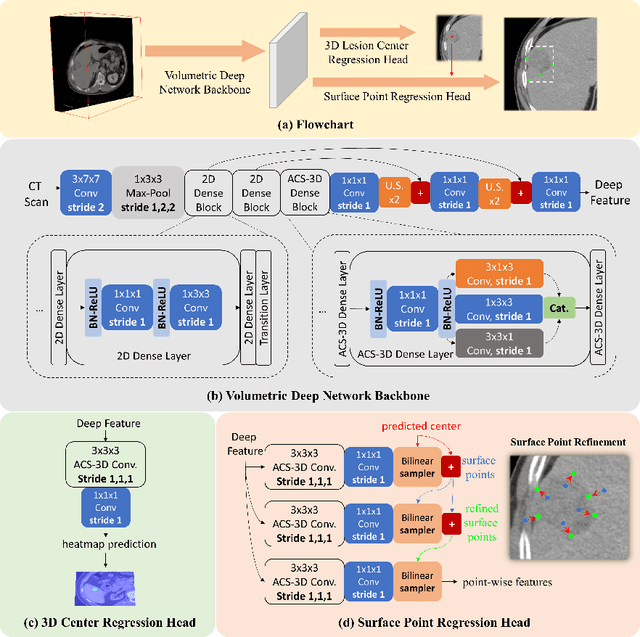
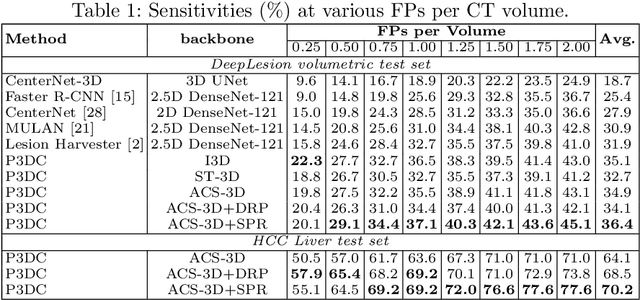

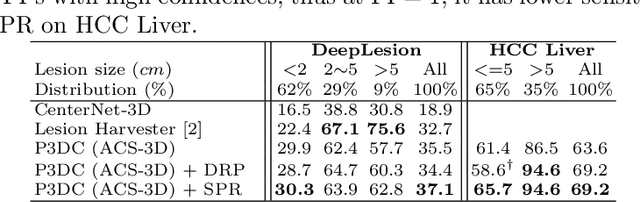
Identifying, measuring and reporting lesions accurately and comprehensively from patient CT scans are important yet time-consuming procedures for physicians. Computer-aided lesion/significant-findings detection techniques are at the core of medical imaging, which remain very challenging due to the tremendously large variability of lesion appearance, location and size distributions in 3D imaging. In this work, we propose a novel deep anchor-free one-stage VULD framework that incorporates (1) P3DC operators to recycle the architectural configurations and pre-trained weights from the off-the-shelf 2D networks, especially ones with large capacities to cope with data variance, and (2) a new SPR method to effectively regress the 3D lesion spatial extents by pinpointing their representative key points on lesion surfaces. Experimental validations are first conducted on the public large-scale NIH DeepLesion dataset where our proposed method delivers new state-of-the-art quantitative performance. We also test VULD on our in-house dataset for liver tumor detection. VULD generalizes well in both large-scale and small-sized tumor datasets in CT imaging.
Lymph Node Gross Tumor Volume Detection in Oncology Imaging via Relationship Learning Using Graph Neural Network
Aug 29, 2020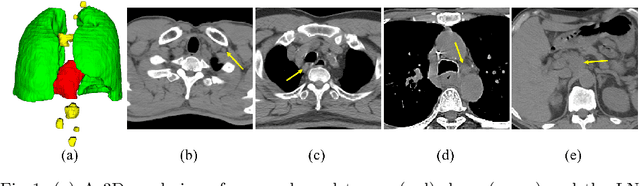
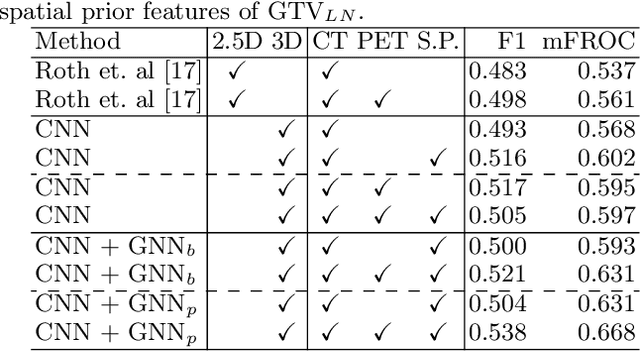
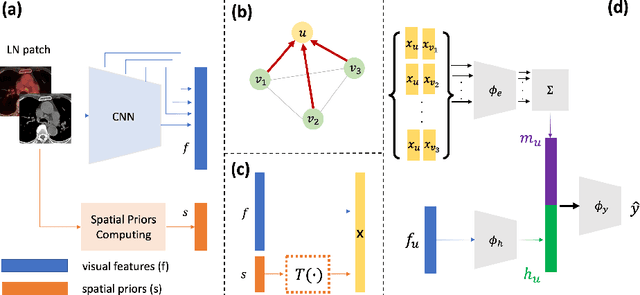
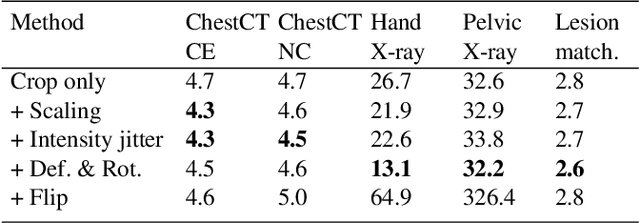
Determining the spread of GTV$_{LN}$ is essential in defining the respective resection or irradiating regions for the downstream workflows of surgical resection and radiotherapy for many cancers. Different from the more common enlarged lymph node (LN), GTV$_{LN}$ also includes smaller ones if associated with high positron emission tomography signals and/or any metastasis signs in CT. This is a daunting task. In this work, we propose a unified LN appearance and inter-LN relationship learning framework to detect the true GTV$_{LN}$. This is motivated by the prior clinical knowledge that LNs form a connected lymphatic system, and the spread of cancer cells among LNs often follows certain pathways. Specifically, we first utilize a 3D convolutional neural network with ROI-pooling to extract the GTV$_{LN}$'s instance-wise appearance features. Next, we introduce a graph neural network to further model the inter-LN relationships where the global LN-tumor spatial priors are included in the learning process. This leads to an end-to-end trainable network to detect by classifying GTV$_{LN}$. We operate our model on a set of GTV$_{LN}$ candidates generated by a preliminary 1st-stage method, which has a sensitivity of $>85\%$ at the cost of high false positive (FP) ($>15$ FPs per patient). We validate our approach on a radiotherapy dataset with 142 paired PET/RTCT scans containing the chest and upper abdominal body parts. The proposed method significantly improves over the state-of-the-art (SOTA) LN classification method by $5.5\%$ and $13.1\%$ in F1 score and the averaged sensitivity value at $2, 3, 4, 6$ FPs per patient, respectively.
Lymph Node Gross Tumor Volume Detection and Segmentation via Distance-based Gating using 3D CT/PET Imaging in Radiotherapy
Aug 27, 2020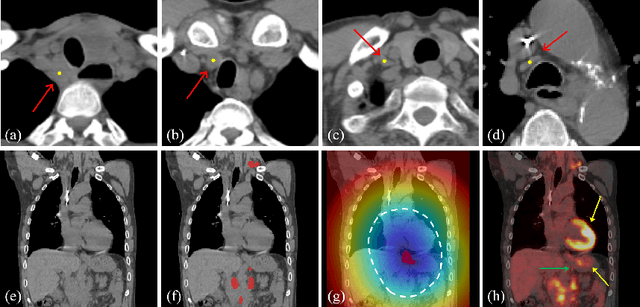
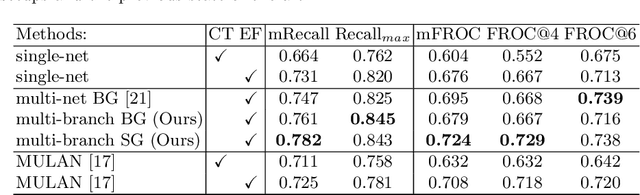
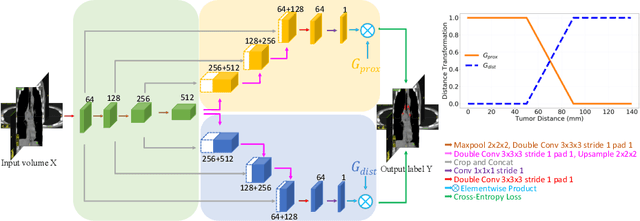
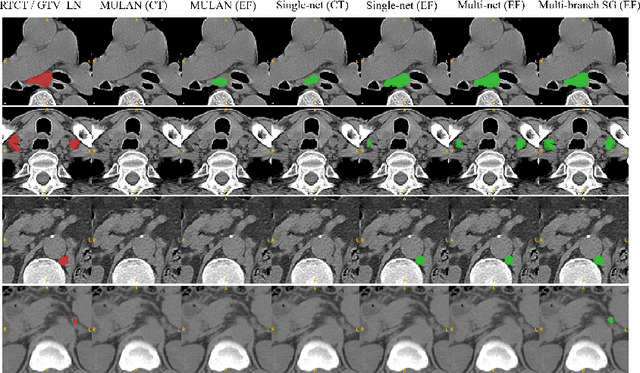
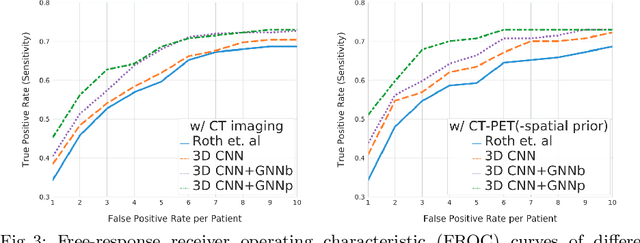
Finding, identifying and segmenting suspicious cancer metastasized lymph nodes from 3D multi-modality imaging is a clinical task of paramount importance. In radiotherapy, they are referred to as Lymph Node Gross Tumor Volume (GTVLN). Determining and delineating the spread of GTVLN is essential in defining the corresponding resection and irradiating regions for the downstream workflows of surgical resection and radiotherapy of various cancers. In this work, we propose an effective distance-based gating approach to simulate and simplify the high-level reasoning protocols conducted by radiation oncologists, in a divide-and-conquer manner. GTVLN is divided into two subgroups of tumor-proximal and tumor-distal, respectively, by means of binary or soft distance gating. This is motivated by the observation that each category can have distinct though overlapping distributions of appearance, size and other LN characteristics. A novel multi-branch detection-by-segmentation network is trained with each branch specializing on learning one GTVLN category features, and outputs from multi-branch are fused in inference. The proposed method is evaluated on an in-house dataset of $141$ esophageal cancer patients with both PET and CT imaging modalities. Our results validate significant improvements on the mean recall from $72.5\%$ to $78.2\%$, as compared to previous state-of-the-art work. The highest achieved GTVLN recall of $82.5\%$ at $20\%$ precision is clinically relevant and valuable since human observers tend to have low sensitivity (around $80\%$ for the most experienced radiation oncologists, as reported by literature).
DeepPrognosis: Preoperative Prediction of Pancreatic Cancer Survival and Surgical Margin via Contrast-Enhanced CT Imaging
Aug 26, 2020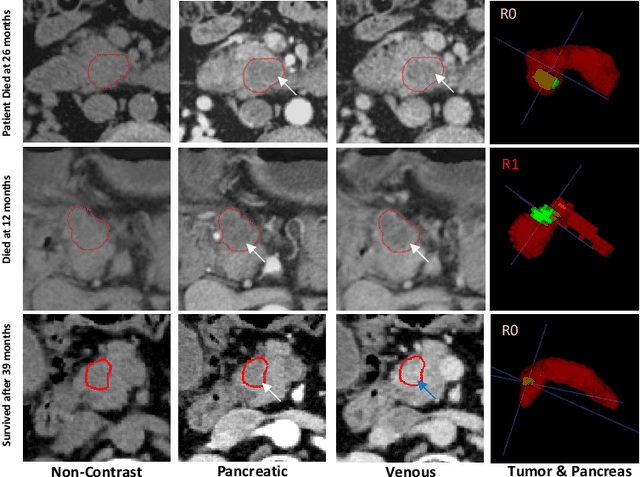
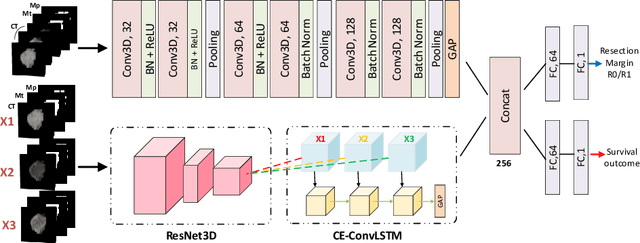
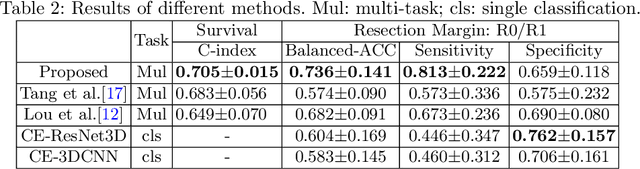
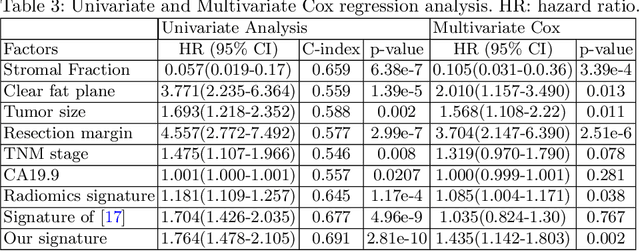
Pancreatic ductal adenocarcinoma (PDAC) is one of the most lethal cancers and carries a dismal prognosis. Surgery remains the best chance of a potential cure for patients who are eligible for initial resection of PDAC. However, outcomes vary significantly even among the resected patients of the same stage and received similar treatments. Accurate preoperative prognosis of resectable PDACs for personalized treatment is thus highly desired. Nevertheless, there are no automated methods yet to fully exploit the contrast-enhanced computed tomography (CE-CT) imaging for PDAC. Tumor attenuation changes across different CT phases can reflect the tumor internal stromal fractions and vascularization of individual tumors that may impact the clinical outcomes. In this work, we propose a novel deep neural network for the survival prediction of resectable PDAC patients, named as 3D Contrast-Enhanced Convolutional Long Short-Term Memory network(CE-ConvLSTM), which can derive the tumor attenuation signatures or patterns from CE-CT imaging studies. We present a multi-task CNN to accomplish both tasks of outcome and margin prediction where the network benefits from learning the tumor resection margin related features to improve survival prediction. The proposed framework can improve the prediction performances compared with existing state-of-the-art survival analysis approaches. The tumor signature built from our model has evidently added values to be combined with the existing clinical staging system.
Robust Pancreatic Ductal Adenocarcinoma Segmentation with Multi-Institutional Multi-Phase Partially-Annotated CT Scans
Aug 24, 2020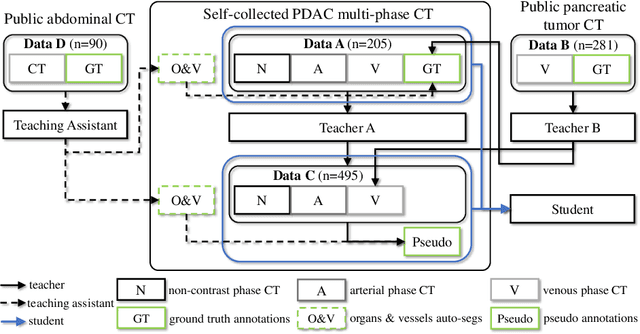
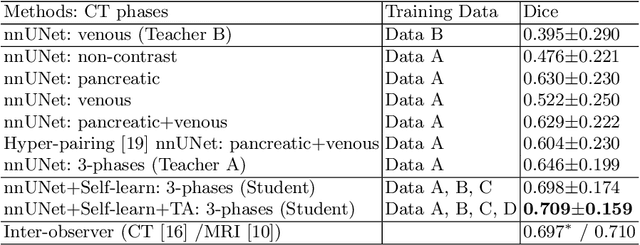
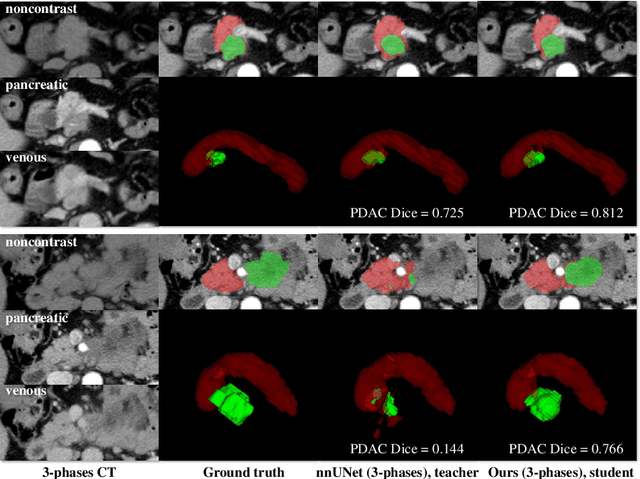
Accurate and automated tumor segmentation is highly desired since it has the great potential to increase the efficiency and reproducibility of computing more complete tumor measurements and imaging biomarkers, comparing to (often partial) human measurements. This is probably the only viable means to enable the large-scale clinical oncology patient studies that utilize medical imaging. Deep learning approaches have shown robust segmentation performances for certain types of tumors, e.g., brain tumors in MRI imaging, when a training dataset with plenty of pixel-level fully-annotated tumor images is available. However, more than often, we are facing the challenge that only (very) limited annotations are feasible to acquire, especially for hard tumors. Pancreatic ductal adenocarcinoma (PDAC) segmentation is one of the most challenging tumor segmentation tasks, yet critically important for clinical needs. Previous work on PDAC segmentation is limited to the moderate amounts of annotated patient images (n<300) from venous or venous+arterial phase CT scans. Based on a new self-learning framework, we propose to train the PDAC segmentation model using a much larger quantity of patients (n~=1,000), with a mix of annotated and un-annotated venous or multi-phase CT images. Pseudo annotations are generated by combining two teacher models with different PDAC segmentation specialties on unannotated images, and can be further refined by a teaching assistant model that identifies associated vessels around the pancreas. A student model is trained on both manual and pseudo annotated multi-phase images. Experiment results show that our proposed method provides an absolute improvement of 6.3% Dice score over the strong baseline of nnUNet trained on annotated images, achieving the performance (Dice = 0.71) similar to the inter-observer variability between radiologists.