 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-institutional Validation of Two-Streamed Deep Learning Method for Automated Delineation of Esophageal Gross Tumor Volume using planning-CT and FDG-PETCT
Oct 11, 2021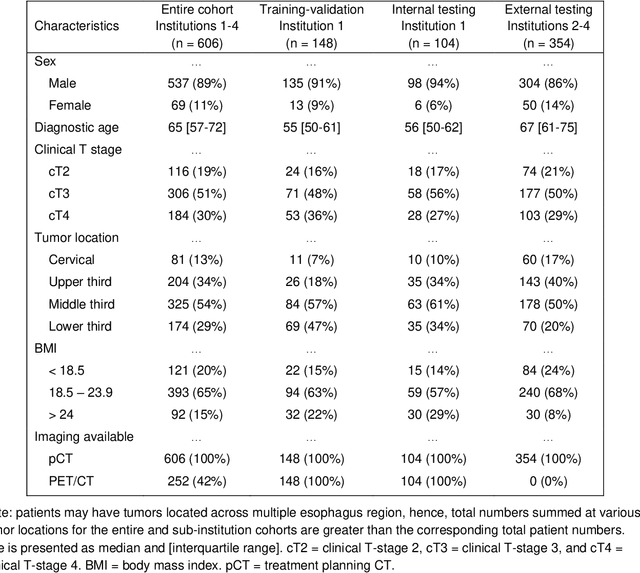
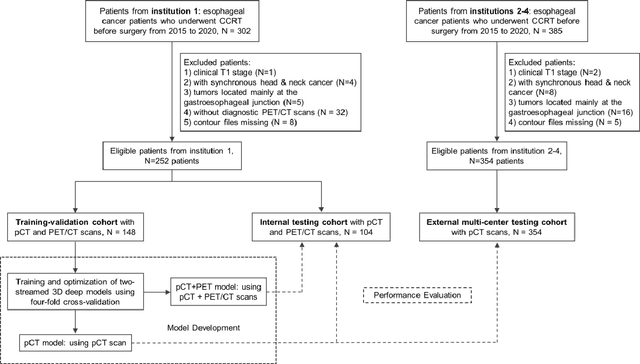
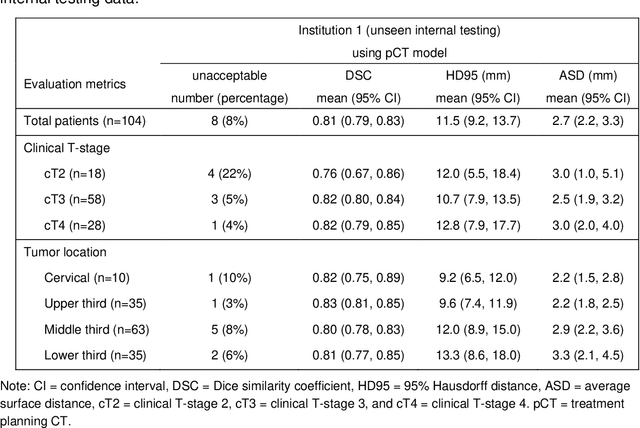
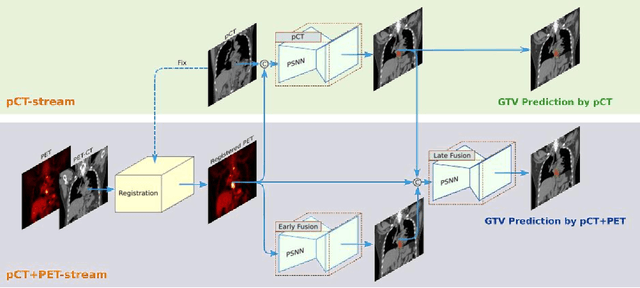
Background: The current clinical workflow for esophageal gross tumor volume (GTV) contouring relies on manual delineation of high labor-costs and interuser variability. Purpose: To validate the clinical applicability of a deep learning (DL) multi-modality esophageal GTV contouring model, developed at 1 institution whereas tested at multiple ones. Methods and Materials: We collected 606 esophageal cancer patients from four institutions. 252 institution-1 patients had a treatment planning-CT (pCT) and a pair of diagnostic FDG-PETCT; 354 patients from other 3 institutions had only pCT. A two-streamed DL model for GTV segmentation was developed using pCT and PETCT scans of a 148 patient institution-1 subset. This built model had the flexibility of segmenting GTVs via only pCT or pCT+PETCT combined. For independent evaluation, the rest 104 institution-1 patients behaved as unseen internal testing, and 354 institutions 2-4 patients were used for external testing. We evaluated manual revision degrees by human experts to assess the contour-editing effort. The performance of the deep model was compared against 4 radiation oncologists in a multiuser study with 20 random external patients. Contouring accuracy and time were recorded for the pre-and post-DL assisted delineation process. Results: Our model achieved high segmentation accuracy in internal testing (mean Dice score: 0.81 using pCT and 0.83 using pCT+PET) and generalized well to external evaluation (mean DSC: 0.80). Expert assessment showed that the predicted contours of 88% patients need only minor or no revision. In multi-user evaluation, with the assistance of a deep model, inter-observer variation and required contouring time were reduced by 37.6% and 48.0%, respectively. Conclusions: Deep learning predicted GTV contours were in close agreement with the ground truth and could be adopted clinically with mostly minor or no changes.
SAME: Deformable Image Registration based on Self-supervised Anatomical Embeddings
Sep 23, 2021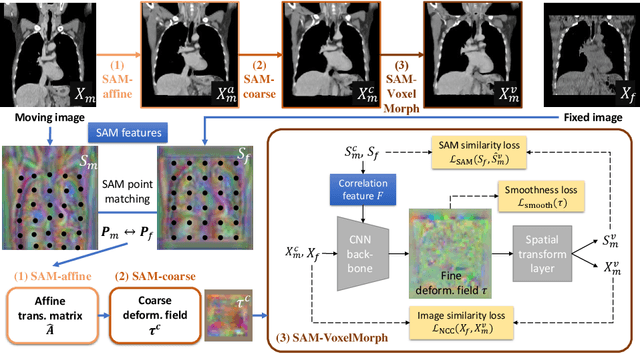
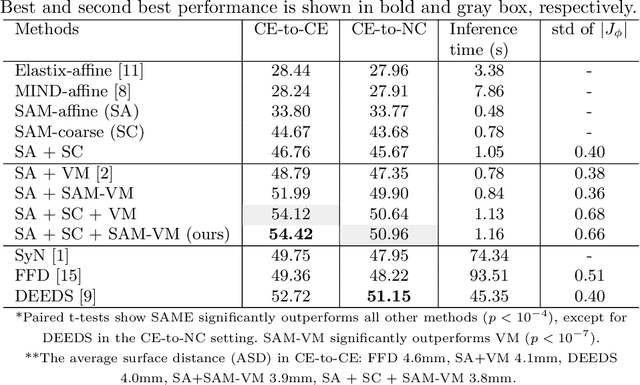

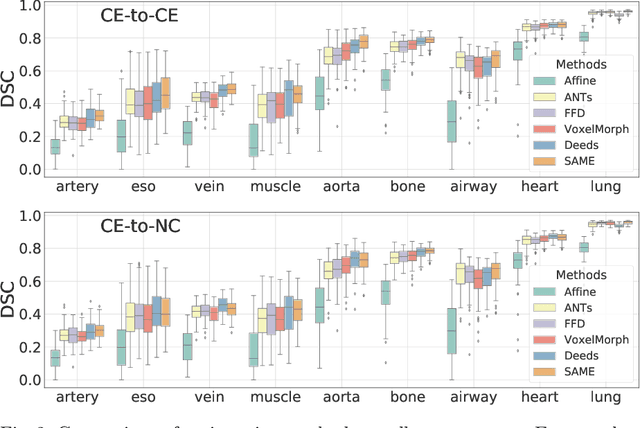
In this work, we introduce a fast and accurate method for unsupervised 3D medical image registration. This work is built on top of a recent algorithm SAM, which is capable of computing dense anatomical/semantic correspondences between two images at the pixel level. Our method is named SAME, which breaks down image registration into three steps: affine transformation, coarse deformation, and deep deformable registration. Using SAM embeddings, we enhance these steps by finding more coherent correspondences, and providing features and a loss function with better semantic guidance. We collect a multi-phase chest computed tomography dataset with 35 annotated organs for each patient and conduct inter-subject registration for quantitative evaluation. Results show that SAME outperforms widely-used traditional registration techniques (Elastix FFD, ANTs SyN) and learning based VoxelMorph method by at least 4.7% and 2.7% in Dice scores for two separate tasks of within-contrast-phase and across-contrast-phase registration, respectively. SAME achieves the comparable performance to the best traditional registration method, DEEDS (from our evaluation), while being orders of magnitude faster (from 45 seconds to 1.2 seconds).
DeepStationing: Thoracic Lymph Node Station Parsing in CT Scans using Anatomical Context Encoding and Key Organ Auto-Search
Sep 20, 2021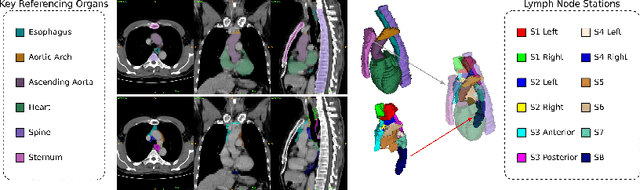
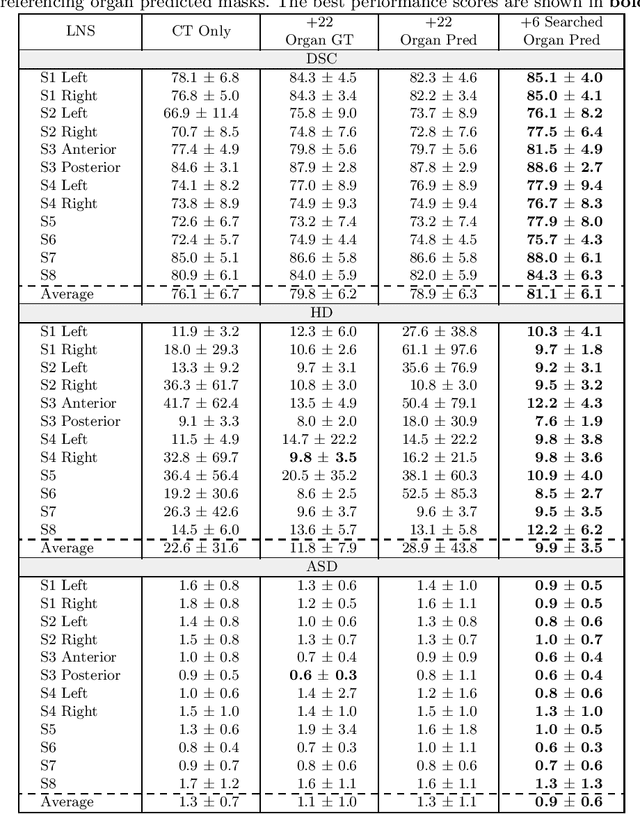
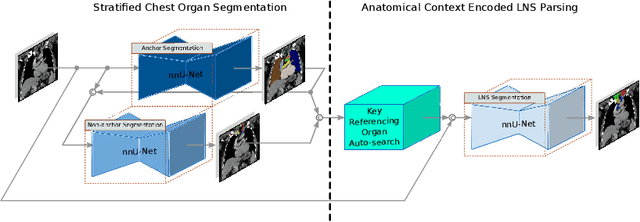
Lymph node station (LNS) delineation from computed tomography (CT) scans is an indispensable step in radiation oncology workflow. High inter-user variabilities across oncologists and prohibitive laboring costs motivated the automated approach. Previous works exploit anatomical priors to infer LNS based on predefined ad-hoc margins. However, without voxel-level supervision, the performance is severely limited. LNS is highly context-dependent - LNS boundaries are constrained by anatomical organs - we formulate it as a deep spatial and contextual parsing problem via encoded anatomical organs. This permits the deep network to better learn from both CT appearance and organ context. We develop a stratified referencing organ segmentation protocol that divides the organs into anchor and non-anchor categories and uses the former's predictions to guide the later segmentation. We further develop an auto-search module to identify the key organs that opt for the optimal LNS parsing performance. Extensive four-fold cross-validation experiments on a dataset of 98 esophageal cancer patients (with the most comprehensive set of 12 LNSs + 22 organs in thoracic region to date) are conducted. Our LNS parsing model produces significant performance improvements, with an average Dice score of 81.1% +/- 6.1%, which is 5.0% and 19.2% higher over the pure CT-based deep model and the previous representative approach, respectively.
A Flexible Three-Dimensional Hetero-phase Computed Tomography Hepatocellular Carcinoma (HCC) Detection Algorithm for Generalizable and Practical HCC Screening
Aug 17, 2021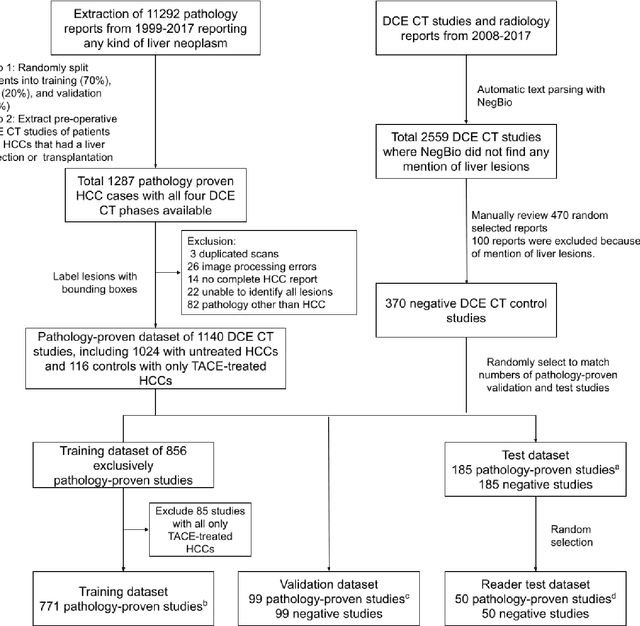
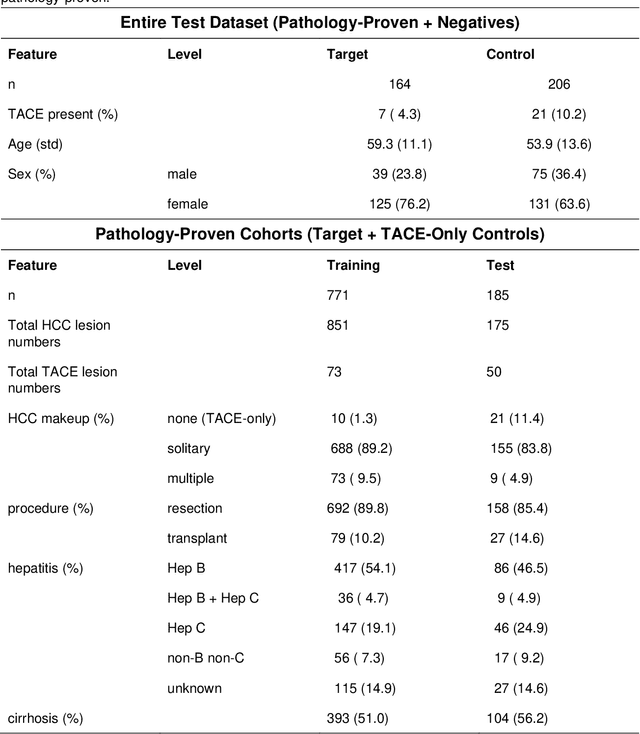
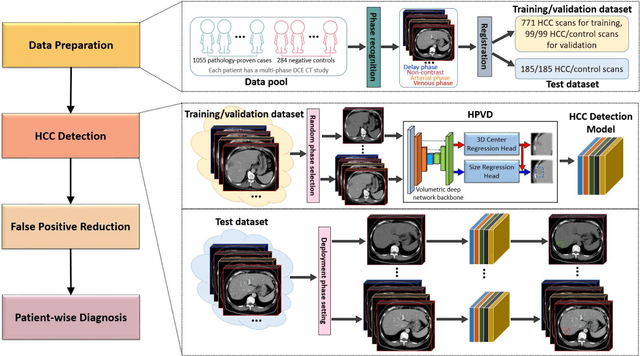
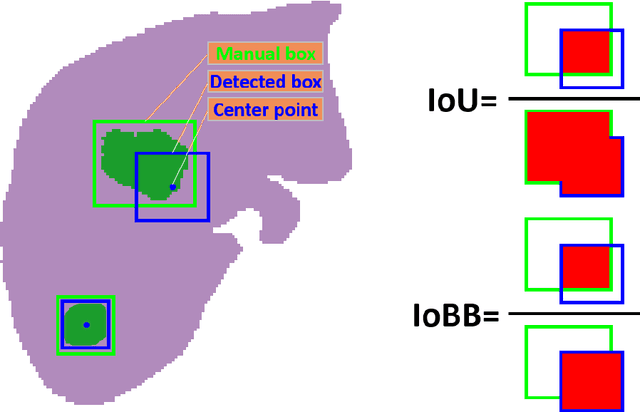
Hepatocellular carcinoma (HCC) can be potentially discovered from abdominal computed tomography (CT) studies under varied clinical scenarios, e.g., fully dynamic contrast enhanced (DCE) studies, non-contrast (NC) plus venous phase (VP) abdominal studies, or NC-only studies. We develop a flexible three-dimensional deep algorithm, called hetero-phase volumetric detection (HPVD), that can accept any combination of contrast-phase inputs and with adjustable sensitivity depending on the clinical purpose. We trained HPVD on 771 DCE CT scans to detect HCCs and tested on external 164 positives and 206 controls, respectively. We compare performance against six clinical readers, including two radiologists, two hepato-pancreatico-biliary (HPB) surgeons, and two hepatologists. The area under curve (AUC) of the localization receiver operating characteristic (LROC) for NC-only, NC plus VP, and full DCE CT yielded 0.71, 0.81, 0.89 respectively. At a high sensitivity operating point of 80% on DCE CT, HPVD achieved 97% specificity, which is comparable to measured physician performance. We also demonstrate performance improvements over more typical and less flexible non hetero-phase detectors. Thus, we demonstrate that a single deep learning algorithm can be effectively applied to diverse HCC detection clinical scenarios.
Lesion Segmentation and RECIST Diameter Prediction via Click-driven Attention and Dual-path Connection
May 05, 2021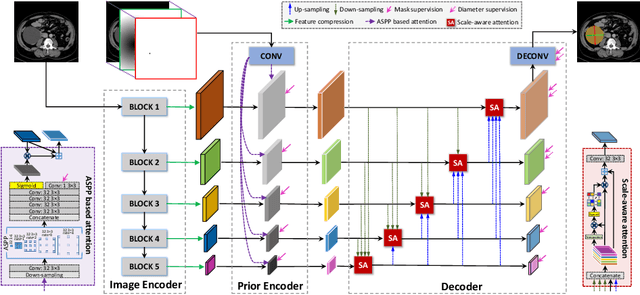
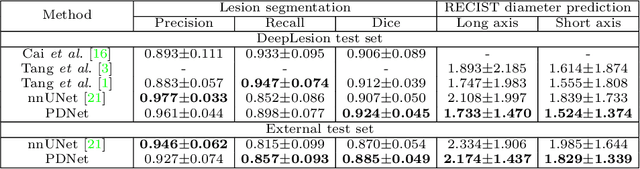
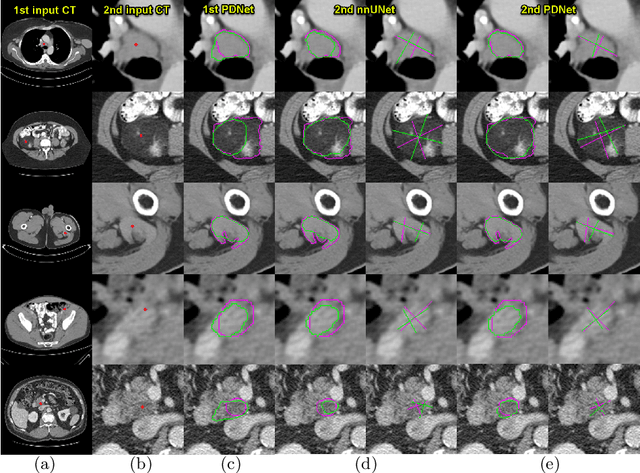
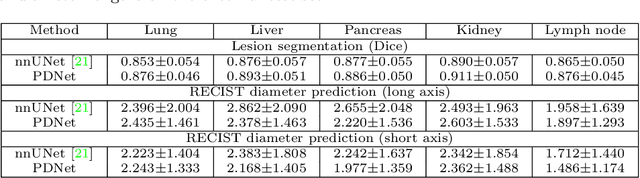
Measuring lesion size is an important step to assess tumor growth and monitor disease progression and therapy response in oncology image analysis. Although it is tedious and highly time-consuming, radiologists have to work on this task by using RECIST criteria (Response Evaluation Criteria In Solid Tumors) routinely and manually. Even though lesion segmentation may be the more accurate and clinically more valuable means, physicians can not manually segment lesions as now since much more heavy laboring will be required. In this paper, we present a prior-guided dual-path network (PDNet) to segment common types of lesions throughout the whole body and predict their RECIST diameters accurately and automatically. Similar to [1], a click guidance from radiologists is the only requirement. There are two key characteristics in PDNet: 1) Learning lesion-specific attention matrices in parallel from the click prior information by the proposed prior encoder, named click-driven attention; 2) Aggregating the extracted multi-scale features comprehensively by introducing top-down and bottom-up connections in the proposed decoder, named dual-path connection. Experiments show the superiority of our proposed PDNet in lesion segmentation and RECIST diameter prediction using the DeepLesion dataset and an external test set. PDNet learns comprehensive and representative deep image features for our tasks and produces more accurate results on both lesion segmentation and RECIST diameter prediction.
Weakly-Supervised Universal Lesion Segmentation with Regional Level Set Loss
May 03, 2021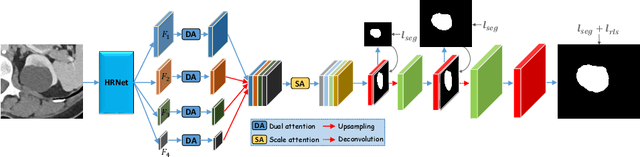
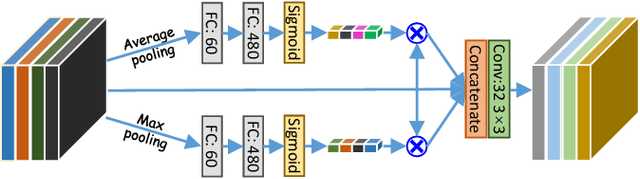
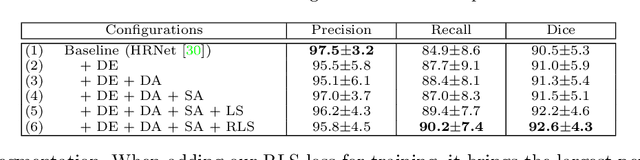
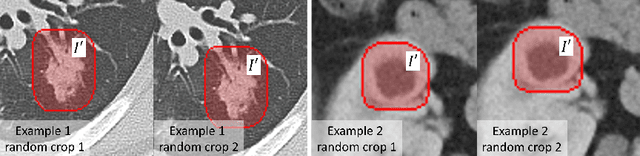
Accurately segmenting a variety of clinically significant lesions from whole body computed tomography (CT) scans is a critical task on precision oncology imaging, denoted as universal lesion segmentation (ULS). Manual annotation is the current clinical practice, being highly time-consuming and inconsistent on tumor's longitudinal assessment. Effectively training an automatic segmentation model is desirable but relies heavily on a large number of pixel-wise labelled data. Existing weakly-supervised segmentation approaches often struggle with regions nearby the lesion boundaries. In this paper, we present a novel weakly-supervised universal lesion segmentation method by building an attention enhanced model based on the High-Resolution Network (HRNet), named AHRNet, and propose a regional level set (RLS) loss for optimizing lesion boundary delineation. AHRNet provides advanced high-resolution deep image features by involving a decoder, dual-attention and scale attention mechanisms, which are crucial to performing accurate lesion segmentation. RLS can optimize the model reliably and effectively in a weakly-supervised fashion, forcing the segmentation close to lesion boundary. Extensive experimental results demonstrate that our method achieves the best performance on the publicly large-scale DeepLesion dataset and a hold-out test set.
Scalable Semi-supervised Landmark Localization for X-ray Images using Few-shot Deep Adaptive Graph
Apr 29, 2021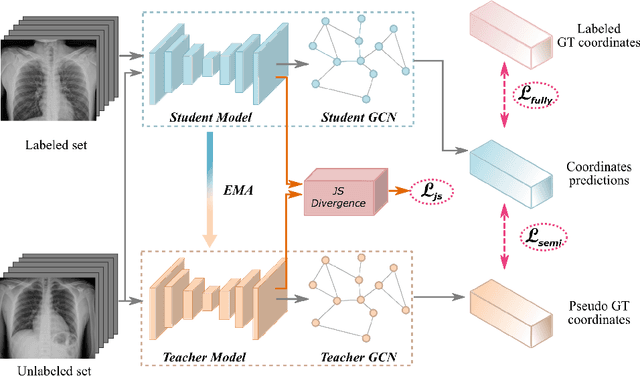
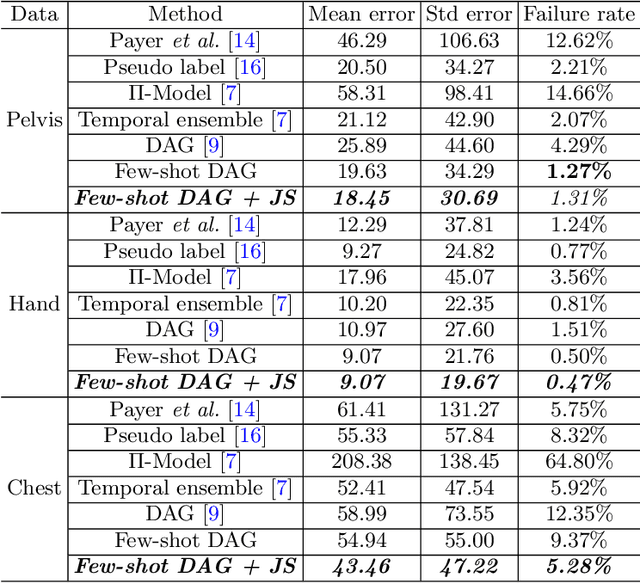
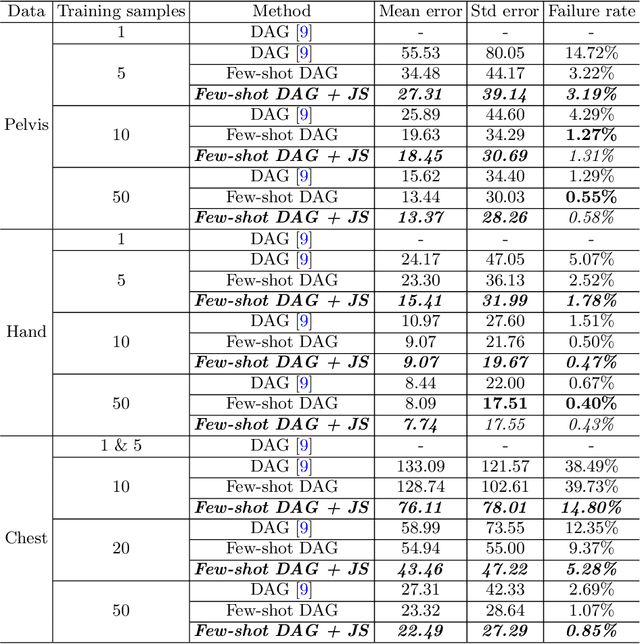
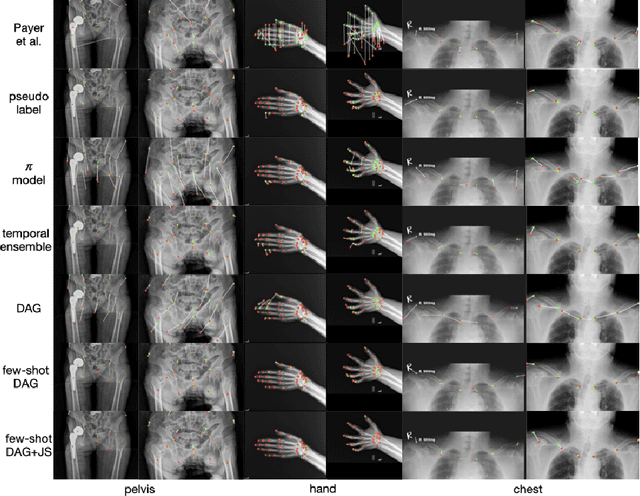
Landmark localization plays an important role in medical image analysis. Learning based methods, including CNN and GCN, have demonstrated the state-of-the-art performance. However, most of these methods are fully-supervised and heavily rely on manual labeling of a large training dataset. In this paper, based on a fully-supervised graph-based method, DAG, we proposed a semi-supervised extension of it, termed few-shot DAG, \ie five-shot DAG. It first trains a DAG model on the labeled data and then fine-tunes the pre-trained model on the unlabeled data with a teacher-student SSL mechanism. In addition to the semi-supervised loss, we propose another loss using JS divergence to regulate the consistency of the intermediate feature maps. We extensively evaluated our method on pelvis, hand and chest landmark detection tasks. Our experiment results demonstrate consistent and significant improvements over previous methods.
Learning from Subjective Ratings Using Auto-Decoded Deep Latent Embeddings
Apr 16, 2021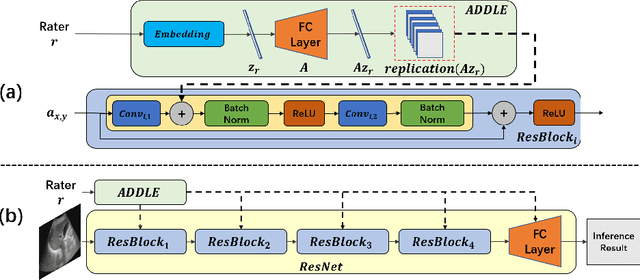
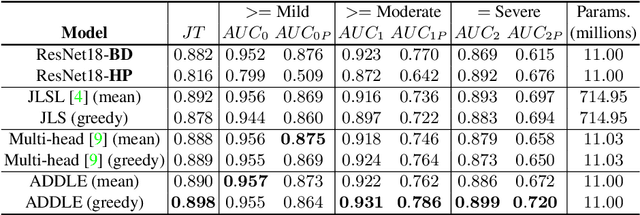
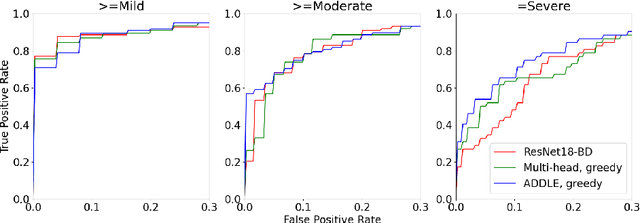
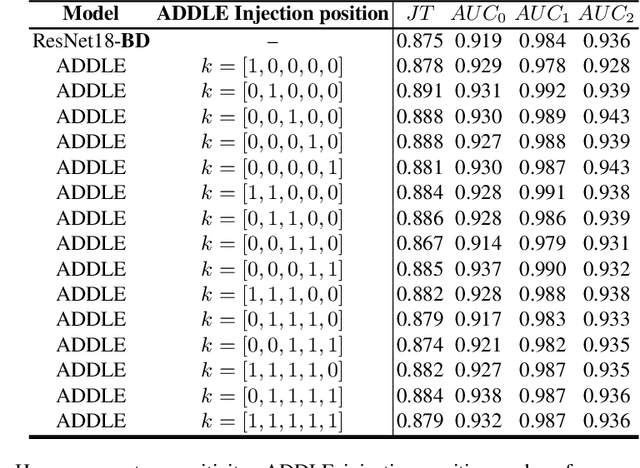
Depending on the application, radiological diagnoses can be associated with high inter- and intra-rater variabilities. Most computer-aided diagnosis (CAD) solutions treat such data as incontrovertible, exposing learning algorithms to considerable and possibly contradictory label noise and biases. Thus, managing subjectivity in labels is a fundamental problem in medical imaging analysis. To address this challenge, we introduce auto-decoded deep latent embeddings (ADDLE), which explicitly models the tendencies of each rater using an auto-decoder framework. After a simple linear transformation, the latent variables can be injected into any backbone at any and multiple points, allowing the model to account for rater-specific effects on the diagnosis. Importantly, ADDLE does not expect multiple raters per image in training, meaning it can readily learn from data mined from hospital archives. Moreover, the complexity of training ADDLE does not increase as more raters are added. During inference each rater can be simulated and a 'mean' or 'greedy' virtual rating can be produced. We test ADDLE on the problem of liver steatosis diagnosis from 2D ultrasound (US) by collecting 46 084 studies along with clinical US diagnoses originating from 65 different raters. We evaluated diagnostic performance using a separate dataset with gold-standard biopsy diagnoses. ADDLE can improve the partial areas under the curve (AUCs) for diagnosing severe steatosis by 10.5% over standard classifiers while outperforming other annotator-noise approaches, including those requiring 65 times the parameters.
Deep Implicit Statistical Shape Models for 3D Medical Image Delineation
Apr 07, 2021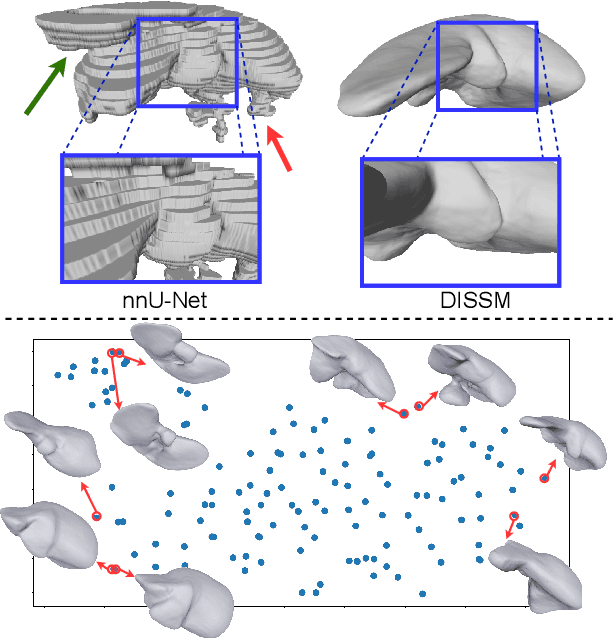
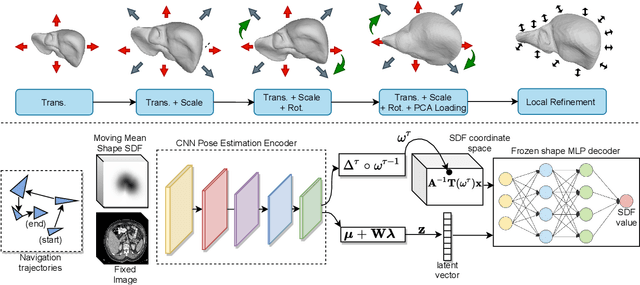

3D delineation of anatomical structures is a cardinal goal in medical imaging analysis. Prior to deep learning, statistical shape models that imposed anatomical constraints and produced high quality surfaces were a core technology. Prior to deep learning, statistical shape models that imposed anatomical constraints and produced high quality surfaces were a core technology. Today fully-convolutional networks (FCNs), while dominant, do not offer these capabilities. We present deep implicit statistical shape models (DISSMs), a new approach to delineation that marries the representation power of convolutional neural networks (CNNs) with the robustness of SSMs. DISSMs use a deep implicit surface representation to produce a compact and descriptive shape latent space that permits statistical models of anatomical variance. To reliably fit anatomically plausible shapes to an image, we introduce a novel rigid and non-rigid pose estimation pipeline that is modelled as a Markov decision process(MDP). We outline a training regime that includes inverted episodic training and a deep realization of marginal space learning (MSL). Intra-dataset experiments on the task of pathological liver segmentation demonstrate that DISSMs can perform more robustly than three leading FCN models, including nnU-Net: reducing the mean Hausdorff distance (HD) by 7.7-14.3mm and improving the worst case Dice-Sorensen coefficient (DSC) by 1.2-2.3%. More critically, cross-dataset experiments on a dataset directly reflecting clinical deployment scenarios demonstrate that DISSMs improve the mean DSC and HD by 3.5-5.9% and 12.3-24.5mm, respectively, and the worst-case DSC by 5.4-7.3%. These improvements are over and above any benefits from representing delineations with high-quality surface.
Opportunistic Screening of Osteoporosis Using Plain Film Chest X-ray
Apr 05, 2021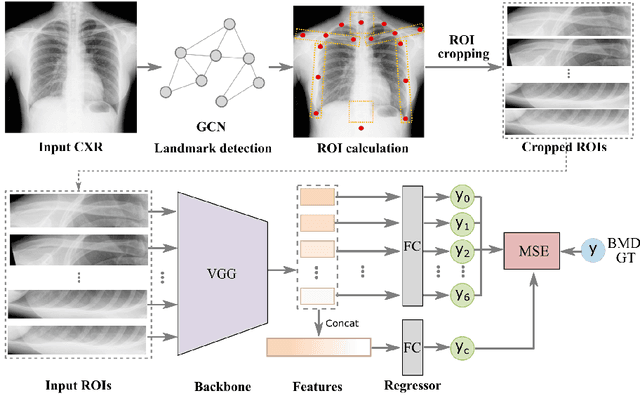
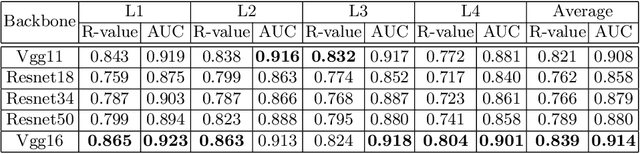
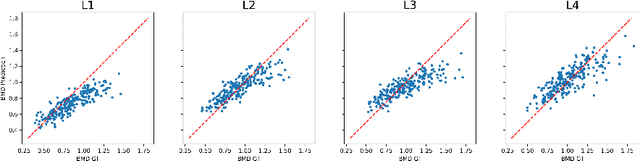
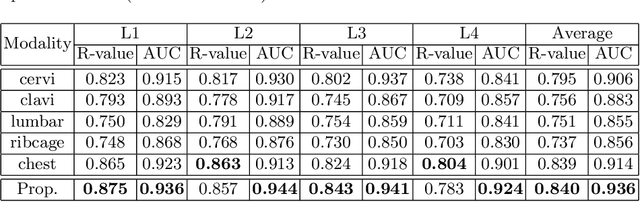
Osteoporosis is a common chronic metabolic bone disease that is often under-diagnosed and under-treated due to the limited access to bone mineral density (BMD) examinations, Dual-energy X-ray Absorptiometry (DXA). In this paper, we propose a method to predict BMD from Chest X-ray (CXR), one of the most common, accessible, and low-cost medical image examinations. Our method first automatically detects Regions of Interest (ROIs) of local and global bone structures from the CXR. Then a multi-ROI model is developed to exploit both local and global information in the chest X-ray image for accurate BMD estimation. Our method is evaluated on 329 CXR cases with ground truth BMD measured by DXA. The model predicted BMD has a strong correlation with the gold standard DXA BMD (Pearson correlation coefficient 0.840). When applied for osteoporosis screening, it achieves a high classification performance (AUC 0.936). As the first effort in the field to use CXR scans to predict the spine BMD, the proposed algorithm holds strong potential in enabling early osteoporosis screening through routine chest X-rays and contributing to the enhancement of public health.