 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaFrame: Adaptive Frame Selection for Fast Video Recognition
Nov 29, 2018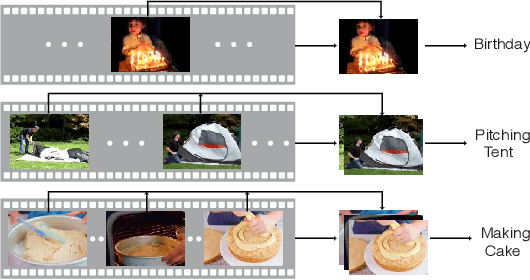
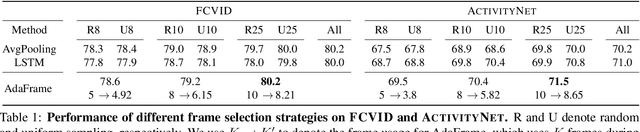
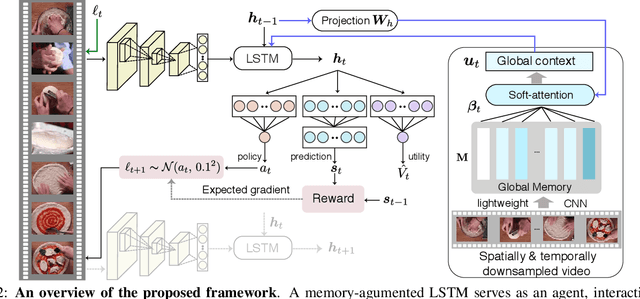
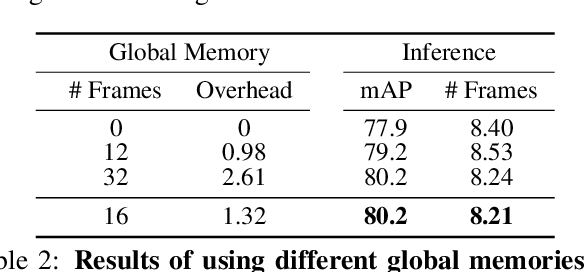
We present AdaFrame, a framework that adaptively selects relevant frames on a per-input basis for fast video recognition. AdaFrame contains a Long Short-Term Memory network augmented with a global memory that provides context information for searching which frames to use over time. Trained with policy gradient methods, AdaFrame generates a prediction, determines which frame to observe next, and computes the utility, i.e., expected future rewards, of seeing more frames at each time step. At testing time, AdaFrame exploits predicted utilities to achieve adaptive lookahead inference such that the overall computational costs are reduced without incurring a decrease in accuracy. Extensive experiments are conducted on two large-scale video benchmarks, FCVID and AvtivityNet. AdaFrame matches the performance of using all frames with only 8.21 and 8.65 frames on FCVID and AvtivityNet, respectively. We further qualitatively demonstrate learned frame usage can indicate the difficulty of making classification decisions; easier samples need fewer frames while harder ones require more, both at instance-level within the same class and at class-level among different categories.
Universal Adversarial Training
Nov 27, 2018
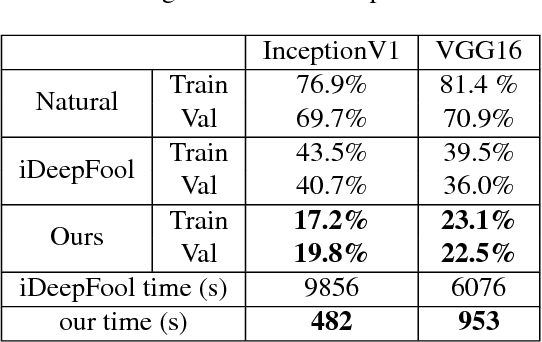
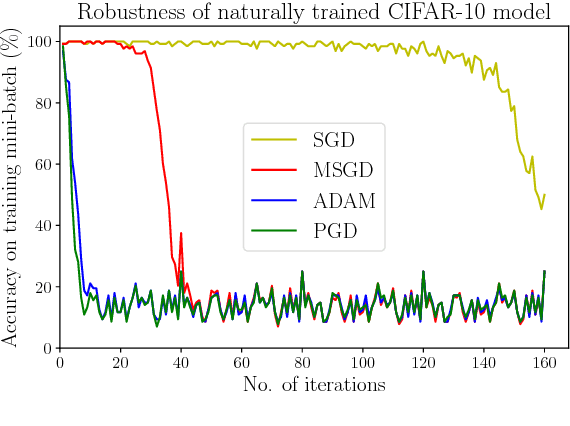
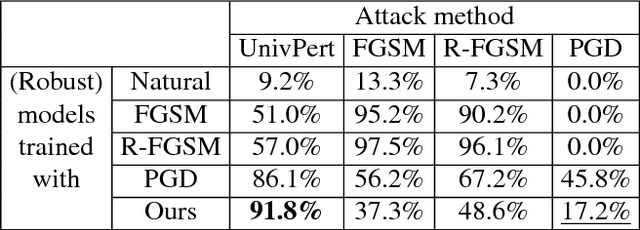
Standard adversarial attacks change the predicted class label of an image by adding specially tailored small perturbations to its pixels. In contrast, a universal perturbation is an update that can be added to any image in a broad class of images, while still changing the predicted class label. We study the efficient generation of universal adversarial perturbations, and also efficient methods for hardening networks to these attacks. We propose a simple optimization-based universal attack that reduces the top-1 accuracy of various network architectures on ImageNet to less than 20%, while learning the universal perturbation 13X faster than the standard method. To defend against these perturbations, we propose universal adversarial training, which models the problem of robust classifier generation as a two-player min-max game. This method is much faster and more scalable than conventional adversarial training with a strong adversary (PGD), and yet yields models that are extremely resistant to universal attacks, and comparably resistant to standard (per-instance) black box attacks. We also discover a rather fascinating side-effect of universal adversarial training: attacks built for universally robust models transfer better to other (black box) models than those built with conventional adversarial training.
Generate, Segment and Replace: Towards Generic Manipulation Segmentation
Nov 24, 2018
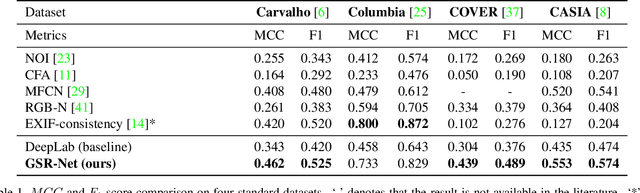
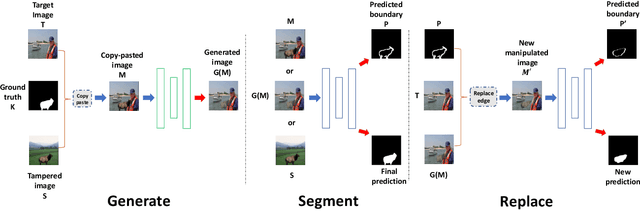
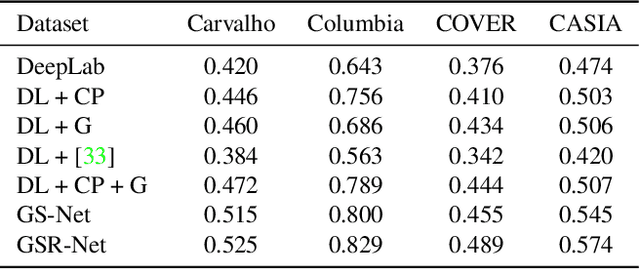
It has been witnessed an emerging demand for image manipulation segmentation to distinguish between fake images produced by advanced photo editing software and authentic ones. In this paper, we describe an approach based on semantic segmentation for detecting image manipulation. The approach consists of three stages. A generation stage generates hard manipulated images from authentic images using a Generative Adversarial Network (GAN) based model by cutting a region out of a training sample, pasting it into an authentic image and then passing the image through a GAN to generate harder true positive tampered region. A segmentation stage and a replacement stage, sharing weights with each other, then collaboratively construct dense predictions of tampered regions. We achieve state-of-the-art performance on four public image manipulation detection benchmarks while maintaining robustness to various attacks.
Explicit Bias Discovery in Visual Question Answering Models
Nov 19, 2018

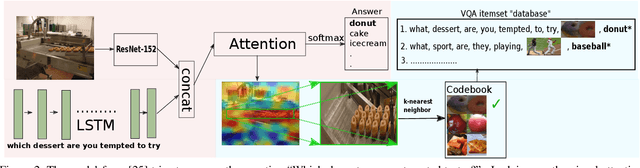

Researchers have observed that Visual Question Answering (VQA) models tend to answer questions by learning statistical biases in the data. For example, their answer to the question "What is the color of the grass?" is usually "Green", whereas a question like "What is the title of the book?" cannot be answered by inferring statistical biases. It is of interest to the community to explicitly discover such biases, both for understanding the behavior of such models, and towards debugging them. Our work address this problem. In a database, we store the words of the question, answer and visual words corresponding to regions of interest in attention maps. By running simple rule mining algorithms on this database, we discover human-interpretable rules which give us unique insight into the behavior of such models. Our results also show examples of unusual behaviors learned by models in attempting VQA tasks.
Modeling Local Geometric Structure of 3D Point Clouds using Geo-CNN
Nov 19, 2018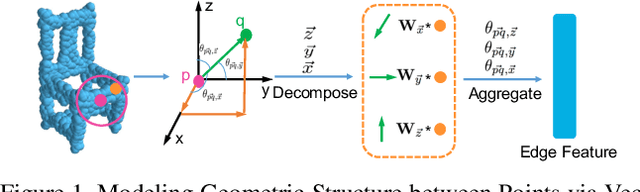
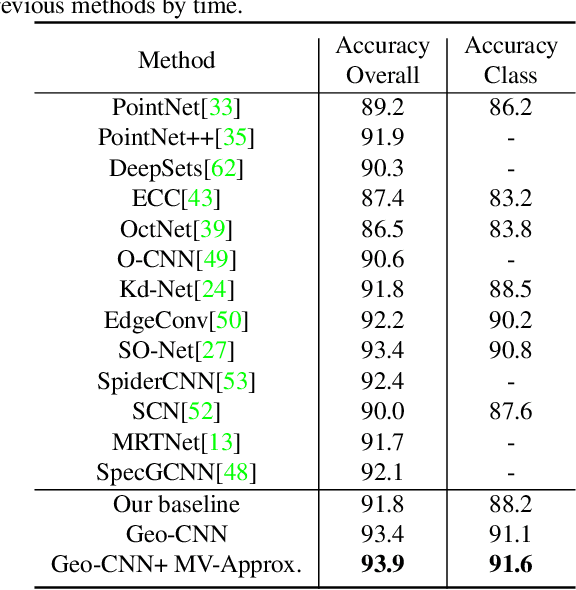
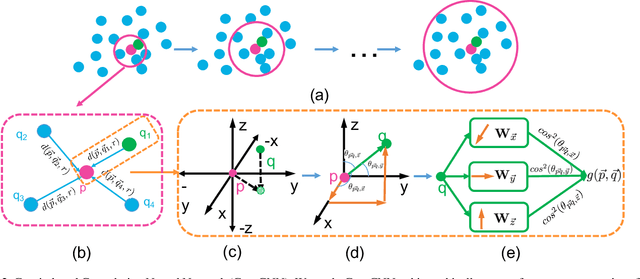
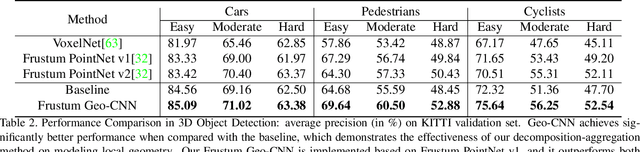
Recent advances in deep convolutional neural networks (CNNs) have motivated researchers to adapt CNNs to directly model points in 3D point clouds. Modeling local structure has been proven to be important for the success of convolutional architectures, and researchers exploited the modeling of local point sets in the feature extraction hierarchy. However, limited attention has been paid to explicitly model the geometric structure amongst points in a local region. To address this problem, we propose Geo-CNN, which applies a generic convolution-like operation dubbed as GeoConv to each point and its local neighborhood. Local geometric relationships among points are captured when extracting edge features between the center and its neighboring points. We first decompose the edge feature extraction process onto three orthogonal bases, and then aggregate the extracted features based on the angles between the edge vector and the bases. This encourages the network to preserve the geometric structure in Euclidean space throughout the feature extraction hierarchy. GeoConv is a generic and efficient operation that can be easily integrated into 3D point cloud analysis pipelines for multiple applications. We evaluate Geo-CNN on ModelNet40 and KITTI and achieve state-of-the-art performance.
Temporal Recurrent Networks for Online Action Detection
Nov 18, 2018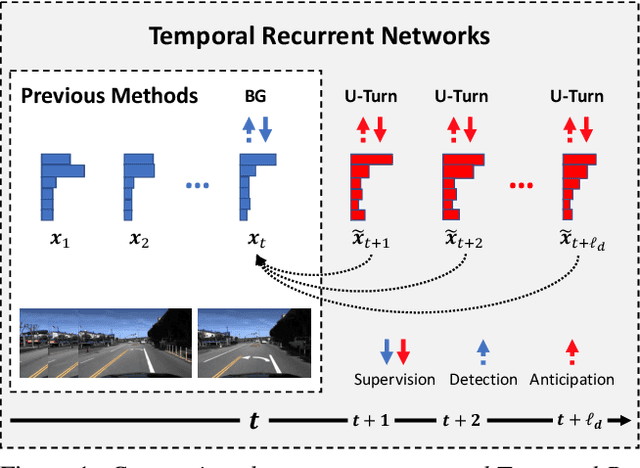
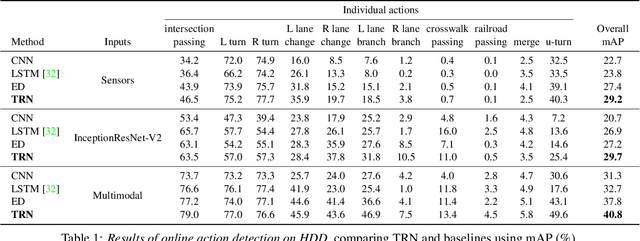
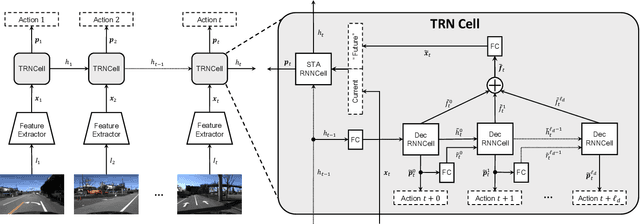
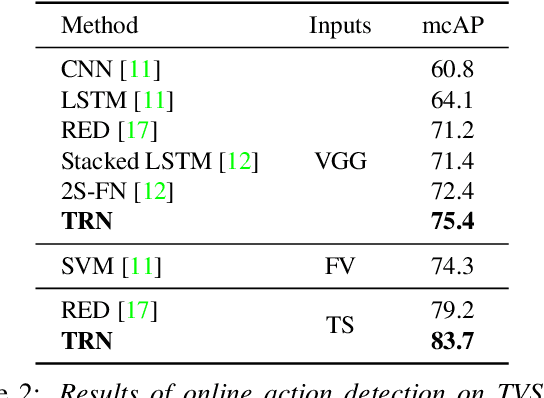
Most work on temporal action detection is formulated in an offline manner, in which the start and end times of actions are determined after the entire video is fully observed. However, real-time applications including surveillance and driver assistance systems require identifying actions as soon as each video frame arrives, based only on current and historical observations. In this paper, we propose a novel framework, Temporal Recurrent Networks (TRNs), to model greater temporal context of a video frame by simultaneously performing online action detection and anticipation of the immediate future. At each moment in time, our approach makes use of both accumulated historical evidence and predicted future information to better recognize the action that is currently occurring, and integrates both of these into a unified end-to-end architecture. We evaluate our approach on two popular online action detection datasets, HDD and TVSeries, as well as another widely used dataset, THUMOS'14. The results show that TRN significantly outperforms the state-of-the-art.
Improving Annotation for 3D Pose Dataset of Fine-Grained Object Categories
Oct 19, 2018


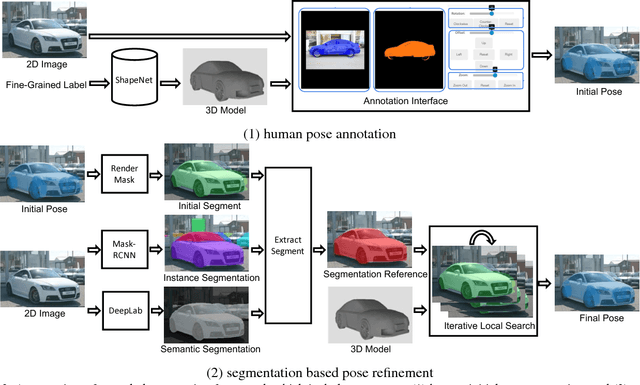
Existing 3D pose datasets of object categories are limited to generic object types and lack of fine-grained information. In this work, we introduce a new large-scale dataset that consists of 409 fine-grained categories and 31,881 images with accurate 3D pose annotation. Specifically, we augment three existing fine-grained object recognition datasets (StanfordCars, CompCars and FGVC-Aircraft) by finding a specific 3D model for each sub-category from ShapeNet and manually annotating each 2D image by adjusting a full set of 7 continuous perspective parameters. Since the fine-grained shapes allow 3D models to better fit the images, we further improve the annotation quality by initializing from the human annotation and conducting local search of the pose parameters with the objective of maximizing the IoUs between the projected mask and the segmentation reference estimated from state-of-the-art deep Convolutional Neural Networks (CNNs). We provide full statistics of the annotations with qualitative and quantitative comparisons suggesting that our dataset can be a complementary source for studying 3D pose estimation. The dataset can be downloaded at http://users.umiacs.umd.edu/~wym/3dpose.html.
C-WSL: Count-guided Weakly Supervised Localization
Jul 25, 2018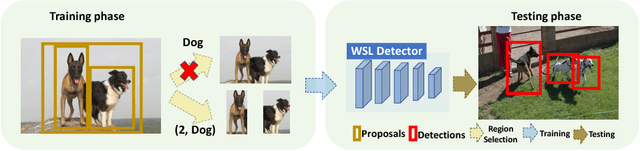
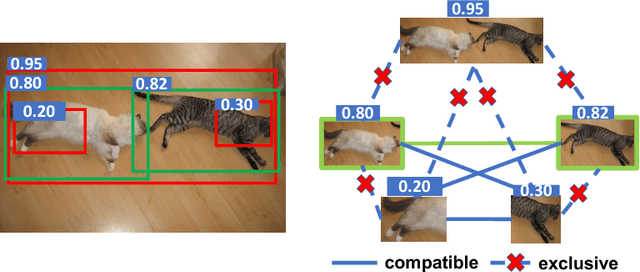
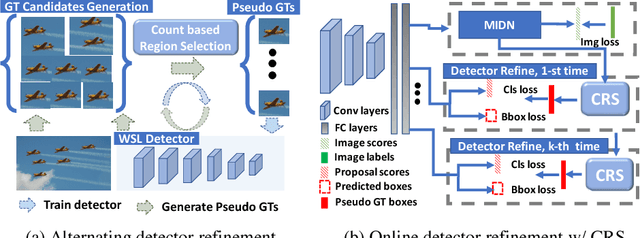
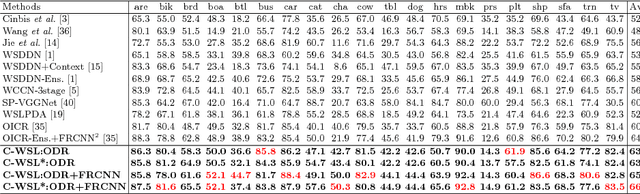
We introduce count-guided weakly supervised localization (C-WSL), an approach that uses per-class object count as a new form of supervision to improve weakly supervised localization (WSL). C-WSL uses a simple count-based region selection algorithm to select high-quality regions, each of which covers a single object instance during training, and improves existing WSL methods by training with the selected regions. To demonstrate the effectiveness of C-WSL, we integrate it into two WSL architectures and conduct extensive experiments on VOC2007 and VOC2012. Experimental results show that C-WSL leads to large improvements in WSL and that the proposed approach significantly outperforms the state-of-the-art methods. The results of annotation experiments on VOC2007 suggest that a modest extra time is needed to obtain per-class object counts compared to labeling only object categories in an image. Furthermore, we reduce the annotation time by more than $2\times$ and $38\times$ compared to center-click and bounding-box annotations.
Soft Sampling for Robust Object Detection
Jun 18, 2018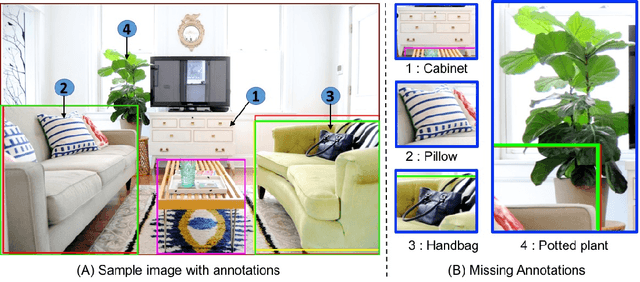
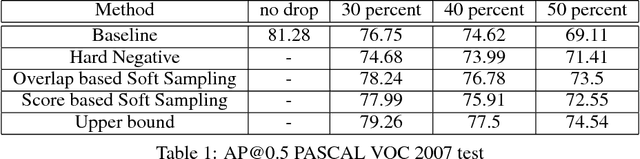
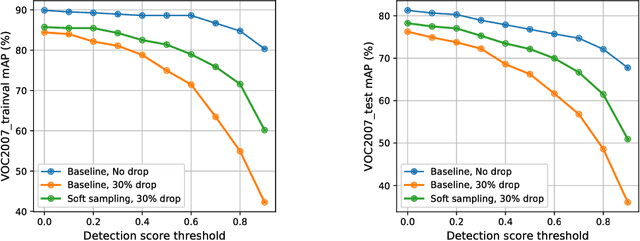
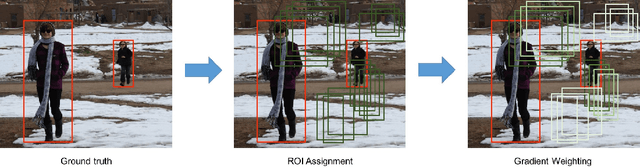
We study the robustness of object detection under the presence of missing annotations. In this setting, the unlabeled object instances will be treated as background, which will generate an incorrect training signal for the detector. Interestingly, we observe that after dropping 30% of the annotations (and labeling them as background), the performance of CNN-based object detectors like Faster-RCNN only drops by 5% on the PASCAL VOC dataset. We provide a detailed explanation for this result. To further bridge the performance gap, we propose a simple yet effective solution, called Soft Sampling. Soft Sampling re-weights the gradients of RoIs as a function of overlap with positive instances. This ensures that the uncertain background regions are given a smaller weight compared to the hardnegatives. Extensive experiments on curated PASCAL VOC datasets demonstrate the effectiveness of the proposed Soft Sampling method at different annotation drop rates. Finally, we show that on OpenImagesV3, which is a real-world dataset with missing annotations, Soft Sampling outperforms standard detection baselines by over 3%.
SNIPER: Efficient Multi-Scale Training
Jun 18, 2018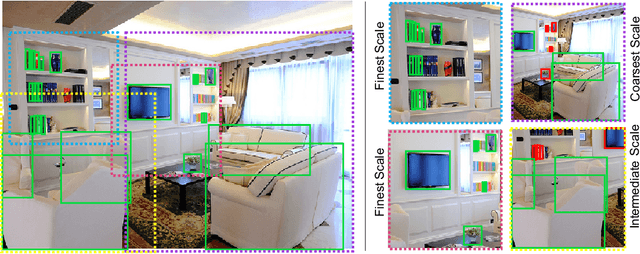



We present SNIPER, an algorithm for performing efficient multi-scale training in instance level visual recognition tasks. Instead of processing every pixel in an image pyramid, SNIPER processes context regions around ground-truth instances (referred to as chips) at the appropriate scale. For background sampling, these context-regions are generated using proposals extracted from a region proposal network trained with a short learning schedule. Hence, the number of chips generated per image during training adaptively changes based on the scene complexity. SNIPER only processes 30% more pixels compared to the commonly used single scale training at 800x1333 pixels on the COCO dataset. But, it also observes samples from extreme resolutions of the image pyramid, like 1400x2000 pixels. As SNIPER operates on resampled low resolution chips (512x512 pixels), it can have a batch size as large as 20 on a single GPU even with a ResNet-101 backbone. Therefore it can benefit from batch-normalization during training without the need for synchronizing batch-normalization statistics across GPUs. SNIPER brings training of instance level recognition tasks like object detection closer to the protocol for image classification and suggests that the commonly accepted guideline that it is important to train on high resolution images for instance level visual recognition tasks might not be correct. Our implementation based on Faster-RCNN with a ResNet-101 backbone obtains an mAP of 47.6% on the COCO dataset for bounding box detection and can process 5 images per second with a single GPU. The code is available at https://github.com/MahyarNajibi/SNIPER.