 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributing Fake Images to GANs: Analyzing Fingerprints in Generated Images
Nov 20, 2018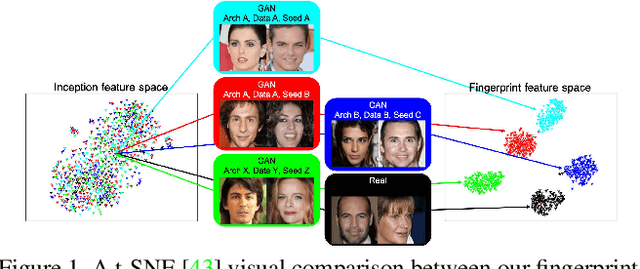
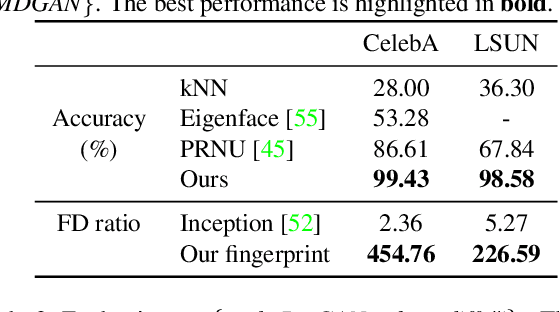
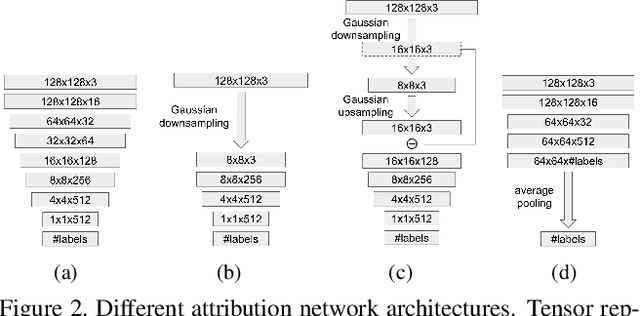
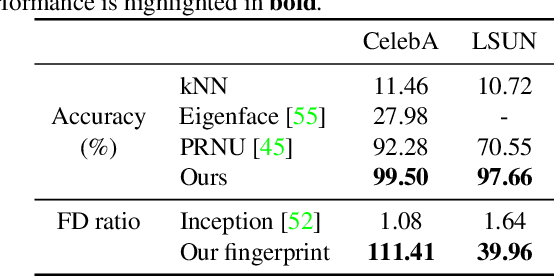
Research in computer graphics has been in pursuit of realistic image generation for a long time. Recent advances in machine learning with deep generative models have shown increasing success of closing the realism gap by using data-driven and learned components. There is an increasing concern that real and fake images will become more and more difficult to tell apart. We take a first step towards this larger research challenge by asking the question if and to what extend a generated fake image can be attribute to a particular Generative Adversarial Networks (GANs) of a certain architecture and trained with particular data and random seed. Our analysis shows single samples from GANs carry highly characteristic fingerprints which make attribution of images to GANs possible. Surprisingly, this is even possible for GANs with same architecture and same training that only differ by the training seed.
Two Stream Self-Supervised Learning for Action Recognition
Jun 16, 2018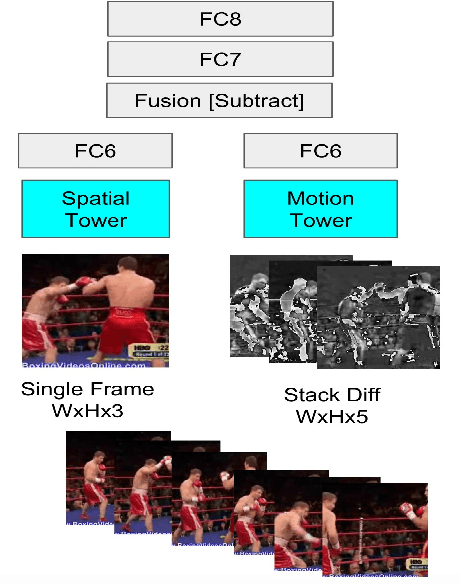
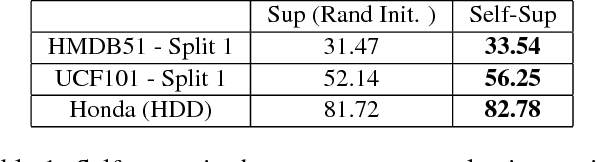

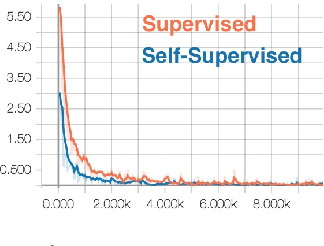
We present a self-supervised approach using spatio-temporal signals between video frames for action recognition. A two-stream architecture is leveraged to tangle spatial and temporal representation learning. Our task is formulated as both a sequence verification and spatio-temporal alignment tasks. The former task requires motion temporal structure understanding while the latter couples the learned motion with the spatial representation. The self-supervised pre-trained weights effectiveness is validated on the action recognition task. Quantitative evaluation shows the self-supervised approach competence on three datasets: HMDB51, UCF101, and Honda driving dataset (HDD). Further investigations to boost performance and generalize validity are still required.
Fused Deep Neural Networks for Efficient Pedestrian Detection
May 02, 2018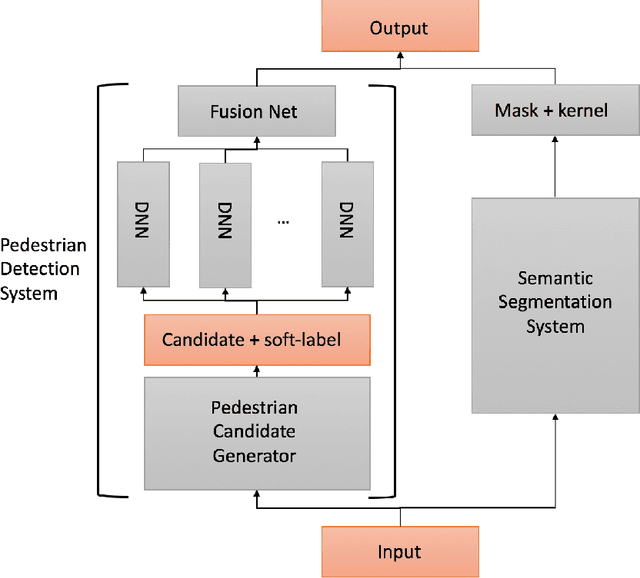
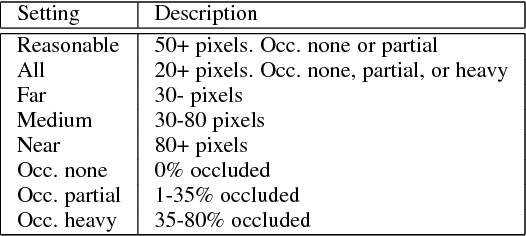
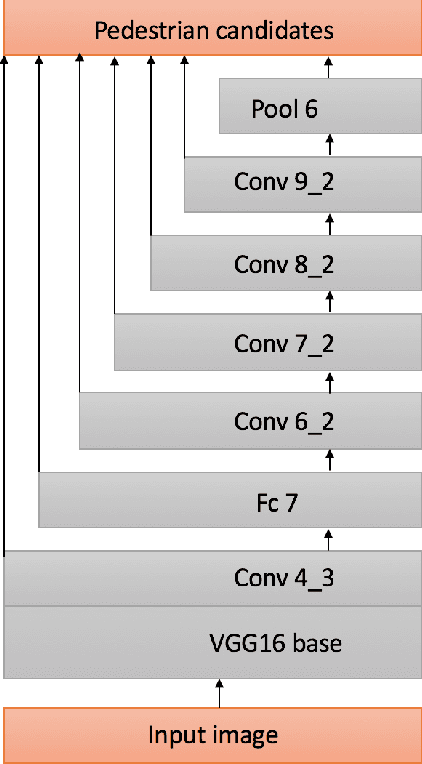
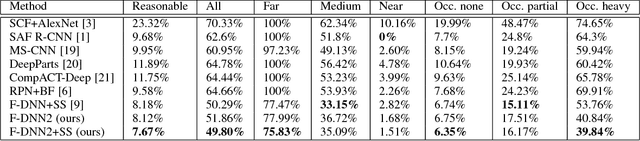
In this paper, we present an efficient pedestrian detection system, designed by fusion of multiple deep neural network (DNN) systems. Pedestrian candidates are first generated by a single shot convolutional multi-box detector at different locations with various scales and aspect ratios. The candidate generator is designed to provide the majority of ground truth pedestrian annotations at the cost of a large number of false positives. Then, a classification system using the idea of ensemble learning is deployed to improve the detection accuracy. The classification system further classifies the generated candidates based on opinions of multiple deep verification networks and a fusion network which utilizes a novel soft-rejection fusion method to adjust the confidence in the detection results. To improve the training of the deep verification networks, a novel soft-label method is devised to assign floating point labels to the generated pedestrian candidates. A deep context aggregation semantic segmentation network also provides pixel-level classification of the scene and its results are softly fused with the detection results by the single shot detector. Our pedestrian detector compared favorably to state-of-art methods on all popular pedestrian detection datasets. For example, our fused DNN has better detection accuracy on the Caltech Pedestrian dataset than all previous state of art methods, while also being the fastest. We significantly improved the log-average miss rate on the Caltech pedestrian dataset to 7.67% and achieved the new state-of-the-art.
Learning to Color from Language
Apr 17, 2018

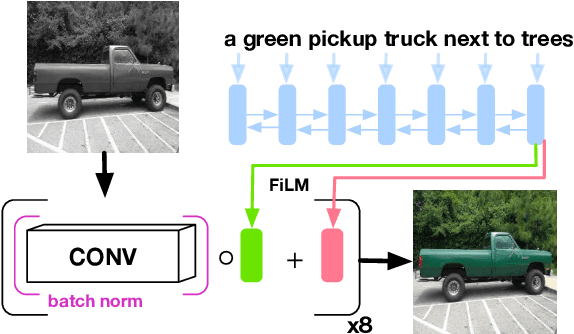

Automatic colorization is the process of adding color to greyscale images. We condition this process on language, allowing end users to manipulate a colorized image by feeding in different captions. We present two different architectures for language-conditioned colorization, both of which produce more accurate and plausible colorizations than a language-agnostic version. Through this language-based framework, we can dramatically alter colorizations by manipulating descriptive color words in captions.
* 6 pages
Deep Motion Boundary Detection
Apr 13, 2018



Motion boundary detection is a crucial yet challenging problem. Prior methods focus on analyzing the gradients and distributions of optical flow fields, or use hand-crafted features for motion boundary learning. In this paper, we propose the first dedicated end-to-end deep learning approach for motion boundary detection, which we term as MoBoNet. We introduce a refinement network structure which takes source input images, initial forward and backward optical flows as well as corresponding warping errors as inputs and produces high-resolution motion boundaries. Furthermore, we show that the obtained motion boundaries, through a fusion sub-network we design, can in turn guide the optical flows for removing the artifacts. The proposed MoBoNet is generic and works with any optical flows. Our motion boundary detection and the refined optical flow estimation achieve results superior to the state of the art.
Boundary-sensitive Network for Portrait Segmentation
Apr 09, 2018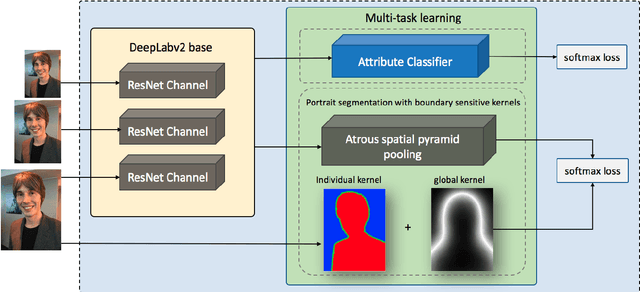



Compared to the general semantic segmentation problem, portrait segmentation has higher precision requirement on boundary area. However, this problem has not been well studied in previous works. In this paper, we propose a boundary-sensitive deep neural network (BSN) for portrait segmentation. BSN introduces three novel techniques. First, an individual boundary-sensitive kernel is proposed by dilating the contour line and assigning the boundary pixels with multi-class labels. Second, a global boundary-sensitive kernel is employed as a position sensitive prior to further constrain the overall shape of the segmentation map. Third, we train a boundary-sensitive attribute classifier jointly with the segmentation network to reinforce the network with semantic boundary shape information. We have evaluated BSN on the current largest public portrait segmentation dataset, i.e, the PFCN dataset, as well as the portrait images collected from other three popular image segmentation datasets: COCO, COCO-Stuff, and PASCAL VOC. Our method achieves the superior quantitative and qualitative performance over state-of-the-arts on all the datasets, especially on the boundary area.
Class Subset Selection for Transfer Learning using Submodularity
Mar 30, 2018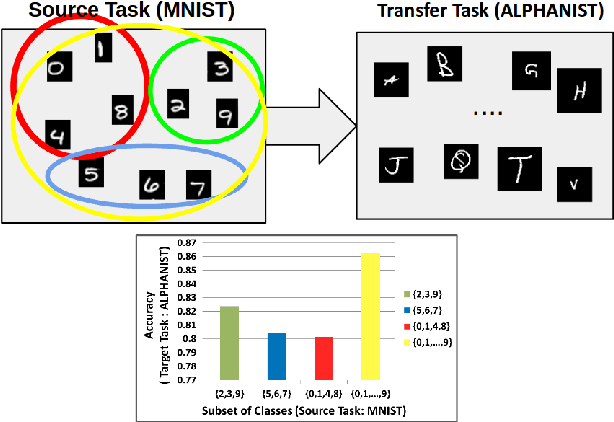
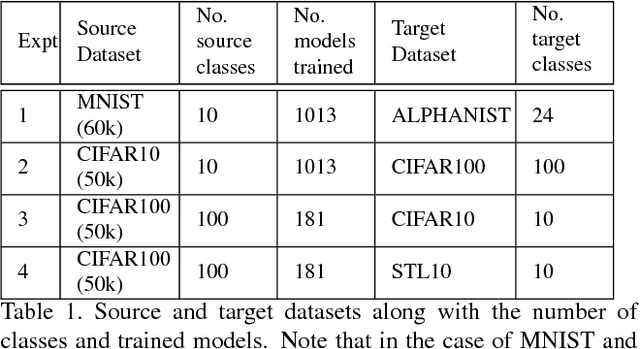

In recent years, it is common practice to extract fully-connected layer (fc) features that were learned while performing image classification on a source dataset, such as ImageNet, and apply them generally to a wide range of other tasks. The general usefulness of some large training datasets for transfer learning is not yet well understood, and raises a number of questions. For example, in the context of transfer learning, what is the role of a specific class in the source dataset, and how is the transferability of fc features affected when they are trained using various subsets of the set of all classes in the source dataset? In this paper, we address the question of how to select an optimal subset of the set of classes, subject to a budget constraint, that will more likely generate good features for other tasks. To accomplish this, we use a submodular set function to model the accuracy achievable on a new task when the features have been learned on a given subset of classes of the source dataset. An optimal subset is identified as the set that maximizes this submodular function. The maximization can be accomplished using an efficient greedy algorithm that comes with guarantees on the optimality of the solution. We empirically validate our submodular model by successfully identifying subsets of classes that produce good features for new tasks.
Face-MagNet: Magnifying Feature Maps to Detect Small Faces
Mar 14, 2018
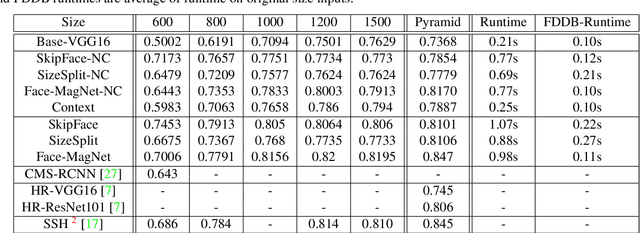
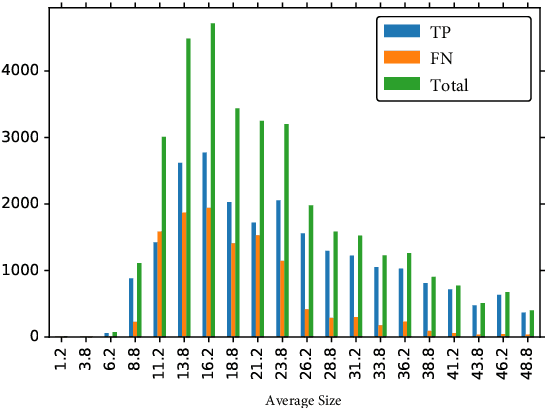
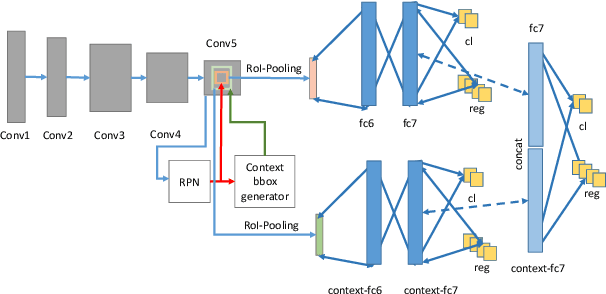
In this paper, we introduce the Face Magnifier Network (Face-MageNet), a face detector based on the Faster-RCNN framework which enables the flow of discriminative information of small scale faces to the classifier without any skip or residual connections. To achieve this, Face-MagNet deploys a set of ConvTranspose, also known as deconvolution, layers in the Region Proposal Network (RPN) and another set before the Region of Interest (RoI) pooling layer to facilitate detection of finer faces. In addition, we also design, train, and evaluate three other well-tuned architectures that represent the conventional solutions to the scale problem: context pooling, skip connections, and scale partitioning. Each of these three networks achieves comparable results to the state-of-the-art face detectors. With extensive experiments, we show that Face-MagNet based on a VGG16 architecture achieves better results than the recently proposed ResNet101-based HR method on the task of face detection on WIDER dataset and also achieves similar results on the hard set as our other method SSH.
SSH: Single Stage Headless Face Detector
Oct 18, 2017
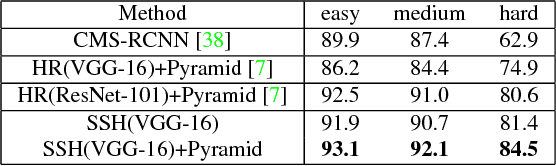
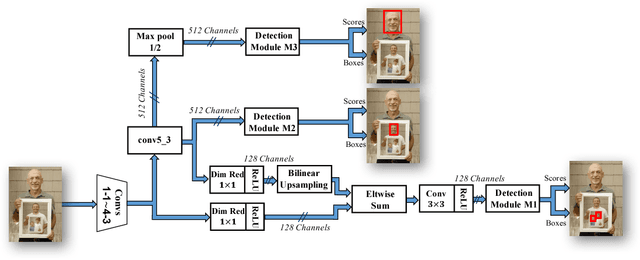

We introduce the Single Stage Headless (SSH) face detector. Unlike two stage proposal-classification detectors, SSH detects faces in a single stage directly from the early convolutional layers in a classification network. SSH is headless. That is, it is able to achieve state-of-the-art results while removing the "head" of its underlying classification network -- i.e. all fully connected layers in the VGG-16 which contains a large number of parameters. Additionally, instead of relying on an image pyramid to detect faces with various scales, SSH is scale-invariant by design. We simultaneously detect faces with different scales in a single forward pass of the network, but from different layers. These properties make SSH fast and light-weight. Surprisingly, with a headless VGG-16, SSH beats the ResNet-101-based state-of-the-art on the WIDER dataset. Even though, unlike the current state-of-the-art, SSH does not use an image pyramid and is 5X faster. Moreover, if an image pyramid is deployed, our light-weight network achieves state-of-the-art on all subsets of the WIDER dataset, improving the AP by 2.5%. SSH also reaches state-of-the-art results on the FDDB and Pascal-Faces datasets while using a small input size, leading to a runtime of 50 ms/image on a GPU. The code is available at https://github.com/mahyarnajibi/SSH.
The Amazing Mysteries of the Gutter: Drawing Inferences Between Panels in Comic Book Narratives
May 07, 2017
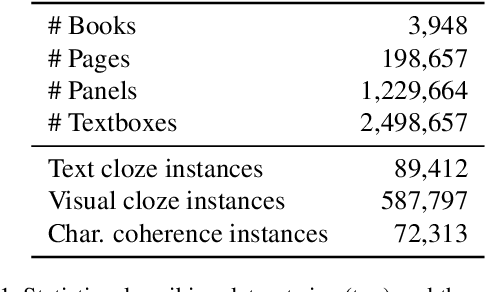

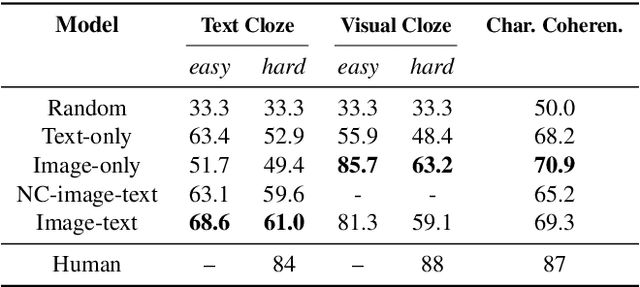
Visual narrative is often a combination of explicit information and judicious omissions, relying on the viewer to supply missing details. In comics, most movements in time and space are hidden in the "gutters" between panels. To follow the story, readers logically connect panels together by inferring unseen actions through a process called "closure". While computers can now describe what is explicitly depicted in natural images, in this paper we examine whether they can understand the closure-driven narratives conveyed by stylized artwork and dialogue in comic book panels. We construct a dataset, COMICS, that consists of over 1.2 million panels (120 GB) paired with automatic textbox transcriptions. An in-depth analysis of COMICS demonstrates that neither text nor image alone can tell a comic book story, so a computer must understand both modalities to keep up with the plot. We introduce three cloze-style tasks that ask models to predict narrative and character-centric aspects of a panel given n preceding panels as context. Various deep neural architectures underperform human baselines on these tasks, suggesting that COMICS contains fundamental challenges for both vision and language.