 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropertyDAG: Multi-objective Bayesian optimization of partially ordered, mixed-variable properties for biological sequence design
Oct 08, 2022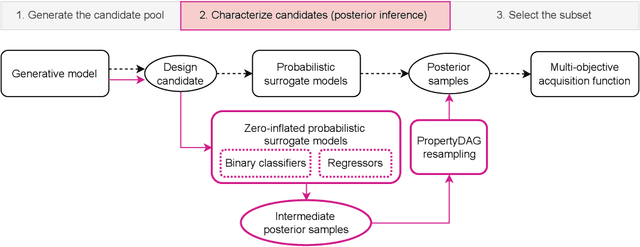
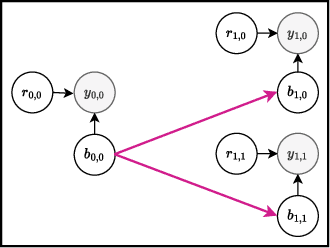
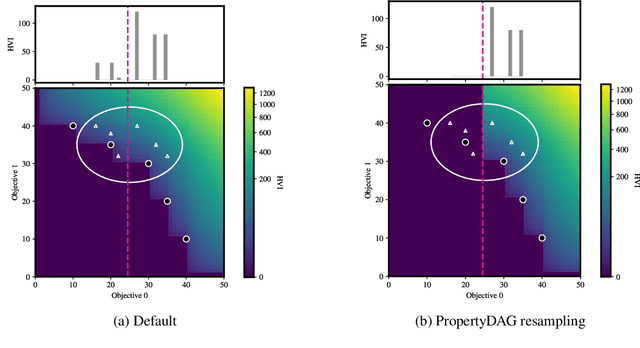
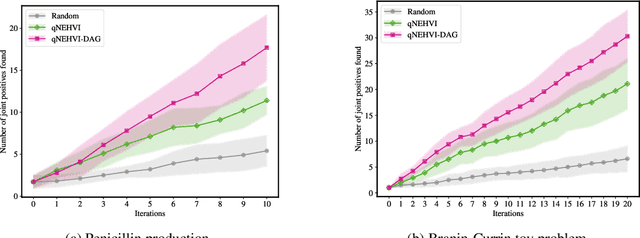
Bayesian optimization offers a sample-efficient framework for navigating the exploration-exploitation trade-off in the vast design space of biological sequences. Whereas it is possible to optimize the various properties of interest jointly using a multi-objective acquisition function, such as the expected hypervolume improvement (EHVI), this approach does not account for objectives with a hierarchical dependency structure. We consider a common use case where some regions of the Pareto frontier are prioritized over others according to a specified $\textit{partial ordering}$ in the objectives. For instance, when designing antibodies, we would like to maximize the binding affinity to a target antigen only if it can be expressed in live cell culture -- modeling the experimental dependency in which affinity can only be measured for antibodies that can be expressed and thus produced in viable quantities. In general, we may want to confer a partial ordering to the properties such that each property is optimized conditioned on its parent properties satisfying some feasibility condition. To this end, we present PropertyDAG, a framework that operates on top of the traditional multi-objective BO to impose this desired ordering on the objectives, e.g. expression $\rightarrow$ affinity. We demonstrate its performance over multiple simulated active learning iterations on a penicillin production task, toy numerical problem, and a real-world antibody design task.
A Non-monotonic Self-terminating Language Model
Oct 03, 2022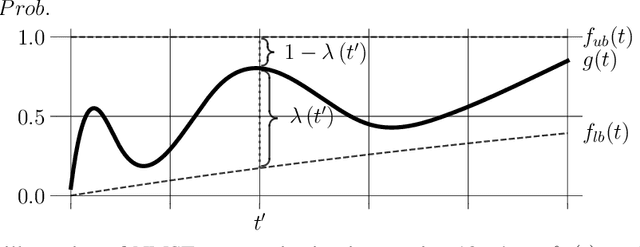
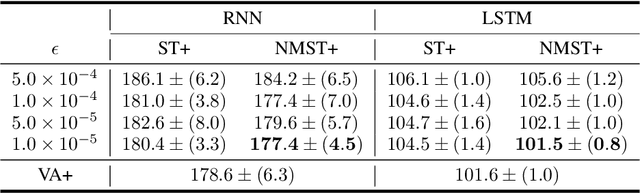
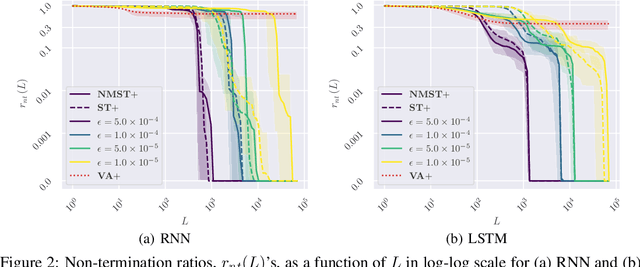
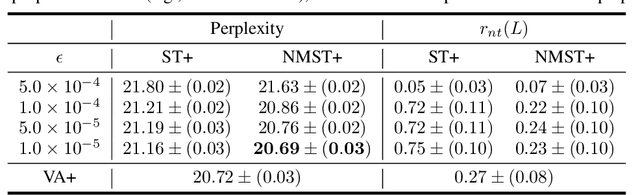
Recent large-scale neural autoregressive sequence models have shown impressive performances on a variety of natural language generation tasks. However, their generated sequences often exhibit degenerate properties such as non-termination, undesirable repetition, and premature termination, when generated with decoding algorithms such as greedy search, beam search, top-$k$ sampling, and nucleus sampling. In this paper, we focus on the problem of non-terminating sequences resulting from an incomplete decoding algorithm. We first define an incomplete probable decoding algorithm which includes greedy search, top-$k$ sampling, and nucleus sampling, beyond the incomplete decoding algorithm originally put forward by Welleck et al. (2020). We then propose a non-monotonic self-terminating language model, which significantly relaxes the constraint of monotonically increasing termination probability in the originally proposed self-terminating language model by Welleck et al. (2020), to address the issue of non-terminating sequences when using incomplete probable decoding algorithms. We prove that our proposed model prevents non-terminating sequences when using not only incomplete probable decoding algorithms but also beam search. We empirically validate our model on sequence completion tasks with various architectures.
Towards Disentangled Speech Representations
Aug 28, 2022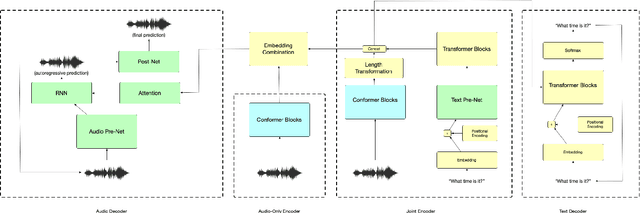
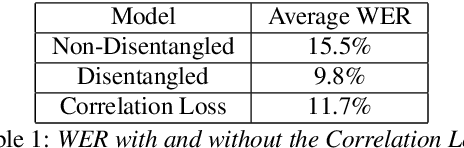

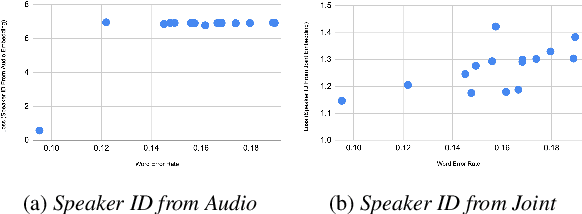
The careful construction of audio representations has become a dominant feature in the design of approaches to many speech tasks. Increasingly, such approaches have emphasized "disentanglement", where a representation contains only parts of the speech signal relevant to transcription while discarding irrelevant information. In this paper, we construct a representation learning task based on joint modeling of ASR and TTS, and seek to learn a representation of audio that disentangles that part of the speech signal that is relevant to transcription from that part which is not. We present empirical evidence that successfully finding such a representation is tied to the randomness inherent in training. We then make the observation that these desired, disentangled solutions to the optimization problem possess unique statistical properties. Finally, we show that enforcing these properties during training improves WER by 24.5% relative on average for our joint modeling task. These observations motivate a novel approach to learning effective audio representations.
Predicting Out-of-Domain Generalization with Local Manifold Smoothness
Jul 17, 2022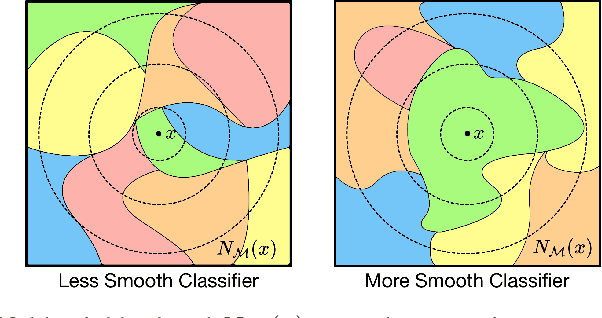
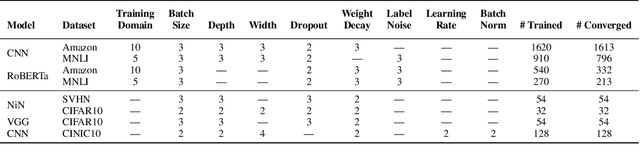

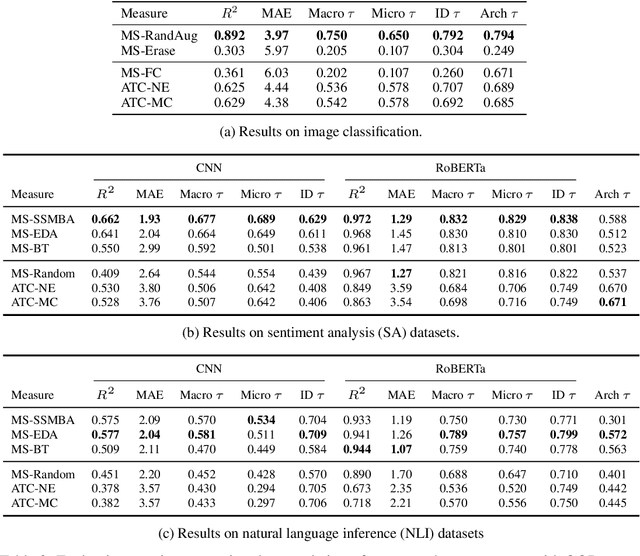
Understanding how machine learning models generalize to new environments is a critical part of their safe deployment. Recent work has proposed a variety of complexity measures that directly predict or theoretically bound the generalization capacity of a model. However, these methods rely on a strong set of assumptions that in practice are not always satisfied. Motivated by the limited settings in which existing measures can be applied, we propose a novel complexity measure based on the local manifold smoothness of a classifier. We define local manifold smoothness as a classifier's output sensitivity to perturbations in the manifold neighborhood around a given test point. Intuitively, a classifier that is less sensitive to these perturbations should generalize better. To estimate smoothness we sample points using data augmentation and measure the fraction of these points classified into the majority class. Our method only requires selecting a data augmentation method and makes no other assumptions about the model or data distributions, meaning it can be applied even in out-of-domain (OOD) settings where existing methods cannot. In experiments on robustness benchmarks in image classification, sentiment analysis, and natural language inference, we demonstrate a strong and robust correlation between our manifold smoothness measure and actual OOD generalization on over 3,000 models evaluated on over 100 train/test domain pairs.
Endowing Language Models with Multimodal Knowledge Graph Representations
Jun 27, 2022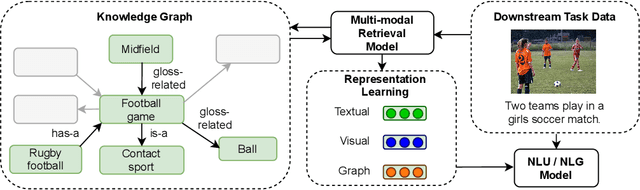
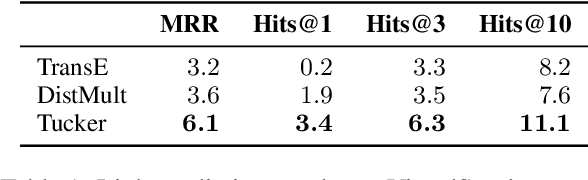
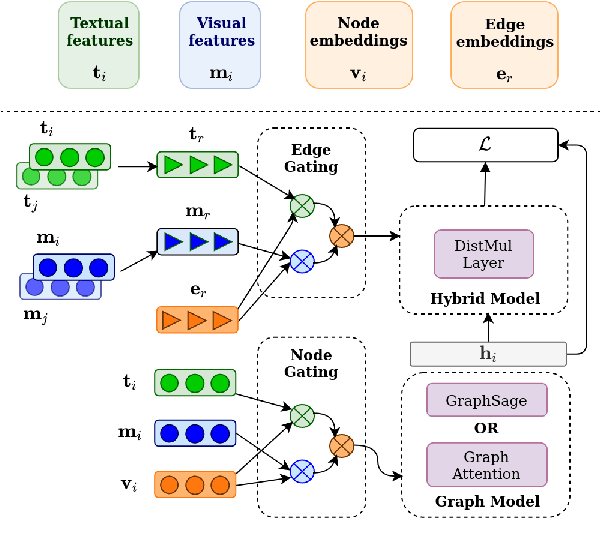
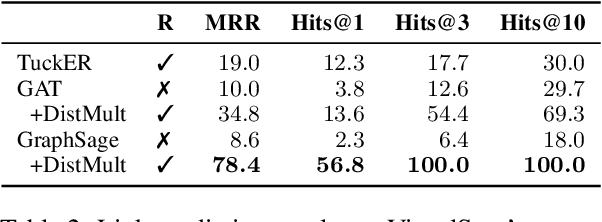
We propose a method to make natural language understanding models more parameter efficient by storing knowledge in an external knowledge graph (KG) and retrieving from this KG using a dense index. Given (possibly multilingual) downstream task data, e.g., sentences in German, we retrieve entities from the KG and use their multimodal representations to improve downstream task performance. We use the recently released VisualSem KG as our external knowledge repository, which covers a subset of Wikipedia and WordNet entities, and compare a mix of tuple-based and graph-based algorithms to learn entity and relation representations that are grounded on the KG multimodal information. We demonstrate the usefulness of the learned entity representations on two downstream tasks, and show improved performance on the multilingual named entity recognition task by $0.3\%$--$0.7\%$ F1, while we achieve up to $2.5\%$ improvement in accuracy on the visual sense disambiguation task. All our code and data are available in: \url{https://github.com/iacercalixto/visualsem-kg}.
Linear Connectivity Reveals Generalization Strategies
May 24, 2022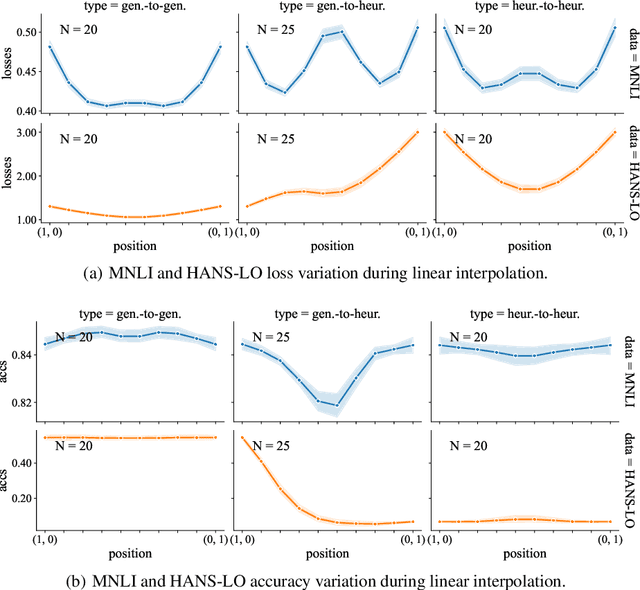
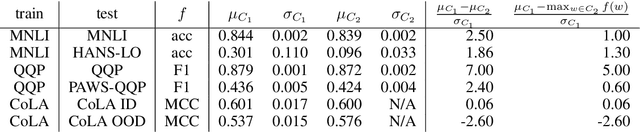
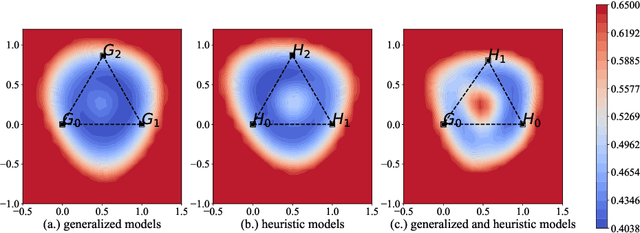
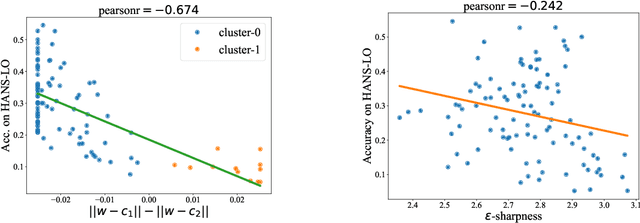
It is widely accepted in the mode connectivity literature that when two neural networks are trained similarly on the same data, they are connected by a path through parameter space over which test set accuracy is maintained. Under some circumstances, including transfer learning from pretrained models, these paths are presumed to be linear. In contrast to existing results, we find that among text classifiers (trained on MNLI, QQP, and CoLA), some pairs of finetuned models have large barriers of increasing loss on the linear paths between them. On each task, we find distinct clusters of models which are linearly connected on the test loss surface, but are disconnected from models outside the cluster -- models that occupy separate basins on the surface. By measuring performance on specially-crafted diagnostic datasets, we find that these clusters correspond to different generalization strategies: one cluster behaves like a bag of words model under domain shift, while another cluster uses syntactic heuristics. Our work demonstrates how the geometry of the loss surface can guide models towards different heuristic functions.
Translating Hanja historical documents to understandable Korean and English
May 20, 2022
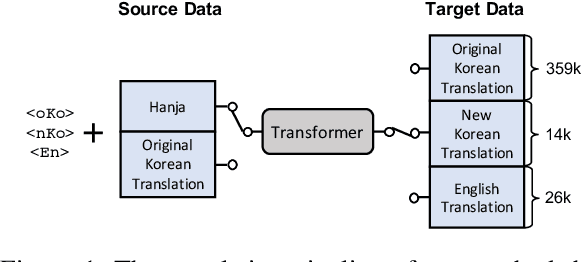
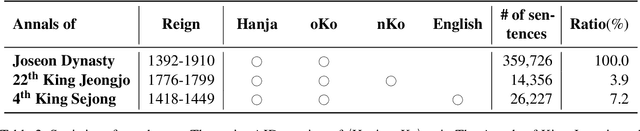
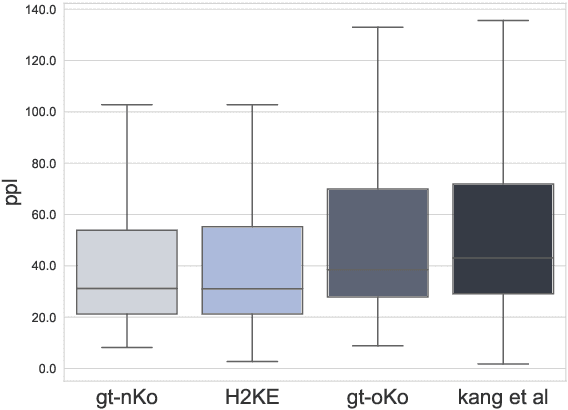
The Annals of Joseon Dynasty (AJD) contain the daily records of the Kings of Joseon, the 500-year kingdom preceding the modern nation of Korea. The Annals were originally written in an archaic Korean writing system, `Hanja', and translated into Korean from 1968 to 1993. However, this translation was literal and contained many archaic Korean words; thus, a new expert translation effort began in 2012, completing the records of only one king in a decade. Also, expert translators are working on an English translation, of which only one king's records are available because of the high cost and slow progress. Thus, we propose H2KE, the neural machine translation model that translates Hanja historical documents to understandable Korean and English. Based on the multilingual neural machine translation approach, it translates the historical document written in Hanja, using both the full dataset of outdated Korean translation and a small dataset of recently translated Korean and English. We compare our method with two baselines: one is a recent model that simultaneously learns to restore and translate Hanja historical document and the other is the transformer that trained on newly translated corpora only. The results show that our method significantly outperforms the baselines in terms of BLEU score in both modern Korean and English translations. We also conduct a human evaluation that shows that our translation is preferred over the original expert translation.
Multi-segment preserving sampling for deep manifold sampler
May 09, 2022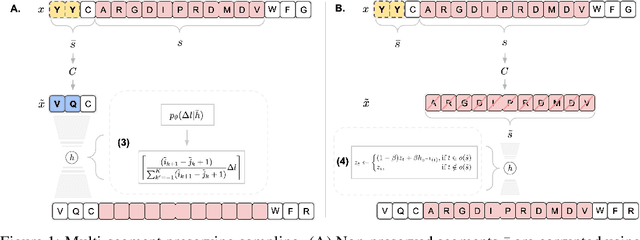

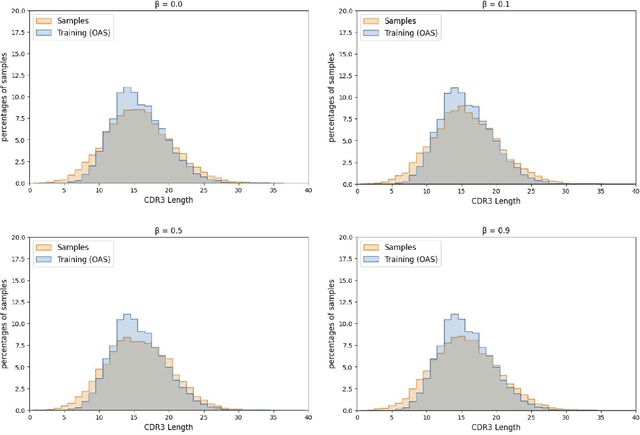
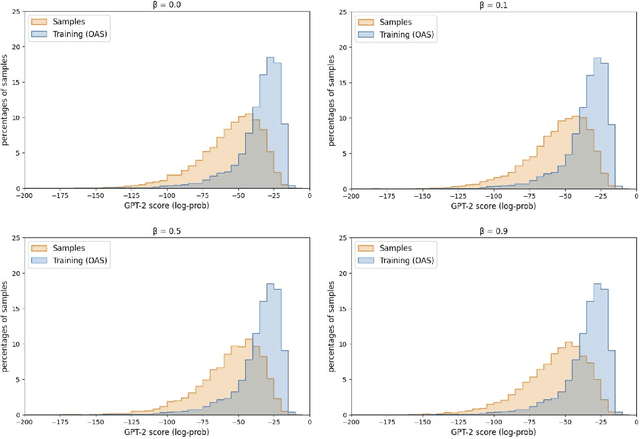
Deep generative modeling for biological sequences presents a unique challenge in reconciling the bias-variance trade-off between explicit biological insight and model flexibility. The deep manifold sampler was recently proposed as a means to iteratively sample variable-length protein sequences by exploiting the gradients from a function predictor. We introduce an alternative approach to this guided sampling procedure, multi-segment preserving sampling, that enables the direct inclusion of domain-specific knowledge by designating preserved and non-preserved segments along the input sequence, thereby restricting variation to only select regions. We present its effectiveness in the context of antibody design by training two models: a deep manifold sampler and a GPT-2 language model on nearly six million heavy chain sequences annotated with the IGHV1-18 gene. During sampling, we restrict variation to only the complementarity-determining region 3 (CDR3) of the input. We obtain log probability scores from a GPT-2 model for each sampled CDR3 and demonstrate that multi-segment preserving sampling generates reasonable designs while maintaining the desired, preserved regions.
Training Language Models with Natural Language Feedback
May 02, 2022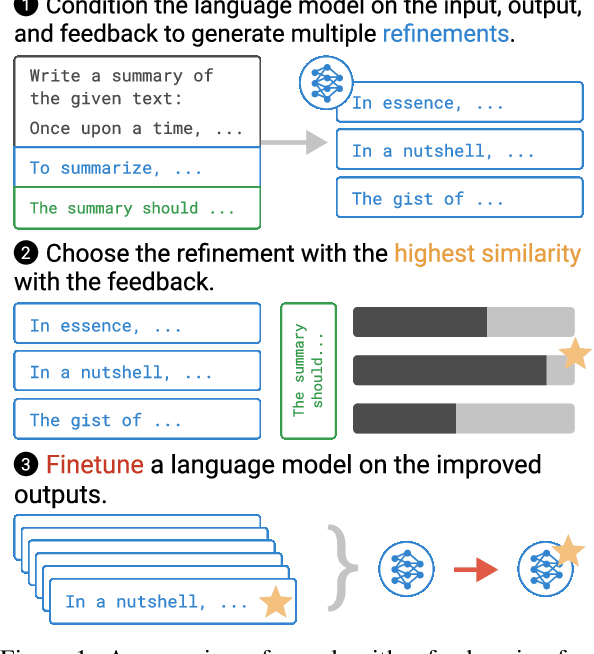
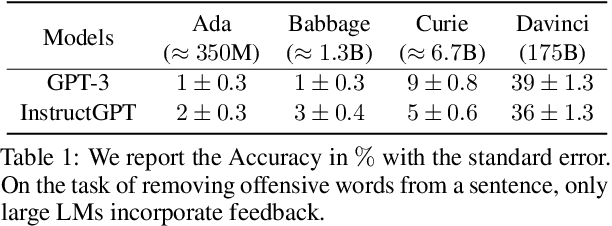
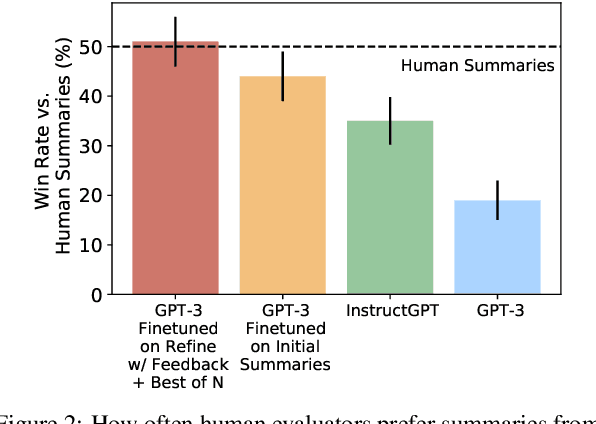
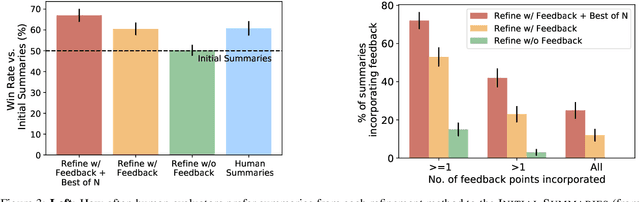
Pretrained language models often do not perform tasks in ways that are in line with our preferences, e.g., generating offensive text or factually incorrect summaries. Recent work approaches the above issue by learning from a simple form of human evaluation: comparisons between pairs of model-generated task outputs. Comparison feedback conveys limited information about human preferences per human evaluation. Here, we propose to learn from natural language feedback, which conveys more information per human evaluation. We learn from language feedback on model outputs using a three-step learning algorithm. First, we condition the language model on the initial output and feedback to generate many refinements. Second, we choose the refinement with the highest similarity to the feedback. Third, we finetune a language model to maximize the likelihood of the chosen refinement given the input. In synthetic experiments, we first evaluate whether language models accurately incorporate feedback to produce refinements, finding that only large language models (175B parameters) do so. Using only 100 samples of human-written feedback, our learning algorithm finetunes a GPT-3 model to roughly human-level summarization.
On the Effect of Pretraining Corpora on In-context Learning by a Large-scale Language Model
Apr 28, 2022
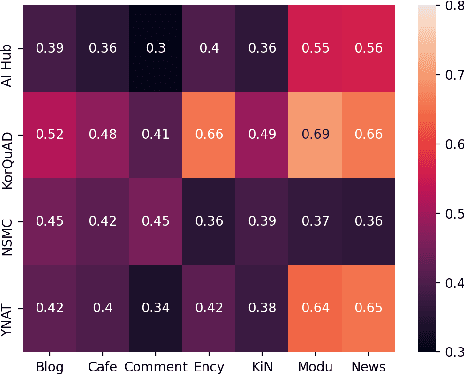
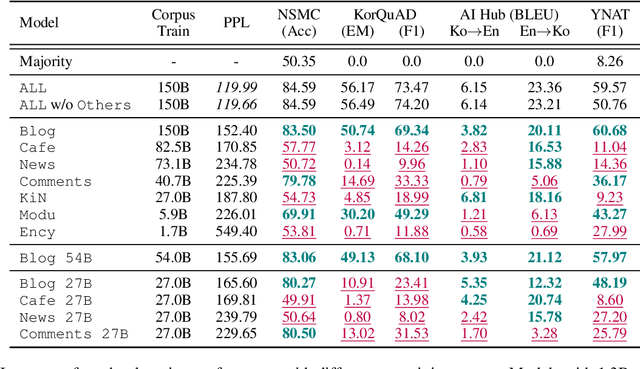
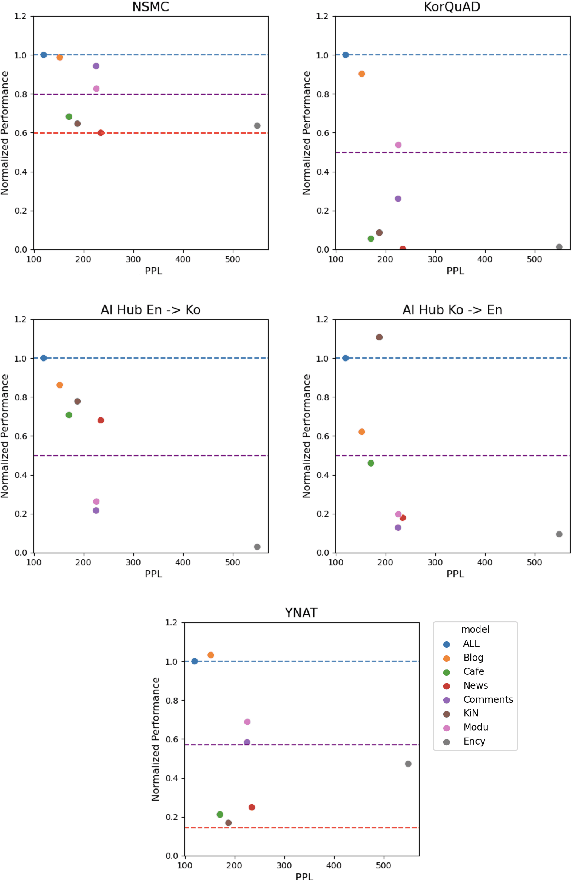
Many recent studies on large-scale language models have reported successful in-context zero- and few-shot learning ability. However, the in-depth analysis of when in-context learning occurs is still lacking. For example, it is unknown how in-context learning performance changes as the training corpus varies. Here, we investigate the effects of the source and size of the pretraining corpus on in-context learning in HyperCLOVA, a Korean-centric GPT-3 model. From our in-depth investigation, we introduce the following observations: (1) in-context learning performance heavily depends on the corpus domain source, and the size of the pretraining corpus does not necessarily determine the emergence of in-context learning, (2) in-context learning ability can emerge when a language model is trained on a combination of multiple corpora, even when each corpus does not result in in-context learning on its own, (3) pretraining with a corpus related to a downstream task does not always guarantee the competitive in-context learning performance of the downstream task, especially in the few-shot setting, and (4) the relationship between language modeling (measured in perplexity) and in-context learning does not always correlate: e.g., low perplexity does not always imply high in-context few-shot learning performance.