 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Stochastic Data Complexity with Boltzmann Influence Functions
Jun 04, 2024Estimating the uncertainty of a model's prediction on a test point is a crucial part of ensuring reliability and calibration under distribution shifts. A minimum description length approach to this problem uses the predictive normalized maximum likelihood (pNML) distribution, which considers every possible label for a data point, and decreases confidence in a prediction if other labels are also consistent with the model and training data. In this work we propose IF-COMP, a scalable and efficient approximation of the pNML distribution that linearizes the model with a temperature-scaled Boltzmann influence function. IF-COMP can be used to produce well-calibrated predictions on test points as well as measure complexity in both labelled and unlabelled settings. We experimentally validate IF-COMP on uncertainty calibration, mislabel detection, and OOD detection tasks, where it consistently matches or beats strong baseline methods.
Improving Black-box Robustness with In-Context Rewriting
Feb 15, 2024



Machine learning models often excel on in-distribution (ID) data but struggle with unseen out-of-distribution (OOD) inputs. Most techniques for improving OOD robustness are not applicable to settings where the model is effectively a black box, such as when the weights are frozen, retraining is costly, or the model is leveraged via an API. Test-time augmentation (TTA) is a simple post-hoc technique for improving robustness that sidesteps black-box constraints by aggregating predictions across multiple augmentations of the test input. TTA has seen limited use in NLP due to the challenge of generating effective natural language augmentations. In this work, we propose LLM-TTA, which uses LLM-generated augmentations as TTA's augmentation function. LLM-TTA outperforms conventional augmentation functions across sentiment, toxicity, and news classification tasks for BERT and T5 models, with BERT's OOD robustness improving by an average of 4.30 percentage points without regressing average ID performance. We explore selectively augmenting inputs based on prediction entropy to reduce the rate of expensive LLM augmentations, allowing us to maintain performance gains while reducing the average number of generated augmentations by 57.76%. LLM-TTA is agnostic to the task model architecture, does not require OOD labels, and is effective across low and high-resource settings. We share our data, models, and code for reproducibility.
Blind Biological Sequence Denoising with Self-Supervised Set Learning
Sep 04, 2023



Biological sequence analysis relies on the ability to denoise the imprecise output of sequencing platforms. We consider a common setting where a short sequence is read out repeatedly using a high-throughput long-read platform to generate multiple subreads, or noisy observations of the same sequence. Denoising these subreads with alignment-based approaches often fails when too few subreads are available or error rates are too high. In this paper, we propose a novel method for blindly denoising sets of sequences without directly observing clean source sequence labels. Our method, Self-Supervised Set Learning (SSSL), gathers subreads together in an embedding space and estimates a single set embedding as the midpoint of the subreads in both the latent and sequence spaces. This set embedding represents the "average" of the subreads and can be decoded into a prediction of the clean sequence. In experiments on simulated long-read DNA data, SSSL methods denoise small reads of $\leq 6$ subreads with 17% fewer errors and large reads of $>6$ subreads with 8% fewer errors compared to the best baseline. On a real dataset of antibody sequences, SSSL improves over baselines on two self-supervised metrics, with a significant improvement on difficult small reads that comprise over 60% of the test set. By accurately denoising these reads, SSSL promises to better realize the potential of high-throughput DNA sequencing data for downstream scientific applications.
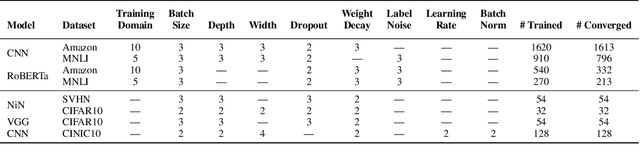
If Influence Functions are the Answer, Then What is the Question?
Sep 12, 2022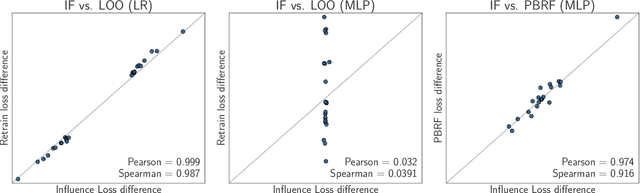


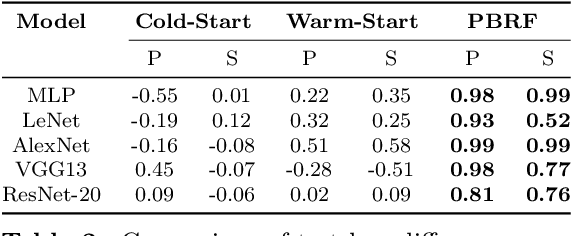
Influence functions efficiently estimate the effect of removing a single training data point on a model's learned parameters. While influence estimates align well with leave-one-out retraining for linear models, recent works have shown this alignment is often poor in neural networks. In this work, we investigate the specific factors that cause this discrepancy by decomposing it into five separate terms. We study the contributions of each term on a variety of architectures and datasets and how they vary with factors such as network width and training time. While practical influence function estimates may be a poor match to leave-one-out retraining for nonlinear networks, we show they are often a good approximation to a different object we term the proximal Bregman response function (PBRF). Since the PBRF can still be used to answer many of the questions motivating influence functions, such as identifying influential or mislabeled examples, our results suggest that current algorithms for influence function estimation give more informative results than previous error analyses would suggest.
Predicting Out-of-Domain Generalization with Local Manifold Smoothness
Jul 17, 2022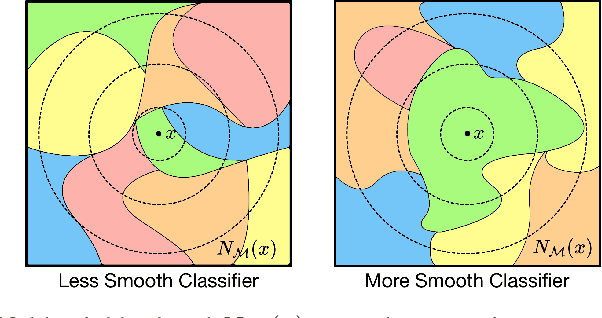

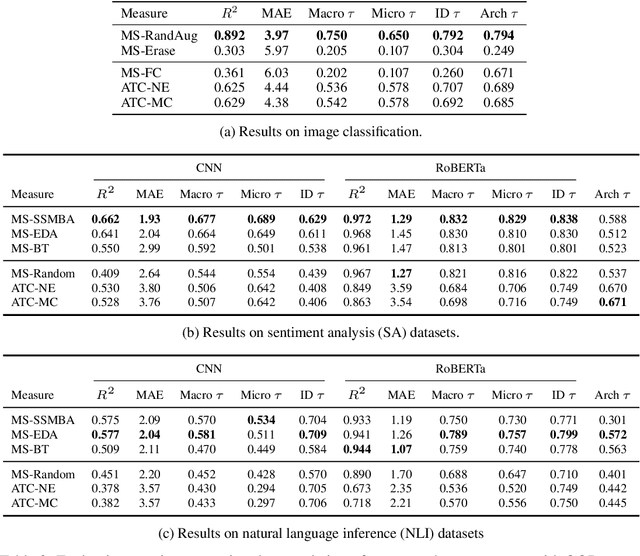
Understanding how machine learning models generalize to new environments is a critical part of their safe deployment. Recent work has proposed a variety of complexity measures that directly predict or theoretically bound the generalization capacity of a model. However, these methods rely on a strong set of assumptions that in practice are not always satisfied. Motivated by the limited settings in which existing measures can be applied, we propose a novel complexity measure based on the local manifold smoothness of a classifier. We define local manifold smoothness as a classifier's output sensitivity to perturbations in the manifold neighborhood around a given test point. Intuitively, a classifier that is less sensitive to these perturbations should generalize better. To estimate smoothness we sample points using data augmentation and measure the fraction of these points classified into the majority class. Our method only requires selecting a data augmentation method and makes no other assumptions about the model or data distributions, meaning it can be applied even in out-of-domain (OOD) settings where existing methods cannot. In experiments on robustness benchmarks in image classification, sentiment analysis, and natural language inference, we demonstrate a strong and robust correlation between our manifold smoothness measure and actual OOD generalization on over 3,000 models evaluated on over 100 train/test domain pairs.
Improving Dialogue Breakdown Detection with Semi-Supervised Learning
Oct 30, 2020
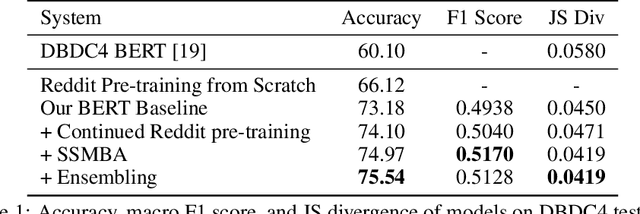
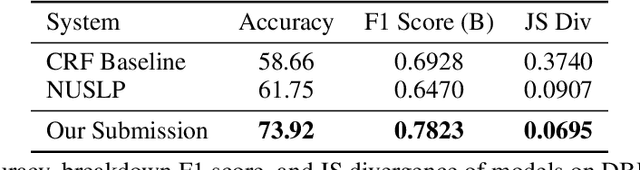
Building user trust in dialogue agents requires smooth and consistent dialogue exchanges. However, agents can easily lose conversational context and generate irrelevant utterances. These situations are called dialogue breakdown, where agent utterances prevent users from continuing the conversation. Building systems to detect dialogue breakdown allows agents to recover appropriately or avoid breakdown entirely. In this paper we investigate the use of semi-supervised learning methods to improve dialogue breakdown detection, including continued pre-training on the Reddit dataset and a manifold-based data augmentation method. We demonstrate the effectiveness of these methods on the Dialogue Breakdown Detection Challenge (DBDC) English shared task. Our submissions to the 2020 DBDC5 shared task place first, beating baselines and other submissions by over 12\% accuracy. In ablations on DBDC4 data from 2019, our semi-supervised learning methods improve the performance of a baseline BERT model by 2\% accuracy. These methods are applicable generally to any dialogue task and provide a simple way to improve model performance.
SSMBA: Self-Supervised Manifold Based Data Augmentation for Improving Out-of-Domain Robustness
Oct 04, 2020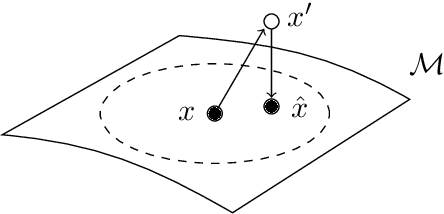
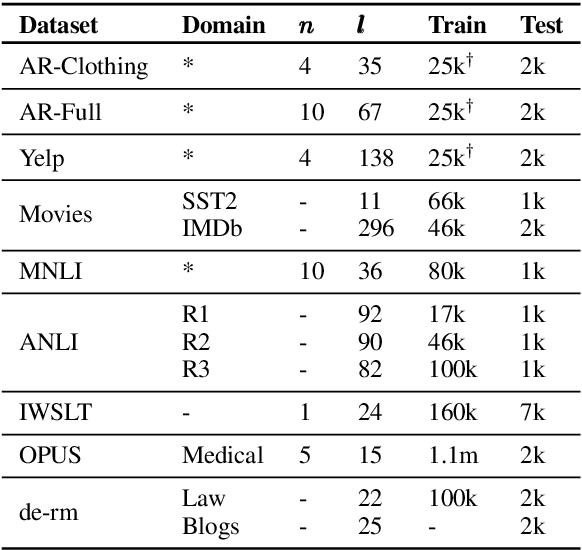
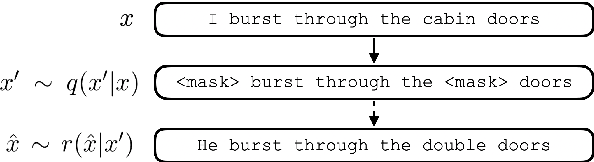
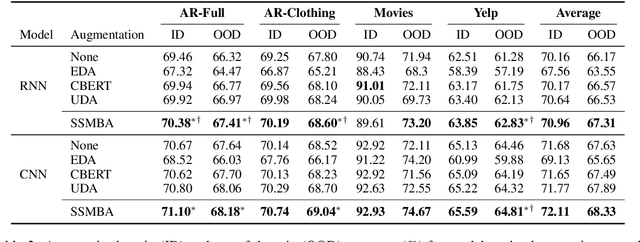
Models that perform well on a training domain often fail to generalize to out-of-domain (OOD) examples. Data augmentation is a common method used to prevent overfitting and improve OOD generalization. However, in natural language, it is difficult to generate new examples that stay on the underlying data manifold. We introduce SSMBA, a data augmentation method for generating synthetic training examples by using a pair of corruption and reconstruction functions to move randomly on a data manifold. We investigate the use of SSMBA in the natural language domain, leveraging the manifold assumption to reconstruct corrupted text with masked language models. In experiments on robustness benchmarks across 3 tasks and 9 datasets, SSMBA consistently outperforms existing data augmentation methods and baseline models on both in-domain and OOD data, achieving gains of 0.8% accuracy on OOD Amazon reviews, 1.8% accuracy on OOD MNLI, and 1.4 BLEU on in-domain IWSLT14 German-English.
Simple and Effective Noisy Channel Modeling for Neural Machine Translation
Aug 15, 2019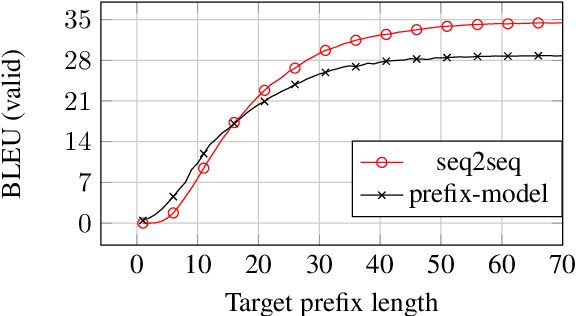
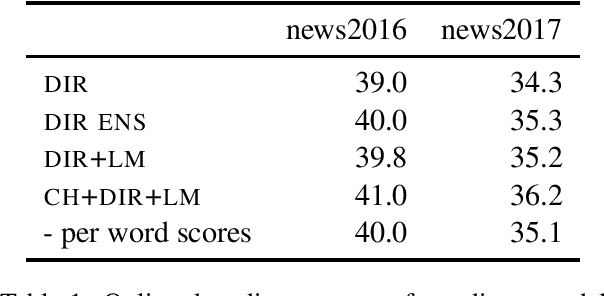
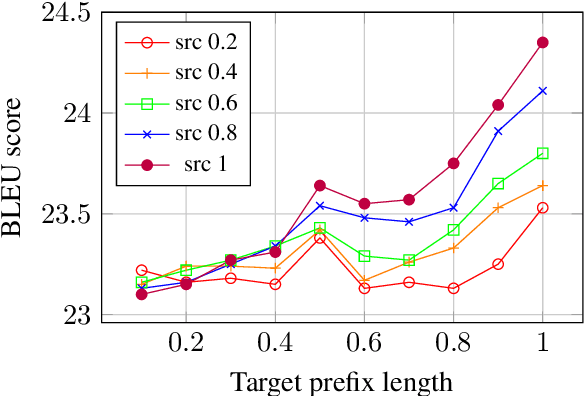
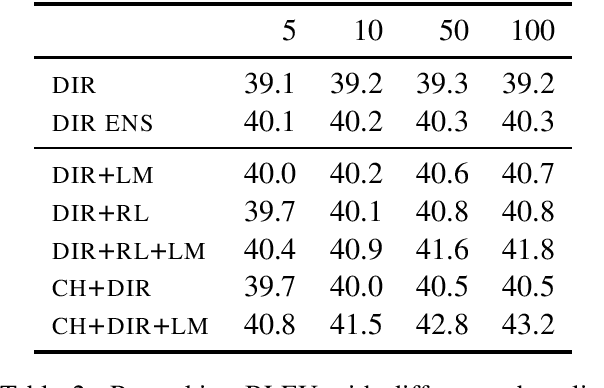
Previous work on neural noisy channel modeling relied on latent variable models that incrementally process the source and target sentence. This makes decoding decisions based on partial source prefixes even though the full source is available. We pursue an alternative approach based on standard sequence to sequence models which utilize the entire source. These models perform remarkably well as channel models, even though they have neither been trained on, nor designed to factor over incomplete target sentences. Experiments with neural language models trained on billions of words show that noisy channel models can outperform a direct model by up to 3.2 BLEU on WMT'17 German-English translation. We evaluate on four language-pairs and our channel models consistently outperform strong alternatives such right-to-left reranking models and ensembles of direct models.
Facebook FAIR's WMT19 News Translation Task Submission
Jul 15, 2019
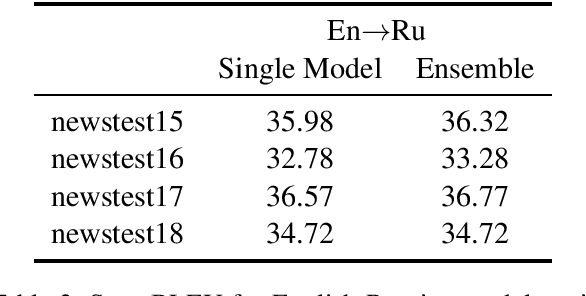
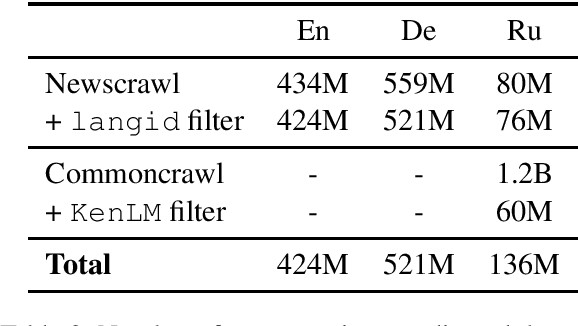
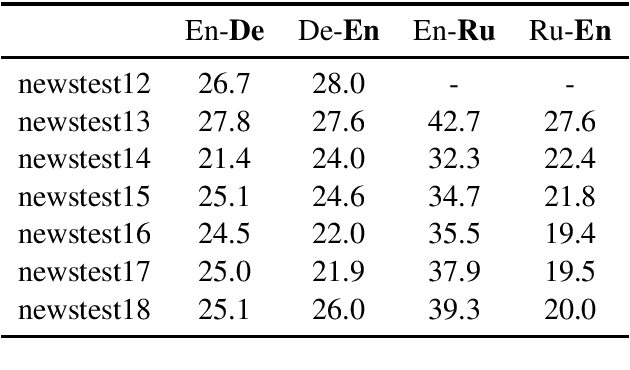
This paper describes Facebook FAIR's submission to the WMT19 shared news translation task. We participate in two language pairs and four language directions, English <-> German and English <-> Russian. Following our submission from last year, our baseline systems are large BPE-based transformer models trained with the Fairseq sequence modeling toolkit which rely on sampled back-translations. This year we experiment with different bitext data filtering schemes, as well as with adding filtered back-translated data. We also ensemble and fine-tune our models on domain-specific data, then decode using noisy channel model reranking. Our submissions are ranked first in all four directions of the human evaluation campaign. On En->De, our system significantly outperforms other systems as well as human translations. This system improves upon our WMT'18 submission by 4.5 BLEU points.
Embryo staging with weakly-supervised region selection and dynamically-decoded predictions
Apr 09, 2019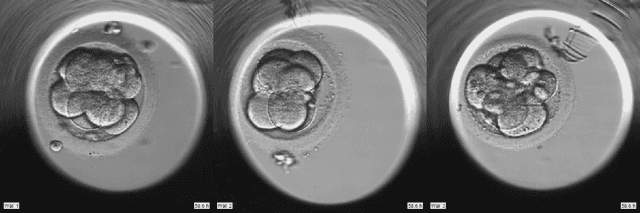
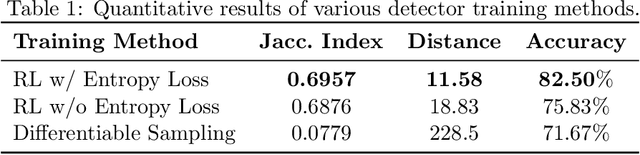
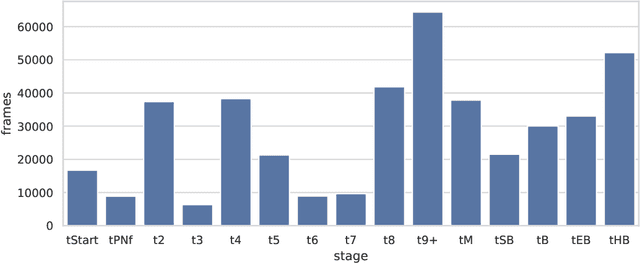
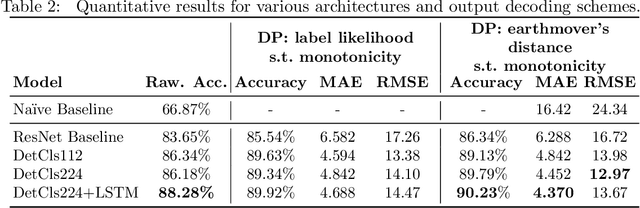
To optimize clinical outcomes, fertility clinics must strategically select which embryos to transfer. Common selection heuristics are formulas expressed in terms of the durations required to reach various developmental milestones, quantities historically annotated manually by experienced embryologists based on time-lapse EmbryoScope videos. We propose a new method for automatic embryo staging that exploits several sources of structure in this time-lapse data. First, noting that in each image the embryo occupies a small subregion, we jointly train a region proposal network with the downstream classifier to isolate the embryo. Notably, because we lack ground-truth bounding boxes, our we weakly supervise the region proposal network optimizing its parameters via reinforcement learning to improve the downstream classifier's loss. Moreover, noting that embryos reaching the blastocyst stage progress monotonically through earlier stages, we develop a dynamic-programming-based decoder that post-processes our predictions to select the most likely monotonic sequence of developmental stages. Our methods outperform vanilla residual networks and rival the best numbers in contemporary papers, as measured by both per-frame accuracy and transition prediction error, despite operating on smaller data than many.