 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critical Look at Targeted Instruction Selection: Disentangling What Matters (and What Doesn't)
Feb 16, 2026Instruction fine-tuning of large language models (LLMs) often involves selecting a subset of instruction training data from a large candidate pool, using a small query set from the target task. Despite growing interest, the literature on targeted instruction selection remains fragmented and opaque: methods vary widely in selection budgets, often omit zero-shot baselines, and frequently entangle the contributions of key components. As a result, practitioners lack actionable guidance on selecting instructions for their target tasks. In this work, we aim to bring clarity to this landscape by disentangling and systematically analyzing the two core ingredients: data representation and selection algorithms. Our framework enables controlled comparisons across models, tasks, and budgets. We find that only gradient-based data representations choose subsets whose similarity to the query consistently predicts performance across datasets and models. While no single method dominates, gradient-based representations paired with a greedy round-robin selection algorithm tend to perform best on average at low budgets, but these benefits diminish at larger budgets. Finally, we unify several existing selection algorithms as forms of approximate distance minimization between the selected subset and the query set, and support this view with new generalization bounds. More broadly, our findings provide critical insights and a foundation for more principled data selection in LLM fine-tuning. The code is available at https://github.com/dcml-lab/targeted-instruction-selection.
DataS^3: Dataset Subset Selection for Specialization
Apr 22, 2025



In many real-world machine learning (ML) applications (e.g. detecting broken bones in x-ray images, detecting species in camera traps), in practice models need to perform well on specific deployments (e.g. a specific hospital, a specific national park) rather than the domain broadly. However, deployments often have imbalanced, unique data distributions. Discrepancy between the training distribution and the deployment distribution can lead to suboptimal performance, highlighting the need to select deployment-specialized subsets from the available training data. We formalize dataset subset selection for specialization (DS3): given a training set drawn from a general distribution and a (potentially unlabeled) query set drawn from the desired deployment-specific distribution, the goal is to select a subset of the training data that optimizes deployment performance. We introduce DataS^3; the first dataset and benchmark designed specifically for the DS3 problem. DataS^3 encompasses diverse real-world application domains, each with a set of distinct deployments to specialize in. We conduct a comprehensive study evaluating algorithms from various families--including coresets, data filtering, and data curation--on DataS^3, and find that general-distribution methods consistently fail on deployment-specific tasks. Additionally, we demonstrate the existence of manually curated (deployment-specific) expert subsets that outperform training on all available data with accuracy gains up to 51.3 percent. Our benchmark highlights the critical role of tailored dataset curation in enhancing performance and training efficiency on deployment-specific distributions, which we posit will only become more important as global, public datasets become available across domains and ML models are deployed in the real world.
Privacy-preserving data release leveraging optimal transport and particle gradient descent
Jan 31, 2024



We present a novel approach for differentially private data synthesis of protected tabular datasets, a relevant task in highly sensitive domains such as healthcare and government. Current state-of-the-art methods predominantly use marginal-based approaches, where a dataset is generated from private estimates of the marginals. In this paper, we introduce PrivPGD, a new generation method for marginal-based private data synthesis, leveraging tools from optimal transport and particle gradient descent. Our algorithm outperforms existing methods on a large range of datasets while being highly scalable and offering the flexibility to incorporate additional domain-specific constraints.
Interpretable Distribution Shift Detection using Optimal Transport
Aug 04, 2022
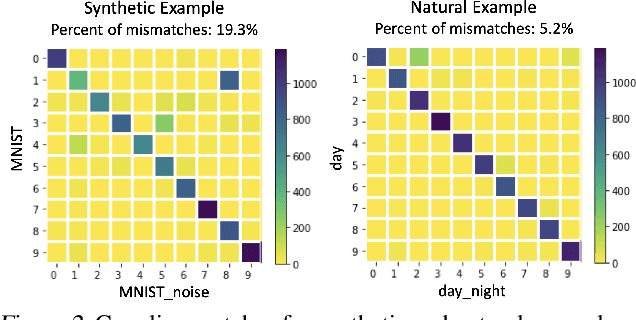


We propose a method to identify and characterize distribution shifts in classification datasets based on optimal transport. It allows the user to identify the extent to which each class is affected by the shift, and retrieves corresponding pairs of samples to provide insights on its nature. We illustrate its use on synthetic and natural shift examples. While the results we present are preliminary, we hope that this inspires future work on interpretable methods for analyzing distribution shifts.
Predicting Out-of-Domain Generalization with Local Manifold Smoothness
Jul 17, 2022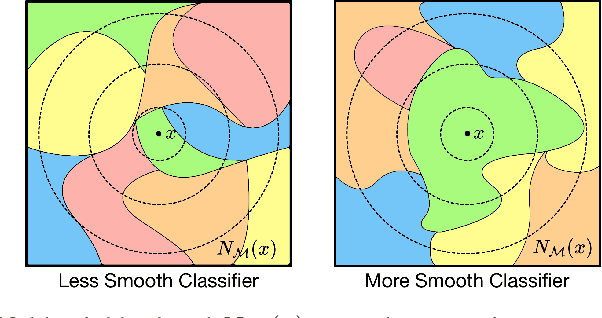

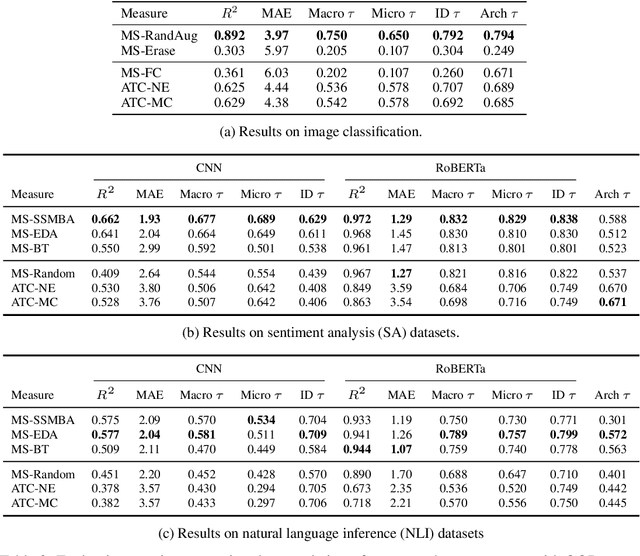
Understanding how machine learning models generalize to new environments is a critical part of their safe deployment. Recent work has proposed a variety of complexity measures that directly predict or theoretically bound the generalization capacity of a model. However, these methods rely on a strong set of assumptions that in practice are not always satisfied. Motivated by the limited settings in which existing measures can be applied, we propose a novel complexity measure based on the local manifold smoothness of a classifier. We define local manifold smoothness as a classifier's output sensitivity to perturbations in the manifold neighborhood around a given test point. Intuitively, a classifier that is less sensitive to these perturbations should generalize better. To estimate smoothness we sample points using data augmentation and measure the fraction of these points classified into the majority class. Our method only requires selecting a data augmentation method and makes no other assumptions about the model or data distributions, meaning it can be applied even in out-of-domain (OOD) settings where existing methods cannot. In experiments on robustness benchmarks in image classification, sentiment analysis, and natural language inference, we demonstrate a strong and robust correlation between our manifold smoothness measure and actual OOD generalization on over 3,000 models evaluated on over 100 train/test domain pairs.
GAN-based Data Augmentation for Chest X-ray Classification
Jul 07, 2021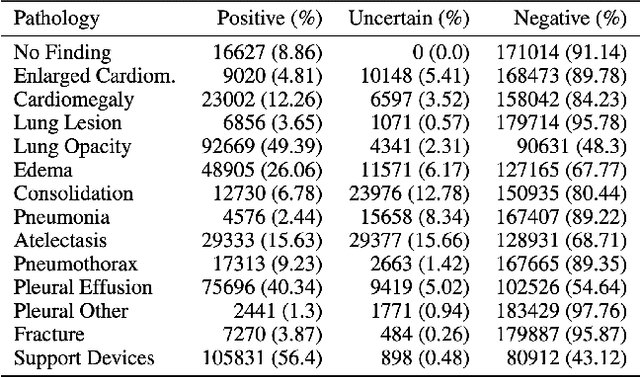
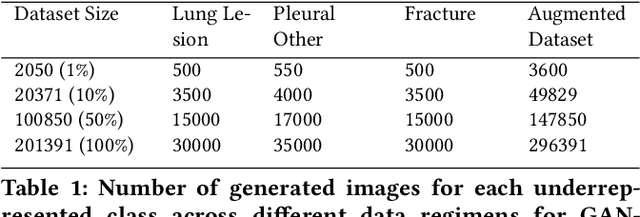
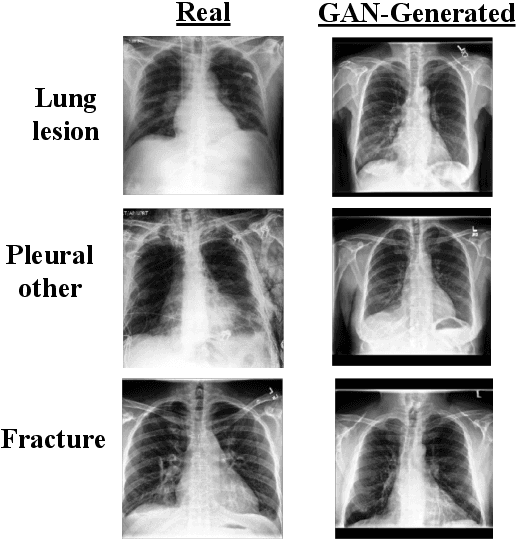
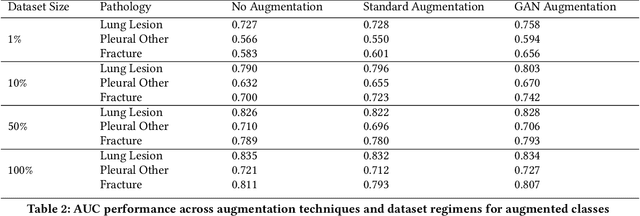
A common problem in computer vision -- particularly in medical applications -- is a lack of sufficiently diverse, large sets of training data. These datasets often suffer from severe class imbalance. As a result, networks often overfit and are unable to generalize to novel examples. Generative Adversarial Networks (GANs) offer a novel method of synthetic data augmentation. In this work, we evaluate the use of GAN- based data augmentation to artificially expand the CheXpert dataset of chest radiographs. We compare performance to traditional augmentation and find that GAN-based augmentation leads to higher downstream performance for underrepresented classes. Furthermore, we see that this result is pronounced in low data regimens. This suggests that GAN-based augmentation a promising area of research to improve network performance when data collection is prohibitively expensive.