 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandOccNet: Occlusion-Robust 3D Hand Mesh Estimation Network
Mar 28, 2022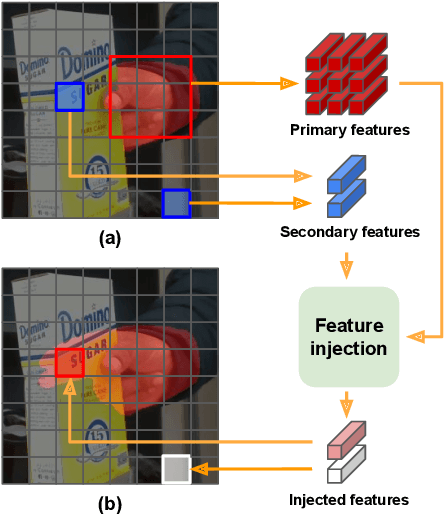
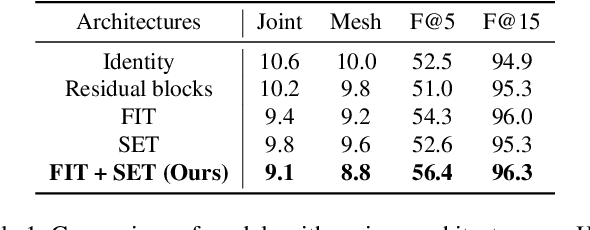
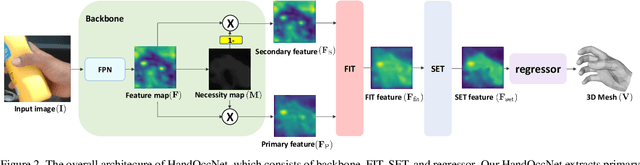

Hands are often severely occluded by objects, which makes 3D hand mesh estimation challenging. Previous works often have disregarded information at occluded regions. However, we argue that occluded regions have strong correlations with hands so that they can provide highly beneficial information for complete 3D hand mesh estimation. Thus, in this work, we propose a novel 3D hand mesh estimation network HandOccNet, that can fully exploits the information at occluded regions as a secondary means to enhance image features and make it much richer. To this end, we design two successive Transformer-based modules, called feature injecting transformer (FIT) and self- enhancing transformer (SET). FIT injects hand information into occluded region by considering their correlation. SET refines the output of FIT by using a self-attention mechanism. By injecting the hand information to the occluded region, our HandOccNet reaches the state-of-the-art performance on 3D hand mesh benchmarks that contain challenging hand-object occlusions. The codes are available in: https://github.com/namepllet/HandOccNet.
* also attached the supplementary material
AP-BSN: Self-Supervised Denoising for Real-World Images via Asymmetric PD and Blind-Spot Network
Mar 24, 2022
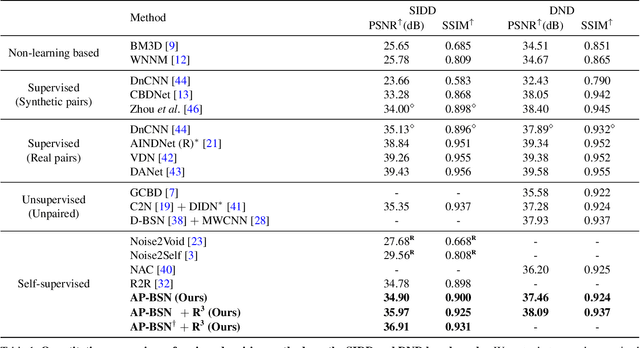
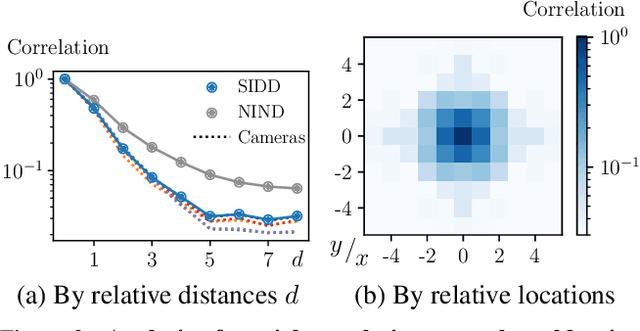

Blind-spot network (BSN) and its variants have made significant advances in self-supervised denoising. Nevertheless, they are still bound to synthetic noisy inputs due to less practical assumptions like pixel-wise independent noise. Hence, it is challenging to deal with spatially correlated real-world noise using self-supervised BSN. Recently, pixel-shuffle downsampling (PD) has been proposed to remove the spatial correlation of real-world noise. However, it is not trivial to integrate PD and BSN directly, which prevents the fully self-supervised denoising model on real-world images. We propose an Asymmetric PD (AP) to address this issue, which introduces different PD stride factors for training and inference. We systematically demonstrate that the proposed AP can resolve inherent trade-offs caused by specific PD stride factors and make BSN applicable to practical scenarios. To this end, we develop AP-BSN, a state-of-the-art self-supervised denoising method for real-world sRGB images. We further propose random-replacing refinement, which significantly improves the performance of our AP-BSN without any additional parameters. Extensive studies demonstrate that our method outperforms the other self-supervised and even unpaired denoising methods by a large margin, without using any additional knowledge, e.g., noise level, regarding the underlying unknown noise.
Recurrence-in-Recurrence Networks for Video Deblurring
Mar 12, 2022
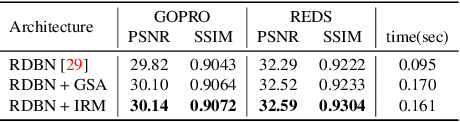
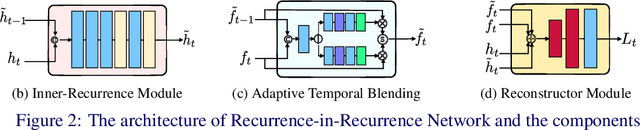
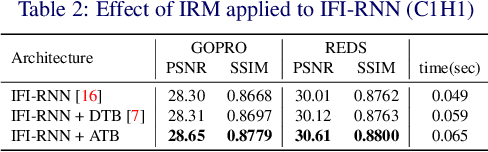
State-of-the-art video deblurring methods often adopt recurrent neural networks to model the temporal dependency between the frames. While the hidden states play key role in delivering information to the next frame, abrupt motion blur tend to weaken the relevance in the neighbor frames. In this paper, we propose recurrence-in-recurrence network architecture to cope with the limitations of short-ranged memory. We employ additional recurrent units inside the RNN cell. First, we employ inner-recurrence module (IRM) to manage the long-ranged dependency in a sequence. IRM learns to keep track of the cell memory and provides complementary information to find the deblurred frames. Second, we adopt an attention-based temporal blending strategy to extract the necessary part of the information in the local neighborhood. The adpative temporal blending (ATB) can either attenuate or amplify the features by the spatial attention. Our extensive experimental results and analysis validate the effectiveness of IRM and ATB on various RNN architectures.
* accepted paper in BMVC 2021
C2N: Practical Generative Noise Modeling for Real-World Denoising
Feb 19, 2022
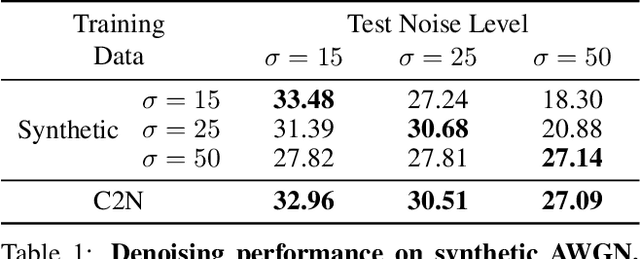
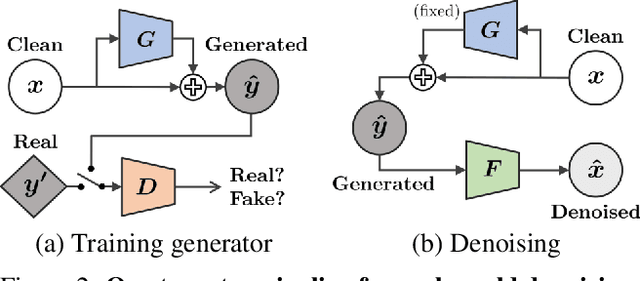

Learning-based image denoising methods have been bounded to situations where well-aligned noisy and clean images are given, or samples are synthesized from predetermined noise models, e.g., Gaussian. While recent generative noise modeling methods aim to simulate the unknown distribution of real-world noise, several limitations still exist. In a practical scenario, a noise generator should learn to simulate the general and complex noise distribution without using paired noisy and clean images. However, since existing methods are constructed on the unrealistic assumption of real-world noise, they tend to generate implausible patterns and cannot express complicated noise maps. Therefore, we introduce a Clean-to-Noisy image generation framework, namely C2N, to imitate complex real-world noise without using any paired examples. We construct the noise generator in C2N accordingly with each component of real-world noise characteristics to express a wide range of noise accurately. Combined with our C2N, conventional denoising CNNs can be trained to outperform existing unsupervised methods on challenging real-world benchmarks by a large margin.
Batch Normalization Tells You Which Filter is Important
Dec 02, 2021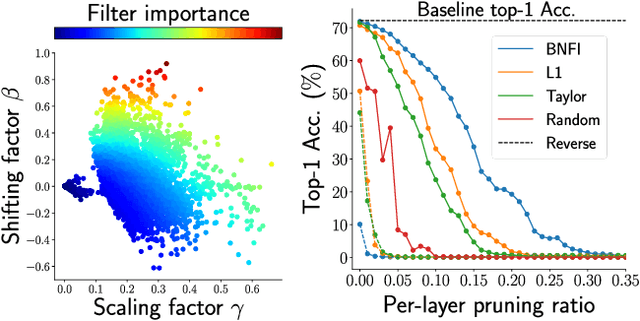
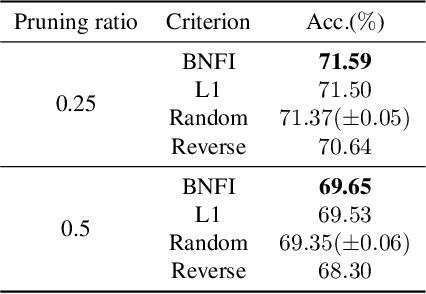
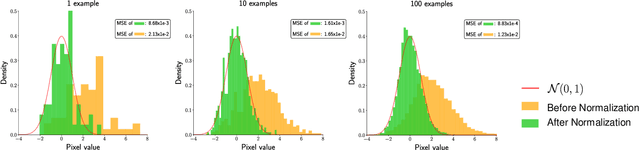
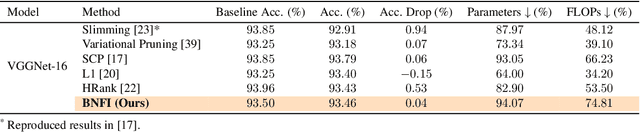
The goal of filter pruning is to search for unimportant filters to remove in order to make convolutional neural networks (CNNs) efficient without sacrificing the performance in the process. The challenge lies in finding information that can help determine how important or relevant each filter is with respect to the final output of neural networks. In this work, we share our observation that the batch normalization (BN) parameters of pre-trained CNNs can be used to estimate the feature distribution of activation outputs, without processing of training data. Upon observation, we propose a simple yet effective filter pruning method by evaluating the importance of each filter based on the BN parameters of pre-trained CNNs. The experimental results on CIFAR-10 and ImageNet demonstrate that the proposed method can achieve outstanding performance with and without fine-tuning in terms of the trade-off between the accuracy drop and the reduction in computational complexity and number of parameters of pruned networks.
Generative Residual Attention Network for Disease Detection
Oct 25, 2021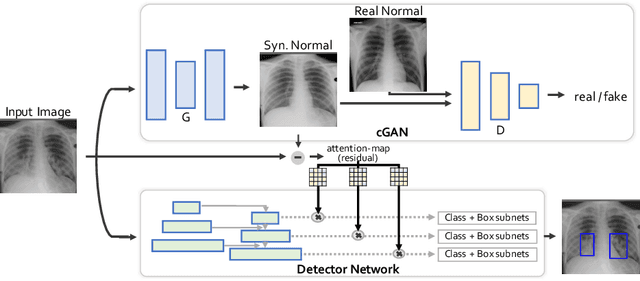
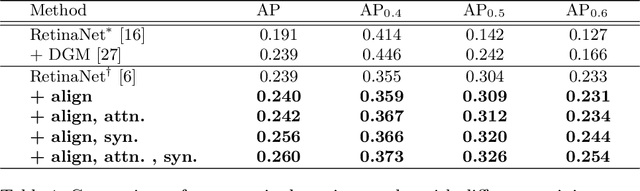
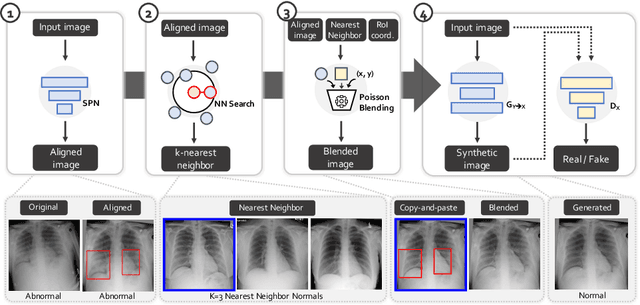
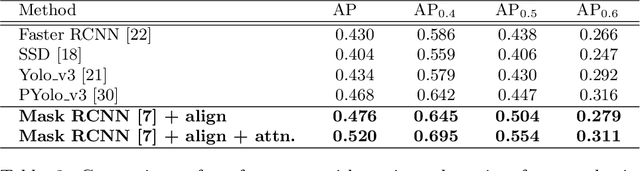
Accurate identification and localization of abnormalities from radiology images serve as a critical role in computer-aided diagnosis (CAD) systems. Building a highly generalizable system usually requires a large amount of data with high-quality annotations, including disease-specific global and localization information. However, in medical images, only a limited number of high-quality images and annotations are available due to annotation expenses. In this paper, we explore this problem by presenting a novel approach for disease generation in X-rays using a conditional generative adversarial learning. Specifically, given a chest X-ray image from a source domain, we generate a corresponding radiology image in a target domain while preserving the identity of the patient. We then use the generated X-ray image in the target domain to augment our training to improve the detection performance. We also present a unified framework that simultaneously performs disease generation and localization.We evaluate the proposed approach on the X-ray image dataset provided by the Radiological Society of North America (RSNA), surpassing the state-of-the-art baseline detection algorithms.
Meta-Learning with Task-Adaptive Loss Function for Few-Shot Learning
Oct 17, 2021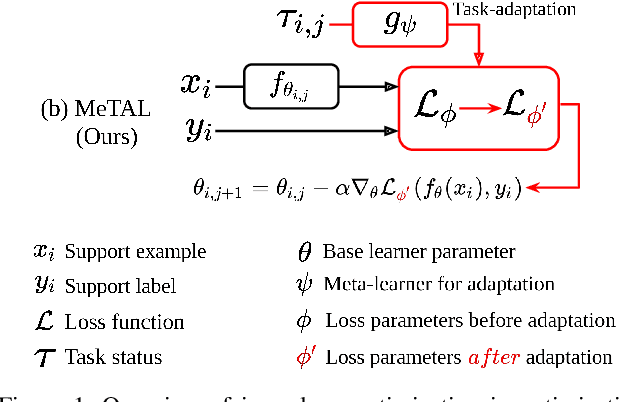
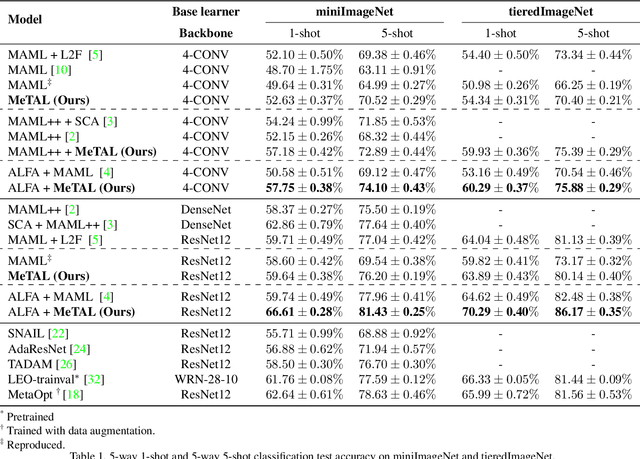
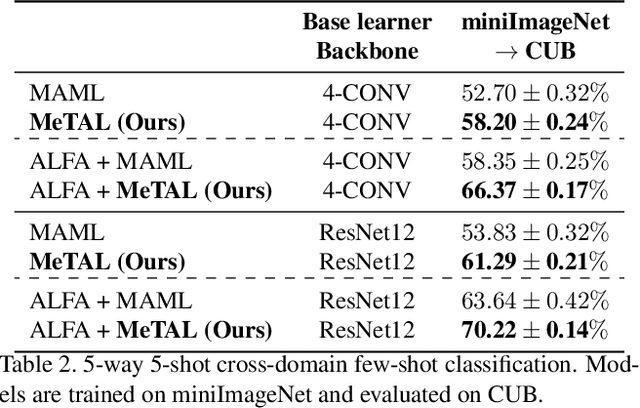
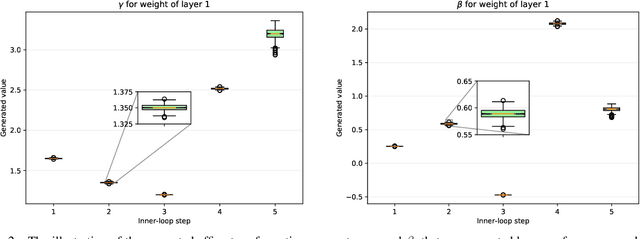
In few-shot learning scenarios, the challenge is to generalize and perform well on new unseen examples when only very few labeled examples are available for each task. Model-agnostic meta-learning (MAML) has gained the popularity as one of the representative few-shot learning methods for its flexibility and applicability to diverse problems. However, MAML and its variants often resort to a simple loss function without any auxiliary loss function or regularization terms that can help achieve better generalization. The problem lies in that each application and task may require different auxiliary loss function, especially when tasks are diverse and distinct. Instead of attempting to hand-design an auxiliary loss function for each application and task, we introduce a new meta-learning framework with a loss function that adapts to each task. Our proposed framework, named Meta-Learning with Task-Adaptive Loss Function (MeTAL), demonstrates the effectiveness and the flexibility across various domains, such as few-shot classification and few-shot regression.
PolyNet: Polynomial Neural Network for 3D Shape Recognition with PolyShape Representation
Oct 15, 2021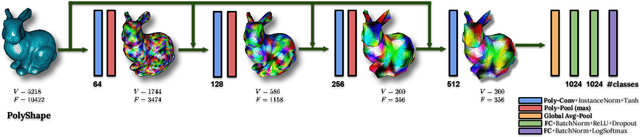
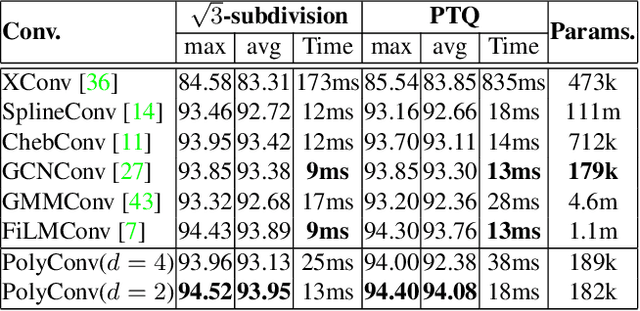
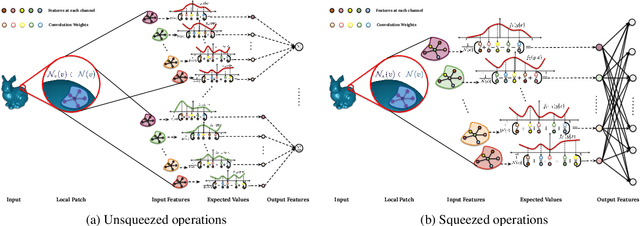
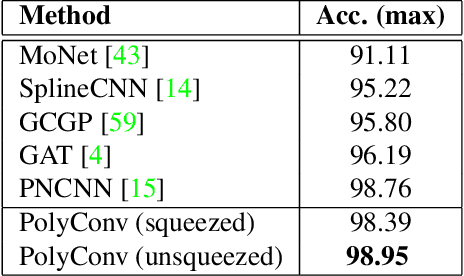
3D shape representation and its processing have substantial effects on 3D shape recognition. The polygon mesh as a 3D shape representation has many advantages in computer graphics and geometry processing. However, there are still some challenges for the existing deep neural network (DNN)-based methods on polygon mesh representation, such as handling the variations in the degree and permutations of the vertices and their pairwise distances. To overcome these challenges, we propose a DNN-based method (PolyNet) and a specific polygon mesh representation (PolyShape) with a multi-resolution structure. PolyNet contains two operations; (1) a polynomial convolution (PolyConv) operation with learnable coefficients, which learns continuous distributions as the convolutional filters to share the weights across different vertices, and (2) a polygonal pooling (PolyPool) procedure by utilizing the multi-resolution structure of PolyShape to aggregate the features in a much lower dimension. Our experiments demonstrate the strength and the advantages of PolyNet on both 3D shape classification and retrieval tasks compared to existing polygon mesh-based methods and its superiority in classifying graph representations of images. The code is publicly available from https://myavartanoo.github.io/polynet/.
Toward Real-World Super-Resolution via Adaptive Downsampling Models
Sep 08, 2021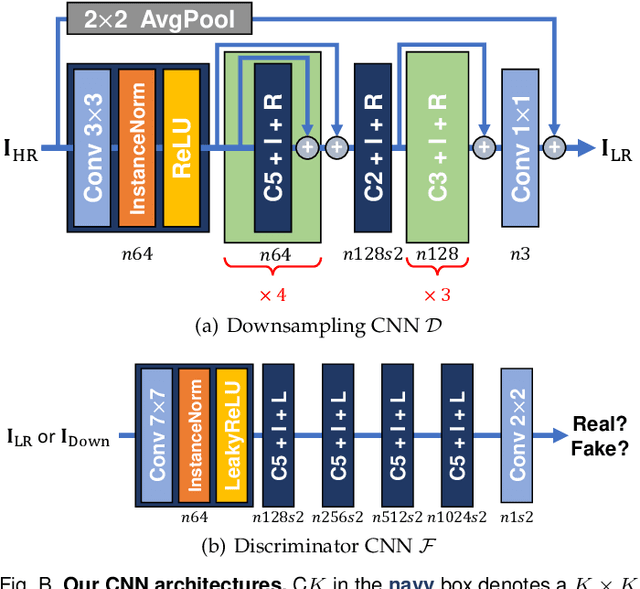

Most image super-resolution (SR) methods are developed on synthetic low-resolution (LR) and high-resolution (HR) image pairs that are constructed by a predetermined operation, e.g., bicubic downsampling. As existing methods typically learn an inverse mapping of the specific function, they produce blurry results when applied to real-world images whose exact formulation is different and unknown. Therefore, several methods attempt to synthesize much more diverse LR samples or learn a realistic downsampling model. However, due to restrictive assumptions on the downsampling process, they are still biased and less generalizable. This study proposes a novel method to simulate an unknown downsampling process without imposing restrictive prior knowledge. We propose a generalizable low-frequency loss (LFL) in the adversarial training framework to imitate the distribution of target LR images without using any paired examples. Furthermore, we design an adaptive data loss (ADL) for the downsampler, which can be adaptively learned and updated from the data during the training loops. Extensive experiments validate that our downsampling model can facilitate existing SR methods to perform more accurate reconstructions on various synthetic and real-world examples than the conventional approaches.
3DIAS: 3D Shape Reconstruction with Implicit Algebraic Surfaces
Aug 19, 2021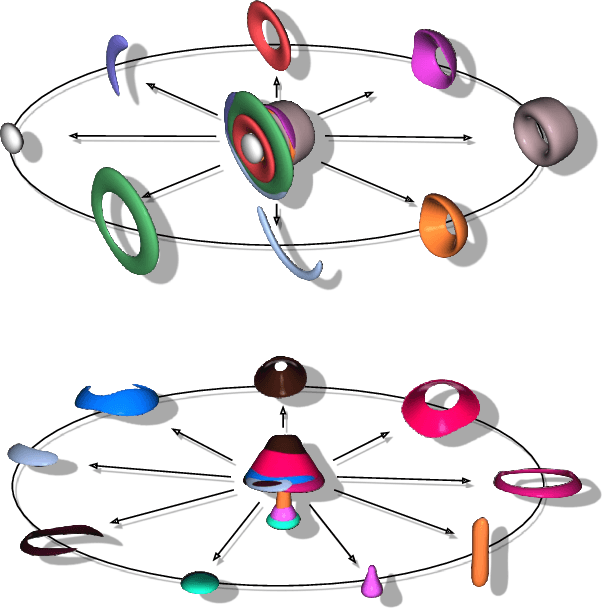
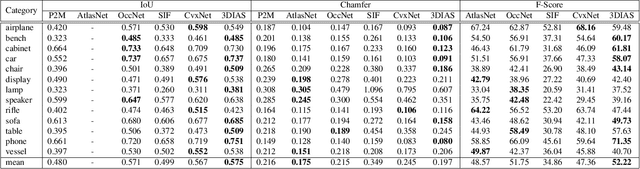
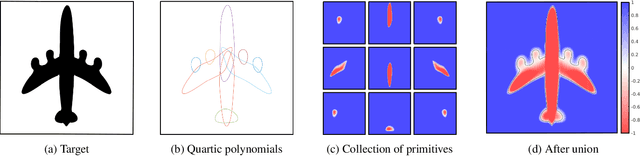

3D Shape representation has substantial effects on 3D shape reconstruction. Primitive-based representations approximate a 3D shape mainly by a set of simple implicit primitives, but the low geometrical complexity of the primitives limits the shape resolution. Moreover, setting a sufficient number of primitives for an arbitrary shape is challenging. To overcome these issues, we propose a constrained implicit algebraic surface as the primitive with few learnable coefficients and higher geometrical complexities and a deep neural network to produce these primitives. Our experiments demonstrate the superiorities of our method in terms of representation power compared to the state-of-the-art methods in single RGB image 3D shape reconstruction. Furthermore, we show that our method can semantically learn segments of 3D shapes in an unsupervised manner. The code is publicly available from https://myavartanoo.github.io/3dias/ .