 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human-Object Interaction for 3D Human Pose Estimation from LiDAR Point Clouds
Mar 17, 2026Understanding humans from LiDAR point clouds is one of the most critical tasks in autonomous driving due to its close relationships with pedestrian safety, yet it remains challenging in the presence of diverse human-object interactions and cluttered backgrounds. Nevertheless, existing methods largely overlook the potential of leveraging human-object interactions to build robust 3D human pose estimation frameworks. There are two major challenges that motivate the incorporation of human-object interaction. First, human-object interactions introduce spatial ambiguity between human and object points, which often leads to erroneous 3D human keypoint predictions in interaction regions. Second, there exists severe class imbalance in the number of points between interacting and non-interacting body parts, with the interaction-frequent regions such as hand and foot being sparsely observed in LiDAR data. To address these challenges, we propose a Human-Object Interaction Learning (HOIL) framework for robust 3D human pose estimation from LiDAR point clouds. To mitigate the spatial ambiguity issue, we present human-object interaction-aware contrastive learning (HOICL) that effectively enhances feature discrimination between human and object points, particularly in interaction regions. To alleviate the class imbalance issue, we introduce contact-aware part-guided pooling (CPPool) that adaptively reallocates representational capacity by compressing overrepresented points while preserving informative points from interacting body parts. In addition, we present an optional contact-based temporal refinement that refines erroneous per-frame keypoint estimates using contact cues over time. As a result, our HOIL effectively leverages human-object interaction to resolve spatial ambiguity and class imbalance in interaction regions. Codes will be released.
Meta-Learning with Task-Adaptive Loss Function for Few-Shot Learning
Oct 17, 2021
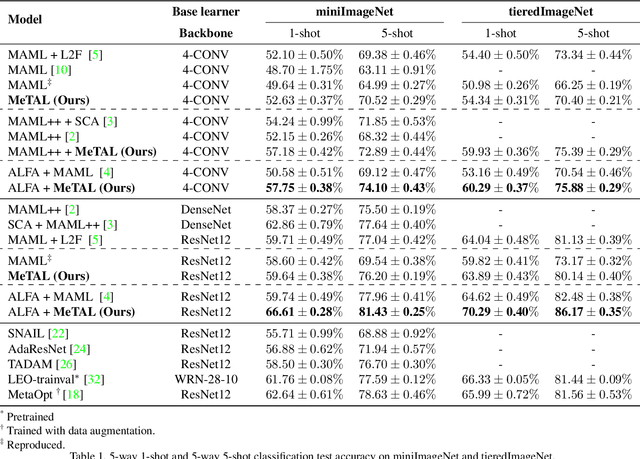
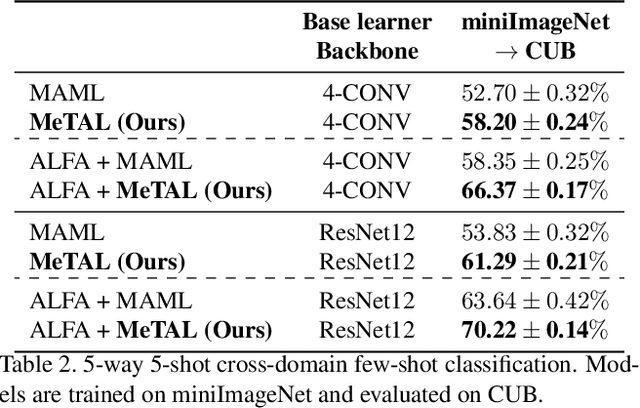
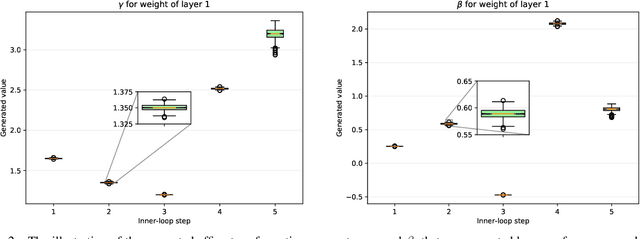
In few-shot learning scenarios, the challenge is to generalize and perform well on new unseen examples when only very few labeled examples are available for each task. Model-agnostic meta-learning (MAML) has gained the popularity as one of the representative few-shot learning methods for its flexibility and applicability to diverse problems. However, MAML and its variants often resort to a simple loss function without any auxiliary loss function or regularization terms that can help achieve better generalization. The problem lies in that each application and task may require different auxiliary loss function, especially when tasks are diverse and distinct. Instead of attempting to hand-design an auxiliary loss function for each application and task, we introduce a new meta-learning framework with a loss function that adapts to each task. Our proposed framework, named Meta-Learning with Task-Adaptive Loss Function (MeTAL), demonstrates the effectiveness and the flexibility across various domains, such as few-shot classification and few-shot regression.