 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Truly Embody Human Personality? Analyzing AI and Human Behavior Alignment in Dispute Resolution
Feb 07, 2026Large language models (LLMs) are increasingly used to simulate human behavior in social settings such as legal mediation, negotiation, and dispute resolution. However, it remains unclear whether these simulations reproduce the personality-behavior patterns observed in humans. Human personality, for instance, shapes how individuals navigate social interactions, including strategic choices and behaviors in emotionally charged interactions. This raises the question: Can LLMs, when prompted with personality traits, reproduce personality-driven differences in human conflict behavior? To explore this, we introduce an evaluation framework that enables direct comparison of human-human and LLM-LLM behaviors in dispute resolution dialogues with respect to Big Five Inventory (BFI) personality traits. This framework provides a set of interpretable metrics related to strategic behavior and conflict outcomes. We additionally contribute a novel dataset creation methodology for LLM dispute resolution dialogues with matched scenarios and personality traits with respect to human conversations. Finally, we demonstrate the use of our evaluation framework with three contemporary closed-source LLMs and show significant divergences in how personality manifests in conflict across different LLMs compared to human data, challenging the assumption that personality-prompted agents can serve as reliable behavioral proxies in socially impactful applications. Our work highlights the need for psychological grounding and validation in AI simulations before real-world use.
KODIS: A Multicultural Dispute Resolution Dialogue Corpus
Apr 17, 2025



We present KODIS, a dyadic dispute resolution corpus containing thousands of dialogues from over 75 countries. Motivated by a theoretical model of culture and conflict, participants engage in a typical customer service dispute designed by experts to evoke strong emotions and conflict. The corpus contains a rich set of dispositional, process, and outcome measures. The initial analysis supports theories of how anger expressions lead to escalatory spirals and highlights cultural differences in emotional expression. We make this corpus and data collection framework available to the community.
Building on Huang et al. GlossBERT for Word Sense Disambiguation
Dec 14, 2021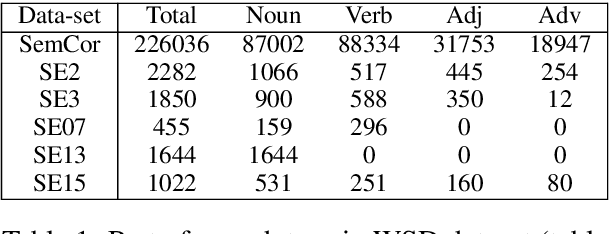
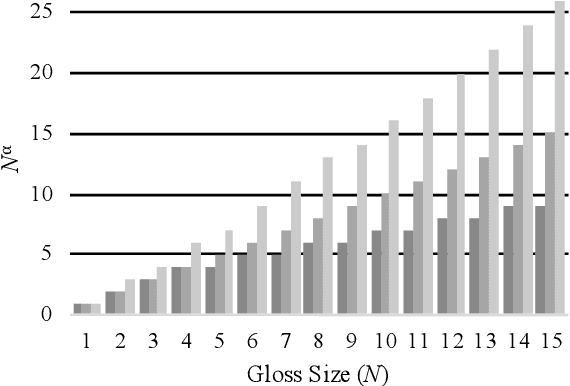
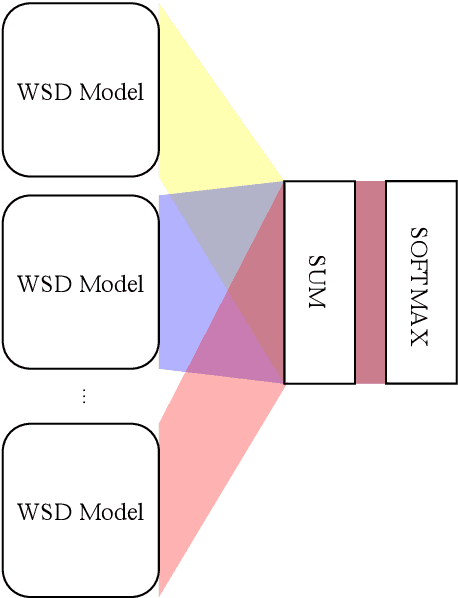
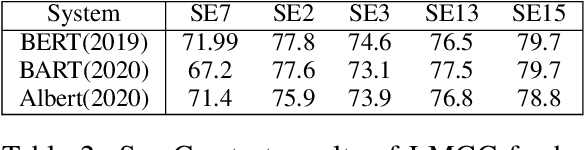
We propose to take on the problem ofWord Sense Disambiguation (WSD). In language, words of the same form can take different meanings depending on context. While humans easily infer the meaning or gloss of such words by their context, machines stumble on this task.As such, we intend to replicated and expand upon the results of Huang et al.GlossBERT, a model which they design to disambiguate these words (Huang et al.,2019). Specifically, we propose the following augmentations: data-set tweaking(alpha hyper-parameter), ensemble methods, and replacement of BERT with BART andALBERT. The following GitHub repository contains all code used in this report, which extends on the code made available by Huang et al.