 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRECAP: Regression Evaluation for Continual Adaptation of Prompts
Jun 04, 2026Production agentic systems routinely face evolving constraints and must comply from the very next interaction. Scenarios like a tool-call notification changing a compliance threshold or a policy update adding disclosure requirements fit this criteria, having close to no room for errors in production. This proactive adaptation setting is common in deployment, but absent from current benchmarks, which assume either static constraint sets or reactive protocols with evaluation feedback. We introduce RECAP, a benchmark that measures continual-learning phenomena (forgetting, regression, forward transfer) at the constraint level under a strictly proactive adapt-then-test protocol: prompt optimization methods receive only the constraint specification and must generalize before seeing any test data. Evaluating six methods across four LLMs and three schedules with evolving constraints, we find that these methods show no significant improvement in performance, even after incurring a higher latency. These methods, designed for offline or reactive settings, are inadequate for the proactive paradigm. Our work emphasizes the growing need for designing proactive prompt adaptation methods, where the models must remain robust to evolving needs in deployment.
Decomposing the Delta: What Do Models Actually Learn from Preference Pairs?
Apr 09, 2026Preference optimization methods such as DPO and KTO are widely used for aligning language models, yet little is understood about what properties of preference data drive downstream reasoning gains. We ask: what aspects of a preference pair improve a reasoning model's performance on general reasoning tasks? We investigate two distinct notions of quality delta in preference data: generator-level delta, arising from the differences in capability between models that generate chosen and rejected reasoning traces, and sample-level delta, arising from differences in judged quality differences within an individual preference pair. To study generator-level delta, we vary the generator's scale and model family, and to study sample-level delta, we employ an LLM-as-a-judge to rate the quality of generated traces along multiple reasoning-quality dimensions. We find that increasing generator-level delta steadily improves performance on out-of-domain reasoning tasks and filtering data by sample-level delta can enable more data-efficient training. Our results suggest a twofold recipe for improving reasoning performance through preference optimization: maximize generator-level delta when constructing preference pairs and exploit sample-level delta to select the most informative training examples.
MindScape Study: Integrating LLM and Behavioral Sensing for Personalized AI-Driven Journaling Experiences
Sep 15, 2024Mental health concerns are prevalent among college students, highlighting the need for effective interventions that promote self-awareness and holistic well-being. MindScape pioneers a novel approach to AI-powered journaling by integrating passively collected behavioral patterns such as conversational engagement, sleep, and location with Large Language Models (LLMs). This integration creates a highly personalized and context-aware journaling experience, enhancing self-awareness and well-being by embedding behavioral intelligence into AI. We present an 8-week exploratory study with 20 college students, demonstrating the MindScape app's efficacy in enhancing positive affect (7%), reducing negative affect (11%), loneliness (6%), and anxiety and depression, with a significant week-over-week decrease in PHQ-4 scores (-0.25 coefficient), alongside improvements in mindfulness (7%) and self-reflection (6%). The study highlights the advantages of contextual AI journaling, with participants particularly appreciating the tailored prompts and insights provided by the MindScape app. Our analysis also includes a comparison of responses to AI-driven contextual versus generic prompts, participant feedback insights, and proposed strategies for leveraging contextual AI journaling to improve well-being on college campuses. By showcasing the potential of contextual AI journaling to support mental health, we provide a foundation for further investigation into the effects of contextual AI journaling on mental health and well-being.
Contextual AI Journaling: Integrating LLM and Time Series Behavioral Sensing Technology to Promote Self-Reflection and Well-being using the MindScape App
Mar 30, 2024MindScape aims to study the benefits of integrating time series behavioral patterns (e.g., conversational engagement, sleep, location) with Large Language Models (LLMs) to create a new form of contextual AI journaling, promoting self-reflection and well-being. We argue that integrating behavioral sensing in LLMs will likely lead to a new frontier in AI. In this Late-Breaking Work paper, we discuss the MindScape contextual journal App design that uses LLMs and behavioral sensing to generate contextual and personalized journaling prompts crafted to encourage self-reflection and emotional development. We also discuss the MindScape study of college students based on a preliminary user study and our upcoming study to assess the effectiveness of contextual AI journaling in promoting better well-being on college campuses. MindScape represents a new application class that embeds behavioral intelligence in AI.
Towards Multi-Objective Statistically Fair Federated Learning
Jan 24, 2022



Federated Learning (FL) has emerged as a result of data ownership and privacy concerns to prevent data from being shared between multiple parties included in a training procedure. Although issues, such as privacy, have gained significant attention in this domain, not much attention has been given to satisfying statistical fairness measures in the FL setting. With this goal in mind, we conduct studies to show that FL is able to satisfy different fairness metrics under different data regimes consisting of different types of clients. More specifically, uncooperative or adversarial clients might contaminate the global FL model by injecting biased or poisoned models due to existing biases in their training datasets. Those biases might be a result of imbalanced training set (Zhang and Zhou 2019), historical biases (Mehrabi et al. 2021a), or poisoned data-points from data poisoning attacks against fairness (Mehrabi et al. 2021b; Solans, Biggio, and Castillo 2020). Thus, we propose a new FL framework that is able to satisfy multiple objectives including various statistical fairness metrics. Through experimentation, we then show the effectiveness of this method comparing it with various baselines, its ability in satisfying different objectives collectively and individually, and its ability in identifying uncooperative or adversarial clients and down-weighing their effect
A Closer Look At Feature Space Data Augmentation For Few-Shot Intent Classification
Oct 09, 2019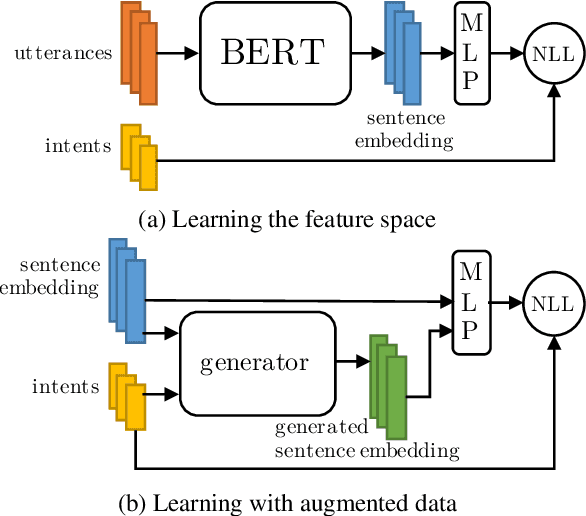
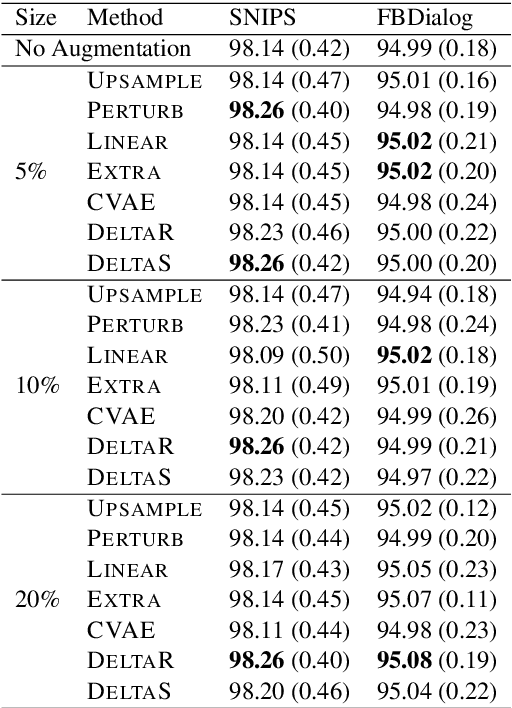
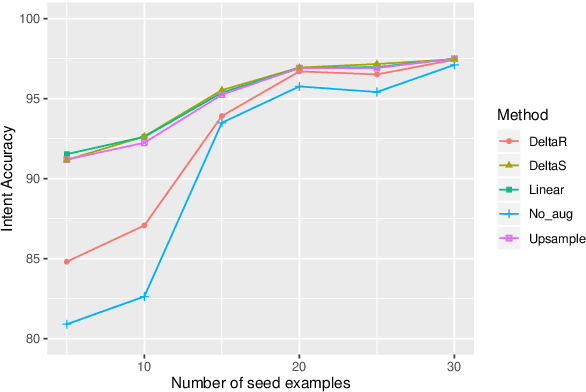
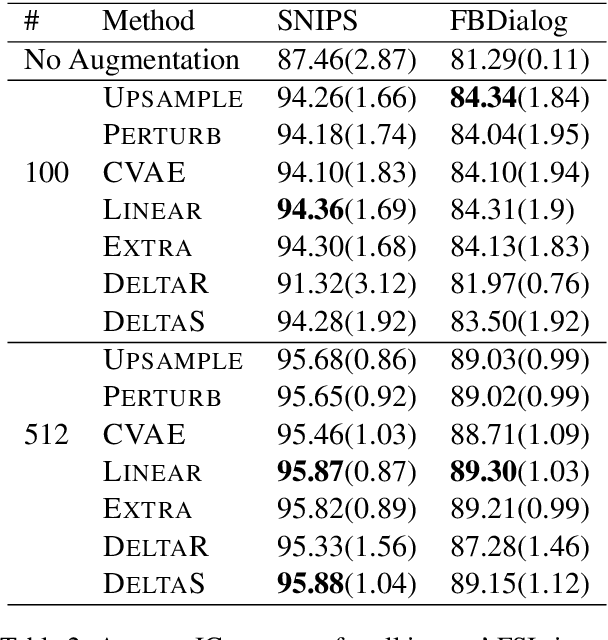
New conversation topics and functionalities are constantly being added to conversational AI agents like Amazon Alexa and Apple Siri. As data collection and annotation is not scalable and is often costly, only a handful of examples for the new functionalities are available, which results in poor generalization performance. We formulate it as a Few-Shot Integration (FSI) problem where a few examples are used to introduce a new intent. In this paper, we study six feature space data augmentation methods to improve classification performance in FSI setting in combination with both supervised and unsupervised representation learning methods such as BERT. Through realistic experiments on two public conversational datasets, SNIPS, and the Facebook Dialog corpus, we show that data augmentation in feature space provides an effective way to improve intent classification performance in few-shot setting beyond traditional transfer learning approaches. In particular, we show that (a) upsampling in latent space is a competitive baseline for feature space augmentation (b) adding the difference between two examples to a new example is a simple yet effective data augmentation method.
Multimodal Sparse Coding for Event Detection
May 17, 2016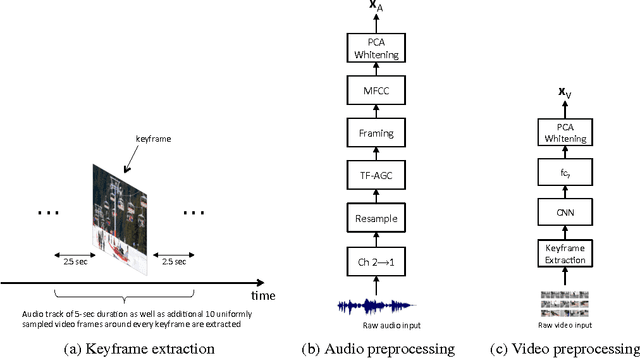
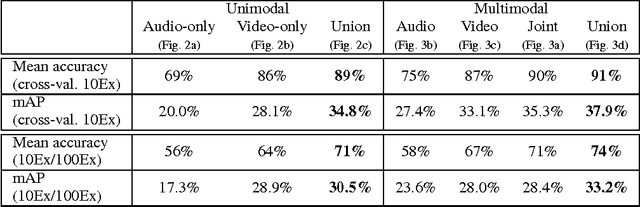
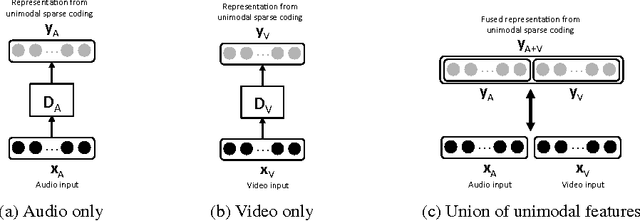
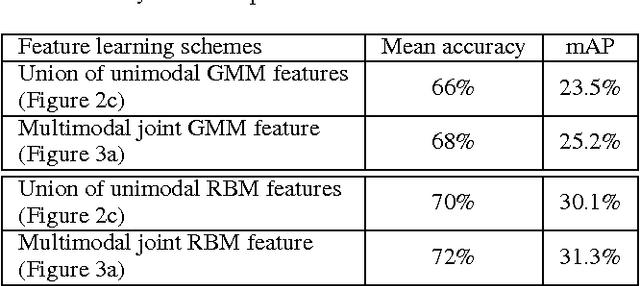
Unsupervised feature learning methods have proven effective for classification tasks based on a single modality. We present multimodal sparse coding for learning feature representations shared across multiple modalities. The shared representations are applied to multimedia event detection (MED) and evaluated in comparison to unimodal counterparts, as well as other feature learning methods such as GMM supervectors and sparse RBM. We report the cross-validated classification accuracy and mean average precision of the MED system trained on features learned from our unimodal and multimodal settings for a subset of the TRECVID MED 2014 dataset.