 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoFlow: Reinforcing Search Agent Via Reward Density Optimization
Oct 30, 2025Reinforcement Learning with Verifiable Rewards (RLVR) is a promising approach for enhancing agentic deep search. However, its application is often hindered by low \textbf{Reward Density} in deep search scenarios, where agents expend significant exploratory costs for infrequent and often null final rewards. In this paper, we formalize this challenge as the \textbf{Reward Density Optimization} problem, which aims to improve the reward obtained per unit of exploration cost. This paper introduce \textbf{InfoFlow}, a systematic framework that tackles this problem from three aspects. 1) \textbf{Subproblem decomposition}: breaking down long-range tasks to assign process rewards, thereby providing denser learning signals. 2) \textbf{Failure-guided hints}: injecting corrective guidance into stalled trajectories to increase the probability of successful outcomes. 3) \textbf{Dual-agent refinement}: employing a dual-agent architecture to offload the cognitive burden of deep exploration. A refiner agent synthesizes the search history, which effectively compresses the researcher's perceived trajectory, thereby reducing exploration cost and increasing the overall reward density. We evaluate InfoFlow on multiple agentic search benchmarks, where it significantly outperforms strong baselines, enabling lightweight LLMs to achieve performance comparable to advanced proprietary LLMs.
RACap: Relation-Aware Prompting for Lightweight Retrieval-Augmented Image Captioning
Sep 19, 2025Recent retrieval-augmented image captioning methods incorporate external knowledge to compensate for the limitations in comprehending complex scenes. However, current approaches face challenges in relation modeling: (1) the representation of semantic prompts is too coarse-grained to capture fine-grained relationships; (2) these methods lack explicit modeling of image objects and their semantic relationships. To address these limitations, we propose RACap, a relation-aware retrieval-augmented model for image captioning, which not only mines structured relation semantics from retrieval captions, but also identifies heterogeneous objects from the image. RACap effectively retrieves structured relation features that contain heterogeneous visual information to enhance the semantic consistency and relational expressiveness. Experimental results show that RACap, with only 10.8M trainable parameters, achieves superior performance compared to previous lightweight captioning models.
OmniGen2: Exploration to Advanced Multimodal Generation
Jun 23, 2025In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. This design enables OmniGen2 to build upon existing multimodal understanding models without the need to re-adapt VAE inputs, thereby preserving the original text generation capabilities. To facilitate the training of OmniGen2, we developed comprehensive data construction pipelines, encompassing image editing and in-context generation data. Additionally, we introduce a reflection mechanism tailored for image generation tasks and curate a dedicated reflection dataset based on OmniGen2. Despite its relatively modest parameter size, OmniGen2 achieves competitive results on multiple task benchmarks, including text-to-image and image editing. To further evaluate in-context generation, also referred to as subject-driven tasks, we introduce a new benchmark named OmniContext. OmniGen2 achieves state-of-the-art performance among open-source models in terms of consistency. We will release our models, training code, datasets, and data construction pipeline to support future research in this field. Project Page: https://vectorspacelab.github.io/OmniGen2; GitHub Link: https://github.com/VectorSpaceLab/OmniGen2
Does RAG Really Perform Bad For Long-Context Processing?
Feb 17, 2025



The efficient processing of long context poses a serious challenge for large language models (LLMs). Recently, retrieval-augmented generation (RAG) has emerged as a promising strategy for this problem, as it enables LLMs to make selective use of the long context for efficient computation. However, existing RAG approaches lag behind other long-context processing methods due to inherent limitations on inaccurate retrieval and fragmented contexts. To address these challenges, we introduce RetroLM, a novel RAG framework for long-context processing. Unlike traditional methods, RetroLM employs KV-level retrieval augmentation, where it partitions the LLM's KV cache into contiguous pages and retrieves the most crucial ones for efficient computation. This approach enhances robustness to retrieval inaccuracy, facilitates effective utilization of fragmented contexts, and saves the cost from repeated computation. Building on this framework, we further develop a specialized retriever for precise retrieval of critical pages and conduct unsupervised post-training to optimize the model's ability to leverage retrieved information. We conduct comprehensive evaluations with a variety of benchmarks, including LongBench, InfiniteBench, and RULER, where RetroLM significantly outperforms existing long-context LLMs and efficient long-context processing methods, particularly in tasks requiring intensive reasoning or extremely long-context comprehension.
Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment
Aug 23, 2024



Pretrained language models like BERT and T5 serve as crucial backbone encoders for dense retrieval. However, these models often exhibit limited generalization capabilities and face challenges in improving in domain accuracy. Recent research has explored using large language models (LLMs) as retrievers, achieving SOTA performance across various tasks. Despite these advancements, the specific benefits of LLMs over traditional retrievers and the impact of different LLM configurations, such as parameter sizes, pretraining duration, and alignment processes on retrieval tasks remain unclear. In this work, we conduct a comprehensive empirical study on a wide range of retrieval tasks, including in domain accuracy, data efficiency, zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. We evaluate over 15 different backbone LLMs and non LLMs. Our findings reveal that larger models and extensive pretraining consistently enhance in domain accuracy and data efficiency. Additionally, larger models demonstrate significant potential in zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. These results underscore the advantages of LLMs as versatile and effective backbone encoders in dense retrieval, providing valuable insights for future research and development in this field.
Enhanced Cascade Prostate Cancer Classifier in mp-MRI Utilizing Recall Feedback Adaptive Loss and Prior Knowledge-Based Feature Extraction
Aug 19, 2024



Prostate cancer is the second most common cancer in males worldwide, and mpMRI is commonly used for diagnosis. However, interpreting mpMRI is challenging and requires expertise from radiologists. This highlights the urgent need for automated grading in mpMRI. Existing studies lack integration of clinical prior information and suffer from uneven training sample distribution due to prevalence. Therefore, we propose a solution that incorporates prior knowledge, addresses the issue of uneven medical sample distribution, and maintains high interpretability in mpMRI. Firstly, we introduce Prior Knowledge-Based Feature Extraction, which mathematically models the PI-RADS criteria for prostate cancer as diagnostic information into model training. Secondly, we propose Adaptive Recall Feedback Loss to address the extremely imbalanced data problem. This method adjusts the training dynamically based on accuracy and recall in the validation set, resulting in high accuracy and recall simultaneously in the testing set.Thirdly, we design an Enhanced Cascade Prostate Cancer Classifier that classifies prostate cancer into different levels in an interpretable way, which refines the classification results and helps with clinical intervention. Our method is validated through experiments on the PI-CAI dataset and outperforms other methods with a more balanced result in both accuracy and recall rate.
BGE Landmark Embedding: A Chunking-Free Embedding Method For Retrieval Augmented Long-Context Large Language Models
Feb 18, 2024



Large language models (LLMs) call for extension of context to handle many critical applications. However, the existing approaches are prone to expensive costs and inferior quality of context extension. In this work, we proposeExtensible Embedding, which realizes high-quality extension of LLM's context with strong flexibility and cost-effectiveness. Extensible embedding stand as an enhancement of typical token embedding, which represents the information for an extensible scope of context instead of a single token. By leveraging such compact input units of higher information density, the LLM can access to a vast scope of context even with a small context window. Extensible embedding is systematically optimized in architecture and training method, which leads to multiple advantages. 1) High flexibility of context extension, which flexibly supports ad-hoc extension of diverse context lengths. 2) Strong sample efficiency of training, which enables the embedding model to be learned in a cost-effective way. 3) Superior compatibility with the existing LLMs, where the extensible embedding can be seamlessly introduced as a plug-in component. Comprehensive evaluations on long-context language modeling and understanding tasks verify extensible embedding as an effective, efficient, flexible, and compatible method to extend the LLM's context.
BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
Feb 10, 2024



In this paper, we present a new embedding model, called M3-Embedding, which is distinguished for its versatility in Multi-Linguality, Multi-Functionality, and Multi-Granularity. It can support more than 100 working languages, leading to new state-of-the-art performances on multi-lingual and cross-lingual retrieval tasks. It can simultaneously perform the three common retrieval functionalities of embedding model: dense retrieval, multi-vector retrieval, and sparse retrieval, which provides a unified model foundation for real-world IR applications. It is able to process inputs of different granularities, spanning from short sentences to long documents of up to 8192 tokens. The effective training of M3-Embedding involves the following technical contributions. We propose a novel self-knowledge distillation approach, where the relevance scores from different retrieval functionalities can be integrated as the teacher signal to enhance the training quality. We also optimize the batching strategy, enabling a large batch size and high training throughput to ensure the discriminativeness of embeddings. To the best of our knowledge, M3-Embedding is the first embedding model which realizes such a strong versatility. The model and code will be publicly available at https://github.com/FlagOpen/FlagEmbedding.
Adaptive Human Matting for Dynamic Videos
Apr 12, 2023



The most recent efforts in video matting have focused on eliminating trimap dependency since trimap annotations are expensive and trimap-based methods are less adaptable for real-time applications. Despite the latest tripmap-free methods showing promising results, their performance often degrades when dealing with highly diverse and unstructured videos. We address this limitation by introducing Adaptive Matting for Dynamic Videos, termed AdaM, which is a framework designed for simultaneously differentiating foregrounds from backgrounds and capturing alpha matte details of human subjects in the foreground. Two interconnected network designs are employed to achieve this goal: (1) an encoder-decoder network that produces alpha mattes and intermediate masks which are used to guide the transformer in adaptively decoding foregrounds and backgrounds, and (2) a transformer network in which long- and short-term attention combine to retain spatial and temporal contexts, facilitating the decoding of foreground details. We benchmark and study our methods on recently introduced datasets, showing that our model notably improves matting realism and temporal coherence in complex real-world videos and achieves new best-in-class generalizability. Further details and examples are available at https://github.com/microsoft/AdaM.
Robust data analysis and imaging with computational ghost imaging
Nov 06, 2021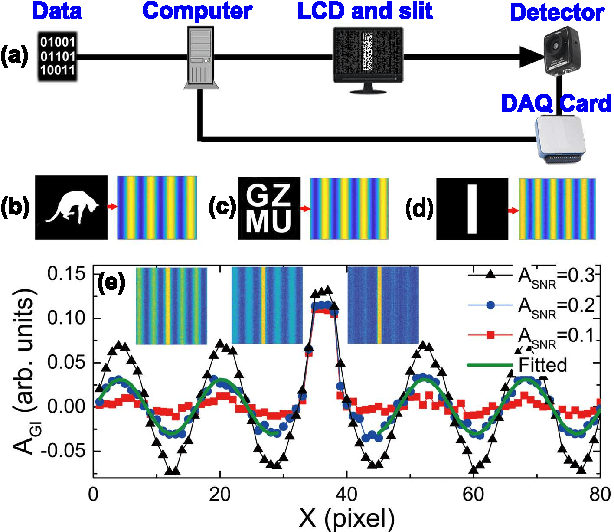
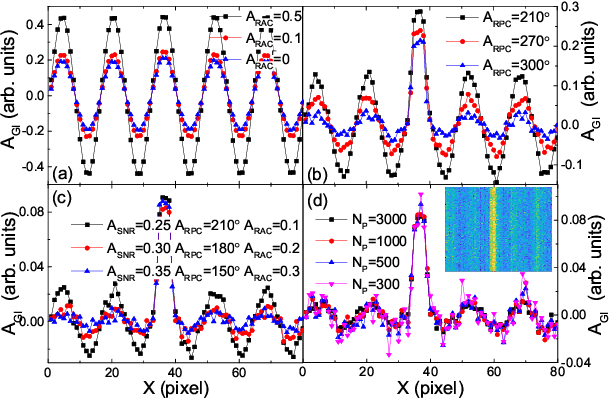
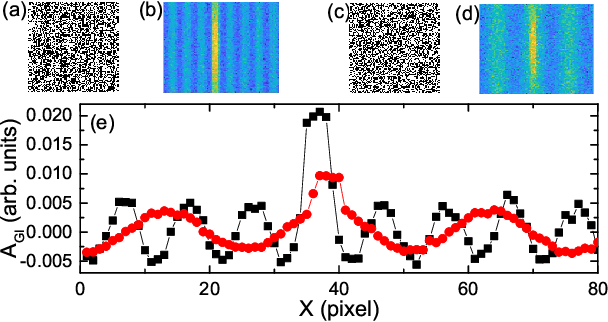
Nowadays the world has entered into the digital age, in which the data analysis and visualization have become more and more important. In analogy to imaging the real object, we demonstrate that the computational ghost imaging can image the digital data to show their characteristics, such as periodicity. Furthermore, our experimental results show that the use of optical imaging methods to analyse data exhibits unique advantages, especially in anti-interference. The data analysis with computational ghost imaging can be well performed against strong noise, random amplitude and phase changes in the binarized signals. Such robust data data analysis and imaging has an important application prospect in big data analysis, meteorology, astronomy, economics and many other fields.