 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffeomorphic Deformation via Sliced Wasserstein Distance Optimization for Cortical Surface Reconstruction
May 27, 2023



Mesh deformation is a core task for 3D mesh reconstruction, but defining an efficient discrepancy between predicted and target meshes remains an open problem. A prevalent approach in current deep learning is the set-based approach which measures the discrepancy between two surfaces by comparing two randomly sampled point-clouds from the two meshes with Chamfer pseudo-distance. Nevertheless, the set-based approach still has limitations such as lacking a theoretical guarantee for choosing the number of points in sampled point-clouds, and the pseudo-metricity and the quadratic complexity of the Chamfer divergence. To address these issues, we propose a novel metric for learning mesh deformation. The metric is defined by sliced Wasserstein distance on meshes represented as probability measures that generalize the set-based approach. By leveraging probability measure space, we gain flexibility in encoding meshes using diverse forms of probability measures, such as continuous, empirical, and discrete measures via \textit{varifold} representation. After having encoded probability measures, we can compare meshes by using the sliced Wasserstein distance which is an effective optimal transport distance with linear computational complexity and can provide a fast statistical rate for approximating the surface of meshes. Furthermore, we employ a neural ordinary differential equation (ODE) to deform the input surface into the target shape by modeling the trajectories of the points on the surface. Our experiments on cortical surface reconstruction demonstrate that our approach surpasses other competing methods in multiple datasets and metrics.
MedGen3D: A Deep Generative Framework for Paired 3D Image and Mask Generation
Apr 08, 2023



Acquiring and annotating sufficient labeled data is crucial in developing accurate and robust learning-based models, but obtaining such data can be challenging in many medical image segmentation tasks. One promising solution is to synthesize realistic data with ground-truth mask annotations. However, no prior studies have explored generating complete 3D volumetric images with masks. In this paper, we present MedGen3D, a deep generative framework that can generate paired 3D medical images and masks. First, we represent the 3D medical data as 2D sequences and propose the Multi-Condition Diffusion Probabilistic Model (MC-DPM) to generate multi-label mask sequences adhering to anatomical geometry. Then, we use an image sequence generator and semantic diffusion refiner conditioned on the generated mask sequences to produce realistic 3D medical images that align with the generated masks. Our proposed framework guarantees accurate alignment between synthetic images and segmentation maps. Experiments on 3D thoracic CT and brain MRI datasets show that our synthetic data is both diverse and faithful to the original data, and demonstrate the benefits for downstream segmentation tasks. We anticipate that MedGen3D's ability to synthesize paired 3D medical images and masks will prove valuable in training deep learning models for medical imaging tasks.
Localized Region Contrast for Enhancing Self-Supervised Learning in Medical Image Segmentation
Apr 06, 2023



Recent advancements in self-supervised learning have demonstrated that effective visual representations can be learned from unlabeled images. This has led to increased interest in applying self-supervised learning to the medical domain, where unlabeled images are abundant and labeled images are difficult to obtain. However, most self-supervised learning approaches are modeled as image level discriminative or generative proxy tasks, which may not capture the finer level representations necessary for dense prediction tasks like multi-organ segmentation. In this paper, we propose a novel contrastive learning framework that integrates Localized Region Contrast (LRC) to enhance existing self-supervised pre-training methods for medical image segmentation. Our approach involves identifying Super-pixels by Felzenszwalb's algorithm and performing local contrastive learning using a novel contrastive sampling loss. Through extensive experiments on three multi-organ segmentation datasets, we demonstrate that integrating LRC to an existing self-supervised method in a limited annotation setting significantly improves segmentation performance. Moreover, we show that LRC can also be applied to fully-supervised pre-training methods to further boost performance.
Identity-Aware Hand Mesh Estimation and Personalization from RGB Images
Sep 22, 2022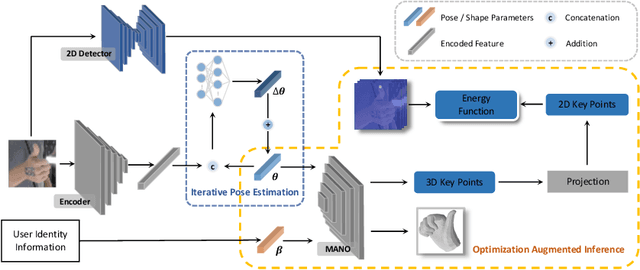
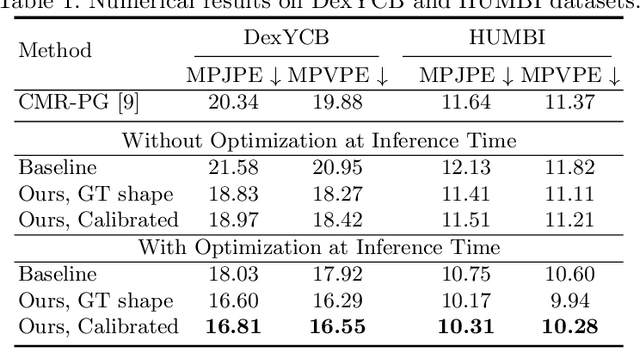
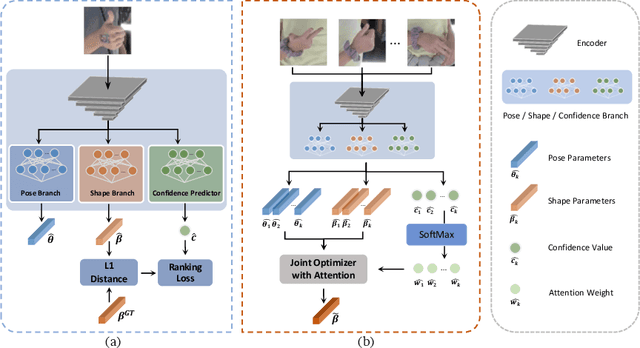
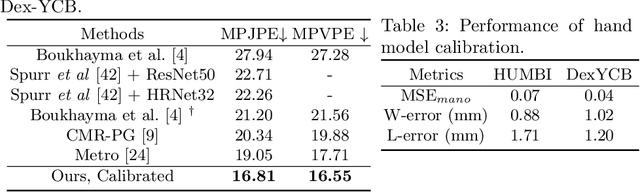
Reconstructing 3D hand meshes from monocular RGB images has attracted increasing amount of attention due to its enormous potential applications in the field of AR/VR. Most state-of-the-art methods attempt to tackle this task in an anonymous manner. Specifically, the identity of the subject is ignored even though it is practically available in real applications where the user is unchanged in a continuous recording session. In this paper, we propose an identity-aware hand mesh estimation model, which can incorporate the identity information represented by the intrinsic shape parameters of the subject. We demonstrate the importance of the identity information by comparing the proposed identity-aware model to a baseline which treats subject anonymously. Furthermore, to handle the use case where the test subject is unseen, we propose a novel personalization pipeline to calibrate the intrinsic shape parameters using only a few unlabeled RGB images of the subject. Experiments on two large scale public datasets validate the state-of-the-art performance of our proposed method.
MIRNF: Medical Image Registration via Neural Fields
Jun 07, 2022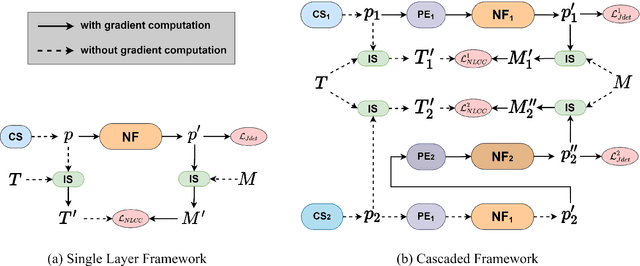
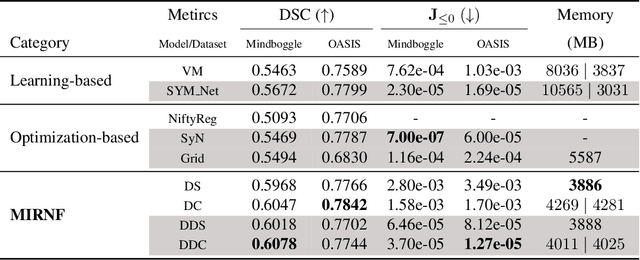
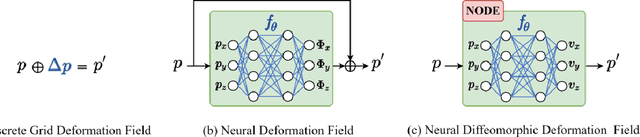
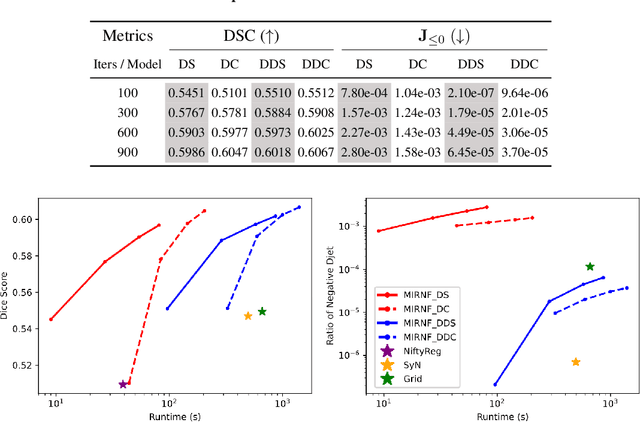
Image registration is widely used in medical image analysis to provide spatial correspondences between two images. Recently learning-based methods utilizing convolutional neural networks (CNNs) have been proposed for solving image registration problems. The learning-based methods tend to be much faster than traditional optimization-based methods, but the accuracy improvements gained from the complex CNN-based methods are modest. Here we introduce a new deep-neural net-based image registration framework, named \textbf{MIRNF}, which represents the correspondence mapping with a continuous function implemented via Neural Fields. MIRNF outputs either a deformation vector or velocity vector given a 3D coordinate as input. To ensure the mapping is diffeomorphic, the velocity vector output from MIRNF is integrated using the Neural ODE solver to derive the correspondences between two images. Furthermore, we propose a hybrid coordinate sampler along with a cascaded architecture to achieve the high-similarity mapping performance and low-distortion deformation fields. We conduct experiments on two 3D MR brain scan datasets, showing that our proposed framework provides state-of-art registration performance while maintaining comparable optimization time.
Topology-Preserving Shape Reconstruction and Registration via Neural Diffeomorphic Flow
Mar 21, 2022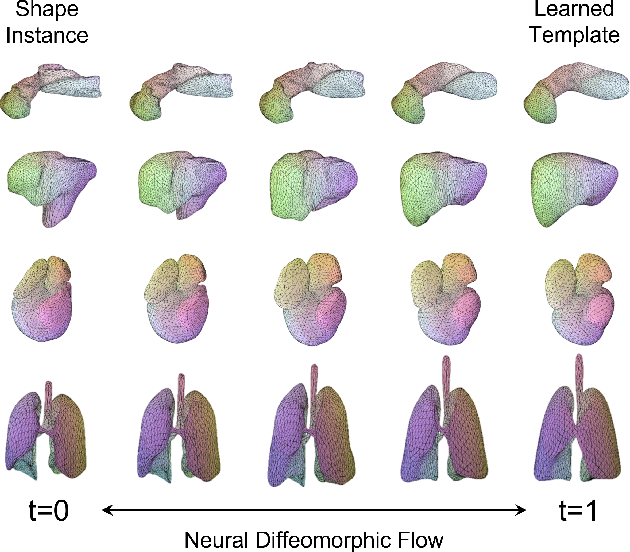

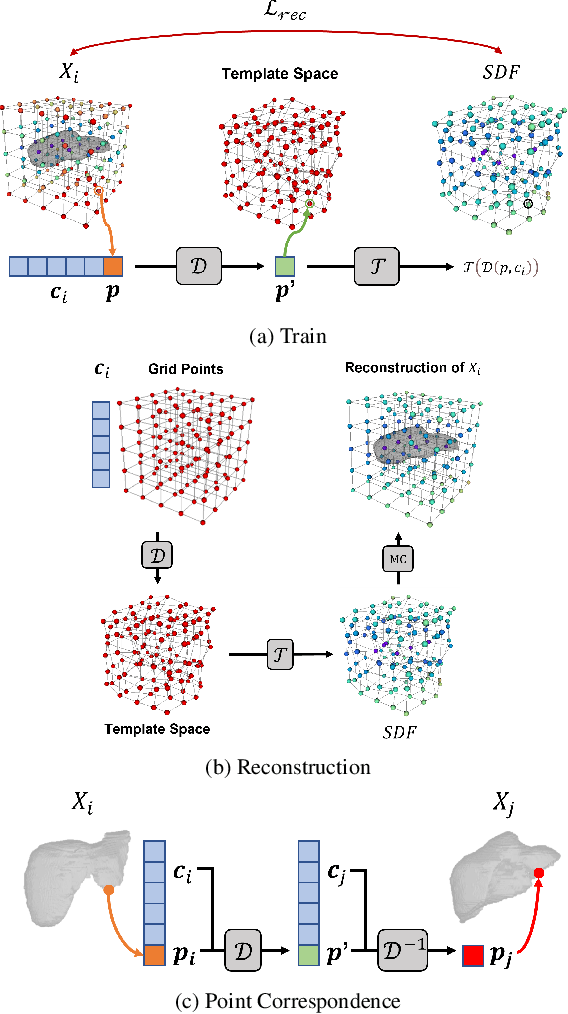
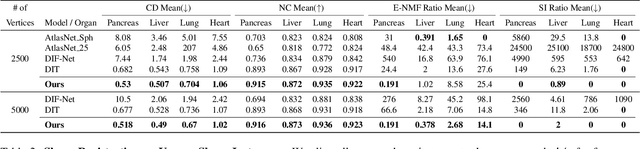
Deep Implicit Functions (DIFs) represent 3D geometry with continuous signed distance functions learned through deep neural nets. Recently DIFs-based methods have been proposed to handle shape reconstruction and dense point correspondences simultaneously, capturing semantic relationships across shapes of the same class by learning a DIFs-modeled shape template. These methods provide great flexibility and accuracy in reconstructing 3D shapes and inferring correspondences. However, the point correspondences built from these methods do not intrinsically preserve the topology of the shapes, unlike mesh-based template matching methods. This limits their applications on 3D geometries where underlying topological structures exist and matter, such as anatomical structures in medical images. In this paper, we propose a new model called Neural Diffeomorphic Flow (NDF) to learn deep implicit shape templates, representing shapes as conditional diffeomorphic deformations of templates, intrinsically preserving shape topologies. The diffeomorphic deformation is realized by an auto-decoder consisting of Neural Ordinary Differential Equation (NODE) blocks that progressively map shapes to implicit templates. We conduct extensive experiments on several medical image organ segmentation datasets to evaluate the effectiveness of NDF on reconstructing and aligning shapes. NDF achieves consistently state-of-the-art organ shape reconstruction and registration results in both accuracy and quality. The source code is publicly available at https://github.com/Siwensun/Neural_Diffeomorphic_Flow--NDF.
Diffeomorphic Image Registration with Neural Velocity Field
Mar 08, 2022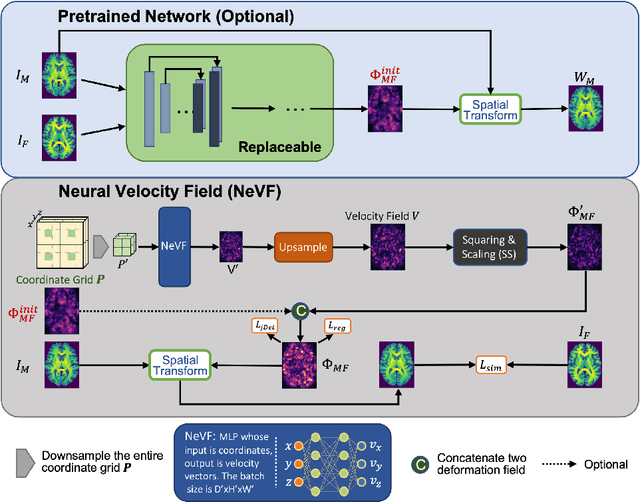
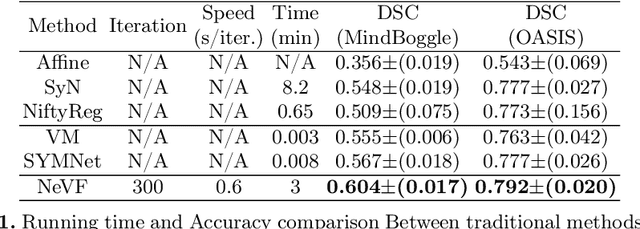
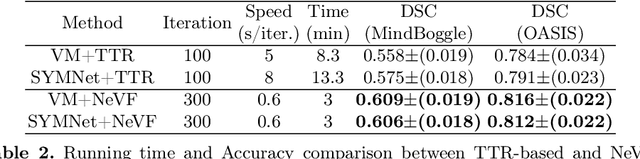
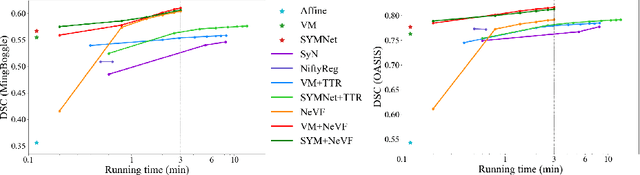
Diffeomorphic image registration is a crucial task in medical image analysis. Recent learning-based image registration methods utilize convolutional neural networks (CNN) to learn the spatial transformation between image pairs and achieve a fast inference speed. However, these methods often require a large number of training data to improve their generalization abilities. During the test time, learning-based methods might fail to provide a good registration result, which is likely because of the model overfitting on the training dataset. In this paper, we propose a neural representation of continuous velocity field (NeVF) to describe the deformations across two images. Specifically, this neural velocity field assigns a velocity vector to each point in the space, which has higher flexibility in modeling the complex deformation field. Furthermore, we propose a simple sparse-sampling strategy to reduce the memory consumption for the diffeomorphic registration. The proposed NeVF can also incorporate with a pre-trained learning-based model whose predicted deformation is taken as an initial state for optimization. Extensive experiments conducted on two large-scale 3D MR brain scan datasets demonstrate that our proposed method outperforms the state-of-the-art registration methods by a large margin.
A Hybrid Task-Oriented Dialog System with Domain and Task Adaptive Pretraining
Feb 08, 2021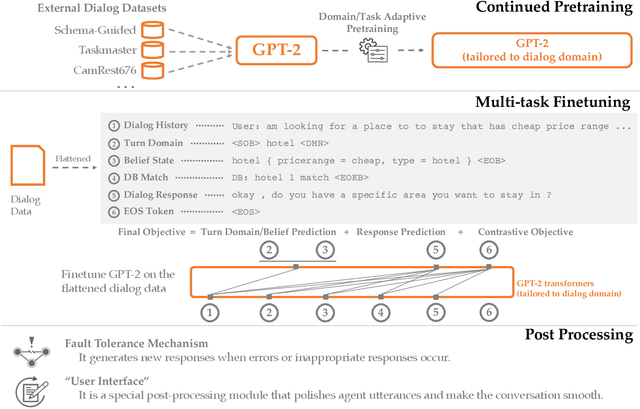

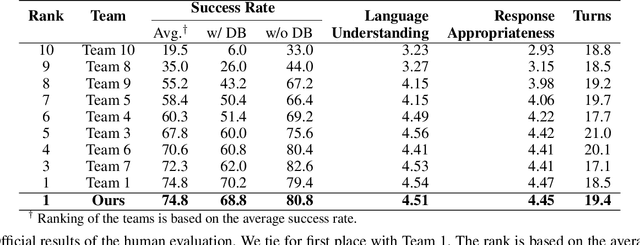
This paper describes our submission for the End-to-end Multi-domain Task Completion Dialog shared task at the 9th Dialog System Technology Challenge (DSTC-9). Participants in the shared task build an end-to-end task completion dialog system which is evaluated by human evaluation and a user simulator based automatic evaluation. Different from traditional pipelined approaches where modules are optimized individually and suffer from cascading failure, we propose an end-to-end dialog system that 1) uses Generative Pretraining 2 (GPT-2) as the backbone to jointly solve Natural Language Understanding, Dialog State Tracking, and Natural Language Generation tasks, 2) adopts Domain and Task Adaptive Pretraining to tailor GPT-2 to the dialog domain before finetuning, 3) utilizes heuristic pre/post-processing rules that greatly simplify the prediction tasks and improve generalizability, and 4) equips a fault tolerance module to correct errors and inappropriate responses. Our proposed method significantly outperforms baselines and ties for first place in the official evaluation. We make our source code publicly available.
Spatial Context-Aware Self-Attention Model For Multi-Organ Segmentation
Dec 16, 2020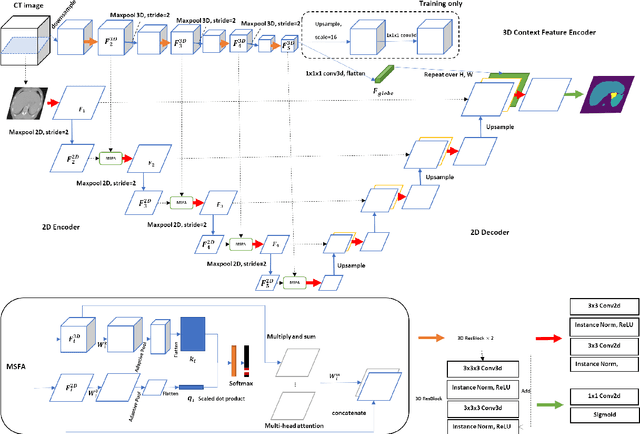

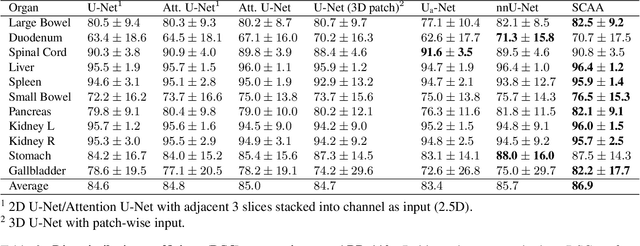
Multi-organ segmentation is one of most successful applications of deep learning in medical image analysis. Deep convolutional neural nets (CNNs) have shown great promise in achieving clinically applicable image segmentation performance on CT or MRI images. State-of-the-art CNN segmentation models apply either 2D or 3D convolutions on input images, with pros and cons associated with each method: 2D convolution is fast, less memory-intensive but inadequate for extracting 3D contextual information from volumetric images, while the opposite is true for 3D convolution. To fit a 3D CNN model on CT or MRI images on commodity GPUs, one usually has to either downsample input images or use cropped local regions as inputs, which limits the utility of 3D models for multi-organ segmentation. In this work, we propose a new framework for combining 3D and 2D models, in which the segmentation is realized through high-resolution 2D convolutions, but guided by spatial contextual information extracted from a low-resolution 3D model. We implement a self-attention mechanism to control which 3D features should be used to guide 2D segmentation. Our model is light on memory usage but fully equipped to take 3D contextual information into account. Experiments on multiple organ segmentation datasets demonstrate that by taking advantage of both 2D and 3D models, our method is consistently outperforms existing 2D and 3D models in organ segmentation accuracy, while being able to directly take raw whole-volume image data as inputs.
Speech SIMCLR: Combining Contrastive and Reconstruction Objective for Self-supervised Speech Representation Learning
Oct 27, 2020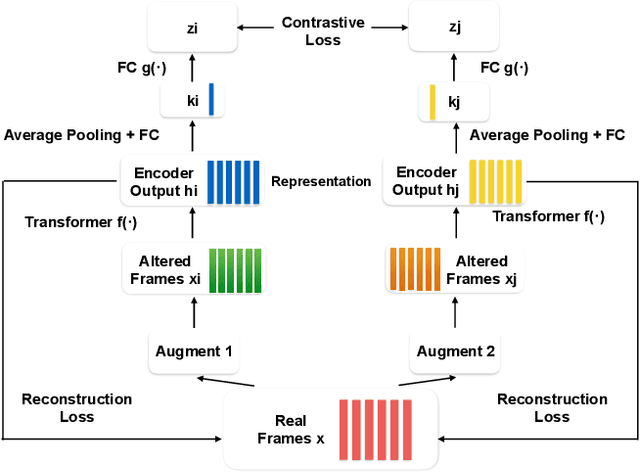

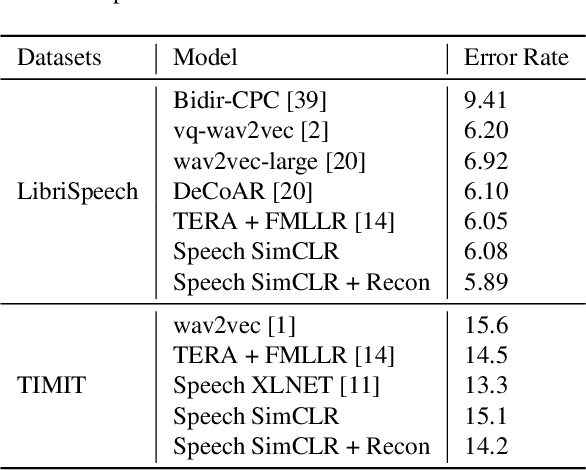

Self-supervised visual pretraining has shown significant progress recently. Among those methods, SimCLR greatly advanced the state of the art in self-supervised and semi-supervised learning on ImageNet. The input feature representations for speech and visual tasks are both continuous, so it is natural to consider applying similar objective on speech representation learning. In this paper, we propose Speech SimCLR, a new self-supervised objective for speech representation learning. During training, Speech SimCLR applies augmentation on raw speech and its spectrogram. Its objective is the combination of contrastive loss that maximizes agreement between differently augmented samples in the latent space and reconstruction loss of input representation. The proposed method achieved competitive results on speech emotion recognition and speech recognition. When used as feature extractor, our best model achieved 5.89% word error rate on LibriSpeech test-clean set using LibriSpeech 960 hours as pretraining data and LibriSpeech train-clean-100 set as fine-tuning data, which is the lowest error rate obtained in this setup to the best of our knowledge.