 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Rotation in Self-Supervised Contrastive Learning: Adaptive Positive or Negative Data Augmentation
Oct 23, 2022Rotation is frequently listed as a candidate for data augmentation in contrastive learning but seldom provides satisfactory improvements. We argue that this is because the rotated image is always treated as either positive or negative. The semantics of an image can be rotation-invariant or rotation-variant, so whether the rotated image is treated as positive or negative should be determined based on the content of the image. Therefore, we propose a novel augmentation strategy, adaptive Positive or Negative Data Augmentation (PNDA), in which an original and its rotated image are a positive pair if they are semantically close and a negative pair if they are semantically different. To achieve PNDA, we first determine whether rotation is positive or negative on an image-by-image basis in an unsupervised way. Then, we apply PNDA to contrastive learning frameworks. Our experiments showed that PNDA improves the performance of contrastive learning. The code is available at \url{ https://github.com/AtsuMiyai/rethinking_rotation}.
Saliency-based Multiple Region of Interest Detection from a Single 360° image
Sep 08, 2022

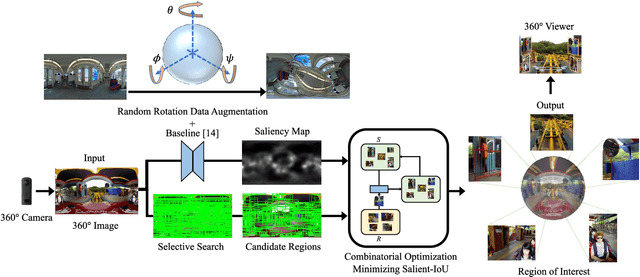
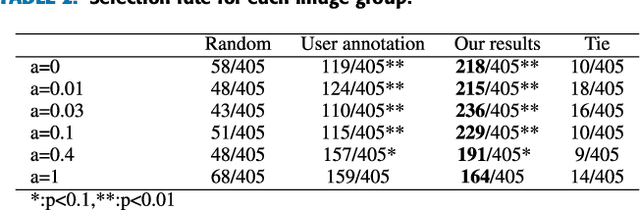
360{\deg} images are informative -- it contains omnidirectional visual information around the camera. However, the areas that cover a 360{\deg} image is much larger than the human's field of view, therefore important information in different view directions is easily overlooked. To tackle this issue, we propose a method for predicting the optimal set of Region of Interest (RoI) from a single 360{\deg} image using the visual saliency as a clue. To deal with the scarce, strongly biased training data of existing single 360{\deg} image saliency prediction dataset, we also propose a data augmentation method based on the spherical random data rotation. From the predicted saliency map and redundant candidate regions, we obtain the optimal set of RoIs considering both the saliency within a region and the Interaction-Over-Union (IoU) between regions. We conduct the subjective evaluation to show that the proposed method can select regions that properly summarize the input 360{\deg} image.
Evaluating the Stability of Deep Image Quality Assessment With Respect to Image Scaling
Jul 20, 2022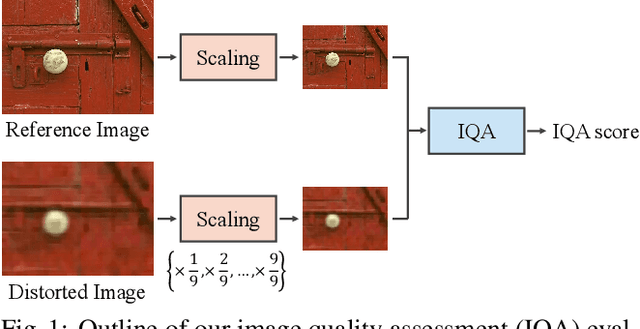
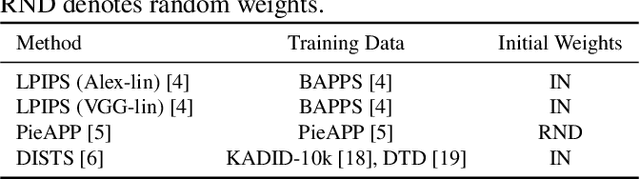
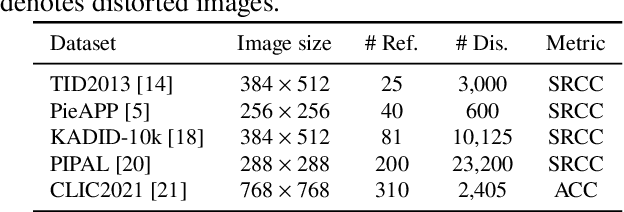

Image quality assessment (IQA) is a fundamental metric for image processing tasks (e.g., compression). With full-reference IQAs, traditional IQAs, such as PSNR and SSIM, have been used. Recently, IQAs based on deep neural networks (deep IQAs), such as LPIPS and DISTS, have also been used. It is known that image scaling is inconsistent among deep IQAs, as some perform down-scaling as pre-processing, whereas others instead use the original image size. In this paper, we show that the image scale is an influential factor that affects deep IQA performance. We comprehensively evaluate four deep IQAs on the same five datasets, and the experimental results show that image scale significantly influences IQA performance. We found that the most appropriate image scale is often neither the default nor the original size, and the choice differs depending on the methods and datasets used. We visualized the stability and found that PieAPP is the most stable among the four deep IQAs.
COO: Comic Onomatopoeia Dataset for Recognizing Arbitrary or Truncated Texts
Jul 11, 2022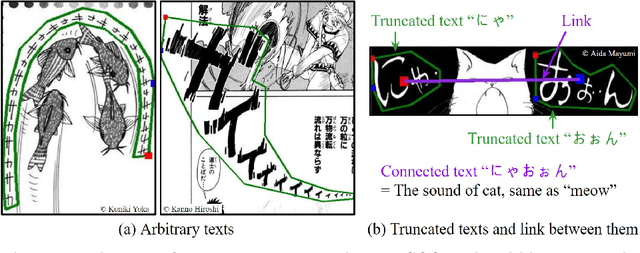
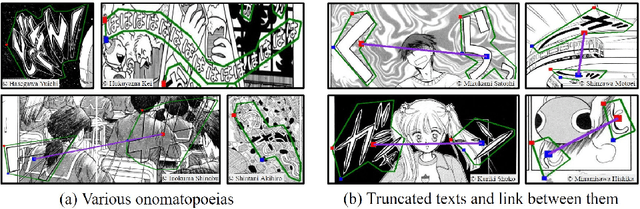
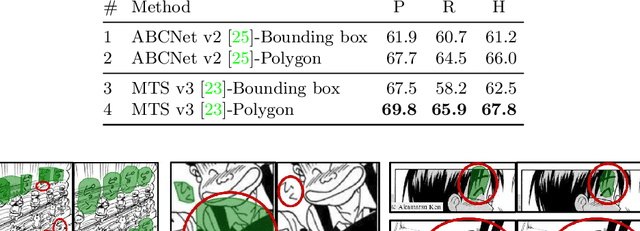
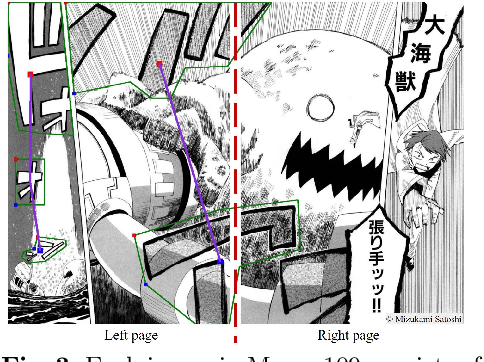
Recognizing irregular texts has been a challenging topic in text recognition. To encourage research on this topic, we provide a novel comic onomatopoeia dataset (COO), which consists of onomatopoeia texts in Japanese comics. COO has many arbitrary texts, such as extremely curved, partially shrunk texts, or arbitrarily placed texts. Furthermore, some texts are separated into several parts. Each part is a truncated text and is not meaningful by itself. These parts should be linked to represent the intended meaning. Thus, we propose a novel task that predicts the link between truncated texts. We conduct three tasks to detect the onomatopoeia region and capture its intended meaning: text detection, text recognition, and link prediction. Through extensive experiments, we analyze the characteristics of the COO. Our data and code are available at \url{https://github.com/ku21fan/COO-Comic-Onomatopoeia}.
SVG Vector Font Generation for Chinese Characters with Transformer
Jun 21, 2022
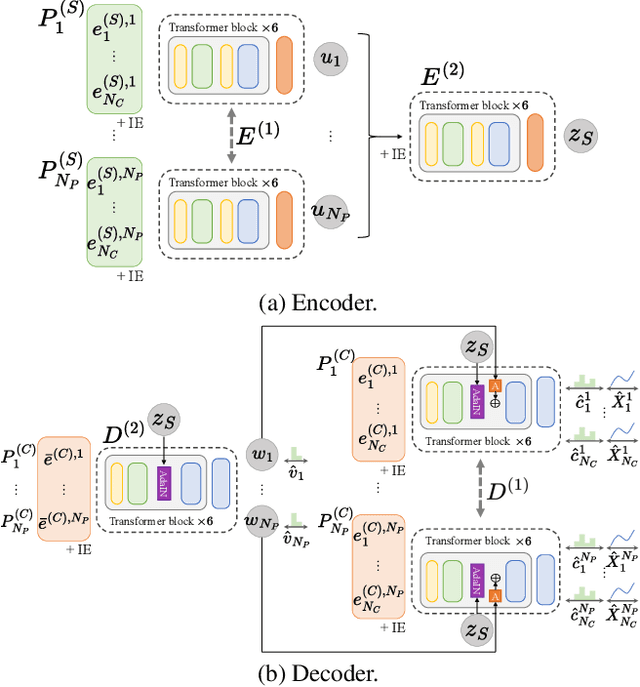
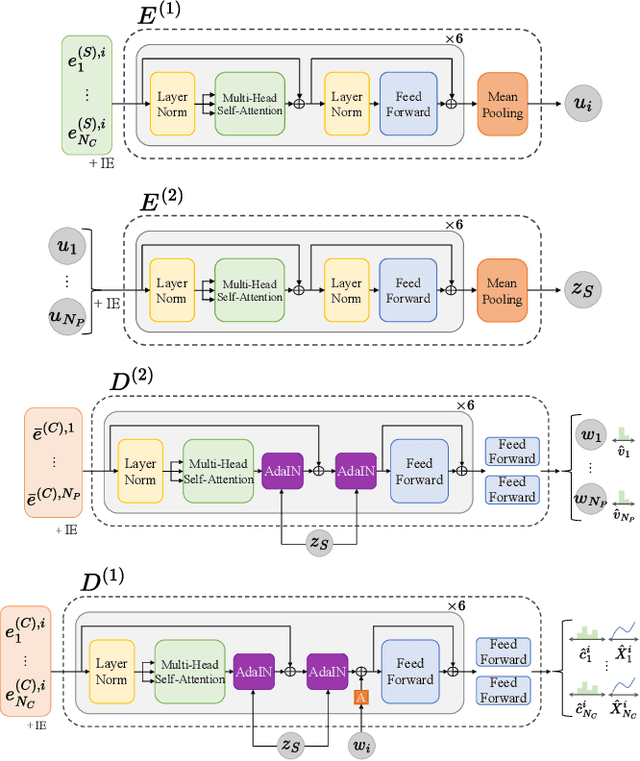
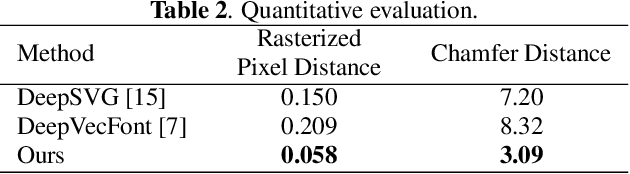
Designing fonts for Chinese characters is highly labor-intensive and time-consuming. While the latest methods successfully generate the English alphabet vector font, despite the high demand for automatic font generation, Chinese vector font generation has been an unsolved problem owing to its complex shape and numerous characters. This study addressed the problem of automatically generating Chinese vector fonts from only a single style and content reference. We proposed a novel network architecture with Transformer and loss functions to capture structural features without differentiable rendering. Although the dataset range was still limited to the sans-serif family, we successfully generated the Chinese vector font for the first time using the proposed method.
Intersection Prediction from Single 360° Image via Deep Detection of Possible Direction of Travel
Apr 10, 2022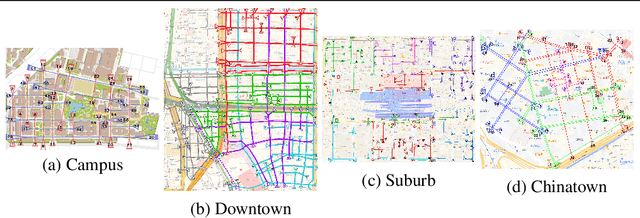
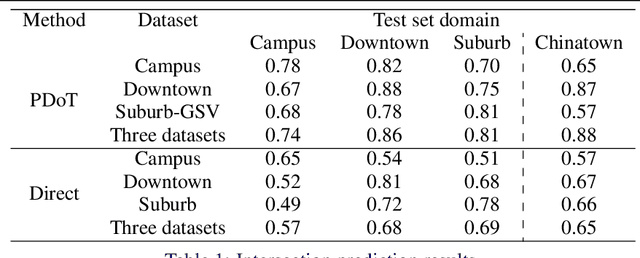


Movie-Map, an interactive first-person-view map that engages the user in a simulated walking experience, comprises short 360{\deg} video segments separated by traffic intersections that are seamlessly connected according to the viewer's direction of travel. However, in wide urban-scale areas with numerous intersecting roads, manual intersection segmentation requires significant human effort. Therefore, automatic identification of intersections from 360{\deg} videos is an important problem for scaling up Movie-Map. In this paper, we propose a novel method that identifies an intersection from individual frames in 360{\deg} videos. Instead of formulating the intersection identification as a standard binary classification task with a 360{\deg} image as input, we identify an intersection based on the number of the possible directions of travel (PDoT) in perspective images projected in eight directions from a single 360{\deg} image detected by the neural network for handling various types of intersections. We constructed a large-scale 360{\deg} Image Intersection Identification (iii360) dataset for training and evaluation where 360{\deg} videos were collected from various areas such as school campus, downtown, suburb, and china town and demonstrate that our PDoT-based method achieves 88\% accuracy, which is significantly better than that achieved by the direct naive binary classification based method. The source codes and a partial dataset will be shared in the community after the paper is published.
Distortion-Aware Self-Supervised 360° Depth Estimation from A Single Equirectangular Projection Image
Apr 03, 2022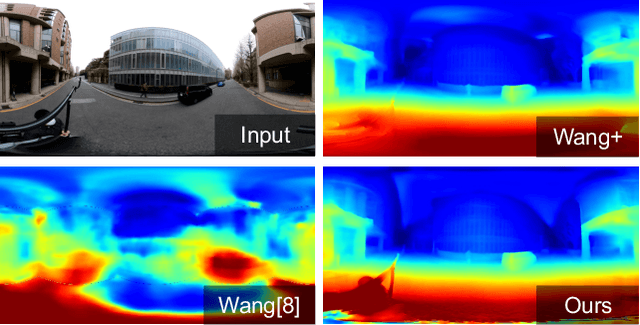

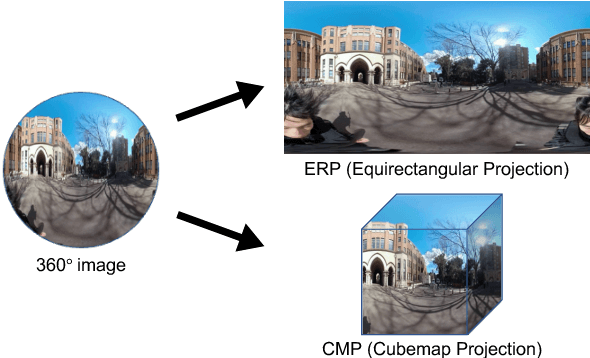
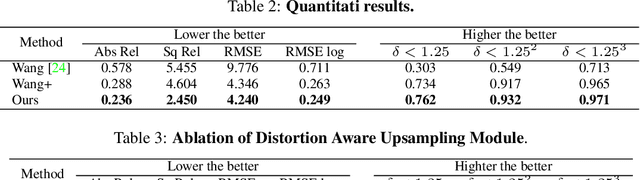
360{\deg} images are widely available over the last few years. This paper proposes a new technique for single 360{\deg} image depth prediction under open environments. Depth prediction from a 360{\deg} single image is not easy for two reasons. One is the limitation of supervision datasets - the currently available dataset is limited to indoor scenes. The other is the problems caused by Equirectangular Projection Format (ERP), commonly used for 360{\deg} images, that are coordinate and distortion. There is only one method existing that uses cube map projection to produce six perspective images and apply self-supervised learning using motion pictures for perspective depth prediction to deal with these problems. Different from the existing method, we directly use the ERP format. We propose a framework of direct use of ERP with coordinate conversion of correspondences and distortion-aware upsampling module to deal with the ERP related problems and extend a self-supervised learning method for open environments. For the experiments, we firstly built a dataset for the evaluation, and quantitatively evaluate the depth prediction in outdoor scenes. We show that it outperforms the state-of-the-art technique
Field-of-View IoU for Object Detection in 360° Images
Feb 07, 2022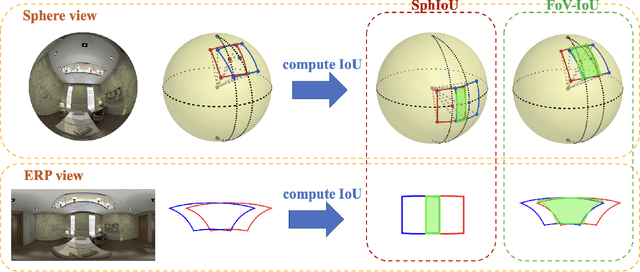
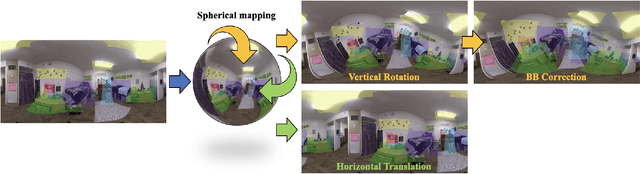
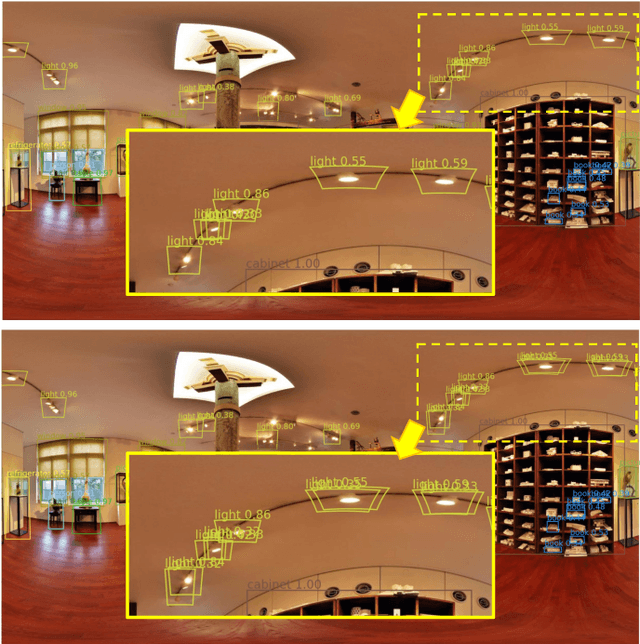

360{\deg} cameras have gained popularity over the last few years. In this paper, we propose two fundamental techniques -- Field-of-View IoU (FoV-IoU) and 360Augmentation for object detection in 360{\deg} images. Although most object detection neural networks designed for the perspective images are applicable to 360{\deg} images in equirectangular projection (ERP) format, their performance deteriorates owing to the distortion in ERP images. Our method can be readily integrated with existing perspective object detectors and significantly improves the performance. The FoV-IoU computes the intersection-over-union of two Field-of-View bounding boxes in a spherical image which could be used for training, inference, and evaluation while 360Augmentation is a data augmentation technique specific to 360{\deg} object detection task which randomly rotates a spherical image and solves the bias due to the sphere-to-plane projection. We conduct extensive experiments on the 360indoor dataset with different types of perspective object detectors and show the consistent effectiveness of our method.
Noisy Annotation Refinement for Object Detection
Oct 20, 2021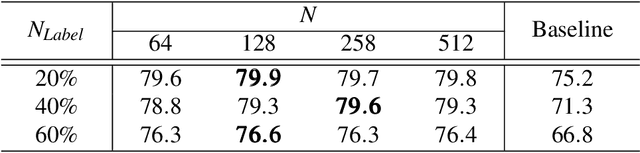
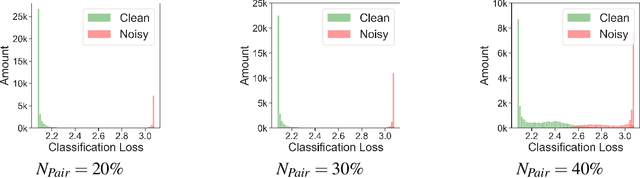
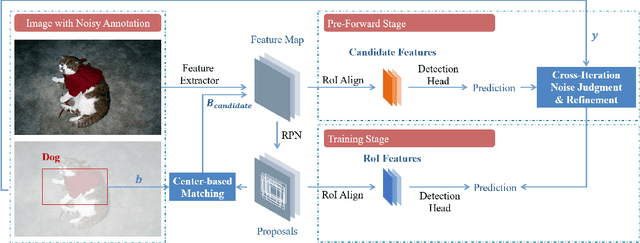

Supervised training of object detectors requires well-annotated large-scale datasets, whose production is costly. Therefore, some efforts have been made to obtain annotations in economical ways, such as cloud sourcing. However, datasets obtained by these methods tend to contain noisy annotations such as inaccurate bounding boxes and incorrect class labels. In this study, we propose a new problem setting of training object detectors on datasets with entangled noises of annotations of class labels and bounding boxes. Our proposed method efficiently decouples the entangled noises, corrects the noisy annotations, and subsequently trains the detector using the corrected annotations. We verified the effectiveness of our proposed method and compared it with the baseline on noisy datasets with different noise levels. The experimental results show that our proposed method significantly outperforms the baseline.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021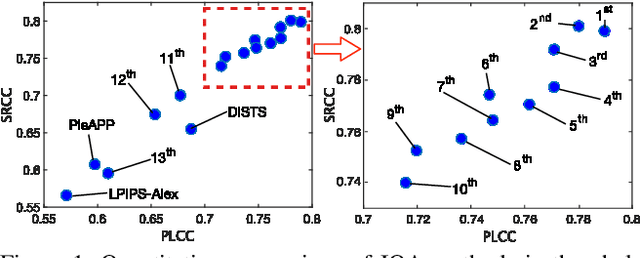
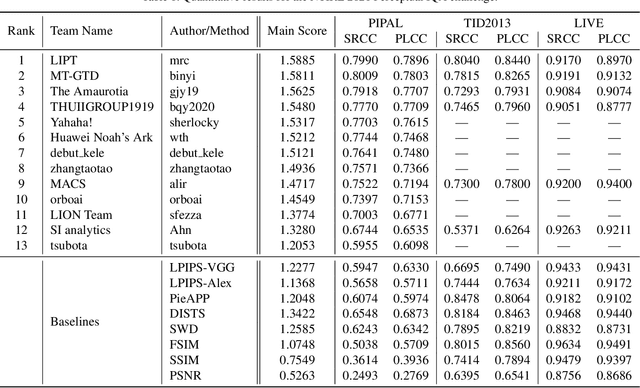

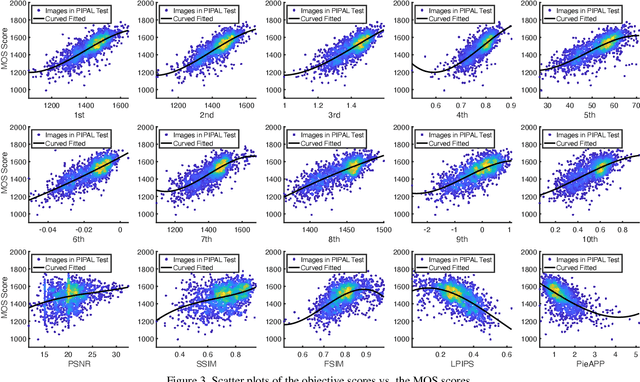
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.