 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-Aware Rubric Learning for Personalized Evaluation
May 29, 2026As Large Language Models (LLMs) evolve from general-purpose assistants to user-centric agents, personalization has become central to aligning model behavior with individual preferences, making the evaluation of personalized alignment a critical bottleneck. Existing evaluation methods-ranging from automatic metrics to LLM-as-a-judge approaches-fail to capture subjective, user-specific preferences embedded in long-term interaction histories. We identify three essential principles for reliable and effective personalized evaluation: Representativeness, User-Consistency, and Discriminativeness. To address these principles, we introduce Personalized Evaluation as Learning, a paradigm that formulates personalized evaluation as a learning problem rather than a static judgment. Under this paradigm, we propose PARL (Preference-Aware Rubric Learning for Personalized Evaluation), a framework that learns to induce preference-aware evaluation rubrics directly from raw user histories and performs a self-validation mechanism to ensure consistency with the user's preferences. PARL integrates rubric induction with a discriminative reinforcement learning objective that contrasts user-authored responses against competitive personalized model outputs, enabling the learned rubrics to capture precise, user-specific decision boundaries. Experiments on real-world personalized text generation tasks show that PARL consistently induces high-fidelity rubrics that reliably identify user-aligned responses and generalize across users and tasks, while capturing stable stylistic preferences and fine-grained evaluative patterns. To ensure reproducibility, our code is available at https://github.com/SnowCharmQ/PARL.
FoodLogAthl-218: Constructing a Real-World Food Image Dataset Using Dietary Management Applications
Dec 16, 2025Food image classification models are crucial for dietary management applications because they reduce the burden of manual meal logging. However, most publicly available datasets for training such models rely on web-crawled images, which often differ from users' real-world meal photos. In this work, we present FoodLogAthl-218, a food image dataset constructed from real-world meal records collected through the dietary management application FoodLog Athl. The dataset contains 6,925 images across 218 food categories, with a total of 14,349 bounding boxes. Rich metadata, including meal date and time, anonymized user IDs, and meal-level context, accompany each image. Unlike conventional datasets-where a predefined class set guides web-based image collection-our data begins with user-submitted photos, and labels are applied afterward. This yields greater intra-class diversity, a natural frequency distribution of meal types, and casual, unfiltered images intended for personal use rather than public sharing. In addition to (1) a standard classification benchmark, we introduce two FoodLog-specific tasks: (2) an incremental fine-tuning protocol that follows the temporal stream of users' logs, and (3) a context-aware classification task where each image contains multiple dishes, and the model must classify each dish by leveraging the overall meal context. We evaluate these tasks using large multimodal models (LMMs). The dataset is publicly available at https://huggingface.co/datasets/FoodLog/FoodLogAthl-218.
A Highly Clean Recipe Dataset with Ingredient States Annotation for State Probing Task
Jul 23, 2025Large Language Models (LLMs) are trained on a vast amount of procedural texts, but they do not directly observe real-world phenomena. In the context of cooking recipes, this poses a challenge, as intermediate states of ingredients are often omitted, making it difficult for models to track ingredient states and understand recipes accurately. In this paper, we apply state probing, a method for evaluating a language model's understanding of the world, to the domain of cooking. We propose a new task and dataset for evaluating how well LLMs can recognize intermediate ingredient states during cooking procedures. We first construct a new Japanese recipe dataset with clear and accurate annotations of ingredient state changes, collected from well-structured and controlled recipe texts. Using this dataset, we design three novel tasks to evaluate whether LLMs can track ingredient state transitions and identify ingredients present at intermediate steps. Our experiments with widely used LLMs, such as Llama3.1-70B and Qwen2.5-72B, show that learning ingredient state knowledge improves their understanding of cooking processes, achieving performance comparable to commercial LLMs.
FoodMLLM-JP: Leveraging Multimodal Large Language Models for Japanese Recipe Generation
Sep 27, 2024



Research on food image understanding using recipe data has been a long-standing focus due to the diversity and complexity of the data. Moreover, food is inextricably linked to people's lives, making it a vital research area for practical applications such as dietary management. Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities, not only in their vast knowledge but also in their ability to handle languages naturally. While English is predominantly used, they can also support multiple languages including Japanese. This suggests that MLLMs are expected to significantly improve performance in food image understanding tasks. We fine-tuned open MLLMs LLaVA-1.5 and Phi-3 Vision on a Japanese recipe dataset and benchmarked their performance against the closed model GPT-4o. We then evaluated the content of generated recipes, including ingredients and cooking procedures, using 5,000 evaluation samples that comprehensively cover Japanese food culture. Our evaluation demonstrates that the open models trained on recipe data outperform GPT-4o, the current state-of-the-art model, in ingredient generation. Our model achieved F1 score of 0.531, surpassing GPT-4o's F1 score of 0.481, indicating a higher level of accuracy. Furthermore, our model exhibited comparable performance to GPT-4o in generating cooking procedure text.
An experimental framework for designing document structure for users' decision making -- An empirical study of recipes
May 02, 2023



Textual documents need to be of good quality to ensure effective asynchronous communication in remote areas, especially during the COVID-19 pandemic. However, defining a preferred document structure (content and arrangement) for improving lay readers' decision-making is challenging. First, the types of useful content for various readers cannot be determined simply by gathering expert knowledge. Second, methodologies to evaluate the document's usefulness from the user's perspective have not been established. This study proposed the experimental framework to identify useful contents of documents by aggregating lay readers' insights. This study used 200 online recipes as research subjects and recruited 1,340 amateur cooks as lay readers. The proposed framework identified six useful contents of recipes. Multi-level modeling then showed that among the six identified contents, suitable ingredients or notes arranged with a subheading at the end of each cooking step significantly increased recipes' usefulness. Our framework contributes to the communication design via documents.
Noisy Annotation Refinement for Object Detection
Oct 20, 2021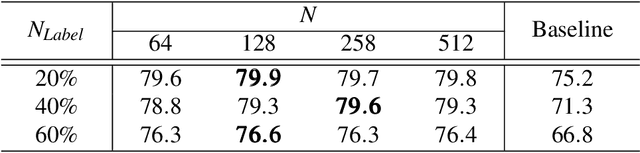
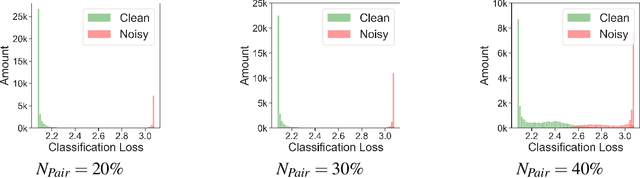
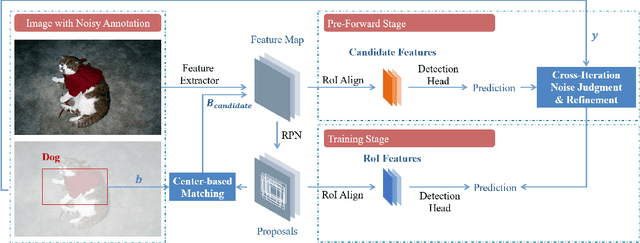

Supervised training of object detectors requires well-annotated large-scale datasets, whose production is costly. Therefore, some efforts have been made to obtain annotations in economical ways, such as cloud sourcing. However, datasets obtained by these methods tend to contain noisy annotations such as inaccurate bounding boxes and incorrect class labels. In this study, we propose a new problem setting of training object detectors on datasets with entangled noises of annotations of class labels and bounding boxes. Our proposed method efficiently decouples the entangled noises, corrects the noisy annotations, and subsequently trains the detector using the corrected annotations. We verified the effectiveness of our proposed method and compared it with the baseline on noisy datasets with different noise levels. The experimental results show that our proposed method significantly outperforms the baseline.
Recognition of Multiple Food Items in a Single Photo for Use in a Buffet-Style Restaurant
Mar 03, 2019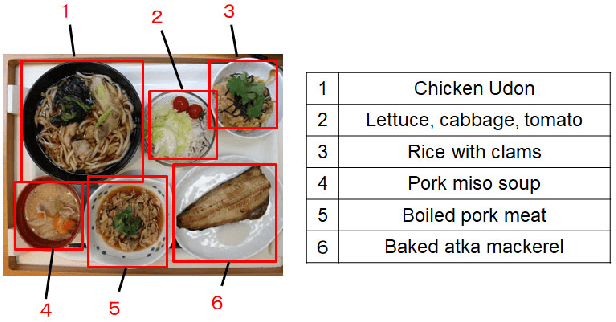
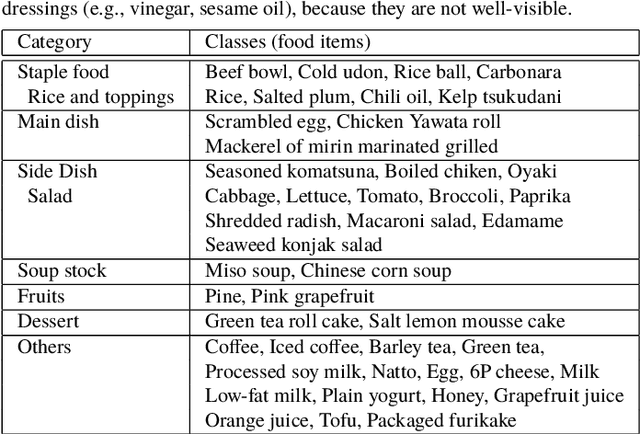
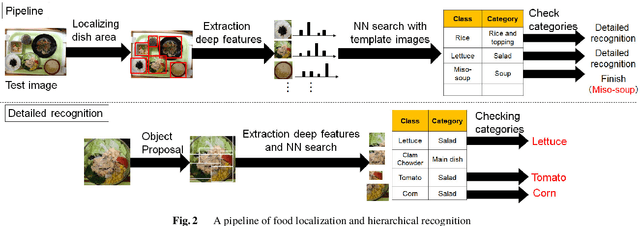
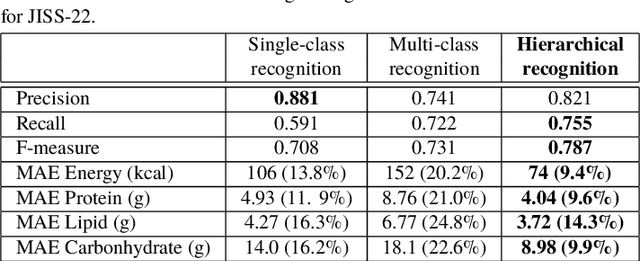
We investigate image recognition of multiple food items in a single photo, focusing on a buffet restaurant application, where menu changes at every meal, and only a few images per class are available. After detecting food areas, we perform hierarchical recognition. We evaluate our results, comparing to two baseline methods.
* 5 pages, 7 figures