 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Differentiable Resampling
Apr 24, 2020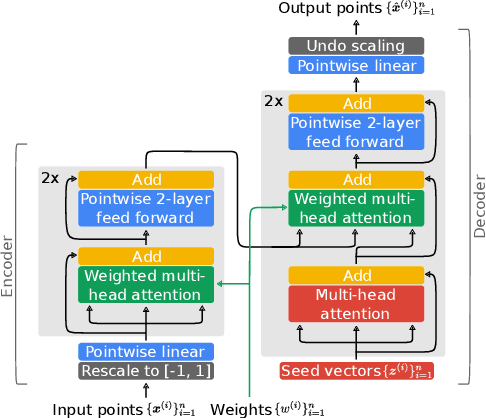
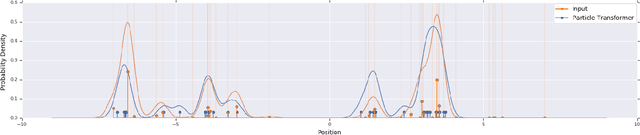
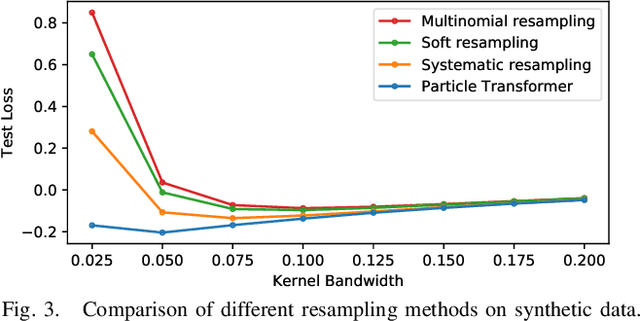
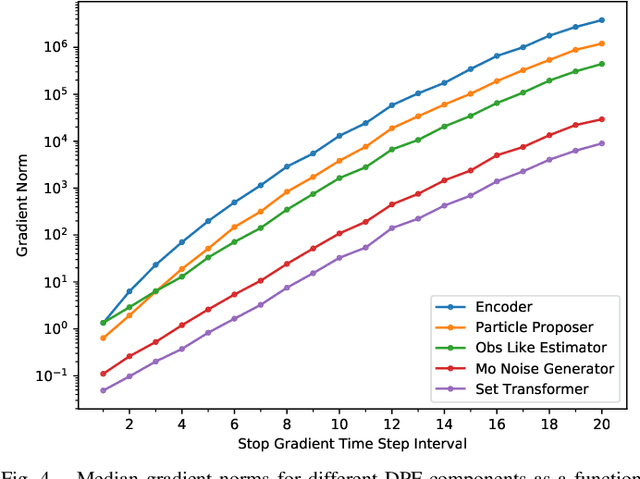
Resampling is a key component of sample-based recursive state estimation in particle filters. Recent work explores differentiable particle filters for end-to-end learning. However, resampling remains a challenge in these works, as it is inherently non-differentiable. We address this challenge by replacing traditional resampling with a learned neural network resampler. We present a novel network architecture, the particle transformer, and train it for particle resampling using a likelihood-based loss function over sets of particles. Incorporated into a differentiable particle filter, our model can be end-to-end optimized jointly with the other particle filter components via gradient descent. Our results show that our learned resampler outperforms traditional resampling techniques on synthetic data and in a simulated robot localization task.
Regularized Autoencoders via Relaxed Injective Probability Flow
Feb 20, 2020
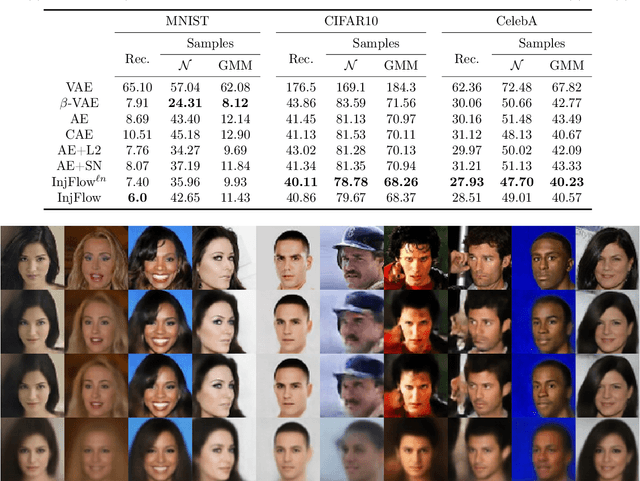


Invertible flow-based generative models are an effective method for learning to generate samples, while allowing for tractable likelihood computation and inference. However, the invertibility requirement restricts models to have the same latent dimensionality as the inputs. This imposes significant architectural, memory, and computational costs, making them more challenging to scale than other classes of generative models such as Variational Autoencoders (VAEs). We propose a generative model based on probability flows that does away with the bijectivity requirement on the model and only assumes injectivity. This also provides another perspective on regularized autoencoders (RAEs), with our final objectives resembling RAEs with specific regularizers that are derived by lower bounding the probability flow objective. We empirically demonstrate the promise of the proposed model, improving over VAEs and AEs in terms of sample quality.
The Garden of Forking Paths: Towards Multi-Future Trajectory Prediction
Dec 17, 2019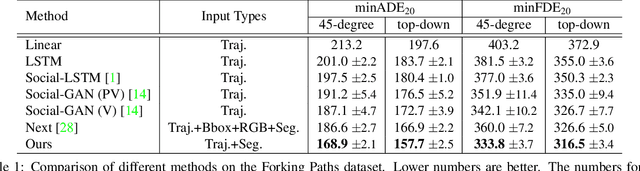
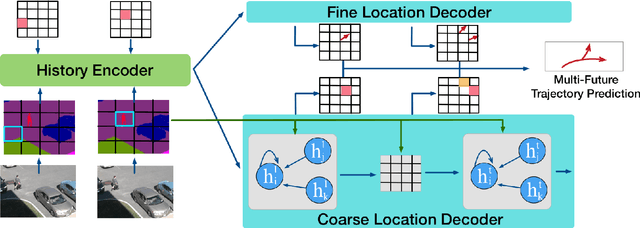
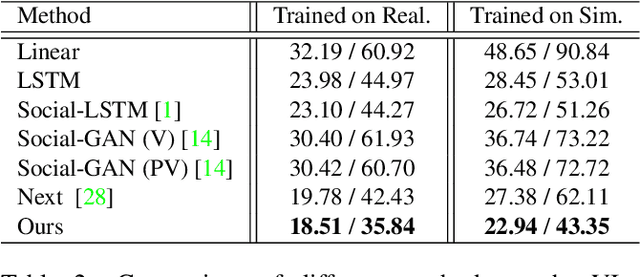

This paper studies the problem of predicting the distribution over multiple possible future paths of people as they move through various visual scenes. We make two main contributions. The first contribution is a new dataset, created in a realistic 3D simulator, which is based on real world trajectory data, and then extrapolated by human annotators to achieve different latent goals. This provides the first benchmark for quantitative evaluation of the models to predict multi-future trajectories. The second contribution is a new model to generate multiple plausible future trajectories, which contains novel designs of using multi-scale location encodings and convolutional RNNs over graphs. We refer to our model as Multiverse. We show that our model achieves the best results on our dataset, as well as on the real-world VIRAT/ActEV dataset (which just contains one possible future). We will release our data, models and code.
Unsupervised Learning of Object Structure and Dynamics from Videos
Jun 19, 2019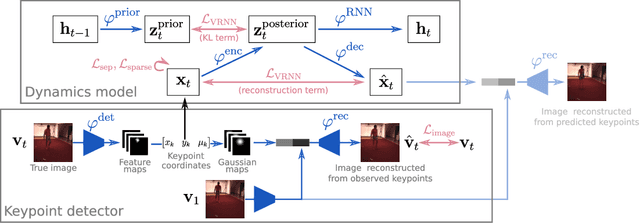
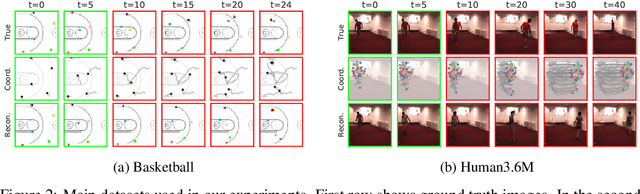
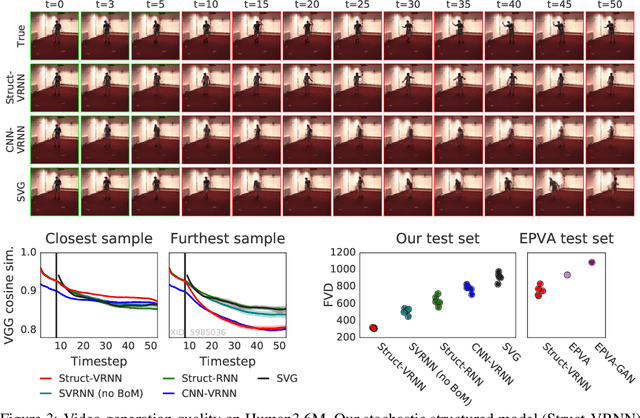
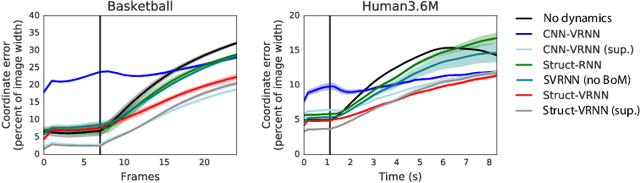
Extracting and predicting object structure and dynamics from videos without supervision is a major challenge in machine learning. To address this challenge, we adopt a keypoint-based image representation and learn a stochastic dynamics model of the keypoints. Future frames are reconstructed from the keypoints and a reference frame. By modeling dynamics in the keypoint coordinate space, we achieve stable learning and avoid compounding of errors in pixel space. Our method improves upon unstructured representations both for pixel-level video prediction and for downstream tasks requiring object-level understanding of motion dynamics. We evaluate our model on diverse datasets: a multi-agent sports dataset, the Human3.6M dataset, and datasets based on continuous control tasks from the DeepMind Control Suite. The spatially structured representation outperforms unstructured representations on a range of motion-related tasks such as object tracking, action recognition and reward prediction.
Language as an Abstraction for Hierarchical Deep Reinforcement Learning
Jun 18, 2019
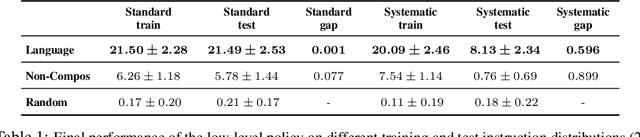
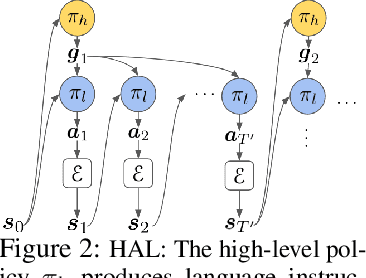
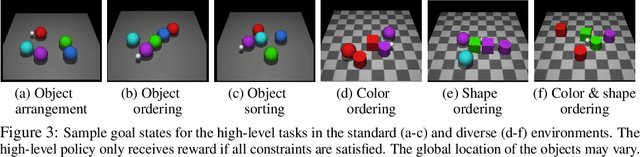
Solving complex, temporally-extended tasks is a long-standing problem in reinforcement learning (RL). We hypothesize that one critical element of solving such problems is the notion of compositionality. With the ability to learn concepts and sub-skills that can be composed to solve longer tasks, i.e. hierarchical RL, we can acquire temporally-extended behaviors. However, acquiring effective yet general abstractions for hierarchical RL is remarkably challenging. In this paper, we propose to use language as the abstraction, as it provides unique compositional structure, enabling fast learning and combinatorial generalization, while retaining tremendous flexibility, making it suitable for a variety of problems. Our approach learns an instruction-following low-level policy and a high-level policy that can reuse abstractions across tasks, in essence, permitting agents to reason using structured language. To study compositional task learning, we introduce an open-source object interaction environment built using the MuJoCo physics engine and the CLEVR engine. We find that, using our approach, agents can learn to solve to diverse, temporally-extended tasks such as object sorting and multi-object rearrangement, including from raw pixel observations. Our analysis find that the compositional nature of language is critical for learning diverse sub-skills and systematically generalizing to new sub-skills in comparison to non-compositional abstractions that use the same supervision.
Floors are Flat: Leveraging Semantics for Real-Time Surface Normal Prediction
Jun 16, 2019
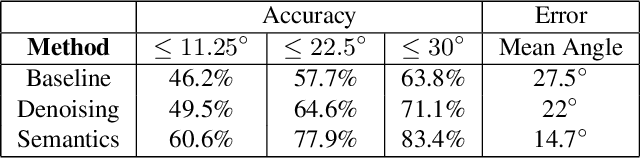

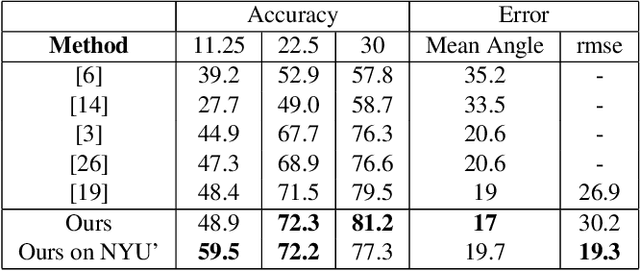
We propose 4 insights that help to significantly improve the performance of deep learning models that predict surface normals and semantic labels from a single RGB image. These insights are: (1) denoise the "ground truth" surface normals in the training set to ensure consistency with the semantic labels; (2) concurrently train on a mix of real and synthetic data, instead of pretraining on synthetic and finetuning on real; (3) jointly predict normals and semantics using a shared model, but only backpropagate errors on pixels that have valid training labels; (4) slim down the model and use grayscale instead of color inputs. Despite the simplicity of these steps, we demonstrate consistently improved results on several datasets, using a model that runs at 12 fps on a standard mobile phone.
Contrastive Bidirectional Transformer for Temporal Representation Learning
Jun 13, 2019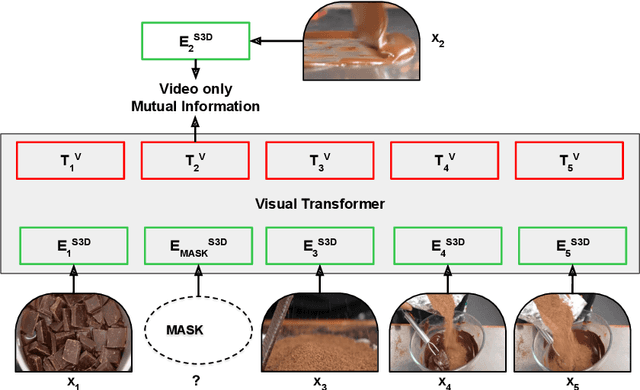

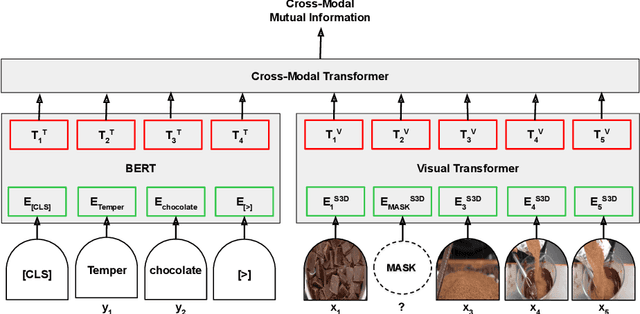
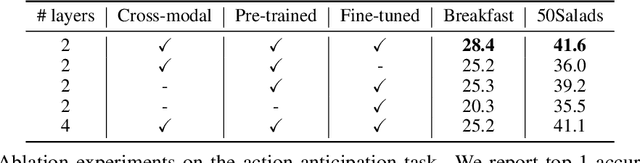
This paper aims at learning representations for long sequences of continuous signals. Recently, the BERT model has demonstrated the effectiveness of stacked transformers for representing sequences of discrete signals (i.e. word tokens). Inspired by its success, we adopt the stacked transformer architecture, but generalize its training objective to maximize the mutual information between the masked signals, and the bidirectional context, via contrastive loss. This enables the model to handle continuous signals, such as visual features. We further consider the case when there are multiple sequences that are semantically aligned at the sequence-level but not at the element-level (e.g. video and ASR), where we propose to use a Transformer to estimate the mutual information between the two sequences, which is again maximized via contrastive loss. We demonstrate the effectiveness of the learned representations on modeling long video sequences for action anticipation and video captioning. The results show that our method, referred to by Contrastive Bidirectional Transformer ({\bf CBT}), outperforms various baselines significantly. Furthermore, we improve over the state of the art.
A view of Estimation of Distribution Algorithms through the lens of Expectation-Maximization
Jun 05, 2019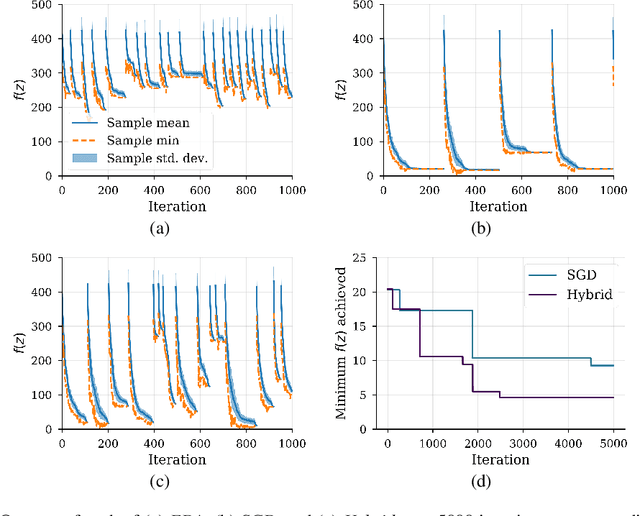
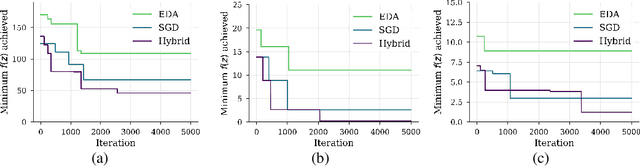
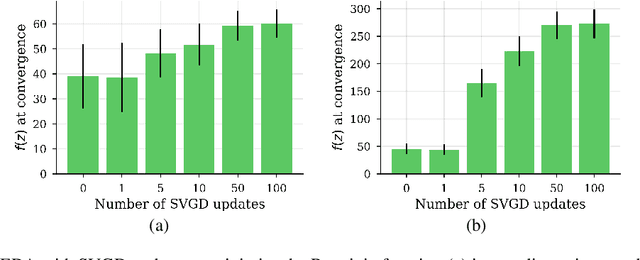
We show that under mild conditions, Estimation of Distribution Algorithms (EDAs) can be written as variational Expectation-Maximization (EM) that uses a mixture of weighted particles as the approximate posterior. In the infinite particle limit, EDAs can be viewed as exact EM. Because EM sits on a rigorous statistical foundation and has been thoroughly analyzed, this connection provides a coherent framework with which to reason about EDAs. Importantly, the connection also suggests avenues for possible improvements to EDAs owing to our ability to leverage general statistical tools and generalizations of EM. For example, we make use of results about known EM convergence properties to propose an adaptive, hybrid EDA-gradient descent algorithm; this hybrid demonstrates better performance than either component of the hybrid on several canonical, non-convex test functions. We also demonstrate empirically that although one might hypothesize that reducing the variational gap could prove useful, it actually degrades performance of EDAs. Finally, we show that the connection between EM and EDAs provides us with a new perspective on why EDAs are performing approximate natural gradient descent.
Relational Action Forecasting
Apr 08, 2019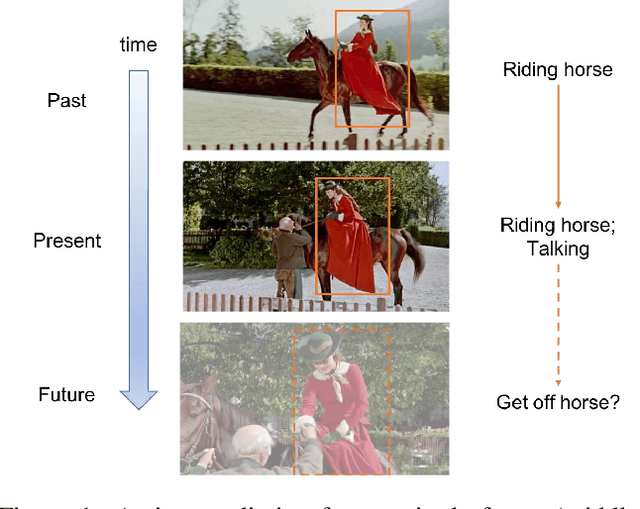


This paper focuses on multi-person action forecasting in videos. More precisely, given a history of H previous frames, the goal is to detect actors and to predict their future actions for the next T frames. Our approach jointly models temporal and spatial interactions among different actors by constructing a recurrent graph, using actor proposals obtained with Faster R-CNN as nodes. Our method learns to select a subset of discriminative relations without requiring explicit supervision, thus enabling us to tackle challenging visual data. We refer to our model as Discriminative Relational Recurrent Network (DRRN). Evaluation of action prediction on AVA demonstrates the effectiveness of our proposed method compared to simpler baselines. Furthermore, we significantly improve performance on the task of early action classification on J-HMDB, from the previous SOTA of 48% to 60%.
VideoBERT: A Joint Model for Video and Language Representation Learning
Apr 03, 2019
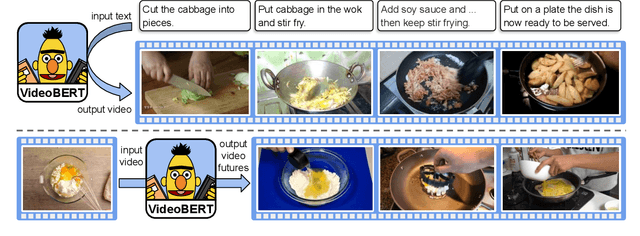

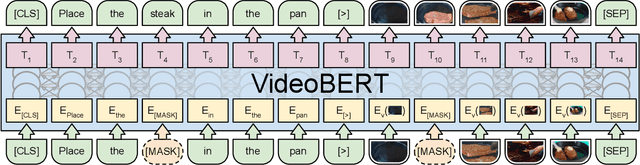
Self-supervised learning has become increasingly important to leverage the abundance of unlabeled data available on platforms like YouTube. Whereas most existing approaches learn low-level representations, we propose a joint visual-linguistic model to learn high-level features without any explicit supervision. In particular, inspired by its recent success in language modeling, we build upon the BERT model to learn bidirectional joint distributions over sequences of visual and linguistic tokens, derived from vector quantization of video data and off-the-shelf speech recognition outputs, respectively. We use this model in a number of tasks, including action classification and video captioning. We show that it can be applied directly to open-vocabulary classification, and confirm that large amounts of training data and cross-modal information are critical to performance. Furthermore, we outperform the state-of-the-art on video captioning, and quantitative results verify that the model learns high-level semantic features.