 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-linear Embeddings in Hilbert Simplex Geometry
Mar 22, 2022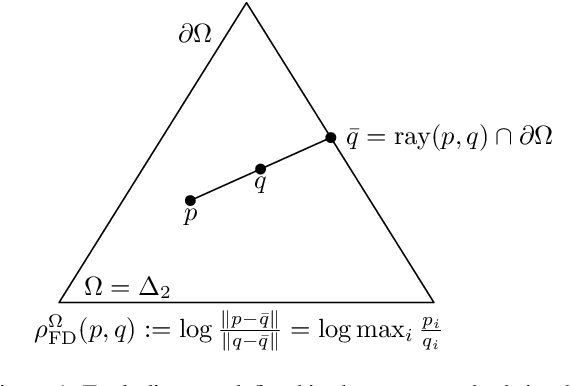
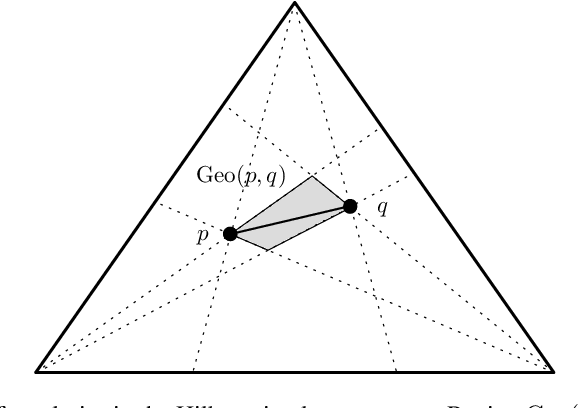
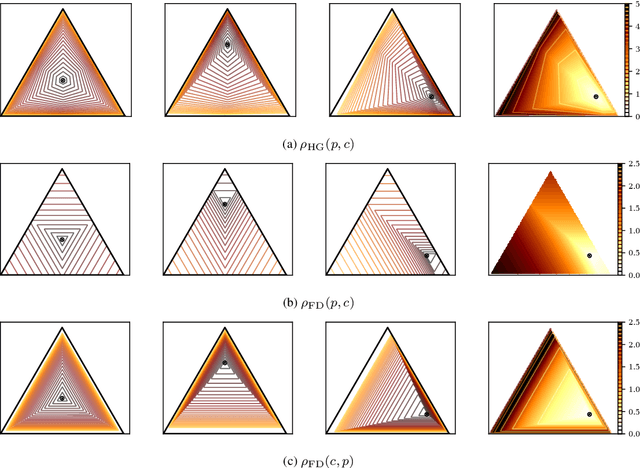
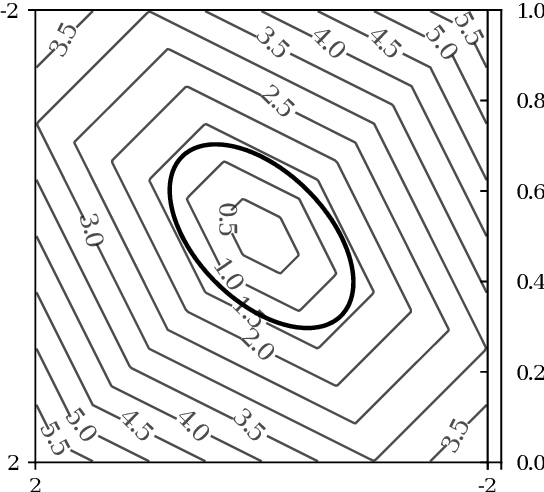
A key technique of machine learning and computer vision is to embed discrete weighted graphs into continuous spaces for further downstream processing. Embedding discrete hierarchical structures in hyperbolic geometry has proven very successful since it was shown that any weighted tree can be embedded in that geometry with arbitrary low distortion. Various optimization methods for hyperbolic embeddings based on common models of hyperbolic geometry have been studied. In this paper, we consider Hilbert geometry for the standard simplex which is isometric to a vector space equipped with the variation polytope norm. We study the representation power of this Hilbert simplex geometry by embedding distance matrices of graphs. Our findings demonstrate that Hilbert simplex geometry is competitive to alternative geometries such as the Poincar\'e hyperbolic ball or the Euclidean geometry for embedding tasks while being fast and numerically robust.
RTGNN: A Novel Approach to Model Stochastic Traffic Dynamics
Feb 21, 2022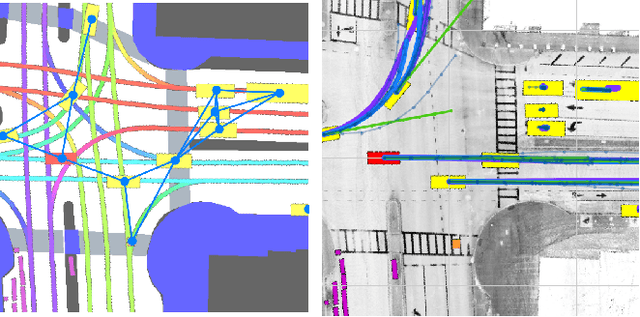
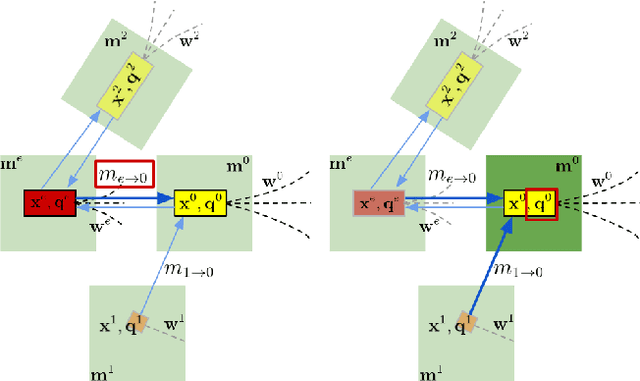
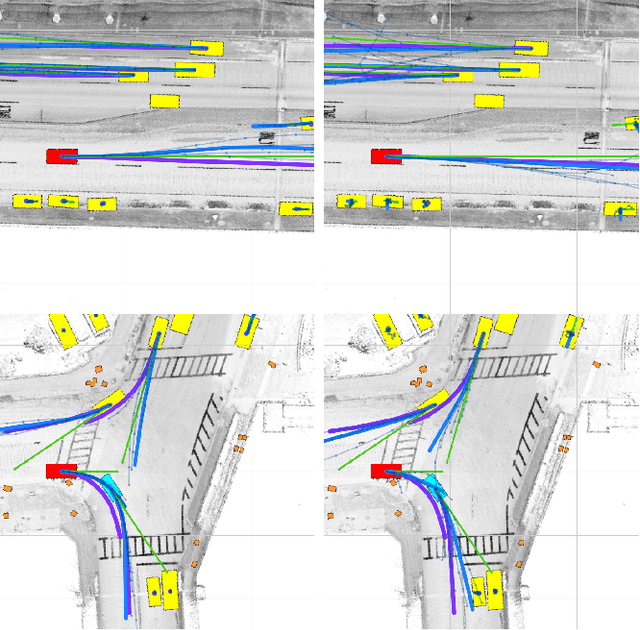
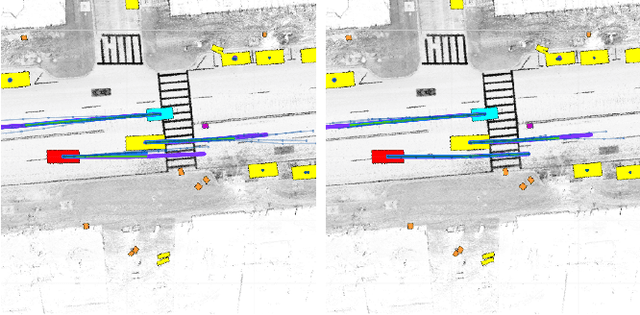
Modeling stochastic traffic dynamics is critical to developing self-driving cars. Because it is difficult to develop first principle models of cars driven by humans, there is great potential for using data driven approaches in developing traffic dynamical models. While there is extensive literature on this subject, previous works mainly address the prediction accuracy of data-driven models. Moreover, it is often difficult to apply these models to common planning frameworks since they fail to meet the assumptions therein. In this work, we propose a new stochastic traffic model, Recurrent Traffic Graph Neural Network (RTGNN), by enforcing additional structures on the model so that the proposed model can be seamlessly integrated with existing motion planning algorithms. RTGNN is a Markovian model and is able to infer future traffic states conditioned on the motion of the ego vehicle. Specifically, RTGNN uses a definition of the traffic state that includes the state of all players in a local region and is therefore able to make joint predictions for all agents of interest. Meanwhile, we explicitly model the hidden states of agents, "intentions," as part of the traffic state to reflect the inherent partial observability of traffic dynamics. The above mentioned properties are critical for integrating RTGNN with motion planning algorithms coupling prediction and decision making. Despite the additional structures, we show that RTGNN is able to achieve state-of-the-art accuracy through comparisons with other similar works.
Distributional Reinforcement Learning via Sinkhorn Iterations
Feb 16, 2022
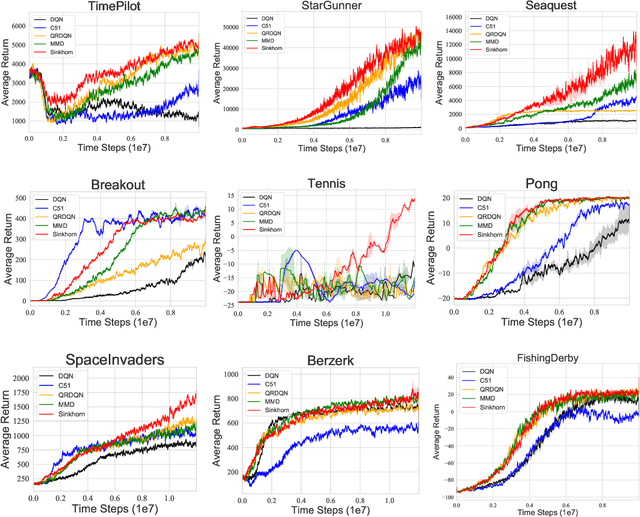
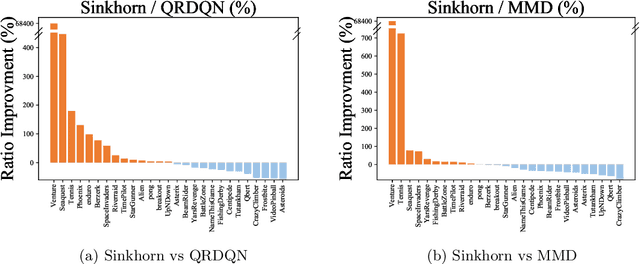
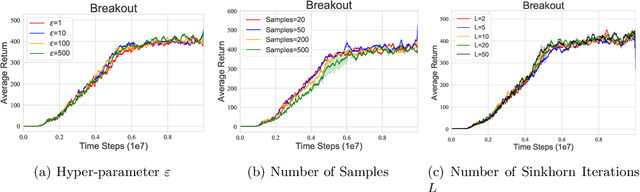
Distributional reinforcement learning~(RL) is a class of state-of-the-art algorithms that estimate the whole distribution of the total return rather than only its expectation. The representation manner of each return distribution and the choice of distribution divergence are pivotal for the empirical success of distributional RL. In this paper, we propose a new class of \textit{Sinkhorn distributional RL} algorithm that learns a finite set of statistics, i.e., deterministic samples, from each return distribution and then leverages Sinkhorn iterations to evaluate the Sinkhorn distance between the current and target Bellmen distributions. Remarkably, as Sinkhorn divergence interpolates between the Wasserstein distance and Maximum Mean Discrepancy~(MMD). This allows our proposed Sinkhorn distributional RL algorithms to find a sweet spot leveraging the geometry of optimal transport-based distance, and the unbiased gradient estimates of MMD. Finally, experiments on a suite of Atari games reveal the competitive performance of Sinkhorn distributional RL algorithm as opposed to existing state-of-the-art algorithms.
Fair Wrapping for Black-box Predictions
Feb 16, 2022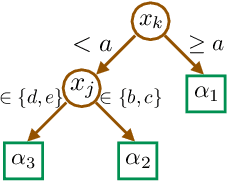
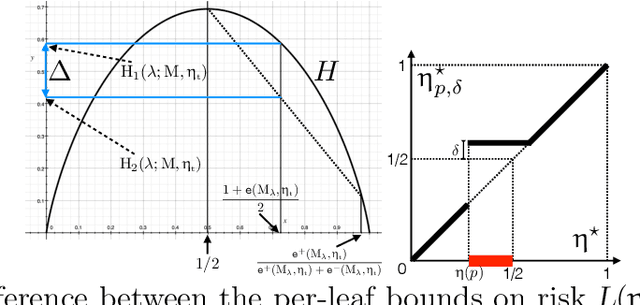
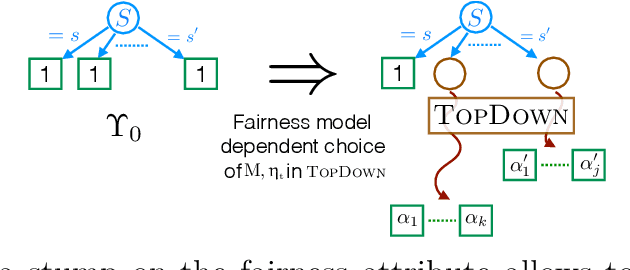
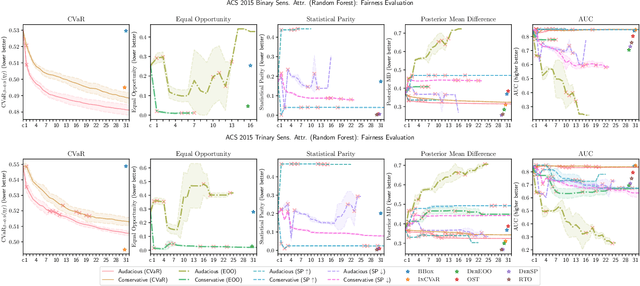
We introduce a new family of techniques to post-process ("wrap") a black-box classifier in order to reduce its bias. Our technique builds on the recent analysis of improper loss functions whose optimisation can correct any twist in prediction, unfairness being treated as a twist. In the post-processing, we learn a wrapper function which we define as an {\alpha}-tree, which modifies the prediction. We provide two generic boosting algorithms to learn {\alpha}-trees. We show that our modification has appealing properties in terms of composition of{\alpha}-trees, generalization, interpretability, and KL divergence between modified and original predictions. We exemplify the use of our technique in three fairness notions: conditional value at risk, equality of opportunity, and statistical parity; and provide experiments on several readily available datasets.
Contrastive Laplacian Eigenmaps
Jan 14, 2022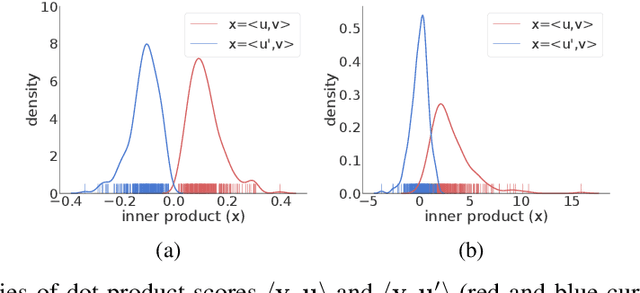
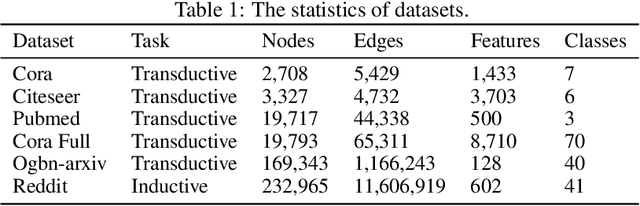
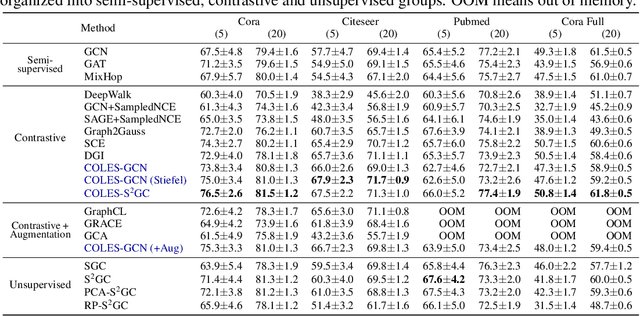
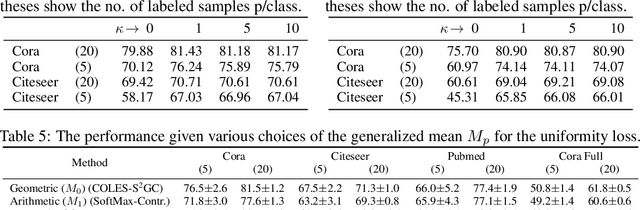
Graph contrastive learning attracts/disperses node representations for similar/dissimilar node pairs under some notion of similarity. It may be combined with a low-dimensional embedding of nodes to preserve intrinsic and structural properties of a graph. In this paper, we extend the celebrated Laplacian Eigenmaps with contrastive learning, and call them COntrastive Laplacian EigenmapS (COLES). Starting from a GAN-inspired contrastive formulation, we show that the Jensen-Shannon divergence underlying many contrastive graph embedding models fails under disjoint positive and negative distributions, which may naturally emerge during sampling in the contrastive setting. In contrast, we demonstrate analytically that COLES essentially minimizes a surrogate of Wasserstein distance, which is known to cope well under disjoint distributions. Moreover, we show that the loss of COLES belongs to the family of so-called block-contrastive losses, previously shown to be superior compared to pair-wise losses typically used by contrastive methods. We show on popular benchmarks/backbones that COLES offers favourable accuracy/scalability compared to DeepWalk, GCN, Graph2Gauss, DGI and GRACE baselines.
* Accepted by NeurIPS 2021. Includes the main paper and the supplementary material. OpenReview: https://openreview.net/forum?id=iLn-bhP-kKH
Dual Contrastive Learning for General Face Forgery Detection
Dec 27, 2021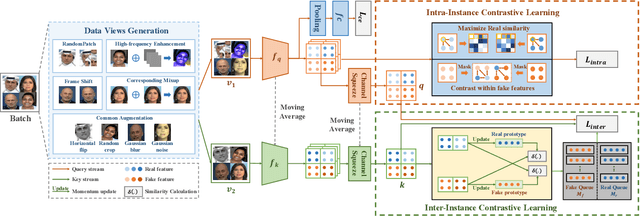
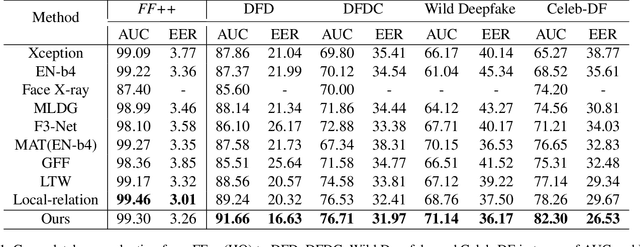
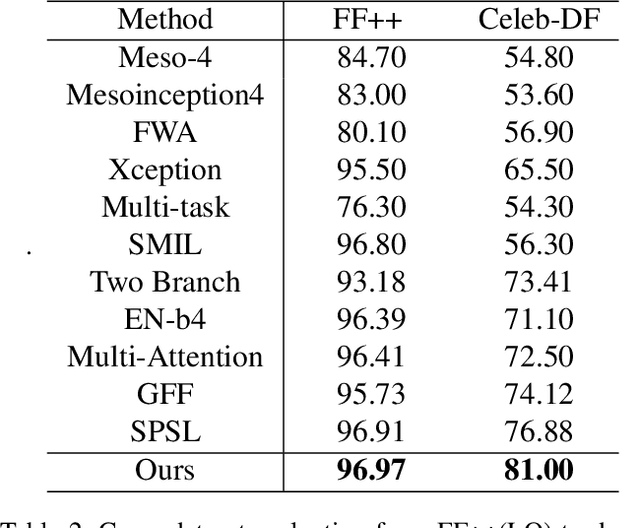
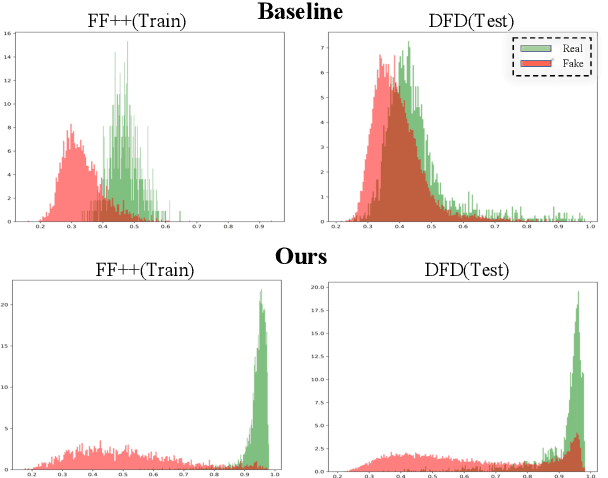
With various facial manipulation techniques arising, face forgery detection has drawn growing attention due to security concerns. Previous works always formulate face forgery detection as a classification problem based on cross-entropy loss, which emphasizes category-level differences rather than the essential discrepancies between real and fake faces, limiting model generalization in unseen domains. To address this issue, we propose a novel face forgery detection framework, named Dual Contrastive Learning (DCL), which specially constructs positive and negative paired data and performs designed contrastive learning at different granularities to learn generalized feature representation. Concretely, combined with the hard sample selection strategy, Inter-Instance Contrastive Learning (Inter-ICL) is first proposed to promote task-related discriminative features learning by especially constructing instance pairs. Moreover, to further explore the essential discrepancies, Intra-Instance Contrastive Learning (Intra-ICL) is introduced to focus on the local content inconsistencies prevalent in the forged faces by constructing local-region pairs inside instances. Extensive experiments and visualizations on several datasets demonstrate the generalization of our method against the state-of-the-art competitors.
Asymptotic Learning Requirements for Stealth Attacks
Dec 22, 2021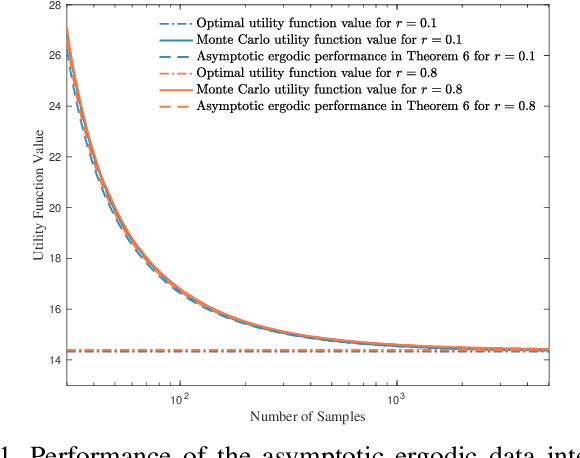
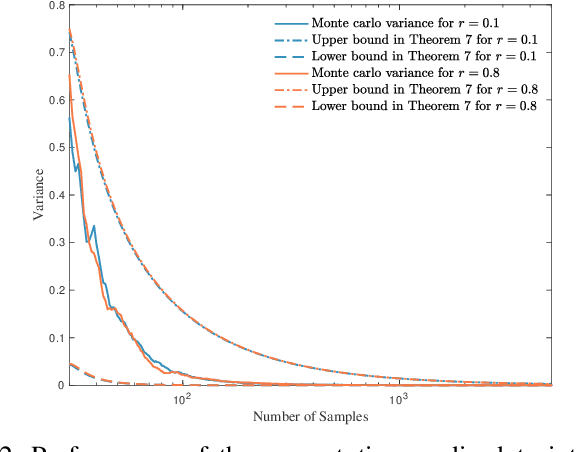
Information-theoretic stealth attacks are data injection attacks that minimize the amount of information acquired by the operator about the state variables, while simultaneously limiting the Kullback-Leibler divergence between the distribution of the measurements under attack and the distribution under normal operation with the aim of controling the probability of detection. For Gaussian distributed state variables, attack construction requires knowledge of the second order statistics of the state variables, which is estimated from a finite number of past realizations using a sample covariance matrix. Within this framework, the attack performance is studied for the attack construction with the sample covariance matrix. This results in an analysis of the amount of data required to learn the covariance matrix of the state variables used on the attack construction. The ergodic attack performance is characterized using asymptotic random matrix theory tools, and the variance of the attack performance is bounded. The ergodic performance and the variance bounds are assessed with simulations on IEEE test systems.
Pareto Adversarial Robustness: Balancing Spatial Robustness and Sensitivity-based Robustness
Nov 03, 2021
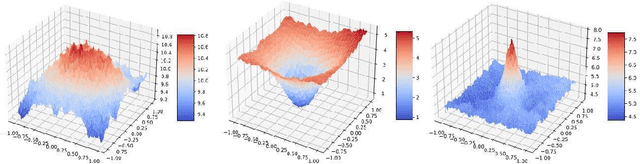
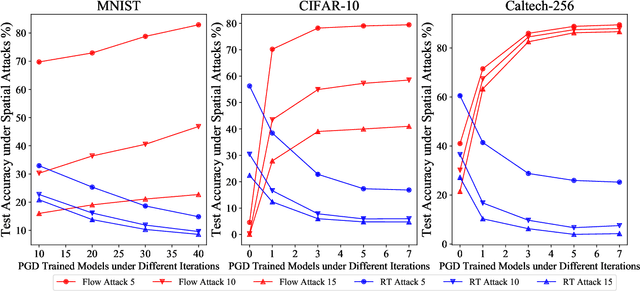
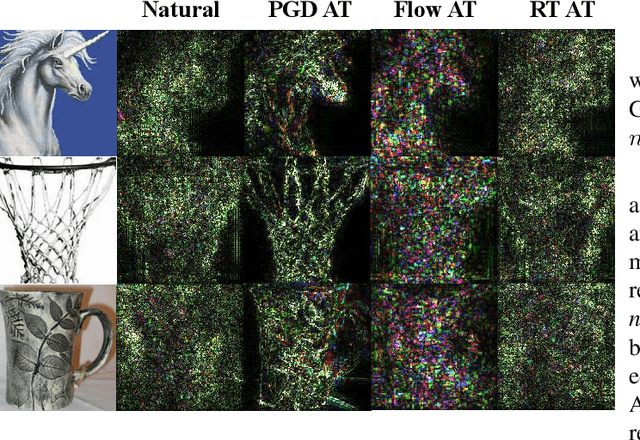
Adversarial robustness, which mainly contains sensitivity-based robustness and spatial robustness, plays an integral part in the robust generalization. In this paper, we endeavor to design strategies to achieve universal adversarial robustness. To hit this target, we firstly investigate the less-studied spatial robustness and then integrate existing spatial robustness methods by incorporating both local and global spatial vulnerability into one spatial attack and adversarial training. Based on this exploration, we further present a comprehensive relationship between natural accuracy, sensitivity-based and different spatial robustness, supported by the strong evidence from the perspective of robust representation. More importantly, in order to balance these mutual impacts of different robustness into one unified framework, we incorporate \textit{Pareto criterion} into the adversarial robustness analysis, yielding a novel strategy called \textit{Pareto Adversarial Training} towards universal robustness. The resulting Pareto front, the set of optimal solutions, provides the set of optimal balance among natural accuracy and different adversarial robustness, shedding light on solutions towards universal robustness in the future. To the best of our knowledge, we are the first to consider the universal adversarial robustness via multi-objective optimization.
Damped Anderson Mixing for Deep Reinforcement Learning: Acceleration, Convergence, and Stabilization
Oct 20, 2021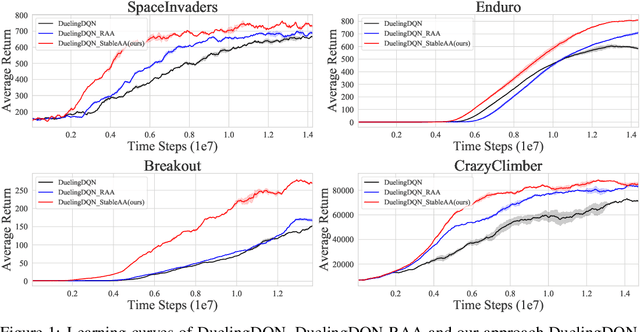
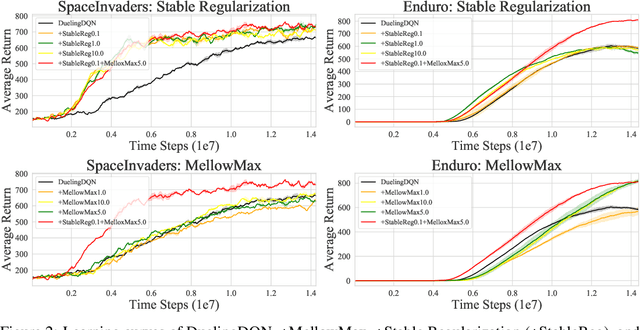
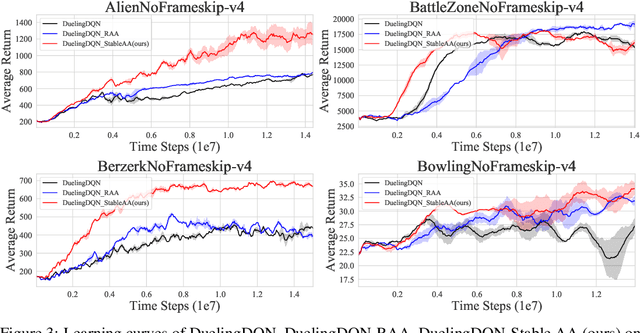
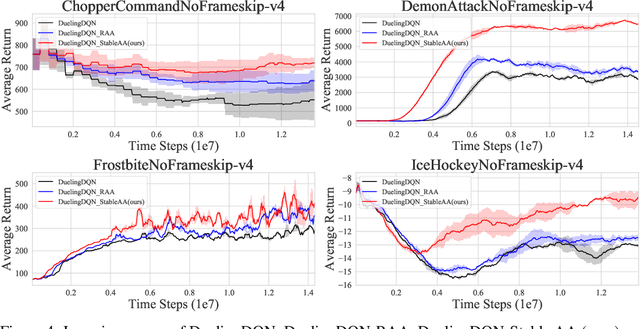
Anderson mixing has been heuristically applied to reinforcement learning (RL) algorithms for accelerating convergence and improving the sampling efficiency of deep RL. Despite its heuristic improvement of convergence, a rigorous mathematical justification for the benefits of Anderson mixing in RL has not yet been put forward. In this paper, we provide deeper insights into a class of acceleration schemes built on Anderson mixing that improve the convergence of deep RL algorithms. Our main results establish a connection between Anderson mixing and quasi-Newton methods and prove that Anderson mixing increases the convergence radius of policy iteration schemes by an extra contraction factor. The key focus of the analysis roots in the fixed-point iteration nature of RL. We further propose a stabilization strategy by introducing a stable regularization term in Anderson mixing and a differentiable, non-expansive MellowMax operator that can allow both faster convergence and more stable behavior. Extensive experiments demonstrate that our proposed method enhances the convergence, stability, and performance of RL algorithms.
High-order Tensor Pooling with Attention for Action Recognition
Oct 11, 2021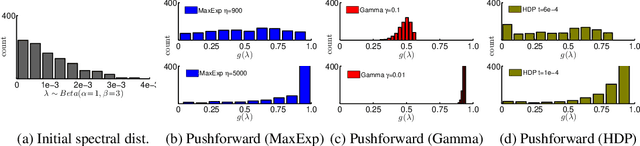


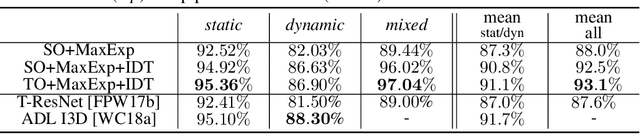
We aim at capturing high-order statistics of feature vectors formed by a neural network, and propose end-to-end second- and higher-order pooling to form a tensor descriptor. Tensor descriptors require a robust similarity measure due to low numbers of aggregated vectors and the burstiness phenomenon, when a given feature appears more/less frequently than statistically expected. We show that the Heat Diffusion Process (HDP) on a graph Laplacian is closely related to the Eigenvalue Power Normalization (EPN) of the covariance/auto-correlation matrix, whose inverse forms a loopy graph Laplacian. We show that the HDP and the EPN play the same role, i.e., to boost or dampen the magnitude of the eigenspectrum thus preventing the burstiness. Finally, we equip higher-order tensors with EPN which acts as a spectral detector of higher-order occurrences to prevent burstiness. We prove that for a tensor of order r built from d dimensional feature descriptors, such a detector gives the likelihood if at least one higher-order occurrence is `projected' into one of binom(d,r) subspaces represented by the tensor; thus forming a tensor power normalization metric endowed with binom(d,r) such `detectors'.