 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Sycophancy as Deviations from Bayesian Rationality in LLMs
Aug 23, 2025Sycophancy, or overly agreeable or flattering behavior, is a documented issue in large language models (LLMs), and is critical to understand in the context of human/AI collaboration. Prior works typically quantify sycophancy by measuring shifts in behavior or impacts on accuracy, but neither metric characterizes shifts in rationality, and accuracy measures can only be used in scenarios with a known ground truth. In this work, we utilize a Bayesian framework to quantify sycophancy as deviations from rational behavior when presented with user perspectives, thus distinguishing between rational and irrational updates based on the introduction of user perspectives. In comparison to other methods, this approach allows us to characterize excessive behavioral shifts, even for tasks that involve inherent uncertainty or do not have a ground truth. We study sycophancy for 3 different tasks, a combination of open-source and closed LLMs, and two different methods for probing sycophancy. We also experiment with multiple methods for eliciting probability judgments from LLMs. We hypothesize that probing LLMs for sycophancy will cause deviations in LLMs' predicted posteriors that will lead to increased Bayesian error. Our findings indicate that: 1) LLMs are not Bayesian rational, 2) probing for sycophancy results in significant increases to the predicted posterior in favor of the steered outcome, 3) sycophancy sometimes results in increased Bayesian error, and in a small number of cases actually decreases error, and 4) changes in Bayesian error due to sycophancy are not strongly correlated in Brier score, suggesting that studying the impact of sycophancy on ground truth alone does not fully capture errors in reasoning due to sycophancy.
Contextual ASR Error Handling with LLMs Augmentation for Goal-Oriented Conversational AI
Jan 10, 2025



General-purpose automatic speech recognition (ASR) systems do not always perform well in goal-oriented dialogue. Existing ASR correction methods rely on prior user data or named entities. We extend correction to tasks that have no prior user data and exhibit linguistic flexibility such as lexical and syntactic variations. We propose a novel context augmentation with a large language model and a ranking strategy that incorporates contextual information from the dialogue states of a goal-oriented conversational AI and its tasks. Our method ranks (1) n-best ASR hypotheses by their lexical and semantic similarity with context and (2) context by phonetic correspondence with ASR hypotheses. Evaluated in home improvement and cooking domains with real-world users, our method improves recall and F1 of correction by 34% and 16%, respectively, while maintaining precision and false positive rate. Users rated .8-1 point (out of 5) higher when our correction method worked properly, with no decrease due to false positives.
Generating Signed Language Instructions in Large-Scale Dialogue Systems
Oct 17, 2024



We introduce a goal-oriented conversational AI system enhanced with American Sign Language (ASL) instructions, presenting the first implementation of such a system on a worldwide multimodal conversational AI platform. Accessible through a touch-based interface, our system receives input from users and seamlessly generates ASL instructions by leveraging retrieval methods and cognitively based gloss translations. Central to our design is a sign translation module powered by Large Language Models, alongside a token-based video retrieval system for delivering instructional content from recipes and wikiHow guides. Our development process is deeply rooted in a commitment to community engagement, incorporating insights from the Deaf and Hard-of-Hearing community, as well as experts in cognitive and ASL learning sciences. The effectiveness of our signing instructions is validated by user feedback, achieving ratings on par with those of the system in its non-signing variant. Additionally, our system demonstrates exceptional performance in retrieval accuracy and text-generation quality, measured by metrics such as BERTScore. We have made our codebase and datasets publicly accessible at https://github.com/Merterm/signed-dialogue, and a demo of our signed instruction video retrieval system is available at https://huggingface.co/spaces/merterm/signed-instructions.
Studying and Mitigating Biases in Sign Language Understanding Models
Oct 07, 2024



Ensuring that the benefits of sign language technologies are distributed equitably among all community members is crucial. Thus, it is important to address potential biases and inequities that may arise from the design or use of these resources. Crowd-sourced sign language datasets, such as the ASL Citizen dataset, are great resources for improving accessibility and preserving linguistic diversity, but they must be used thoughtfully to avoid reinforcing existing biases. In this work, we utilize the rich information about participant demographics and lexical features present in the ASL Citizen dataset to study and document the biases that may result from models trained on crowd-sourced sign datasets. Further, we apply several bias mitigation techniques during model training, and find that these techniques reduce performance disparities without decreasing accuracy. With the publication of this work, we release the demographic information about the participants in the ASL Citizen dataset to encourage future bias mitigation work in this space.
Dialogue with Robots: Proposals for Broadening Participation and Research in the SLIVAR Community
Apr 01, 2024


The ability to interact with machines using natural human language is becoming not just commonplace, but expected. The next step is not just text interfaces, but speech interfaces and not just with computers, but with all machines including robots. In this paper, we chronicle the recent history of this growing field of spoken dialogue with robots and offer the community three proposals, the first focused on education, the second on benchmarks, and the third on the modeling of language when it comes to spoken interaction with robots. The three proposals should act as white papers for any researcher to take and build upon.
Multilingual Content Moderation: A Case Study on Reddit
Feb 19, 2023



Content moderation is the process of flagging content based on pre-defined platform rules. There has been a growing need for AI moderators to safeguard users as well as protect the mental health of human moderators from traumatic content. While prior works have focused on identifying hateful/offensive language, they are not adequate for meeting the challenges of content moderation since 1) moderation decisions are based on violation of rules, which subsumes detection of offensive speech, and 2) such rules often differ across communities which entails an adaptive solution. We propose to study the challenges of content moderation by introducing a multilingual dataset of 1.8 Million Reddit comments spanning 56 subreddits in English, German, Spanish and French. We perform extensive experimental analysis to highlight the underlying challenges and suggest related research problems such as cross-lingual transfer, learning under label noise (human biases), transfer of moderation models, and predicting the violated rule. Our dataset and analysis can help better prepare for the challenges and opportunities of auto moderation.
APPDIA: A Discourse-aware Transformer-based Style Transfer Model for Offensive Social Media Conversations
Sep 17, 2022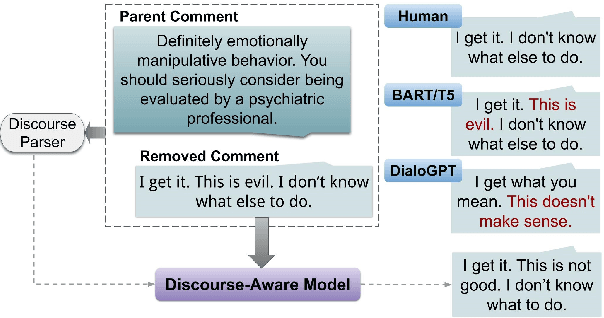
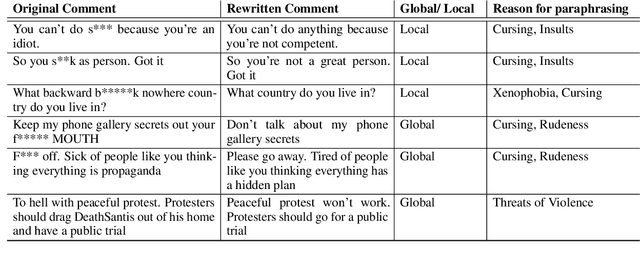
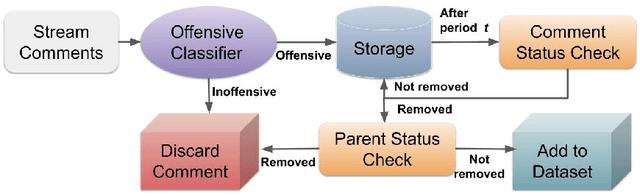
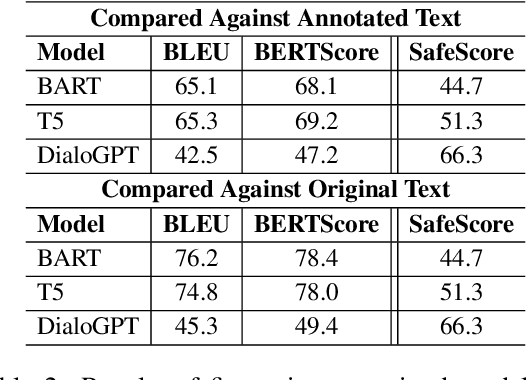
Using style-transfer models to reduce offensiveness of social media comments can help foster a more inclusive environment. However, there are no sizable datasets that contain offensive texts and their inoffensive counterparts, and fine-tuning pretrained models with limited labeled data can lead to the loss of original meaning in the style-transferred text. To address this issue, we provide two major contributions. First, we release the first publicly-available, parallel corpus of offensive Reddit comments and their style-transferred counterparts annotated by expert sociolinguists. Then, we introduce the first discourse-aware style-transfer models that can effectively reduce offensiveness in Reddit text while preserving the meaning of the original text. These models are the first to examine inferential links between the comment and the text it is replying to when transferring the style of offensive Reddit text. We propose two different methods of integrating discourse relations with pretrained transformer models and evaluate them on our dataset of offensive comments from Reddit and their inoffensive counterparts. Improvements over the baseline with respect to both automatic metrics and human evaluation indicate that our discourse-aware models are better at preserving meaning in style-transferred text when compared to the state-of-the-art discourse-agnostic models.
Dimensions of Interpersonal Dynamics in Text: Group Membership and Fine-grained Interpersonal Emotion
Sep 14, 2022
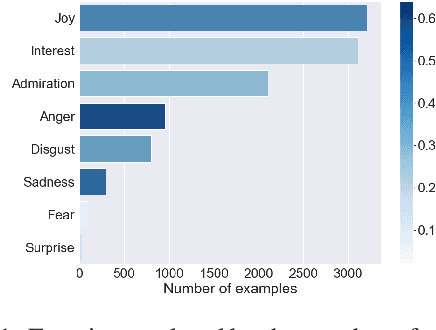
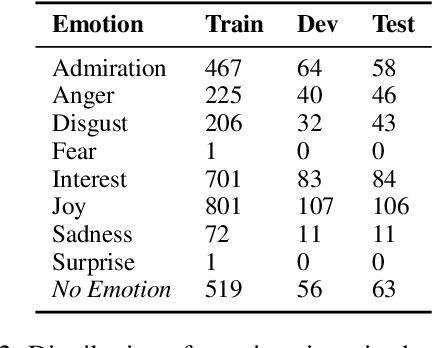
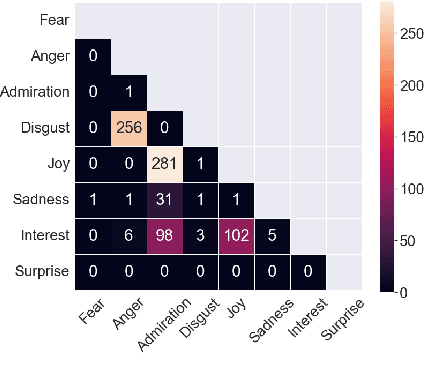
The ability of language to perpetuate inequality is most evident when individuals refer to, or talk about, other individuals in their utterances. While current studies of bias in NLP rely mainly on identifying hate speech or bias towards a specific group, we believe we can reach a more subtle and nuanced understanding of the interaction between bias and language use by modeling the speaker, the text, and the target in the text. In this paper, we introduce a dataset of 3033 English tweets by US Congress members annotated for interpersonal emotion, and `found supervision' for interpersonal group membership labels. We find that negative emotions such as anger and disgust are used predominantly in out-group situations, and directed predominantly at leaders of opposite parties. While humans can perform better than chance at identifying interpersonal group membership given an utterance, neural models perform much better; furthermore, a shared encoding between interpersonal group membership and interpersonal perceived emotion enabled some performance gains in the latter. This work aims to re-align the study of bias in NLP away from specific instances of bias to one which encapsulates the relationship between speaker, text, target and social dynamics. Data and code for this paper are available at https://github.com/venkatasg/Interpersonal-Dynamics
PAC-Bayesian Domain Adaptation Bounds for Multiclass Learners
Jul 12, 2022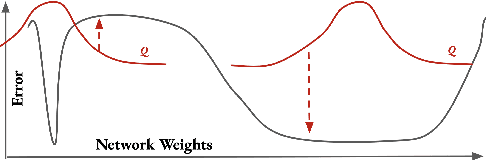

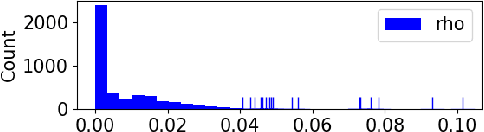
Multiclass neural networks are a common tool in modern unsupervised domain adaptation, yet an appropriate theoretical description for their non-uniform sample complexity is lacking in the adaptation literature. To fill this gap, we propose the first PAC-Bayesian adaptation bounds for multiclass learners. We facilitate practical use of our bounds by also proposing the first approximation techniques for the multiclass distribution divergences we consider. For divergences dependent on a Gibbs predictor, we propose additional PAC-Bayesian adaptation bounds which remove the need for inefficient Monte-Carlo estimation. Empirically, we test the efficacy of our proposed approximation techniques as well as some novel design-concepts which we include in our bounds. Finally, we apply our bounds to analyze a common adaptation algorithm that uses neural networks.
The Change that Matters in Discourse Parsing: Estimating the Impact of Domain Shift on Parser Error
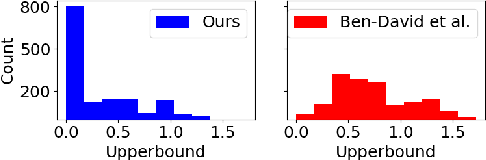
Mar 21, 2022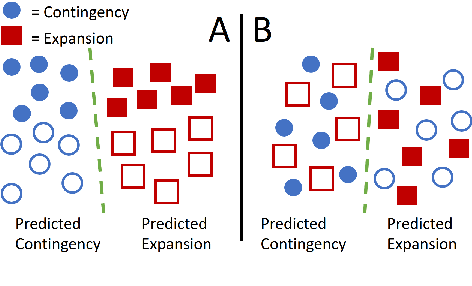
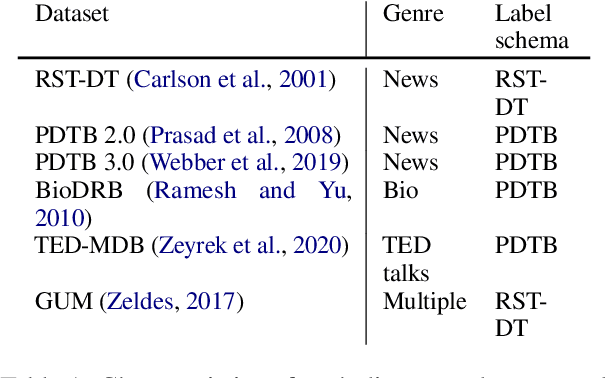
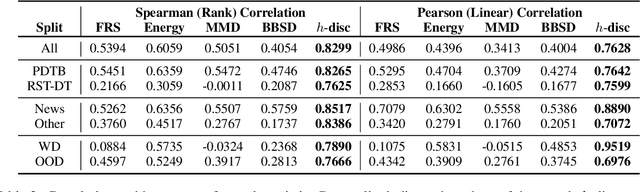

Discourse analysis allows us to attain inferences of a text document that extend beyond the sentence-level. The current performance of discourse models is very low on texts outside of the training distribution's coverage, diminishing the practical utility of existing models. There is need for a measure that can inform us to what extent our model generalizes from the training to the test sample when these samples may be drawn from distinct distributions. While this can be estimated via distribution shift, we argue that this does not directly correlate with change in the observed error of a classifier (i.e. error-gap). Thus, we propose to use a statistic from the theoretical domain adaptation literature which can be directly tied to error-gap. We study the bias of this statistic as an estimator of error-gap both theoretically and through a large-scale empirical study of over 2400 experiments on 6 discourse datasets from domains including, but not limited to: news, biomedical texts, TED talks, Reddit posts, and fiction. Our results not only motivate our proposal and help us to understand its limitations, but also provide insight on the properties of discourse models and datasets which improve performance in domain adaptation. For instance, we find that non-news datasets are slightly easier to transfer to than news datasets when the training and test sets are very different. Our code and an associated Python package are available to allow practitioners to make more informed model and dataset choices.