 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal QUD: Inquisitive Questions from Scientific Figures
Apr 26, 2026Asking inquisitive questions while reading, and looking for their answers, is an important part in human discourse comprehension, curiosity, and creative ideation, and prior work has investigated this in text-only scenarios. However, in scientific or research papers, many of the critical takeaways are conveyed through both figures and the text that analyzes them. While scientific visualizations have been used to evaluate Vision-Language Models (VLMs) capabilities, current benchmarks are limited to questions that focus simply on extracting information from them. Such questions only require lower-level reasoning, do not take into account the context in which a figure appears, and do not reflect the communicative goals the authors wish to achieve. We generate inquisitive questions that reach the depth of questions humans generate when engaging with scientific papers, conditioned on both the figure and the paper's context, and require reasoning across both modalities. To do so, we extend the linguistic theory of Questions Under Discussion (QUD) from being text-only to multimodal, where implicit questions are raised and resolved as discourse progresses. We present MQUD, a dataset of research papers in which such questions are made explicit and annotated by the original authors. We show that fine-tuning a VLM on MQUD shifts the model from generating generic low-level visual questions to content-specific grounding that requires a high-level of multimodal reasoning, yielding higher-quality, more visually grounded multimodal QUD generation.
Do they mean 'us'? Interpreting Referring Expressions in Intergroup Bias
Jun 25, 2024The variations between in-group and out-group speech (intergroup bias) are subtle and could underlie many social phenomena like stereotype perpetuation and implicit bias. In this paper, we model the intergroup bias as a tagging task on English sports comments from forums dedicated to fandom for NFL teams. We curate a unique dataset of over 6 million game-time comments from opposing perspectives (the teams in the game), each comment grounded in a non-linguistic description of the events that precipitated these comments (live win probabilities for each team). Expert and crowd annotations justify modeling the bias through tagging of implicit and explicit referring expressions and reveal the rich, contextual understanding of language and the world required for this task. For large-scale analysis of intergroup variation, we use LLMs for automated tagging, and discover that some LLMs perform best when prompted with linguistic descriptions of the win probability at the time of the comment, rather than numerical probability. Further, large-scale tagging of comments using LLMs uncovers linear variations in the form of referent across win probabilities that distinguish in-group and out-group utterances. Code and data are available at https://github.com/venkatasg/intergroup-nfl .
Counterfactually Probing Language Identity in Multilingual Models
Oct 29, 2023



Techniques in causal analysis of language models illuminate how linguistic information is organized in LLMs. We use one such technique, AlterRep, a method of counterfactual probing, to explore the internal structure of multilingual models (mBERT and XLM-R). We train a linear classifier on a binary language identity task, to classify tokens between Language X and Language Y. Applying a counterfactual probing procedure, we use the classifier weights to project the embeddings into the null space and push the resulting embeddings either in the direction of Language X or Language Y. Then we evaluate on a masked language modeling task. We find that, given a template in Language X, pushing towards Language Y systematically increases the probability of Language Y words, above and beyond a third-party control language. But it does not specifically push the model towards translation-equivalent words in Language Y. Pushing towards Language X (the same direction as the template) has a minimal effect, but somewhat degrades these models. Overall, we take these results as further evidence of the rich structure of massive multilingual language models, which include both a language-specific and language-general component. And we show that counterfactual probing can be fruitfully applied to multilingual models.
Lil-Bevo: Explorations of Strategies for Training Language Models in More Humanlike Ways
Oct 26, 2023



We present Lil-Bevo, our submission to the BabyLM Challenge. We pretrained our masked language models with three ingredients: an initial pretraining with music data, training on shorter sequences before training on longer ones, and masking specific tokens to target some of the BLiMP subtasks. Overall, our baseline models performed above chance, but far below the performance levels of larger LLMs trained on more data. We found that training on short sequences performed better than training on longer sequences.Pretraining on music may help performance marginally, but, if so, the effect seems small. Our targeted Masked Language Modeling augmentation did not seem to improve model performance in general, but did seem to help on some of the specific BLiMP tasks that we were targeting (e.g., Negative Polarity Items). Training performant LLMs on small amounts of data is a difficult but potentially informative task. While some of our techniques showed some promise, more work is needed to explore whether they can improve performance more than the modest gains here. Our code is available at https://github.com/venkatasg/Lil-Bevo and out models at https://huggingface.co/collections/venkatasg/babylm-653591cdb66f4bf68922873a
Counterfactual Probing for the Influence of Affect and Specificity on Intergroup Bias
Jun 02, 2023



While existing work on studying bias in NLP focues on negative or pejorative language use, Govindarajan et al. (2023) offer a revised framing of bias in terms of intergroup social context, and its effects on language behavior. In this paper, we investigate if two pragmatic features (specificity and affect) systematically vary in different intergroup contexts -- thus connecting this new framing of bias to language output. Preliminary analysis finds modest correlations between specificity and affect of tweets with supervised intergroup relationship (IGR) labels. Counterfactual probing further reveals that while neural models finetuned for predicting IGR labels reliably use affect in classification, the model's usage of specificity is inconclusive. Code and data can be found at: https://github.com/venkatasg/intergroup-probing
Dimensions of Interpersonal Dynamics in Text: Group Membership and Fine-grained Interpersonal Emotion
Sep 14, 2022
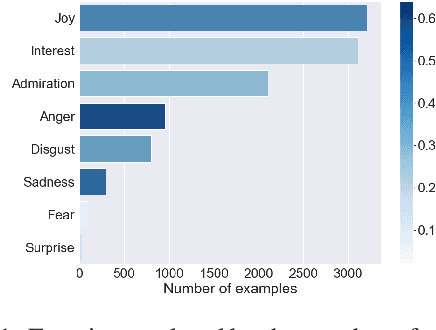
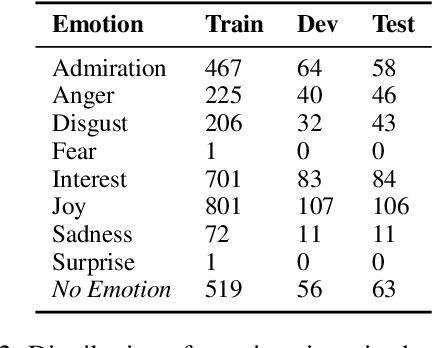
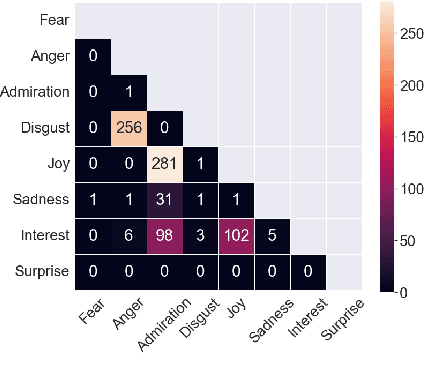
The ability of language to perpetuate inequality is most evident when individuals refer to, or talk about, other individuals in their utterances. While current studies of bias in NLP rely mainly on identifying hate speech or bias towards a specific group, we believe we can reach a more subtle and nuanced understanding of the interaction between bias and language use by modeling the speaker, the text, and the target in the text. In this paper, we introduce a dataset of 3033 English tweets by US Congress members annotated for interpersonal emotion, and `found supervision' for interpersonal group membership labels. We find that negative emotions such as anger and disgust are used predominantly in out-group situations, and directed predominantly at leaders of opposite parties. While humans can perform better than chance at identifying interpersonal group membership given an utterance, neural models perform much better; furthermore, a shared encoding between interpersonal group membership and interpersonal perceived emotion enabled some performance gains in the latter. This work aims to re-align the study of bias in NLP away from specific instances of bias to one which encapsulates the relationship between speaker, text, target and social dynamics. Data and code for this paper are available at https://github.com/venkatasg/Interpersonal-Dynamics
longhorns at DADC 2022: How many linguists does it take to fool a Question Answering model? A systematic approach to adversarial attacks
Jun 29, 2022



Developing methods to adversarially challenge NLP systems is a promising avenue for improving both model performance and interpretability. Here, we describe the approach of the team "longhorns" on Task 1 of the The First Workshop on Dynamic Adversarial Data Collection (DADC), which asked teams to manually fool a model on an Extractive Question Answering task. Our team finished first, with a model error rate of 62%. We advocate for a systematic, linguistically informed approach to formulating adversarial questions, and we describe the results of our pilot experiments, as well as our official submission.