 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Sign Language Annotations with Sign Language Models
Apr 08, 2026AI-driven sign language interpretation is limited by a lack of high-quality annotated data. New datasets including ASL STEM Wiki and FLEURS-ASL contain professional interpreters and 100s of hours of data but remain only partially annotated and thus underutilized, in part due to the prohibitive costs of annotating at this scale. In this work, we develop a pseudo-annotation pipeline that takes signed video and English as input and outputs a ranked set of likely annotations, including time intervals, for glosses, fingerspelled words, and sign classifiers. Our pipeline uses sparse predictions from our fingerspelling recognizer and isolated sign recognizer (ISR), along with a K-Shot LLM approach, to estimate these annotations. In service of this pipeline, we establish simple yet effective baseline fingerspelling and ISR models, achieving state-of-the-art on FSBoard (6.7% CER) and on ASL Citizen datasets (74% top-1 accuracy). To validate and provide a gold-standard benchmark, a professional interpreter annotated nearly 500 videos from ASL STEM Wiki with sequence-level gloss labels containing glosses, classifiers, and fingerspelling signs. These human annotations and over 300 hours of pseudo-annotations are being released in supplemental material.
Generating Signed Language Instructions in Large-Scale Dialogue Systems
Oct 17, 2024



We introduce a goal-oriented conversational AI system enhanced with American Sign Language (ASL) instructions, presenting the first implementation of such a system on a worldwide multimodal conversational AI platform. Accessible through a touch-based interface, our system receives input from users and seamlessly generates ASL instructions by leveraging retrieval methods and cognitively based gloss translations. Central to our design is a sign translation module powered by Large Language Models, alongside a token-based video retrieval system for delivering instructional content from recipes and wikiHow guides. Our development process is deeply rooted in a commitment to community engagement, incorporating insights from the Deaf and Hard-of-Hearing community, as well as experts in cognitive and ASL learning sciences. The effectiveness of our signing instructions is validated by user feedback, achieving ratings on par with those of the system in its non-signing variant. Additionally, our system demonstrates exceptional performance in retrieval accuracy and text-generation quality, measured by metrics such as BERTScore. We have made our codebase and datasets publicly accessible at https://github.com/Merterm/signed-dialogue, and a demo of our signed instruction video retrieval system is available at https://huggingface.co/spaces/merterm/signed-instructions.
Modeling Intensification for Sign Language Generation: A Computational Approach
Mar 18, 2022
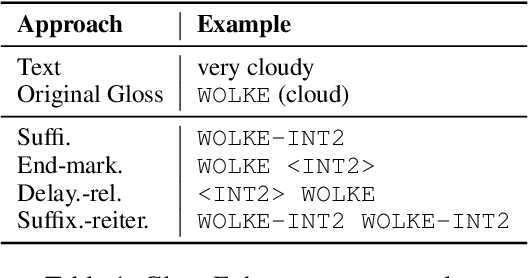
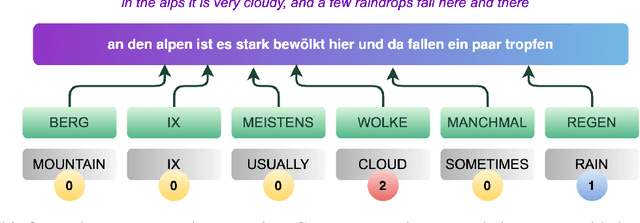
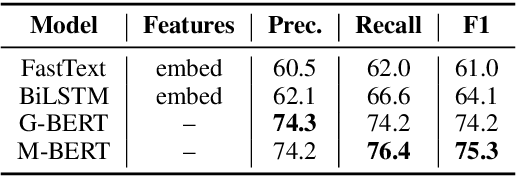
End-to-end sign language generation models do not accurately represent the prosody in sign language. A lack of temporal and spatial variations leads to poor-quality generated presentations that confuse human interpreters. In this paper, we aim to improve the prosody in generated sign languages by modeling intensification in a data-driven manner. We present different strategies grounded in linguistics of sign language that inform how intensity modifiers can be represented in gloss annotations. To employ our strategies, we first annotate a subset of the benchmark PHOENIX-14T, a German Sign Language dataset, with different levels of intensification. We then use a supervised intensity tagger to extend the annotated dataset and obtain labels for the remaining portion of it. This enhanced dataset is then used to train state-of-the-art transformer models for sign language generation. We find that our efforts in intensification modeling yield better results when evaluated with automatic metrics. Human evaluation also indicates a higher preference of the videos generated using our model.
Including Facial Expressions in Contextual Embeddings for Sign Language Generation
Feb 11, 2022



State-of-the-art sign language generation frameworks lack expressivity and naturalness which is the result of only focusing manual signs, neglecting the affective, grammatical and semantic functions of facial expressions. The purpose of this work is to augment semantic representation of sign language through grounding facial expressions. We study the effect of modeling the relationship between text, gloss, and facial expressions on the performance of the sign generation systems. In particular, we propose a Dual Encoder Transformer able to generate manual signs as well as facial expressions by capturing the similarities and differences found in text and sign gloss annotation. We take into consideration the role of facial muscle activity to express intensities of manual signs by being the first to employ facial action units in sign language generation. We perform a series of experiments showing that our proposed model improves the quality of automatically generated sign language.