 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASL STEM Wiki: Dataset and Benchmark for Interpreting STEM Articles
Nov 08, 2024Deaf and hard-of-hearing (DHH) students face significant barriers in accessing science, technology, engineering, and mathematics (STEM) education, notably due to the scarcity of STEM resources in signed languages. To help address this, we introduce ASL STEM Wiki: a parallel corpus of 254 Wikipedia articles on STEM topics in English, interpreted into over 300 hours of American Sign Language (ASL). ASL STEM Wiki is the first continuous signing dataset focused on STEM, facilitating the development of AI resources for STEM education in ASL. We identify several use cases of ASL STEM Wiki with human-centered applications. For example, because this dataset highlights the frequent use of fingerspelling for technical concepts, which inhibits DHH students' ability to learn, we develop models to identify fingerspelled words -- which can later be used to query for appropriate ASL signs to suggest to interpreters.
Studying and Mitigating Biases in Sign Language Understanding Models
Oct 07, 2024



Ensuring that the benefits of sign language technologies are distributed equitably among all community members is crucial. Thus, it is important to address potential biases and inequities that may arise from the design or use of these resources. Crowd-sourced sign language datasets, such as the ASL Citizen dataset, are great resources for improving accessibility and preserving linguistic diversity, but they must be used thoughtfully to avoid reinforcing existing biases. In this work, we utilize the rich information about participant demographics and lexical features present in the ASL Citizen dataset to study and document the biases that may result from models trained on crowd-sourced sign datasets. Further, we apply several bias mitigation techniques during model training, and find that these techniques reduce performance disparities without decreasing accuracy. With the publication of this work, we release the demographic information about the participants in the ASL Citizen dataset to encourage future bias mitigation work in this space.
ASL Citizen: A Community-Sourced Dataset for Advancing Isolated Sign Language Recognition
Apr 12, 2023



Sign languages are used as a primary language by approximately 70 million D/deaf people world-wide. However, most communication technologies operate in spoken and written languages, creating inequities in access. To help tackle this problem, we release ASL Citizen, the largest Isolated Sign Language Recognition (ISLR) dataset to date, collected with consent and containing 83,912 videos for 2,731 distinct signs filmed by 52 signers in a variety of environments. We propose that this dataset be used for sign language dictionary retrieval for American Sign Language (ASL), where a user demonstrates a sign to their own webcam with the aim of retrieving matching signs from a dictionary. We show that training supervised machine learning classifiers with our dataset greatly advances the state-of-the-art on metrics relevant for dictionary retrieval, achieving, for instance, 62% accuracy and a recall-at-10 of 90%, evaluated entirely on videos of users who are not present in the training or validation sets. An accessible PDF of this article is available at https://aashakadesai.github.io/research/ASL_Dataset__arxiv_.pdf
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
Sign Language Recognition, Generation, and Translation: An Interdisciplinary Perspective
Aug 22, 2019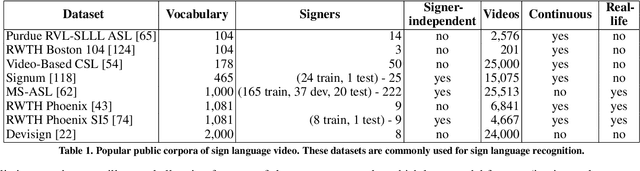

Developing successful sign language recognition, generation, and translation systems requires expertise in a wide range of fields, including computer vision, computer graphics, natural language processing, human-computer interaction, linguistics, and Deaf culture. Despite the need for deep interdisciplinary knowledge, existing research occurs in separate disciplinary silos, and tackles separate portions of the sign language processing pipeline. This leads to three key questions: 1) What does an interdisciplinary view of the current landscape reveal? 2) What are the biggest challenges facing the field? and 3) What are the calls to action for people working in the field? To help answer these questions, we brought together a diverse group of experts for a two-day workshop. This paper presents the results of that interdisciplinary workshop, providing key background that is often overlooked by computer scientists, a review of the state-of-the-art, a set of pressing challenges, and a call to action for the research community.