 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking While Moving: Deep Reinforcement Learning with Concurrent Control
Apr 25, 2020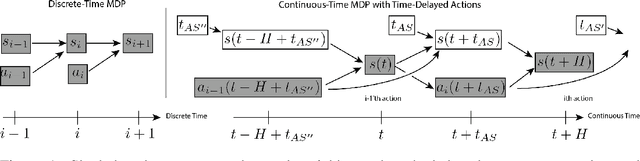
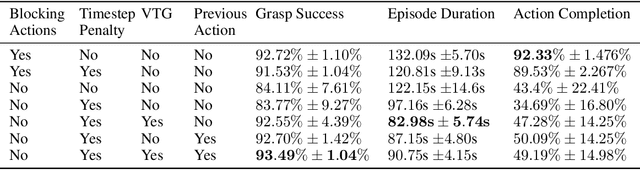
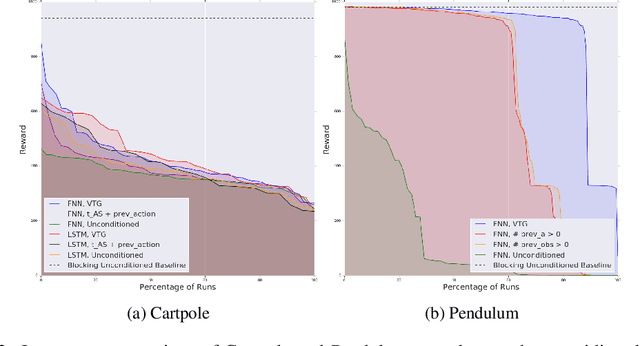

We study reinforcement learning in settings where sampling an action from the policy must be done concurrently with the time evolution of the controlled system, such as when a robot must decide on the next action while still performing the previous action. Much like a person or an animal, the robot must think and move at the same time, deciding on its next action before the previous one has completed. In order to develop an algorithmic framework for such concurrent control problems, we start with a continuous-time formulation of the Bellman equations, and then discretize them in a way that is aware of system delays. We instantiate this new class of approximate dynamic programming methods via a simple architectural extension to existing value-based deep reinforcement learning algorithms. We evaluate our methods on simulated benchmark tasks and a large-scale robotic grasping task where the robot must "think while moving".
Efficient Adaptation for End-to-End Vision-Based Robotic Manipulation
Apr 21, 2020
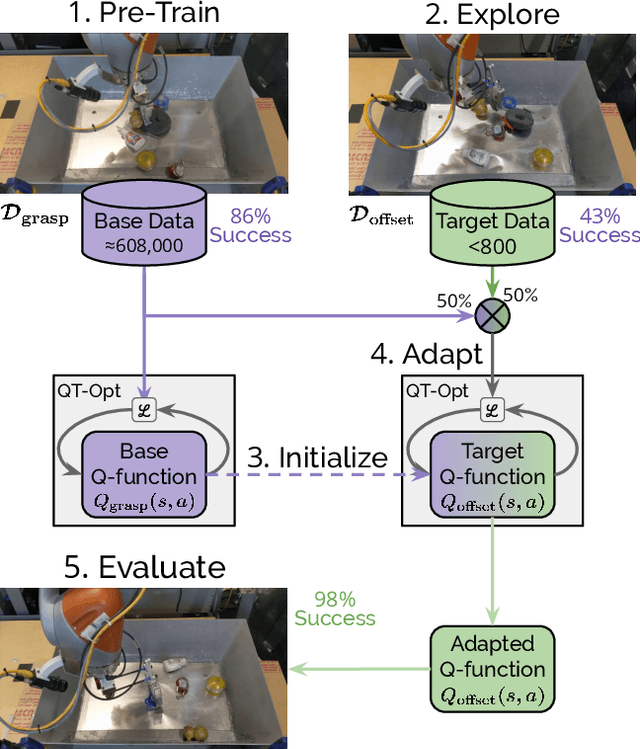
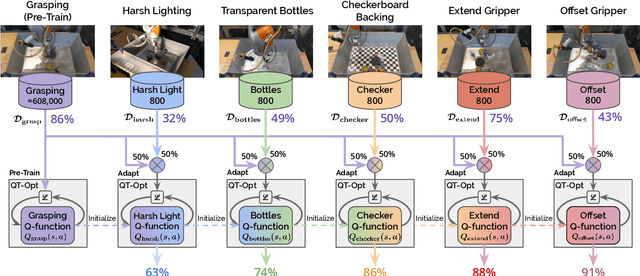
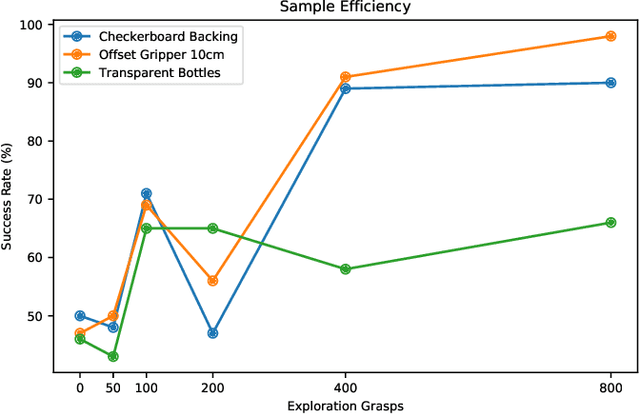
One of the great promises of robot learning systems is that they will be able to learn from their mistakes and continuously adapt to ever-changing environments. Despite this potential, most of the robot learning systems today are deployed as a fixed policy and they are not being adapted after their deployment. Can we efficiently adapt previously learned behaviors to new environments, objects and percepts in the real world? In this paper, we present a method and empirical evidence towards a robot learning framework that facilitates continuous adaption. In particular, we demonstrate how to adapt vision-based robotic manipulation policies to new variations by fine-tuning via off-policy reinforcement learning, including changes in background, object shape and appearance, lighting conditions, and robot morphology. Further, this adaptation uses less than 0.2% of the data necessary to learn the task from scratch. We find that our approach of adapting pre-trained policies leads to substantial performance gains over the course of fine-tuning, and that pre-training via RL is essential: training from scratch or adapting from supervised ImageNet features are both unsuccessful with such small amounts of data. We also find that these positive results hold in a limited continual learning setting, in which we repeatedly fine-tune a single lineage of policies using data from a succession of new tasks. Our empirical conclusions are consistently supported by experiments on simulated manipulation tasks, and by 52 unique fine-tuning experiments on a real robotic grasping system pre-trained on 580,000 grasps.
Gradient Surgery for Multi-Task Learning
Jan 19, 2020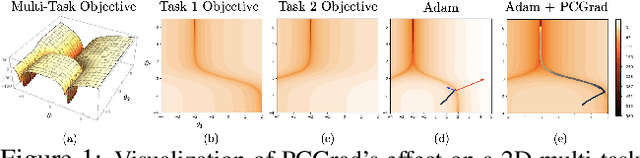
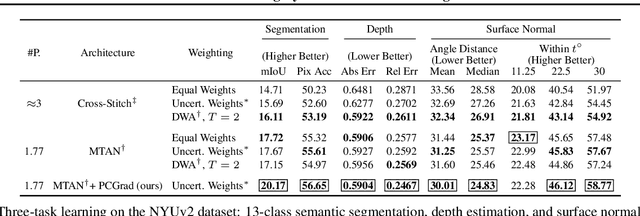
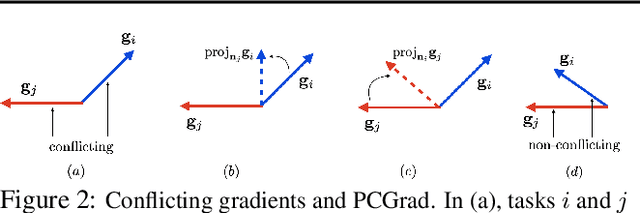
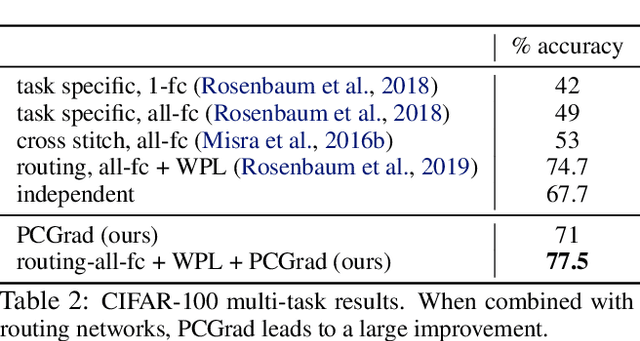
While deep learning and deep reinforcement learning (RL) systems have demonstrated impressive results in domains such as image classification, game playing, and robotic control, data efficiency remains a major challenge. Multi-task learning has emerged as a promising approach for sharing structure across multiple tasks to enable more efficient learning. However, the multi-task setting presents a number of optimization challenges, making it difficult to realize large efficiency gains compared to learning tasks independently. The reasons why multi-task learning is so challenging compared to single-task learning are not fully understood. In this work, we identify a set of three conditions of the multi-task optimization landscape that cause detrimental gradient interference, and develop a simple yet general approach for avoiding such interference between task gradients. We propose a form of gradient surgery that projects a task's gradient onto the normal plane of the gradient of any other task that has a conflicting gradient. On a series of challenging multi-task supervised and multi-task RL problems, this approach leads to substantial gains in efficiency and performance. Further, it is model-agnostic and can be combined with previously-proposed multi-task architectures for enhanced performance.
Relay Policy Learning: Solving Long-Horizon Tasks via Imitation and Reinforcement Learning
Oct 25, 2019

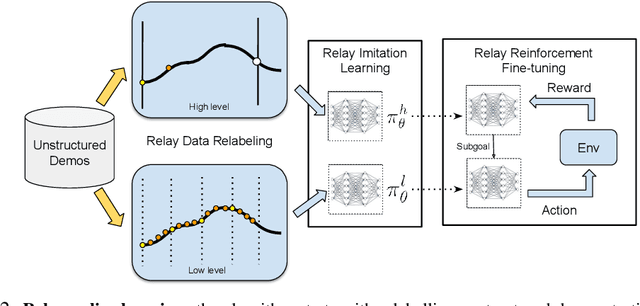
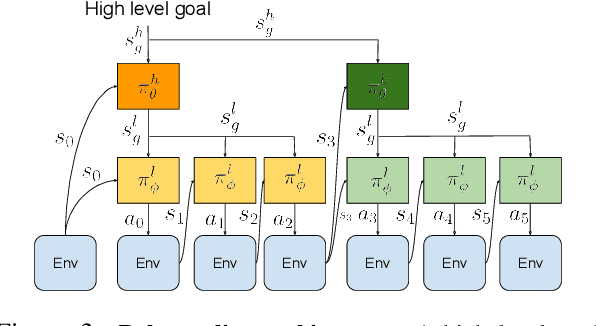
We present relay policy learning, a method for imitation and reinforcement learning that can solve multi-stage, long-horizon robotic tasks. This general and universally-applicable, two-phase approach consists of an imitation learning stage that produces goal-conditioned hierarchical policies, and a reinforcement learning phase that finetunes these policies for task performance. Our method, while not necessarily perfect at imitation learning, is very amenable to further improvement via environment interaction, allowing it to scale to challenging long-horizon tasks. We simplify the long-horizon policy learning problem by using a novel data-relabeling algorithm for learning goal-conditioned hierarchical policies, where the low-level only acts for a fixed number of steps, regardless of the goal achieved. While we rely on demonstration data to bootstrap policy learning, we do not assume access to demonstrations of every specific tasks that is being solved, and instead leverage unstructured and unsegmented demonstrations of semantically meaningful behaviors that are not only less burdensome to provide, but also can greatly facilitate further improvement using reinforcement learning. We demonstrate the effectiveness of our method on a number of multi-stage, long-horizon manipulation tasks in a challenging kitchen simulation environment. Videos are available at https://relay-policy-learning.github.io/
Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning
Oct 24, 2019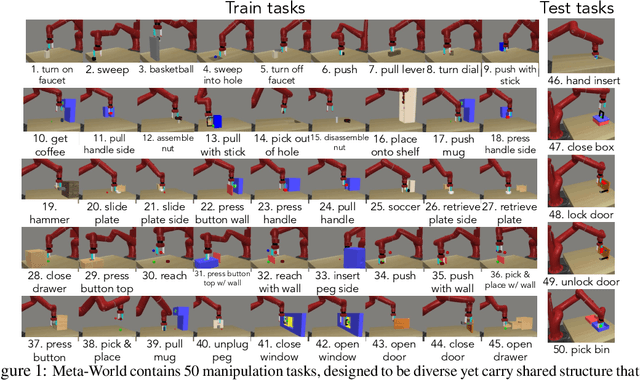


Meta-reinforcement learning algorithms can enable robots to acquire new skills much more quickly, by leveraging prior experience to learn how to learn. However, much of the current research on meta-reinforcement learning focuses on task distributions that are very narrow. For example, a commonly used meta-reinforcement learning benchmark uses different running velocities for a simulated robot as different tasks. When policies are meta-trained on such narrow task distributions, they cannot possibly generalize to more quickly acquire entirely new tasks. Therefore, if the aim of these methods is to enable faster acquisition of entirely new behaviors, we must evaluate them on task distributions that are sufficiently broad to enable generalization to new behaviors. In this paper, we propose an open-source simulated benchmark for meta-reinforcement learning and multi-task learning consisting of 50 distinct robotic manipulation tasks. Our aim is to make it possible to develop algorithms that generalize to accelerate the acquisition of entirely new, held-out tasks. We evaluate 6 state-of-the-art meta-reinforcement learning and multi-task learning algorithms on these tasks. Surprisingly, while each task and its variations (e.g., with different object positions) can be learned with reasonable success, these algorithms struggle to learn with multiple tasks at the same time, even with as few as ten distinct training tasks. Our analysis and open-source environments pave the way for future research in multi-task learning and meta-learning that can enable meaningful generalization, thereby unlocking the full potential of these methods.
Quantile QT-Opt for Risk-Aware Vision-Based Robotic Grasping
Oct 01, 2019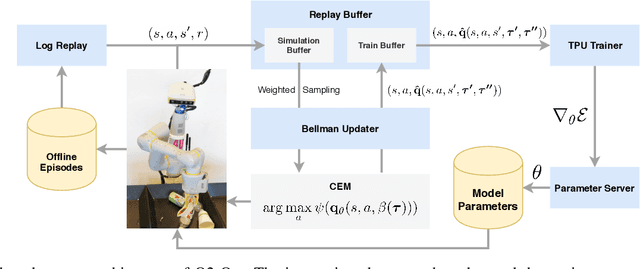
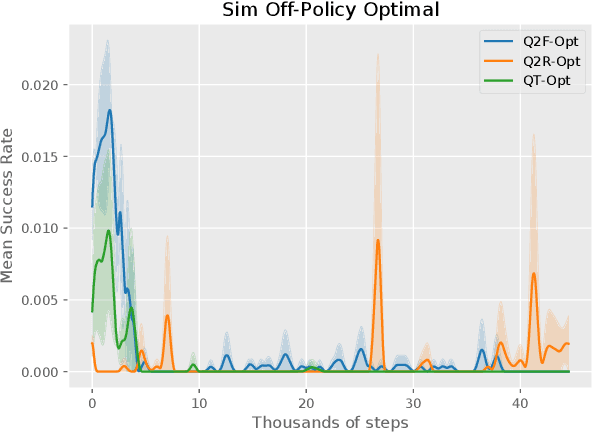
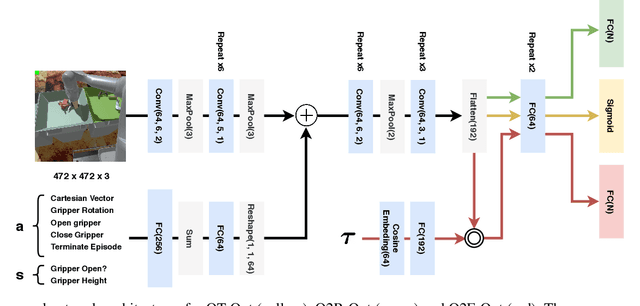
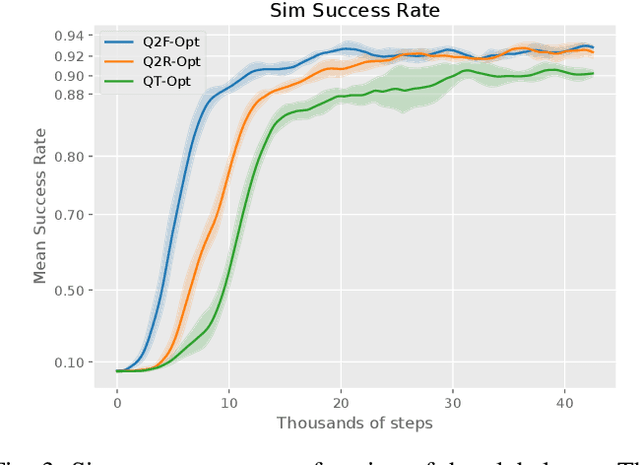
The distributional perspective on reinforcement learning (RL) has given rise to a series of successful Q-learning algorithms, resulting in state-of-the-art performance in arcade game environments. However, it has not yet been analyzed how these findings from a discrete setting translate to complex practical applications characterized by noisy, high dimensional and continuous state-action spaces. In this work, we propose Quantile QT-Opt (Q2-Opt), a distributional variant of the recently introduced distributed Q-learning algorithm for continuous domains, and examine its behaviour in a series of simulated and real vision-based robotic grasping tasks. The absence of an actor in Q2-Opt allows us to directly draw a parallel to the previous discrete experiments in the literature without the additional complexities induced by an actor-critic architecture. We demonstrate that Q2-Opt achieves a superior vision-based object grasping success rate, while also being more sample efficient. The distributional formulation also allows us to experiment with various risk-distortion metrics that give us an indication of how robots can concretely manage risk in practice using a Deep RL control policy. As an additional contribution, we perform experiments on offline datasets and compare them with the latest findings from discrete settings. Surprisingly, we find that there is a discrepancy between our results and the previous batch RL findings from the literature obtained on arcade game environments.
Dynamics-Aware Unsupervised Discovery of Skills
Jul 02, 2019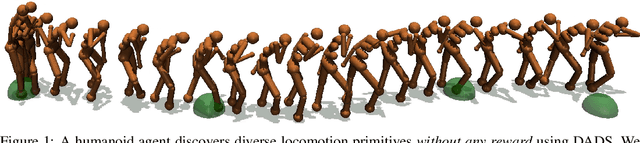
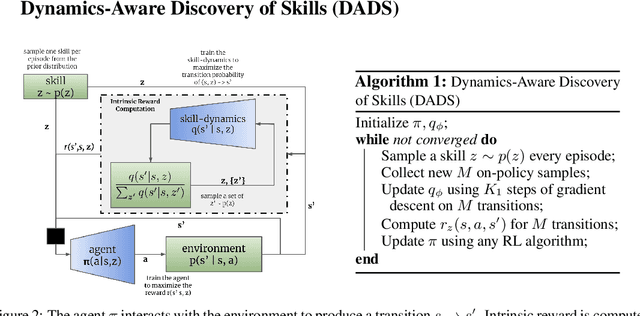
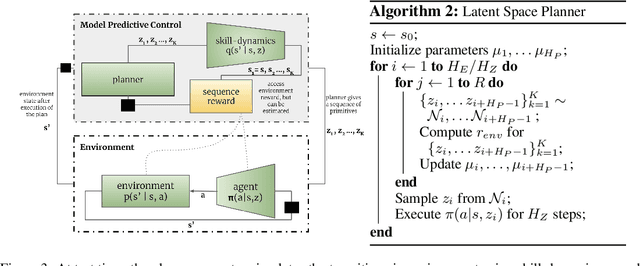

Conventionally, model-based reinforcement learning (MBRL) aims to learn a global model for the dynamics of the environment. A good model can potentially enable planning algorithms to generate a large variety of behaviors and solve diverse tasks. However, learning an accurate model for complex dynamical systems is difficult, and even then, the model might not generalize well outside the distribution of states on which it was trained. In this work, we combine model-based learning with model-free learning of primitives that make model-based planning easy. To that end, we aim to answer the question: how can we discover skills whose outcomes are easy to predict? We propose an unsupervised learning algorithm, Dynamics-Aware Discovery of Skills (DADS), which simultaneously discovers predictable behaviors and learns their dynamics. Our method can leverage continuous skill spaces, theoretically, allowing us to learn infinitely many behaviors even for high-dimensional state-spaces. We demonstrate that zero-shot planning in the learned latent space significantly outperforms standard MBRL and model-free goal-conditioned RL, can handle sparse-reward tasks, and substantially improves over prior hierarchical RL methods for unsupervised skill discovery.
Training an Interactive Helper
Jul 02, 2019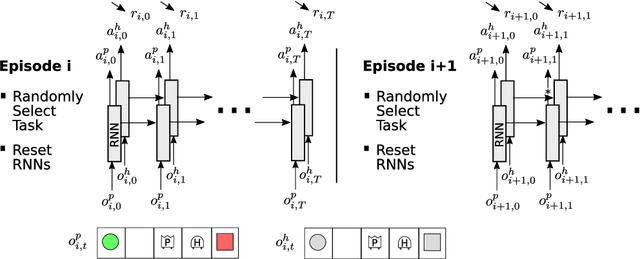
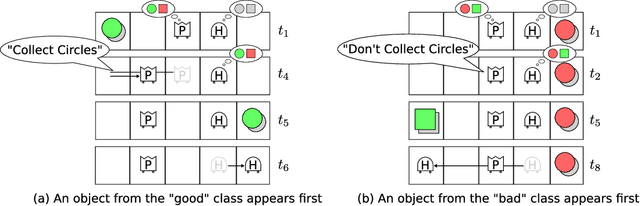
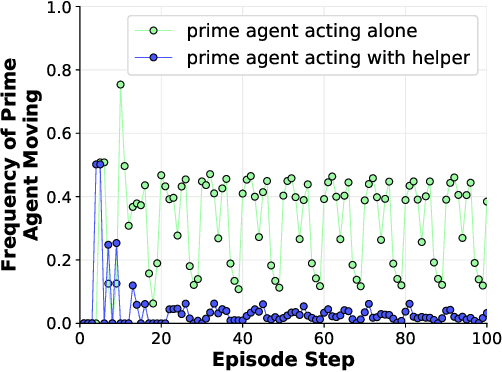
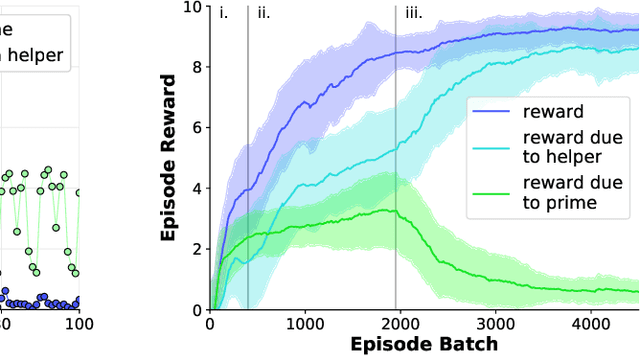
Developing agents that can quickly adapt their behavior to new tasks remains a challenge. Meta-learning has been applied to this problem, but previous methods require either specifying a reward function which can be tedious or providing demonstrations which can be inefficient. In this paper, we investigate if, and how, a "helper" agent can be trained to interactively adapt their behavior to maximize the reward of another agent, whom we call the "prime" agent, without observing their reward or receiving explicit demonstrations. To this end, we propose to meta-learn a helper agent along with a prime agent, who, during training, observes the reward function and serves as a surrogate for a human prime. We introduce a distribution of multi-agent cooperative foraging tasks, in which only the prime agent knows the objects that should be collected. We demonstrate that, from the emerged physical communication, the trained helper rapidly infers and collects the correct objects.
Learning to Interactively Learn and Assist
Jul 01, 2019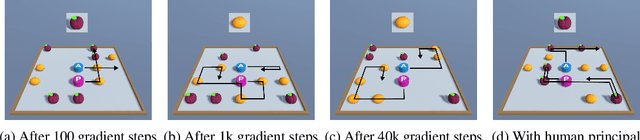

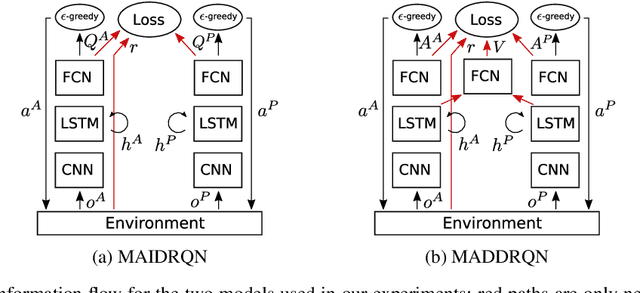

When deploying autonomous agents in the real world, we need effective ways of communicating objectives to them. Traditional skill learning has revolved around reinforcement and imitation learning, each with rigid constraints on the format of information exchanged between the human and the agent. While scalar rewards carry little information, demonstrations require significant effort to provide and may carry more information than is necessary. Furthermore, rewards and demonstrations are often defined and collected before training begins, when the human is most uncertain about what information would help the agent. In contrast, when humans communicate objectives with each other, they make use of a large vocabulary of informative behaviors, including non-verbal communication, and often communicate throughout learning, responding to observed behavior. In this way, humans communicate intent with minimal effort. In this paper, we propose such interactive learning as an alternative to reward or demonstration-driven learning. To accomplish this, we introduce a multi-agent training framework that enables an agent to learn from another agent who knows the current task. Through a series of experiments, we demonstrate the emergence of a variety of interactive learning behaviors, including information-sharing, information-seeking, and question-answering. Most importantly, we find that our approach produces an agent that is capable of learning interactively from a human user, without a set of explicit demonstrations or a reward function, and achieving significantly better performance cooperatively with a human than a human performing the task alone.
Scaling simulation-to-real transfer by learning composable robot skills
Nov 13, 2018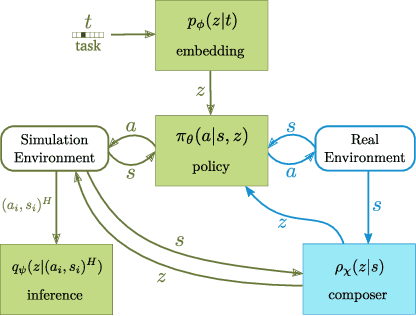
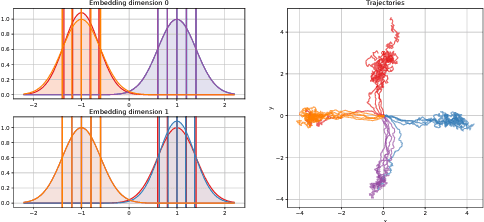

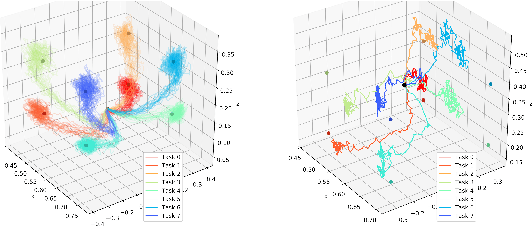
We present a novel solution to the problem of simulation-to-real transfer, which builds on recent advances in robot skill decomposition. Rather than focusing on minimizing the simulation-reality gap, we learn a set of diverse policies that are parameterized in a way that makes them easily reusable. This diversity and parameterization of low-level skills allows us to find a transferable policy that is able to use combinations and variations of different skills to solve more complex, high-level tasks. In particular, we first use simulation to jointly learn a policy for a set of low-level skills, and a "skill embedding" parameterization which can be used to compose them. Later, we learn high-level policies which actuate the low-level policies via this skill embedding parameterization. The high-level policies encode how and when to reuse the low-level skills together to achieve specific high-level tasks. Importantly, our method learns to control a real robot in joint-space to achieve these high-level tasks with little or no on-robot time, despite the fact that the low-level policies may not be perfectly transferable from simulation to real, and that the low-level skills were not trained on any examples of high-level tasks. We illustrate the principles of our method using informative simulation experiments. We then verify its usefulness for real robotics problems by learning, transferring, and composing free-space and contact motion skills on a Sawyer robot using only joint-space control. We experiment with several techniques for composing pre-learned skills, and find that our method allows us to use both learning-based approaches and efficient search-based planning to achieve high-level tasks using only pre-learned skills.