 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAV2Wav: Diffusion-Based Re-synthesis from Continuous Self-supervised Features for Audio-Visual Speech Enhancement
Sep 14, 2023Speech enhancement systems are typically trained using pairs of clean and noisy speech. In audio-visual speech enhancement (AVSE), there is not as much ground-truth clean data available; most audio-visual datasets are collected in real-world environments with background noise and reverberation, hampering the development of AVSE. In this work, we introduce AV2Wav, a resynthesis-based audio-visual speech enhancement approach that can generate clean speech despite the challenges of real-world training data. We obtain a subset of nearly clean speech from an audio-visual corpus using a neural quality estimator, and then train a diffusion model on this subset to generate waveforms conditioned on continuous speech representations from AV-HuBERT with noise-robust training. We use continuous rather than discrete representations to retain prosody and speaker information. With this vocoding task alone, the model can perform speech enhancement better than a masking-based baseline. We further fine-tune the diffusion model on clean/noisy utterance pairs to improve the performance. Our approach outperforms a masking-based baseline in terms of both automatic metrics and a human listening test and is close in quality to the target speech in the listening test. Audio samples can be found at https://home.ttic.edu/~jcchou/demo/avse/avse_demo.html.
Self-Supervised Video Transformers for Isolated Sign Language Recognition
Sep 02, 2023



This paper presents an in-depth analysis of various self-supervision methods for isolated sign language recognition (ISLR). We consider four recently introduced transformer-based approaches to self-supervised learning from videos, and four pre-training data regimes, and study all the combinations on the WLASL2000 dataset. Our findings reveal that MaskFeat achieves performance superior to pose-based and supervised video models, with a top-1 accuracy of 79.02% on gloss-based WLASL2000. Furthermore, we analyze these models' ability to produce representations of ASL signs using linear probing on diverse phonological features. This study underscores the value of architecture and pre-training task choices in ISLR. Specifically, our results on WLASL2000 highlight the power of masked reconstruction pre-training, and our linear probing results demonstrate the importance of hierarchical vision transformers for sign language representation.
What do self-supervised speech models know about words?
Jun 30, 2023Many self-supervised speech models (S3Ms) have been introduced over the last few years, producing performance and data efficiency improvements for a variety of speech tasks. Evidence is emerging that different S3Ms encode linguistic information in different layers, and also that some S3Ms appear to learn phone-like sub-word units. However, the extent to which these models capture larger linguistic units, such as words, and where word-related information is encoded, remains unclear. In this study, we conduct several analyses of word segment representations extracted from different layers of three S3Ms: wav2vec2, HuBERT, and WavLM. We employ canonical correlation analysis (CCA), a lightweight analysis tool, to measure the similarity between these representations and word-level linguistic properties. We find that the maximal word-level linguistic content tends to be found in intermediate model layers, while some lower-level information like pronunciation is also retained in higher layers of HuBERT and WavLM. Syntactic and semantic word attributes have similar layer-wise behavior. We also find that, for all of the models tested, word identity information is concentrated near the center of each word segment. We then test the layer-wise performance of the same models, when used directly with no additional learned parameters, on several tasks: acoustic word discrimination, word segmentation, and semantic sentence similarity. We find similar layer-wise trends in performance, and furthermore, find that when using the best-performing layer of HuBERT or WavLM, it is possible to achieve performance on word segmentation and sentence similarity that rivals more complex existing approaches.
SLUE Phase-2: A Benchmark Suite of Diverse Spoken Language Understanding Tasks
Dec 20, 2022Spoken language understanding (SLU) tasks have been studied for many decades in the speech research community, but have not received as much attention as lower-level tasks like speech and speaker recognition. In particular, there are not nearly as many SLU task benchmarks, and many of the existing ones use data that is not freely available to all researchers. Recent work has begun to introduce such benchmark datasets for several tasks. In this work, we introduce several new annotated SLU benchmark tasks based on freely available speech data, which complement existing benchmarks and address gaps in the SLU evaluation landscape. We contribute four tasks: question answering and summarization involve inference over longer speech sequences; named entity localization addresses the speech-specific task of locating the targeted content in the signal; dialog act classification identifies the function of a given speech utterance. We follow the blueprint of the Spoken Language Understanding Evaluation (SLUE) benchmark suite. In order to facilitate the development of SLU models that leverage the success of pre-trained speech representations, we will be publishing for each task (i) annotations for a relatively small fine-tuning set, (ii) annotated development and test sets, and (iii) baseline models for easy reproducibility and comparisons. In this work, we present the details of data collection and annotation and the performance of the baseline models. We also perform sensitivity analysis of pipeline models' performance (speech recognizer + text model) to the speech recognition accuracy, using more than 20 state-of-the-art speech recognition models.
Context-aware Fine-tuning of Self-supervised Speech Models
Dec 16, 2022



Self-supervised pre-trained transformers have improved the state of the art on a variety of speech tasks. Due to the quadratic time and space complexity of self-attention, they usually operate at the level of relatively short (e.g., utterance) segments. In this paper, we study the use of context, i.e., surrounding segments, during fine-tuning and propose a new approach called context-aware fine-tuning. We attach a context module on top of the last layer of a pre-trained model to encode the whole segment into a context embedding vector which is then used as an additional feature for the final prediction. During the fine-tuning stage, we introduce an auxiliary loss that encourages this context embedding vector to be similar to context vectors of surrounding segments. This allows the model to make predictions without access to these surrounding segments at inference time and requires only a tiny overhead compared to standard fine-tuned models. We evaluate the proposed approach using the SLUE and Librilight benchmarks for several downstream tasks: Automatic speech recognition (ASR), named entity recognition (NER), and sentiment analysis (SA). The results show that context-aware fine-tuning not only outperforms a standard fine-tuning baseline but also rivals a strong context injection baseline that uses neighboring speech segments during inference.
Comparative layer-wise analysis of self-supervised speech models
Nov 08, 2022Many self-supervised speech models, varying in their pre-training objective, input modality, and pre-training data, have been proposed in the last few years. Despite impressive empirical successes on downstream tasks, we still have a limited understanding of the properties encoded by the models and the differences across models. In this work, we examine the intermediate representations for a variety of recent models. Specifically, we measure acoustic, phonetic, and word-level properties encoded in individual layers, using a lightweight analysis tool based on canonical correlation analysis (CCA). We find that these properties evolve across layers differently depending on the model, and the variations relate to the choice of pre-training objective. We further investigate the utility of our analyses for downstream tasks by comparing the property trends with performance on speech recognition and spoken language understanding tasks. We discover that CCA trends provide reliable guidance to choose layers of interest for downstream tasks and that single-layer performance often matches or improves upon using all layers, suggesting implications for more efficient use of pre-trained models.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Open-Domain Sign Language Translation Learned from Online Video
May 25, 2022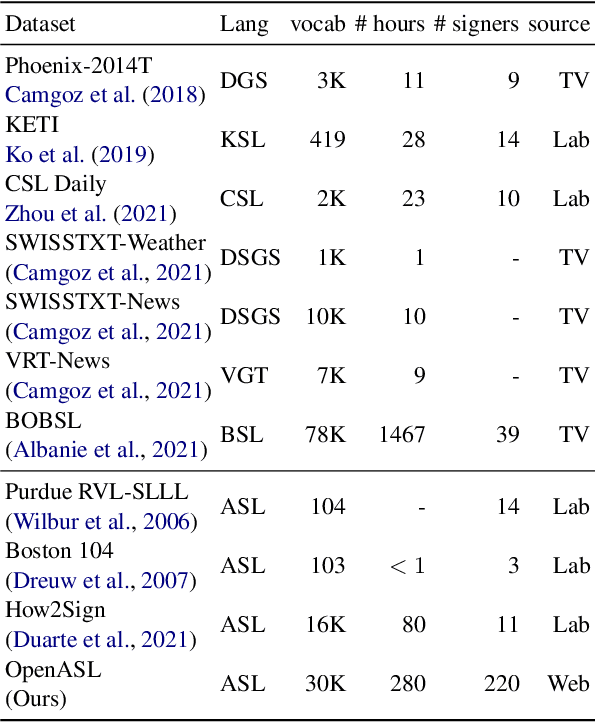
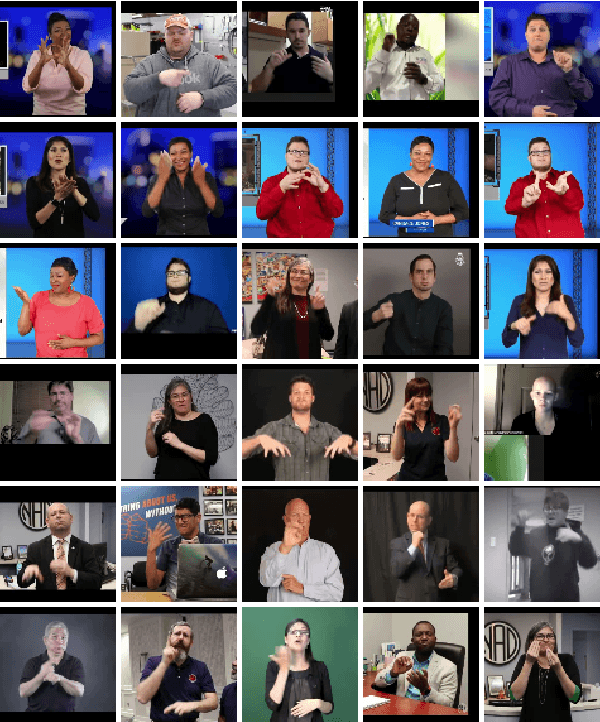
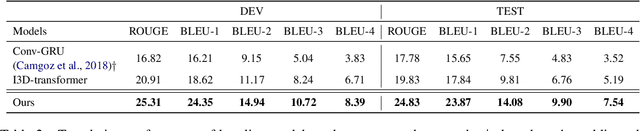
Existing work on sign language translation--that is, translation from sign language videos into sentences in a written language--has focused mainly on (1) data collected in a controlled environment or (2) data in a specific domain, which limits the applicability to real-world settings. In this paper, we introduce OpenASL, a large-scale ASL-English dataset collected from online video sites (e.g., YouTube). OpenASL contains 288 hours of ASL videos in various domains (news, VLOGs, etc.) from over 200 signers and is the largest publicly available ASL translation dataset to date. To tackle the challenges of sign language translation in realistic settings and without glosses, we propose a set of techniques including sign search as a pretext task for pre-training and fusion of mouthing and handshape features. The proposed techniques produce consistent and large improvements in translation quality, over baseline models based on prior work. Our data, code and model will be publicly available at https://github.com/chevalierNoir/OpenASL
Self-Supervised Speech Representation Learning: A Review
May 21, 2022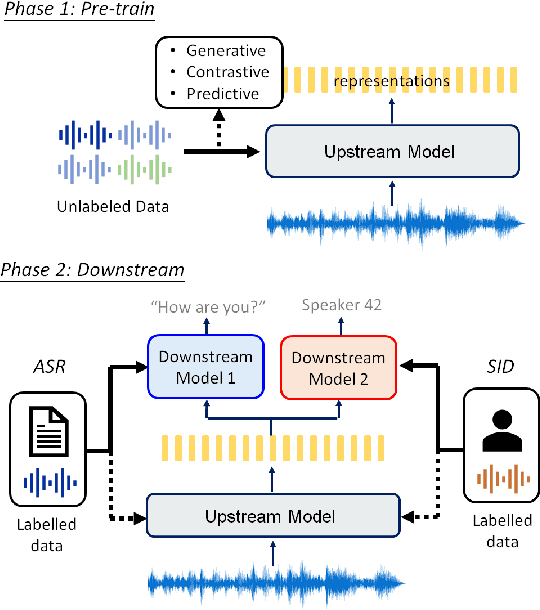
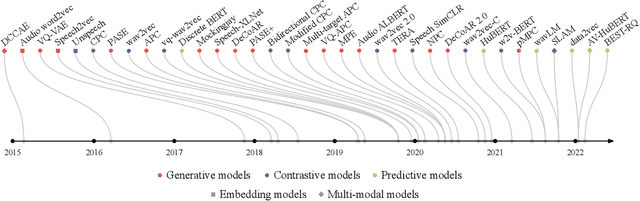
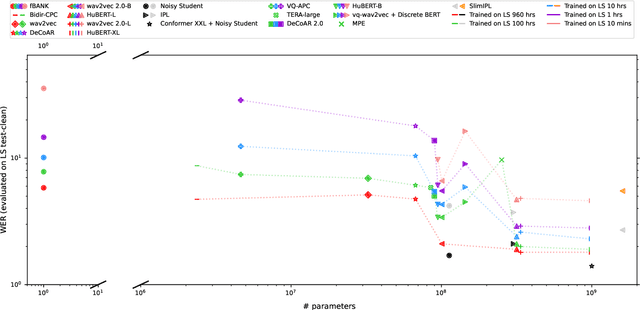
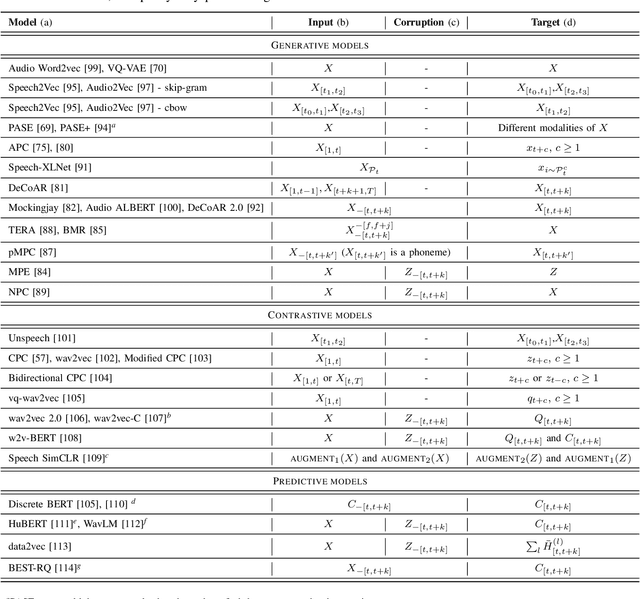
Although supervised deep learning has revolutionized speech and audio processing, it has necessitated the building of specialist models for individual tasks and application scenarios. It is likewise difficult to apply this to dialects and languages for which only limited labeled data is available. Self-supervised representation learning methods promise a single universal model that would benefit a wide variety of tasks and domains. Such methods have shown success in natural language processing and computer vision domains, achieving new levels of performance while reducing the number of labels required for many downstream scenarios. Speech representation learning is experiencing similar progress in three main categories: generative, contrastive, and predictive methods. Other approaches rely on multi-modal data for pre-training, mixing text or visual data streams with speech. Although self-supervised speech representation is still a nascent research area, it is closely related to acoustic word embedding and learning with zero lexical resources, both of which have seen active research for many years. This review presents approaches for self-supervised speech representation learning and their connection to other research areas. Since many current methods focus solely on automatic speech recognition as a downstream task, we review recent efforts on benchmarking learned representations to extend the application beyond speech recognition.
Searching for fingerspelled content in American Sign Language
Mar 24, 2022
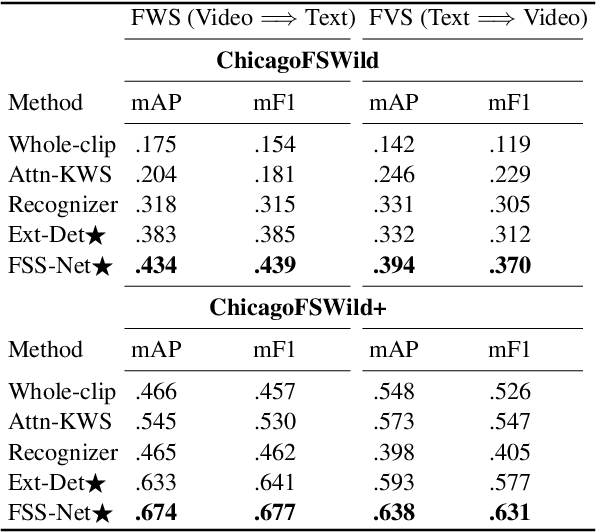
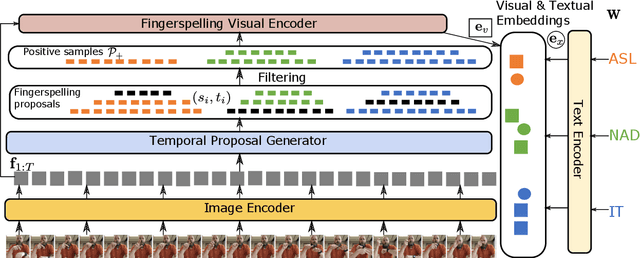
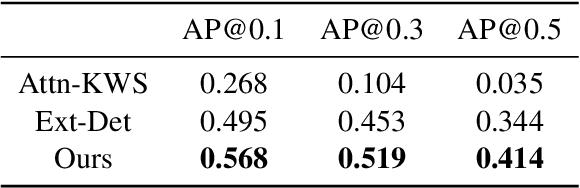
Natural language processing for sign language video - including tasks like recognition, translation, and search - is crucial for making artificial intelligence technologies accessible to deaf individuals, and is gaining research interest in recent years. In this paper, we address the problem of searching for fingerspelled key-words or key phrases in raw sign language videos. This is an important task since significant content in sign language is often conveyed via fingerspelling, and to our knowledge the task has not been studied before. We propose an end-to-end model for this task, FSS-Net, that jointly detects fingerspelling and matches it to a text sequence. Our experiments, done on a large public dataset of ASL fingerspelling in the wild, show the importance of fingerspelling detection as a component of a search and retrieval model. Our model significantly outperforms baseline methods adapted from prior work on related tasks