 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariate-Balancing-Aware Interpretable Deep Learning models for Treatment Effect Estimation
Mar 08, 2022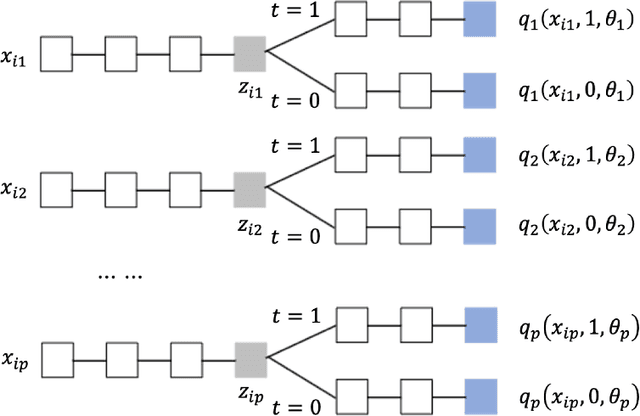

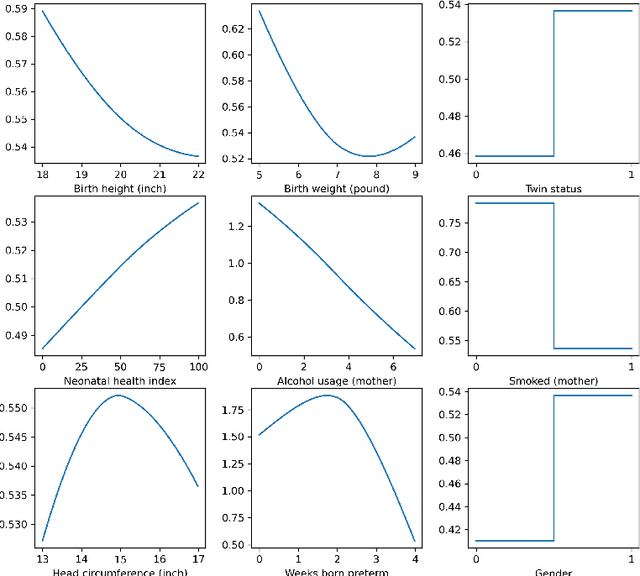
Estimating treatment effects is of great importance for many biomedical applications with observational data. Particularly, interpretability of the treatment effects is preferable for many biomedical researchers. In this paper, we first give a theoretical analysis and propose an upper bound for the bias of average treatment effect estimation under the strong ignorability assumption. The proposed upper bound consists of two parts: training error for factual outcomes, and the distance between treated and control distributions. We use the Weighted Energy Distance (WED) to measure the distance between two distributions. Motivated by the theoretical analysis, we implement this upper bound as an objective function being minimized by leveraging a novel additive neural network architecture, which combines the expressivity of deep neural network, the interpretability of generalized additive model, the sufficiency of the balancing score for estimation adjustment, and covariate balancing properties of treated and control distributions, for estimating average treatment effects from observational data. Furthermore, we impose a so-called weighted regularization procedure based on non-parametric theory, to obtain some desirable asymptotic properties. The proposed method is illustrated by re-examining the benchmark datasets for causal inference, and it outperforms the state-of-art.
MultiPath++: Efficient Information Fusion and Trajectory Aggregation for Behavior Prediction
Dec 22, 2021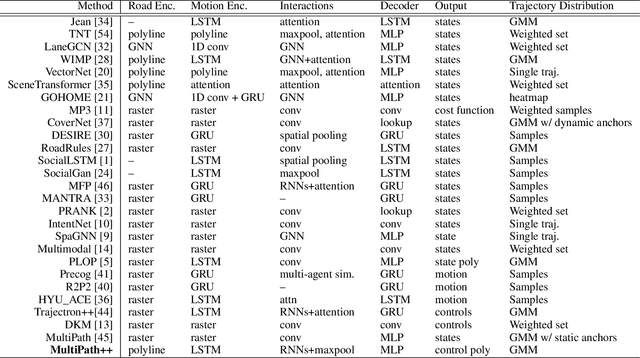
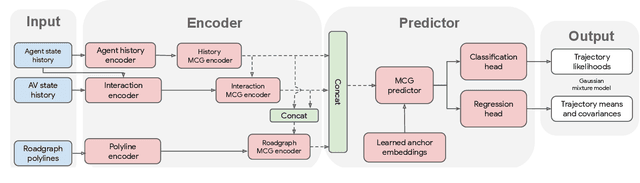
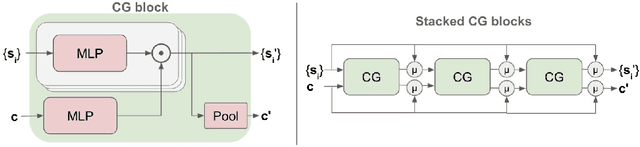
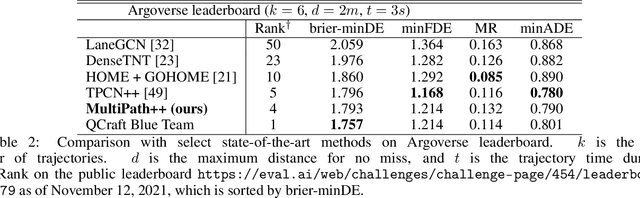
Predicting the future behavior of road users is one of the most challenging and important problems in autonomous driving. Applying deep learning to this problem requires fusing heterogeneous world state in the form of rich perception signals and map information, and inferring highly multi-modal distributions over possible futures. In this paper, we present MultiPath++, a future prediction model that achieves state-of-the-art performance on popular benchmarks. MultiPath++ improves the MultiPath architecture by revisiting many design choices. The first key design difference is a departure from dense image-based encoding of the input world state in favor of a sparse encoding of heterogeneous scene elements: MultiPath++ consumes compact and efficient polylines to describe road features, and raw agent state information directly (e.g., position, velocity, acceleration). We propose a context-aware fusion of these elements and develop a reusable multi-context gating fusion component. Second, we reconsider the choice of pre-defined, static anchors, and develop a way to learn latent anchor embeddings end-to-end in the model. Lastly, we explore ensembling and output aggregation techniques -- common in other ML domains -- and find effective variants for our probabilistic multimodal output representation. We perform an extensive ablation on these design choices, and show that our proposed model achieves state-of-the-art performance on the Argoverse Motion Forecasting Competition and the Waymo Open Dataset Motion Prediction Challenge.
Cross-Domain Object Detection via Adaptive Self-Training
Nov 25, 2021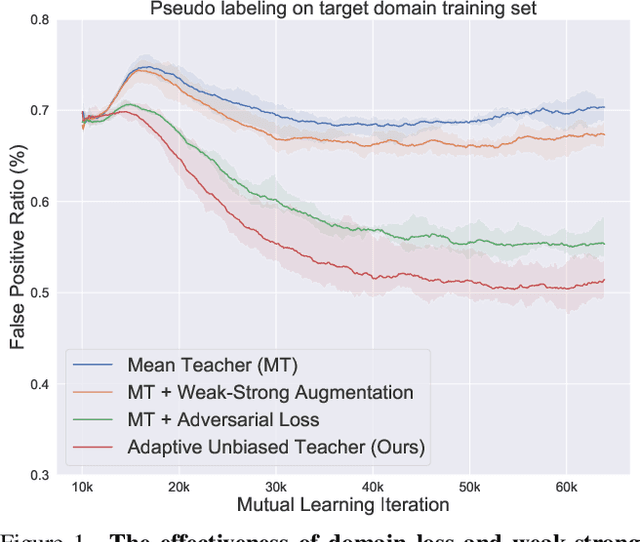
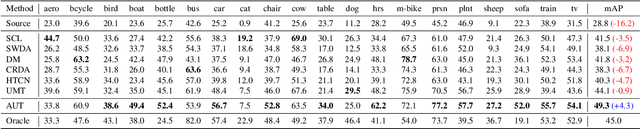
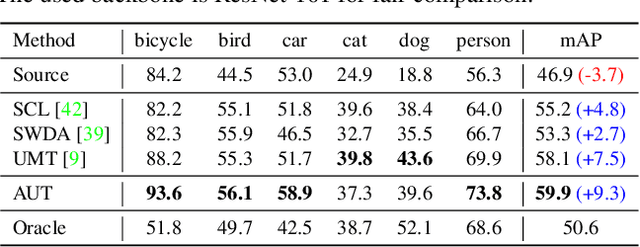
We tackle the problem of domain adaptation in object detection, where there is a significant domain shift between a source (a domain with supervision) and a target domain (a domain of interest without supervision). As a widely adopted domain adaptation method, the self-training teacher-student framework (a student model learns from pseudo labels generated from a teacher model) has yielded remarkable accuracy gain on the target domain. However, it still suffers from the large amount of low-quality pseudo labels (e.g., false positives) generated from the teacher due to its bias toward the source domain. To address this issue, we propose a self-training framework called Adaptive Unbiased Teacher (AUT) leveraging adversarial learning and weak-strong data augmentation during mutual learning to address domain shift. Specifically, we employ feature-level adversarial training in the student model, ensuring features extracted from the source and target domains share similar statistics. This enables the student model to capture domain-invariant features. Furthermore, we apply weak-strong augmentation and mutual learning between the teacher model on the target domain and the student model on both domains. This enables the teacher model to gradually benefit from the student model without suffering domain shift. We show that AUT demonstrates superiority over all existing approaches and even Oracle (fully supervised) models by a large margin. For example, we achieve 50.9% (49.3%) mAP on Foggy Cityscape (Clipart1K), which is 9.2% (5.2%) and 8.2% (11.0%) higher than previous state-of-the-art and Oracle, respectively
Edge of chaos as a guiding principle for modern neural network training
Jul 20, 2021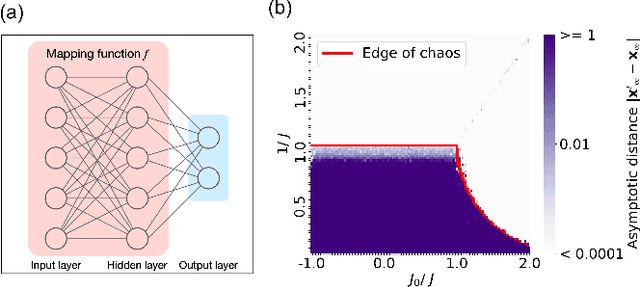
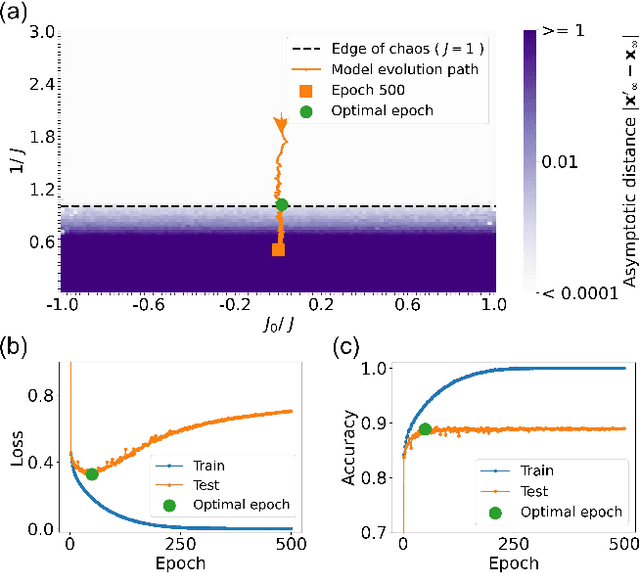
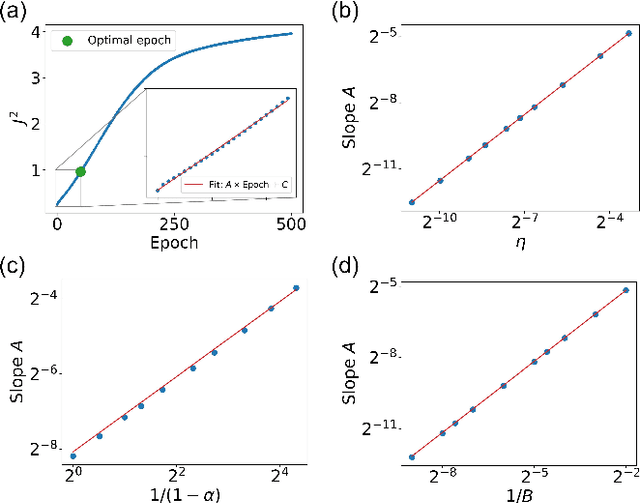
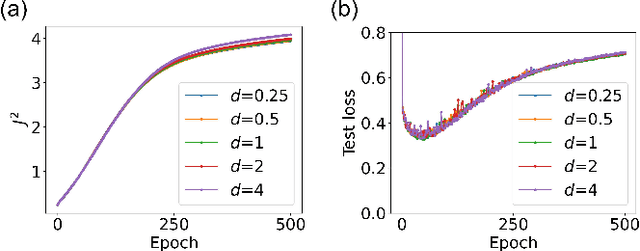
The success of deep neural networks in real-world problems has prompted many attempts to explain their training dynamics and generalization performance, but more guiding principles for the training of neural networks are still needed. Motivated by the edge of chaos principle behind the optimal performance of neural networks, we study the role of various hyperparameters in modern neural network training algorithms in terms of the order-chaos phase diagram. In particular, we study a fully analytical feedforward neural network trained on the widely adopted Fashion-MNIST dataset, and study the dynamics associated with the hyperparameters in back-propagation during the training process. We find that for the basic algorithm of stochastic gradient descent with momentum, in the range around the commonly used hyperparameter values, clear scaling relations are present with respect to the training time during the ordered phase in the phase diagram, and the model's optimal generalization power at the edge of chaos is similar across different training parameter combinations. In the chaotic phase, the same scaling no longer exists. The scaling allows us to choose the training parameters to achieve faster training without sacrificing performance. In addition, we find that the commonly used model regularization method - weight decay - effectively pushes the model towards the ordered phase to achieve better performance. Leveraging on this fact and the scaling relations in the other hyperparameters, we derived a principled guideline for hyperparameter determination, such that the model can achieve optimal performance by saturating it at the edge of chaos. Demonstrated on this simple neural network model and training algorithm, our work improves the understanding of neural network training dynamics, and can potentially be extended to guiding principles of more complex model architectures and algorithms.
Differentially Private Bayesian Neural Networks on Accuracy, Privacy and Reliability
Jul 18, 2021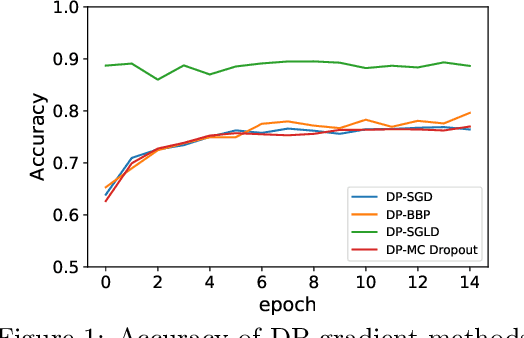
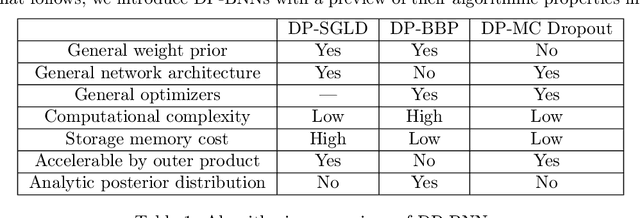
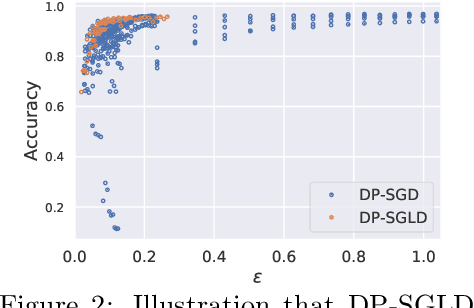
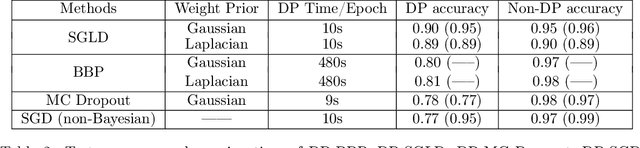
Bayesian neural network (BNN) allows for uncertainty quantification in prediction, offering an advantage over regular neural networks that has not been explored in the differential privacy (DP) framework. We fill this important gap by leveraging recent development in Bayesian deep learning and privacy accounting to offer a more precise analysis of the trade-off between privacy and accuracy in BNN. We propose three DP-BNNs that characterize the weight uncertainty for the same network architecture in distinct ways, namely DP-SGLD (via the noisy gradient method), DP-BBP (via changing the parameters of interest) and DP-MC Dropout (via the model architecture). Interestingly, we show a new equivalence between DP-SGD and DP-SGLD, implying that some non-Bayesian DP training naturally allows for uncertainty quantification. However, the hyperparameters such as learning rate and batch size, can have different or even opposite effects in DP-SGD and DP-SGLD. Extensive experiments are conducted to compare DP-BNNs, in terms of privacy guarantee, prediction accuracy, uncertainty quantification, calibration, computation speed, and generalizability to network architecture. As a result, we observe a new tradeoff between the privacy and the reliability. When compared to non-DP and non-Bayesian approaches, DP-SGLD is remarkably accurate under strong privacy guarantee, demonstrating the great potential of DP-BNN in real-world tasks.
Video Question Answering with Phrases via Semantic Roles
Apr 08, 2021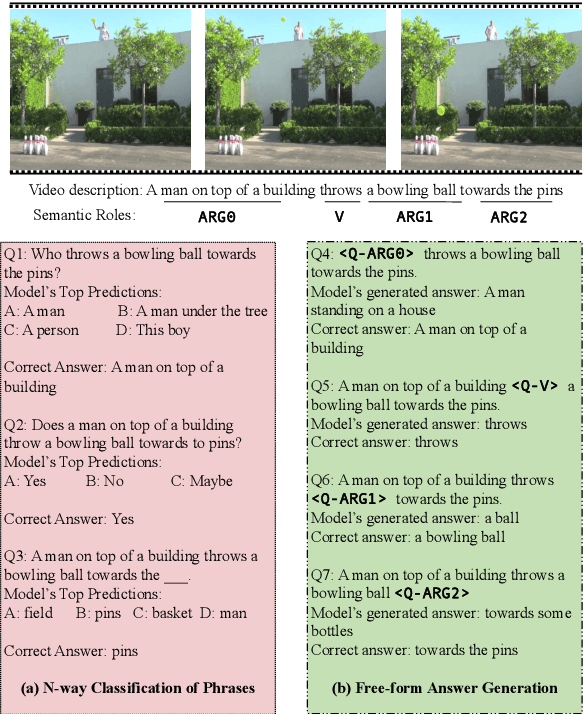
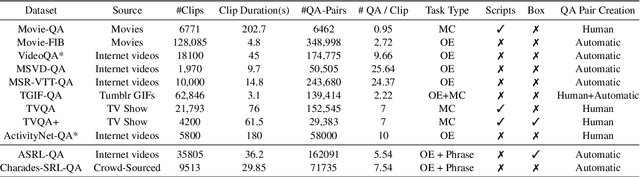
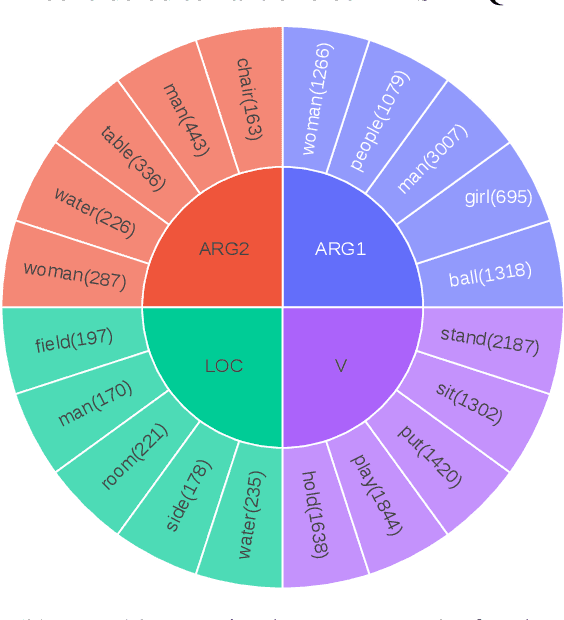
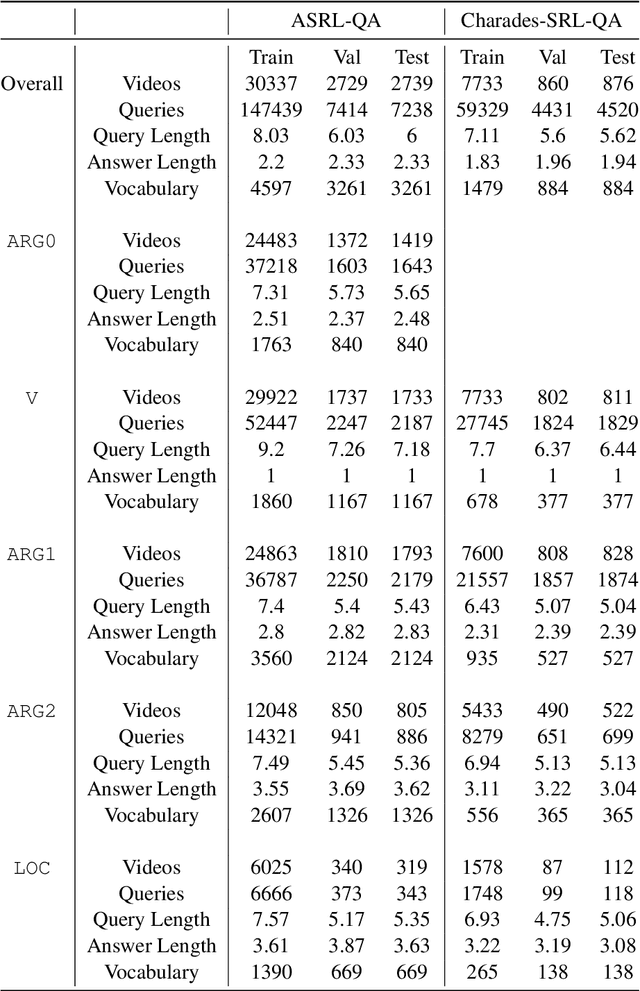
Video Question Answering (VidQA) evaluation metrics have been limited to a single-word answer or selecting a phrase from a fixed set of phrases. These metrics limit the VidQA models' application scenario. In this work, we leverage semantic roles derived from video descriptions to mask out certain phrases, to introduce VidQAP which poses VidQA as a fill-in-the-phrase task. To enable evaluation of answer phrases, we compute the relative improvement of the predicted answer compared to an empty string. To reduce the influence of language bias in VidQA datasets, we retrieve a video having a different answer for the same question. To facilitate research, we construct ActivityNet-SRL-QA and Charades-SRL-QA and benchmark them by extending three vision-language models. We further perform extensive analysis and ablative studies to guide future work.
Unbiased Teacher for Semi-Supervised Object Detection
Feb 18, 2021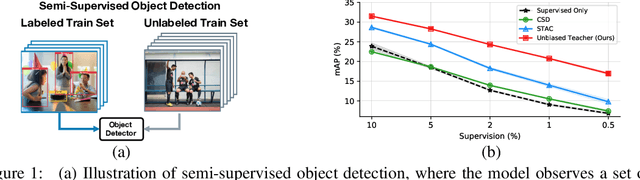

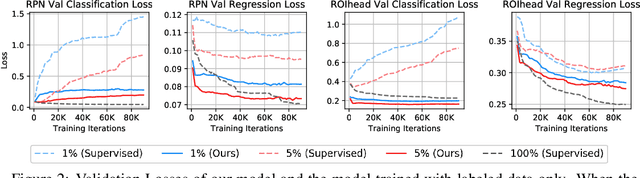
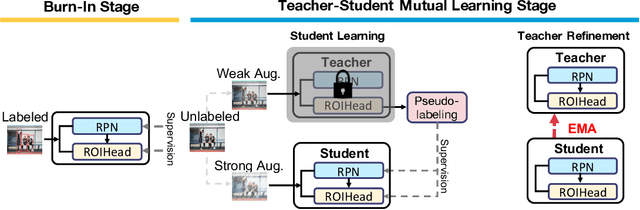
Semi-supervised learning, i.e., training networks with both labeled and unlabeled data, has made significant progress recently. However, existing works have primarily focused on image classification tasks and neglected object detection which requires more annotation effort. In this work, we revisit the Semi-Supervised Object Detection (SS-OD) and identify the pseudo-labeling bias issue in SS-OD. To address this, we introduce Unbiased Teacher, a simple yet effective approach that jointly trains a student and a gradually progressing teacher in a mutually-beneficial manner. Together with a class-balance loss to downweight overly confident pseudo-labels, Unbiased Teacher consistently improved state-of-the-art methods by significant margins on COCO-standard, COCO-additional, and VOC datasets. Specifically, Unbiased Teacher achieves 6.8 absolute mAP improvements against state-of-the-art method when using 1% of labeled data on MS-COCO, achieves around 10 mAP improvements against the supervised baseline when using only 0.5, 1, 2% of labeled data on MS-COCO.
A Dynamical View on Optimization Algorithms of Overparameterized Neural Networks
Oct 25, 2020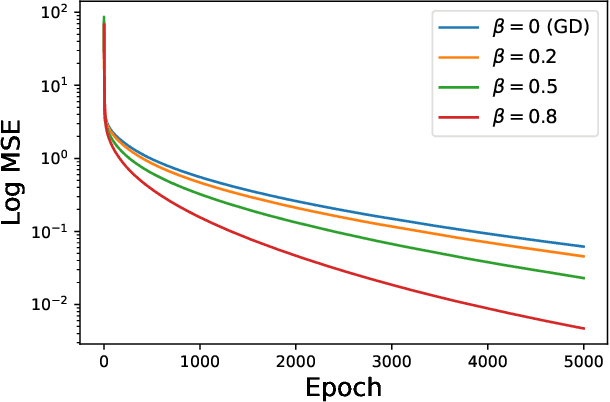
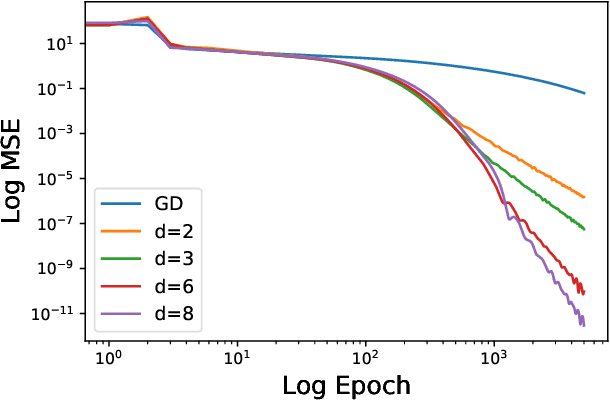
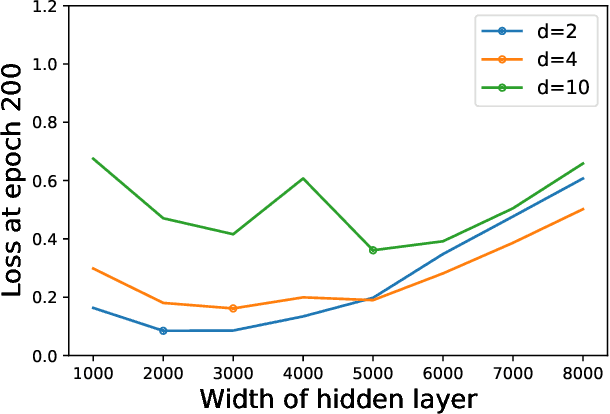
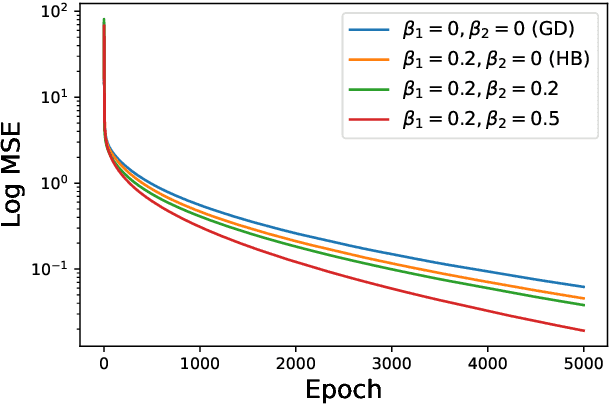
When equipped with efficient optimization algorithms, the over-parameterized neural networks have demonstrated high level of performance even though the loss function is non-convex and non-smooth. While many works have been focusing on understanding the loss dynamics by training neural networks with the gradient descent (GD), in this work, we consider a broad class of optimization algorithms that are commonly used in practice. For example, we show from a dynamical system perspective that the Heavy Ball (HB) method can converge to global minimum on mean squared error (MSE) at a linear rate (similar to GD); however, the Nesterov accelerated gradient descent (NAG) only converges to global minimum sublinearly. Our results rely on the connection between neural tangent kernel (NTK) and finite over-parameterized neural networks with ReLU activation, which leads to analyzing the limiting ordinary differential equations (ODE) for optimization algorithms. We show that, optimizing the non-convex loss over the weights corresponds to optimizing some strongly convex loss over the prediction error. As a consequence, we can leverage the classical convex optimization theory to understand the convergence behavior of neural networks. We believe our approach can also be extended to other loss functions and network architectures.
FBNetV3: Joint Architecture-Recipe Search using Neural Acquisition Function
Jun 07, 2020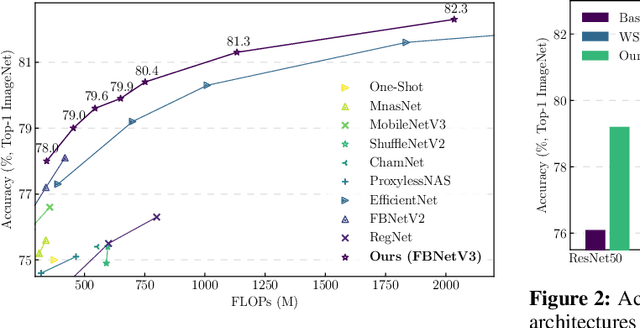
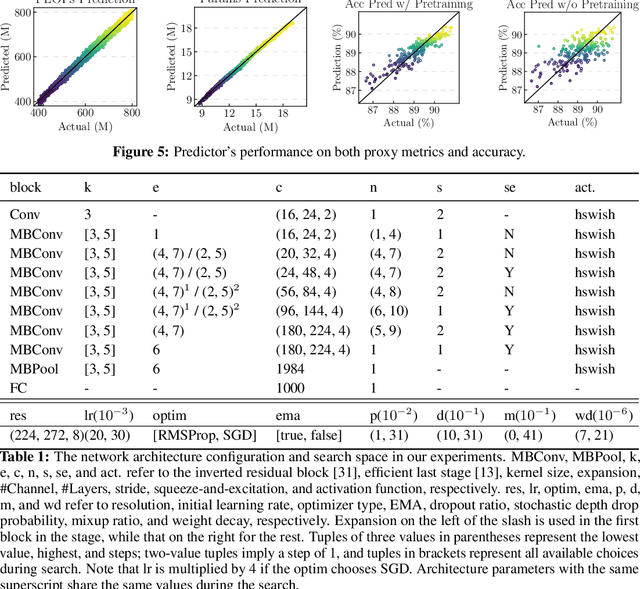
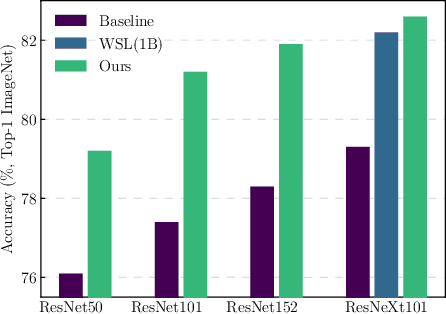

Neural Architecture Search (NAS) yields state-of-the-art neural networks that outperform their best manually-designed counterparts. However, previous NAS methods search for architectures under one training recipe (i.e., training hyperparameters), ignoring the significance of training recipes and overlooking superior architectures under other training recipes. Thus, they fail to find higher-accuracy architecture-recipe combinations. To address this oversight, we present JointNAS to search both (a) architectures and (b) their corresponding training recipes. To accomplish this, we introduce a neural acquisition function that scores architectures and training recipes jointly. Following pre-training on a proxy dataset, this acquisition function guides both coarse-grained and fine-grained searches to produce FBNetV3. FBNetV3 is a family of state-of-the-art compact ImageNet models, outperforming both automatically and manually-designed architectures. For example, FBNetV3 matches both EfficientNet and ResNeSt accuracy with 1.4x and 5.0x fewer FLOPs, respectively. Furthermore, the JointNAS-searched training recipe yields significant performance gains across different networks and tasks.
CPARR: Category-based Proposal Analysis for Referring Relationships
Apr 17, 2020
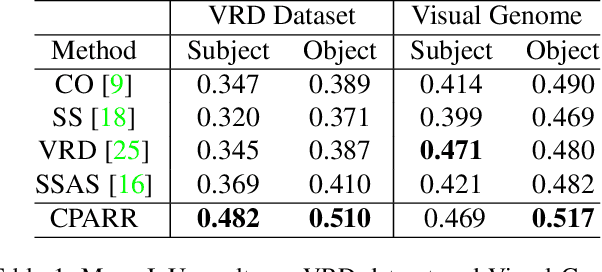
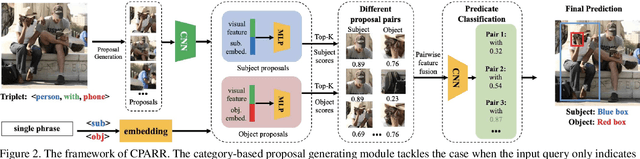
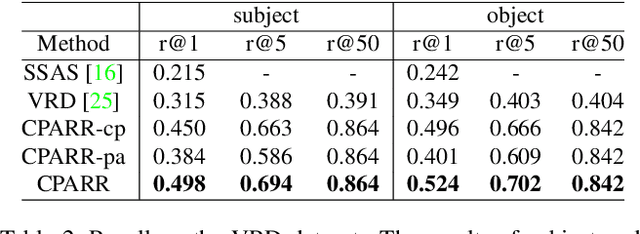
The task of referring relationships is to localize subject and object entities in an image satisfying a relationship query, which is given in the form of \texttt{<subject, predicate, object>}. This requires simultaneous localization of the subject and object entities in a specified relationship. We introduce a simple yet effective proposal-based method for referring relationships. Different from the existing methods such as SSAS, our method can generate a high-resolution result while reducing its complexity and ambiguity. Our method is composed of two modules: a category-based proposal generation module to select the proposals related to the entities and a predicate analysis module to score the compatibility of pairs of selected proposals. We show state-of-the-art performance on the referring relationship task on two public datasets: Visual Relationship Detection and Visual Genome.