 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Pretraining via Active Forgetting for Improving Cross Lingual Transfer for Decoder Language Models
Oct 21, 2024



Large Language Models (LLMs) demonstrate exceptional capabilities in a multitude of NLP tasks. However, the efficacy of such models to languages other than English is often limited. Prior works have shown that encoder-only models such as BERT or XLM-RoBERTa show impressive cross lingual transfer of their capabilities from English to other languages. In this work, we propose a pretraining strategy that uses active forgetting to achieve similar cross lingual transfer in decoder-only LLMs. We show that LLMs pretrained with active forgetting are highly effective when adapting to new and unseen languages. Through extensive experimentation, we find that LLMs pretrained with active forgetting are able to learn better multilingual representations which translates to better performance in many downstream tasks.
Exploring Continual Fine-Tuning for Enhancing Language Ability in Large Language Model
Oct 21, 2024



A common challenge towards the adaptability of Large Language Models (LLMs) is their ability to learn new languages over time without hampering the model's performance on languages in which the model is already proficient (usually English). Continual fine-tuning (CFT) is the process of sequentially fine-tuning an LLM to enable the model to adapt to downstream tasks with varying data distributions and time shifts. This paper focuses on the language adaptability of LLMs through CFT. We study a two-phase CFT process in which an English-only end-to-end fine-tuned LLM from Phase 1 (predominantly Task Ability) is sequentially fine-tuned on a multilingual dataset -- comprising task data in new languages -- in Phase 2 (predominantly Language Ability). We observe that the ``similarity'' of Phase 2 tasks with Phase 1 determines the LLM's adaptability. For similar phase-wise datasets, the LLM after Phase 2 does not show deterioration in task ability. In contrast, when the phase-wise datasets are not similar, the LLM's task ability deteriorates. We test our hypothesis on the open-source \mis\ and \llm\ models with multiple phase-wise dataset pairs. To address the deterioration, we analyze tailored variants of two CFT methods: layer freezing and generative replay. Our findings demonstrate their effectiveness in enhancing the language ability of LLMs while preserving task performance, in comparison to relevant baselines.
Improving Self Consistency in LLMs through Probabilistic Tokenization
Jul 04, 2024



Prior research has demonstrated noticeable performance gains through the use of probabilistic tokenizations, an approach that involves employing multiple tokenizations of the same input string during the training phase of a language model. Despite these promising findings, modern large language models (LLMs) have yet to be trained using probabilistic tokenizations. Interestingly, while the tokenizers of these contemporary LLMs have the capability to generate multiple tokenizations, this property remains underutilized. In this work, we propose a novel method to leverage the multiple tokenization capabilities of modern LLM tokenizers, aiming to enhance the self-consistency of LLMs in reasoning tasks. Our experiments indicate that when utilizing probabilistic tokenizations, LLMs generate logically diverse reasoning paths, moving beyond mere surface-level linguistic diversity.We carefully study probabilistic tokenization and offer insights to explain the self consistency improvements it brings through extensive experimentation on 5 LLM families and 4 reasoning benchmarks.
Sketch-Plan-Generalize: Continual Few-Shot Learning of Inductively Generalizable Spatial Concepts for Language-Guided Robot Manipulation
Apr 11, 2024



Our goal is to build embodied agents that can learn inductively generalizable spatial concepts in a continual manner, e.g, constructing a tower of a given height. Existing work suffers from certain limitations (a) (Liang et al., 2023) and their multi-modal extensions, rely heavily on prior knowledge and are not grounded in the demonstrations (b) (Liu et al., 2023) lack the ability to generalize due to their purely neural approach. A key challenge is to achieve a fine balance between symbolic representations which have the capability to generalize, and neural representations that are physically grounded. In response, we propose a neuro-symbolic approach by expressing inductive concepts as symbolic compositions over grounded neural concepts. Our key insight is to decompose the concept learning problem into the following steps 1) Sketch: Getting a programmatic representation for the given instruction 2) Plan: Perform Model-Based RL over the sequence of grounded neural action concepts to learn a grounded plan 3) Generalize: Abstract out a generic (lifted) Python program to facilitate generalizability. Continual learning is achieved by interspersing learning of grounded neural concepts with higher level symbolic constructs. Our experiments demonstrate that our approach significantly outperforms existing baselines in terms of its ability to learn novel concepts and generalize inductively.
MAPLE: Multilingual Evaluation of Parameter Efficient Finetuning of Large Language Models
Jan 15, 2024



Parameter efficient finetuning has emerged as a viable solution for improving the performance of Large Language Models without requiring massive resources and compute. Prior work on multilingual evaluation has shown that there is a large gap between the performance of LLMs on English and other languages. Further, there is also a large gap between the performance of smaller open-source models and larger LLMs. Finetuning can be an effective way to bridge this gap and make language models more equitable. In this work, we finetune the LLaMA-7B and Mistral-7B models on synthetic multilingual instruction tuning data to determine its effect on model performance on five downstream tasks covering twenty three languages in all. Additionally, we experiment with various parameters, such as rank for low-rank adaptation and values of quantisation to determine their effects on downstream performance and find that higher rank and higher quantisation values benefit low-resource languages. We find that parameter efficient finetuning of smaller open source models sometimes bridges the gap between the performance of these models and the larger ones, however, English performance can take a hit. We also find that finetuning sometimes improves performance on low-resource languages, while degrading performance on high-resource languages.
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Nov 13, 2023Recently, there has been a rapid advancement in research on Large Language Models (LLMs), resulting in significant progress in several Natural Language Processing (NLP) tasks. Consequently, there has been a surge in LLM evaluation research to comprehend the models' capabilities and limitations. However, much of this research has been confined to the English language, leaving LLM building and evaluation for non-English languages relatively unexplored. There has been an introduction of several new LLMs, necessitating their evaluation on non-English languages. This study aims to expand our MEGA benchmarking suite by including six new datasets to form the MEGAVERSE benchmark. The benchmark comprises 22 datasets covering 81 languages, including low-resource African languages. We evaluate several state-of-the-art LLMs like GPT-3.5-Turbo, GPT4, PaLM2, and Llama2 on the MEGAVERSE datasets. Additionally, we include two multimodal datasets in the benchmark and assess the performance of the LLaVa-v1.5 model. Our experiments suggest that GPT4 and PaLM2 outperform the Llama models on various tasks, notably on low-resource languages, with GPT4 outperforming PaLM2 on more datasets than vice versa. However, issues such as data contamination must be addressed to obtain an accurate assessment of LLM performance on non-English languages.
Evaluating Inter-Bilingual Semantic Parsing for Indian Languages
Apr 25, 2023Despite significant progress in Natural Language Generation for Indian languages (IndicNLP), there is a lack of datasets around complex structured tasks such as semantic parsing. One reason for this imminent gap is the complexity of the logical form, which makes English to multilingual translation difficult. The process involves alignment of logical forms, intents and slots with translated unstructured utterance. To address this, we propose an Inter-bilingual Seq2seq Semantic parsing dataset IE-SEMPARSE for 11 distinct Indian languages. We highlight the proposed task's practicality, and evaluate existing multilingual seq2seq models across several train-test strategies. Our experiment reveals a high correlation across performance of original multilingual semantic parsing datasets (such as mTOP, multilingual TOP and multiATIS++) and our proposed IE-SEMPARSE suite.
A Review of Deep Learning Techniques for Protein Function Prediction
Oct 27, 2022



Deep Learning and big data have shown tremendous success in bioinformatics and computational biology in recent years; artificial intelligence methods have also significantly contributed in the task of protein function classification. This review paper analyzes the recent developments in approaches for the task of predicting protein function using deep learning. We explain the importance of determining the protein function and why automating the following task is crucial. Then, after reviewing the widely used deep learning techniques for this task, we continue our review and highlight the emergence of the modern State of The Art (SOTA) deep learning models which have achieved groundbreaking results in the field of computer vision, natural language processing and multi-modal learning in the last few years. We hope that this review will provide a broad view of the current role and advances of deep learning in biological sciences, especially in predicting protein function tasks and encourage new researchers to contribute to this area.
IndicXNLI: Evaluating Multilingual Inference for Indian Languages
Apr 19, 2022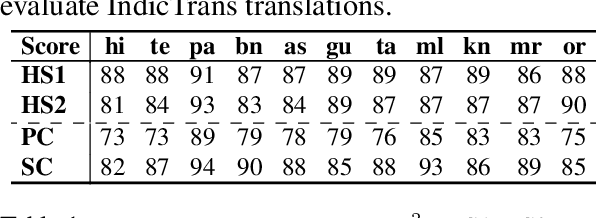
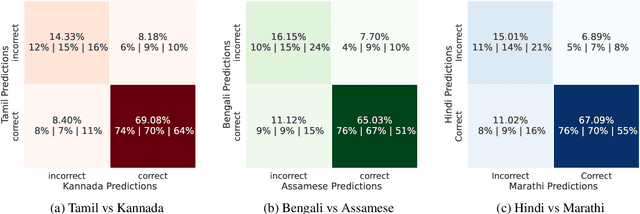
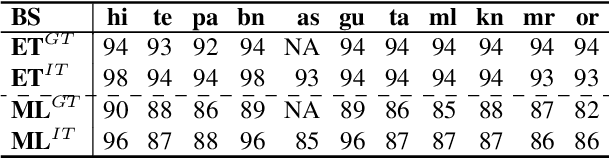
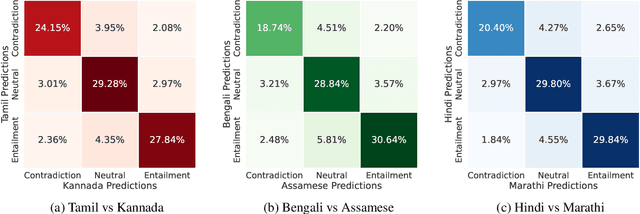
While Indic NLP has made rapid advances recently in terms of the availability of corpora and pre-trained models, benchmark datasets on standard NLU tasks are limited. To this end, we introduce IndicXNLI, an NLI dataset for 11 Indic languages. It has been created by high-quality machine translation of the original English XNLI dataset and our analysis attests to the quality of IndicXNLI. By finetuning different pre-trained LMs on this IndicXNLI, we analyze various cross-lingual transfer techniques with respect to the impact of the choice of language models, languages, multi-linguality, mix-language input, etc. These experiments provide us with useful insights into the behaviour of pre-trained models for a diverse set of languages.