 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKV Cache Offloading for Context-Intensive Tasks
Apr 09, 2026With the growing demand for long-context LLMs across a wide range of applications, the key-value (KV) cache has become a critical bottleneck for both latency and memory usage. Recently, KV-cache offloading has emerged as a promising approach to reduce memory footprint and inference latency while preserving accuracy. Prior evaluations have largely focused on tasks that do not require extracting large amounts of information from the context. In this work, we study KV-cache offloading on context-intensive tasks: problems where the solution requires looking up a lot of information from the input prompt. We create and release the Text2JSON benchmark, a highly context-intensive task that requires extracting structured knowledge from raw text. We evaluate modern KV offloading on Text2JSON and other context-intensive tasks and find significant performance degradation on both Llama 3 and Qwen 3 models. Our analysis identifies two key reasons for poor accuracy: low-rank projection of keys and unreliable landmarks, and proposes a simpler alternative strategy that significantly improves accuracy across multiple LLM families and benchmarks. These findings highlight the need for a comprehensive and rigorous evaluation of long-context compression techniques.
Asynchronous Reasoning: Training-Free Interactive Thinking LLMs
Dec 11, 2025Many state-of-the-art LLMs are trained to think before giving their answer. Reasoning can greatly improve language model capabilities and safety, but it also makes them less interactive: given a new input, a model must stop thinking before it can respond. Real-world use cases such as voice-based or embedded assistants require an LLM agent to respond and adapt to additional information in real time, which is incompatible with sequential interactions. In contrast, humans can listen, think, and act asynchronously: we begin thinking about the problem while reading it and continue thinking while formulating the answer. In this work, we augment LLMs capable of reasoning to operate in a similar way without additional training. Our method uses the properties of rotary embeddings to enable LLMs built for sequential interactions to simultaneously think, listen, and generate outputs. We evaluate our approach on math, commonsense, and safety reasoning and find that it can generate accurate thinking-augmented answers in real time, reducing time to first non-thinking token from minutes to <= 5s. and the overall real-time delays by 6-11x.
Hogwild! Inference: Parallel LLM Generation via Concurrent Attention
Apr 09, 2025



Large Language Models (LLMs) have demonstrated the ability to tackle increasingly complex tasks through advanced reasoning, long-form content generation, and tool use. Solving these tasks often involves long inference-time computations. In human problem solving, a common strategy to expedite work is collaboration: by dividing the problem into sub-tasks, exploring different strategies concurrently, etc. Recent research has shown that LLMs can also operate in parallel by implementing explicit cooperation frameworks, such as voting mechanisms or the explicit creation of independent sub-tasks that can be executed in parallel. However, each of these frameworks may not be suitable for all types of tasks, which can hinder their applicability. In this work, we propose a different design approach: we run LLM "workers" in parallel , allowing them to synchronize via a concurrently-updated attention cache and prompt these workers to decide how best to collaborate. Our approach allows the instances to come up with their own collaboration strategy for the problem at hand, all the while "seeing" each other's partial progress in the concurrent cache. We implement this approach via Hogwild! Inference: a parallel LLM inference engine where multiple instances of the same LLM run in parallel with the same attention cache, with "instant" access to each other's generated tokens. Hogwild! inference takes advantage of Rotary Position Embeddings (RoPE) to avoid recomputation while improving parallel hardware utilization. We find that modern reasoning-capable LLMs can perform inference with shared Key-Value cache out of the box, without additional fine-tuning.
Scale-wise Distillation of Diffusion Models
Mar 20, 2025



We present SwD, a scale-wise distillation framework for diffusion models (DMs), which effectively employs next-scale prediction ideas for diffusion-based few-step generators. In more detail, SwD is inspired by the recent insights relating diffusion processes to the implicit spectral autoregression. We suppose that DMs can initiate generation at lower data resolutions and gradually upscale the samples at each denoising step without loss in performance while significantly reducing computational costs. SwD naturally integrates this idea into existing diffusion distillation methods based on distribution matching. Also, we enrich the family of distribution matching approaches by introducing a novel patch loss enforcing finer-grained similarity to the target distribution. When applied to state-of-the-art text-to-image diffusion models, SwD approaches the inference times of two full resolution steps and significantly outperforms the counterparts under the same computation budget, as evidenced by automated metrics and human preference studies.
Cache Me If You Must: Adaptive Key-Value Quantization for Large Language Models
Jan 31, 2025Efficient real-world deployments of large language models (LLMs) rely on Key-Value (KV) caching for processing and generating long outputs, reducing the need for repetitive computation. For large contexts, Key-Value caches can take up tens of gigabytes of device memory, as they store vector representations for each token and layer. Recent work has shown that the cached vectors can be compressed through quantization, pruning or merging, but these techniques often compromise quality towards higher compression rates. In this work, we aim to improve Key & Value compression by exploiting two observations: 1) the inherent dependencies between keys and values across different layers, and 2) high-compression mechanisms for internal network states. We propose AQUA-KV, an adaptive quantization for Key-Value caches that relies on compact adapters to exploit existing dependencies between Keys and Values, and aims to "optimally" compress the information that cannot be predicted. AQUA-KV significantly improves compression rates, while maintaining high accuracy on state-of-the-art LLM families. On Llama 3.2 LLMs, we achieve near-lossless inference at 2-2.5 bits per value with under $1\%$ relative error in perplexity and LongBench scores. AQUA-KV is one-shot, simple, and efficient: it can be calibrated on a single GPU within 1-6 hours, even for 70B models.
Label Privacy in Split Learning for Large Models with Parameter-Efficient Training
Dec 21, 2024As deep learning models become larger and more expensive, many practitioners turn to fine-tuning APIs. These web services allow fine-tuning a model between two parties: the client that provides the data, and the server that hosts the model. While convenient, these APIs raise a new concern: the data of the client is at risk of privacy breach during the training procedure. This challenge presents an important practical case of vertical federated learning, where the two parties perform parameter-efficient fine-tuning (PEFT) of a large model. In this study, we systematically search for a way to fine-tune models over an API while keeping the labels private. We analyze the privacy of LoRA, a popular approach for parameter-efficient fine-tuning when training over an API. Using this analysis, we propose P$^3$EFT, a multi-party split learning algorithm that takes advantage of existing PEFT properties to maintain privacy at a lower performance overhead. To validate our algorithm, we fine-tune DeBERTa-v2-XXLarge, Flan-T5 Large and LLaMA-2 7B using LoRA adapters on a range of NLP tasks. We find that P$^3$EFT is competitive with existing privacy-preserving methods in multi-party and two-party setups while having higher accuracy.
Switti: Designing Scale-Wise Transformers for Text-to-Image Synthesis
Dec 03, 2024



This work presents Switti, a scale-wise transformer for text-to-image generation. Starting from existing next-scale prediction AR models, we first explore them for T2I generation and propose architectural modifications to improve their convergence and overall performance. We then observe that self-attention maps of our pretrained scale-wise AR model exhibit weak dependence on preceding scales. Based on this insight, we propose a non-AR counterpart facilitating ~11% faster sampling and lower memory usage while also achieving slightly better generation quality. Furthermore, we reveal that classifier-free guidance at high-resolution scales is often unnecessary and can even degrade performance. By disabling guidance at these scales, we achieve an additional sampling acceleration of ~20% and improve the generation of fine-grained details. Extensive human preference studies and automated evaluations show that Switti outperforms existing T2I AR models and competes with state-of-the-art T2I diffusion models while being up to 7 times faster.
EvoPress: Towards Optimal Dynamic Model Compression via Evolutionary Search
Oct 18, 2024



The high computational costs of large language models (LLMs) have led to a flurry of research on LLM compression, via methods such as quantization, sparsification, or structured pruning. A new frontier in this area is given by \emph{dynamic, non-uniform} compression methods, which adjust the compression levels (e.g., sparsity) per-block or even per-layer in order to minimize accuracy loss, while guaranteeing a global compression threshold. Yet, current methods rely on heuristics for identifying the "importance" of a given layer towards the loss, based on assumptions such as \emph{error monotonicity}, i.e. that the end-to-end model compression error is proportional to the sum of layer-wise errors. In this paper, we revisit this area, and propose a new and general approach for dynamic compression that is provably optimal in a given input range. We begin from the motivating observation that, in general, \emph{error monotonicity does not hold for LLMs}: compressed models with lower sum of per-layer errors can perform \emph{worse} than models with higher error sums. To address this, we propose a new general evolutionary framework for dynamic LLM compression called EvoPress, which has provable convergence, and low sample and evaluation complexity. We show that these theoretical guarantees lead to highly competitive practical performance for dynamic compression of Llama, Mistral and Phi models. Via EvoPress, we set new state-of-the-art results across all compression approaches: structural pruning (block/layer dropping), unstructured sparsity, as well as quantization with dynamic bitwidths. Our code is available at https://github.com/IST-DASLab/EvoPress.
Accurate Compression of Text-to-Image Diffusion Models via Vector Quantization
Aug 31, 2024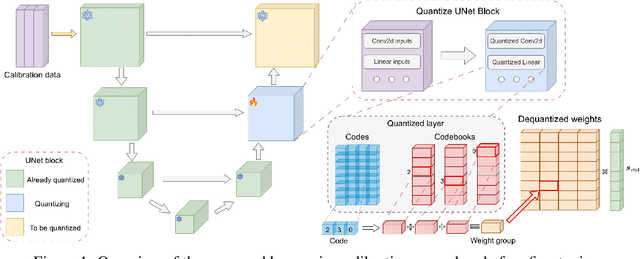
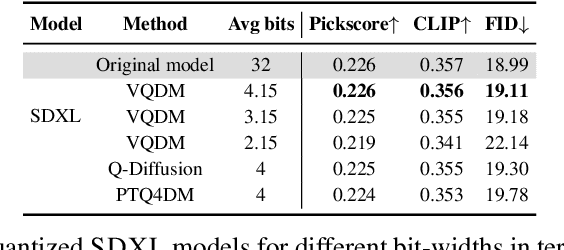


Text-to-image diffusion models have emerged as a powerful framework for high-quality image generation given textual prompts. Their success has driven the rapid development of production-grade diffusion models that consistently increase in size and already contain billions of parameters. As a result, state-of-the-art text-to-image models are becoming less accessible in practice, especially in resource-limited environments. Post-training quantization (PTQ) tackles this issue by compressing the pretrained model weights into lower-bit representations. Recent diffusion quantization techniques primarily rely on uniform scalar quantization, providing decent performance for the models compressed to 4 bits. This work demonstrates that more versatile vector quantization (VQ) may achieve higher compression rates for large-scale text-to-image diffusion models. Specifically, we tailor vector-based PTQ methods to recent billion-scale text-to-image models (SDXL and SDXL-Turbo), and show that the diffusion models of 2B+ parameters compressed to around 3 bits using VQ exhibit the similar image quality and textual alignment as previous 4-bit compression techniques.
The Iterative Optimal Brain Surgeon: Faster Sparse Recovery by Leveraging Second-Order Information
Aug 30, 2024The rising footprint of machine learning has led to a focus on imposing \emph{model sparsity} as a means of reducing computational and memory costs. For deep neural networks (DNNs), the state-of-the-art accuracy-vs-sparsity is achieved by heuristics inspired by the classical Optimal Brain Surgeon (OBS) framework~\citep{lecun90brain, hassibi1992second, hassibi1993optimal}, which leverages loss curvature information to make better pruning decisions. Yet, these results still lack a solid theoretical understanding, and it is unclear whether they can be improved by leveraging connections to the wealth of work on sparse recovery algorithms. In this paper, we draw new connections between these two areas and present new sparse recovery algorithms inspired by the OBS framework that comes with theoretical guarantees under reasonable assumptions and have strong practical performance. Specifically, our work starts from the observation that we can leverage curvature information in OBS-like fashion upon the projection step of classic iterative sparse recovery algorithms such as IHT. We show for the first time that this leads both to improved convergence bounds under standard assumptions. Furthermore, we present extensions of this approach to the practical task of obtaining accurate sparse DNNs, and validate it experimentally at scale for Transformer-based models on vision and language tasks.