 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDNet: Unified Listener Dependent Modeling in MOS Prediction for Synthetic Speech
Oct 18, 2021
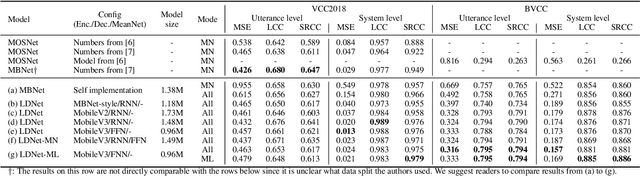
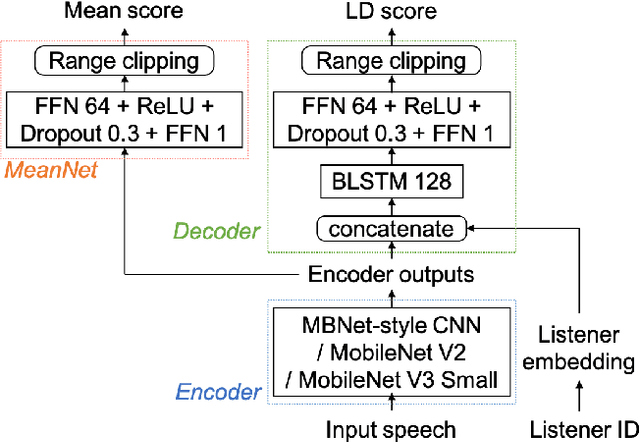
An effective approach to automatically predict the subjective rating for synthetic speech is to train on a listening test dataset with human-annotated scores. Although each speech sample in the dataset is rated by several listeners, most previous works only used the mean score as the training target. In this work, we present LDNet, a unified framework for mean opinion score (MOS) prediction that predicts the listener-wise perceived quality given the input speech and the listener identity. We reflect recent advances in LD modeling, including design choices of the model architecture, and propose two inference methods that provide more stable results and efficient computation. We conduct systematic experiments on the voice conversion challenge (VCC) 2018 benchmark and a newly collected large-scale MOS dataset, providing an in-depth analysis of the proposed framework. Results show that the mean listener inference method is a better way to utilize the mean scores, whose effectiveness is more obvious when having more ratings per sample.
Generalization Ability of MOS Prediction Networks
Oct 18, 2021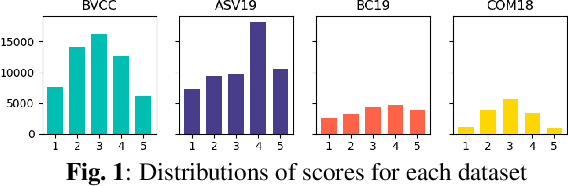
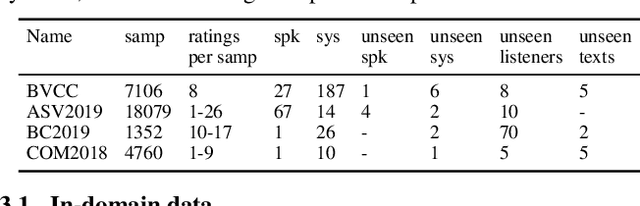
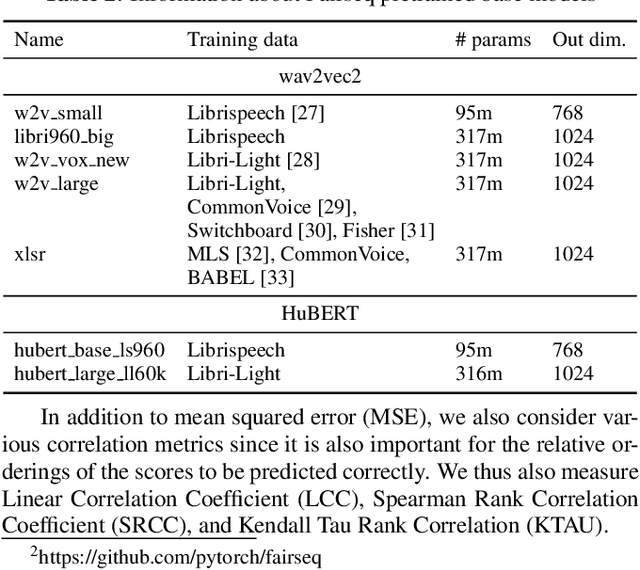
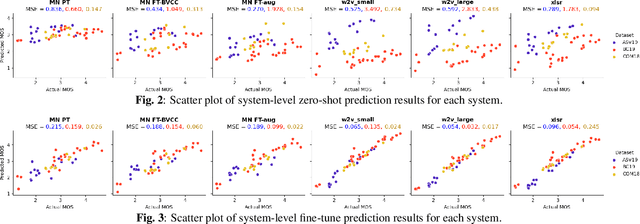
Automatic methods to predict listener opinions of synthesized speech remain elusive since listeners, systems being evaluated, characteristics of the speech, and even the instructions given and the rating scale all vary from test to test. While automatic predictors for metrics such as mean opinion score (MOS) can achieve high prediction accuracy on samples from the same test, they typically fail to generalize well to new listening test contexts. In this paper, using a variety of networks for MOS prediction including MOSNet and self-supervised speech models such as wav2vec2, we investigate their performance on data from different listening tests in both zero-shot and fine-tuned settings. We find that wav2vec2 models fine-tuned for MOS prediction have good generalization capability to out-of-domain data even for the most challenging case of utterance-level predictions in the zero-shot setting, and that fine-tuning to in-domain data can improve predictions. We also observe that unseen systems are especially challenging for MOS prediction models.
Revisiting Speech Content Privacy
Oct 13, 2021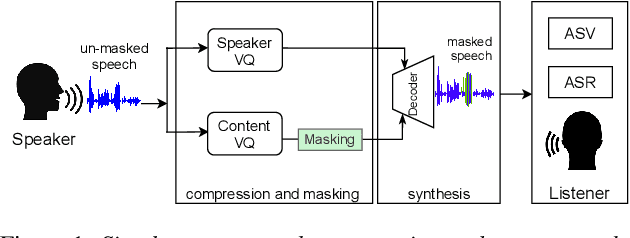
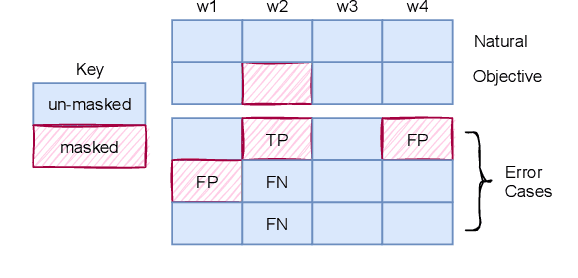
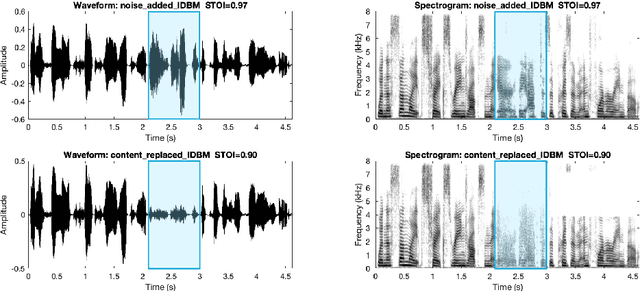
In this paper, we discuss an important aspect of speech privacy: protecting spoken content. New capabilities from the field of machine learning provide a unique and timely opportunity to revisit speech content protection. There are many different applications of content privacy, even though this area has been under-explored in speech technology research. This paper presents several scenarios that indicate a need for speech content privacy even as the specific techniques to achieve content privacy may necessarily vary. Our discussion includes several different types of content privacy including recoverable and non-recoverable content. Finally, we introduce evaluation strategies as well as describe some of the difficulties that may be encountered.
LaughNet: synthesizing laughter utterances from waveform silhouettes and a single laughter example
Oct 11, 2021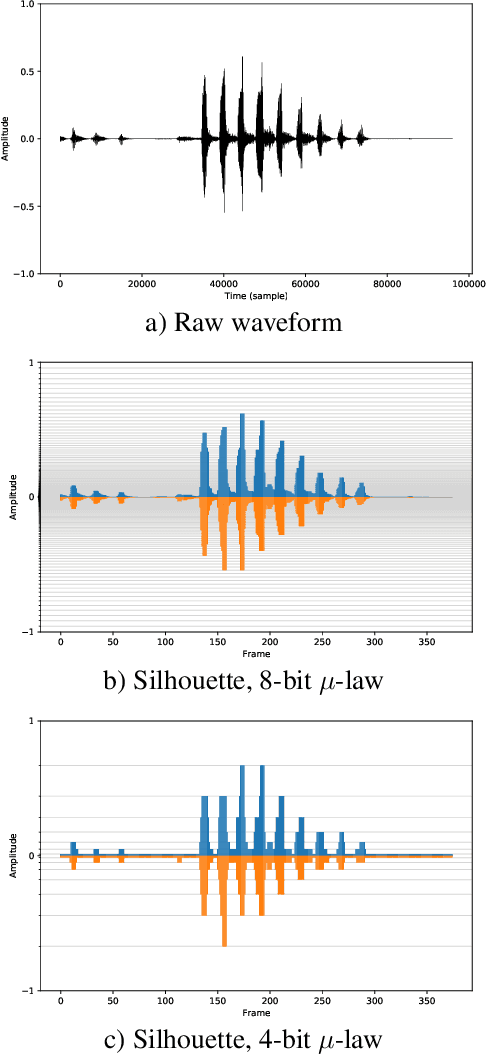
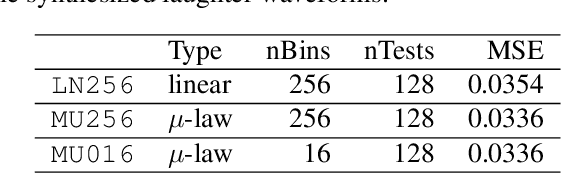
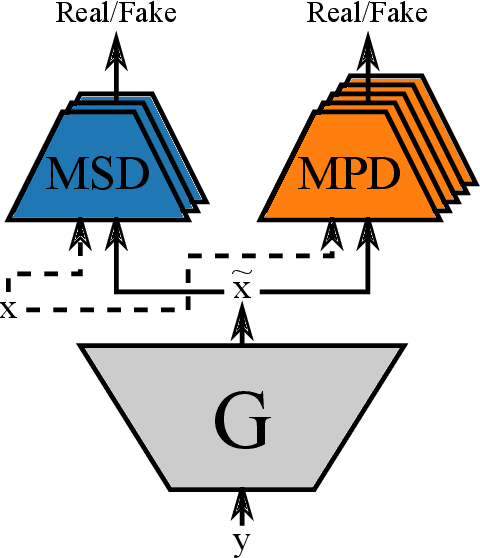
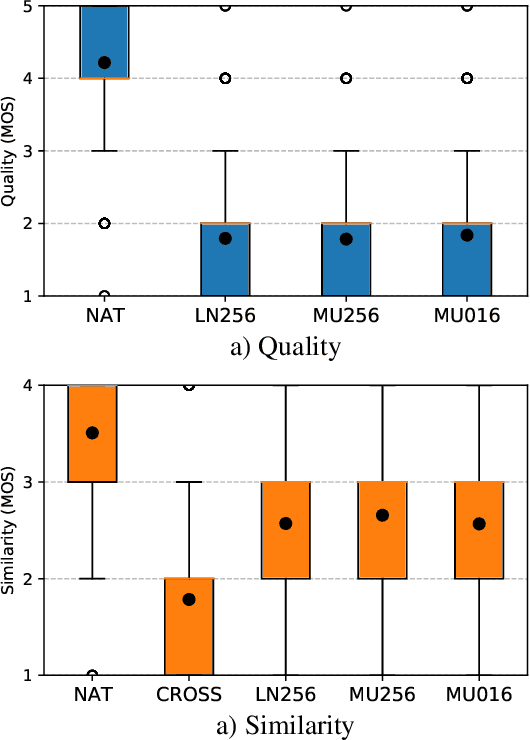
Emotional and controllable speech synthesis is a topic that has received much attention. However, most studies focused on improving the expressiveness and controllability in the context of linguistic content, even though natural verbal human communication is inseparable from spontaneous non-speech expressions such as laughter, crying, or grunting. We propose a model called LaughNet for synthesizing laughter by using waveform silhouettes as inputs. The motivation is not simply synthesizing new laughter utterances but testing a novel synthesis-control paradigm that uses an abstract representation of the waveform. We conducted basic listening test experiments, and the results showed that LaughNet can synthesize laughter utterances with moderate quality and retain the characteristics of the training example. More importantly, the generated waveforms have shapes similar to the input silhouettes. For future work, we will test the same method on other types of human nonverbal expressions and integrate it into more elaborated synthesis systems.
Estimating the confidence of speech spoofing countermeasure
Oct 10, 2021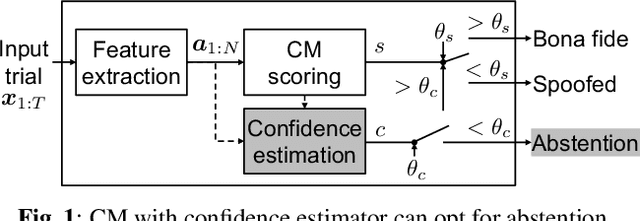

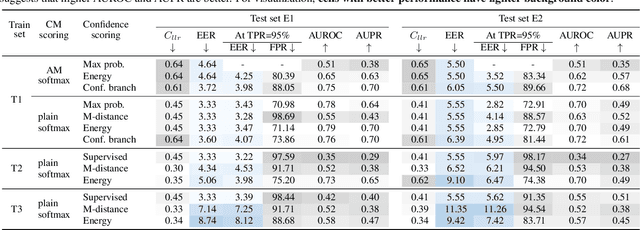
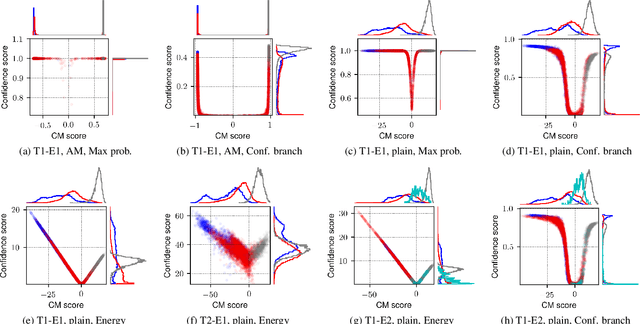
Conventional speech spoofing countermeasures (CMs) are designed to make a binary decision on an input trial. However, a CM trained on a closed-set database is theoretically not guaranteed to perform well on unknown spoofing attacks. In some scenarios, an alternative strategy is to let the CM defer a decision when it is not confident. The question is then how to estimate a CM's confidence regarding an input trial. We investigated a few confidence estimators that can be easily plugged into a CM. On the ASVspoof2019 logical access database, the results demonstrate that an energy-based estimator and a neural-network-based one achieved acceptable performance in identifying unknown attacks in the test set. On a test set with additional unknown attacks and bona fide trials from other databases, the confidence estimators performed moderately well, and the CMs better discriminated bona fide and spoofed trials that had a high confidence score. Additional results also revealed the difficulty in enhancing a confidence estimator by adding unknown attacks to the training set.
On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis
Oct 04, 2021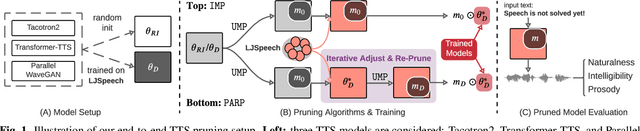
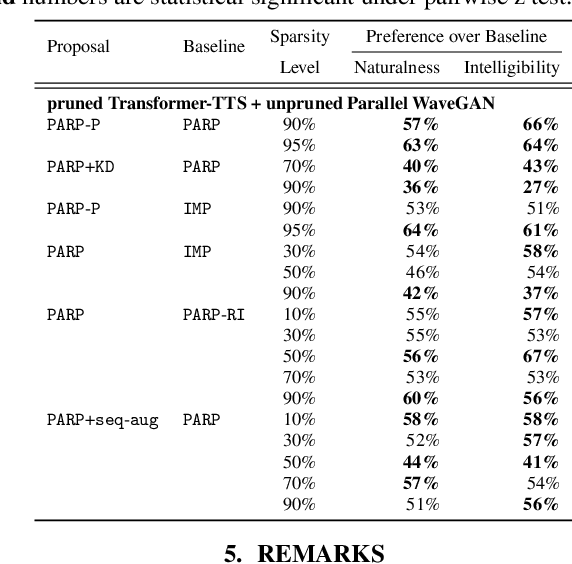
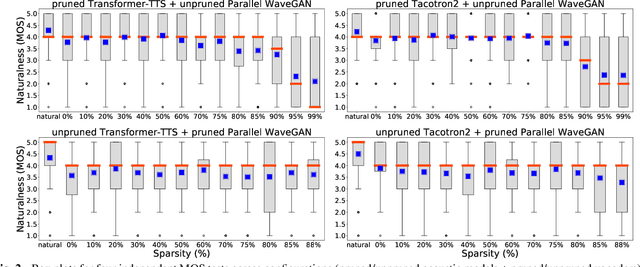
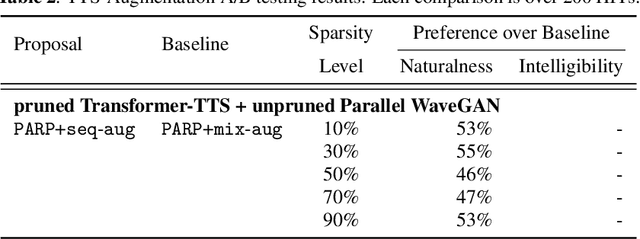
Are end-to-end text-to-speech (TTS) models over-parametrized? To what extent can these models be pruned, and what happens to their synthesis capabilities? This work serves as a starting point to explore pruning both spectrogram prediction networks and vocoders. We thoroughly investigate the tradeoffs between sparstiy and its subsequent effects on synthetic speech. Additionally, we explored several aspects of TTS pruning: amount of finetuning data versus sparsity, TTS-Augmentation to utilize unspoken text, and combining knowledge distillation and pruning. Our findings suggest that not only are end-to-end TTS models highly prunable, but also, perhaps surprisingly, pruned TTS models can produce synthetic speech with equal or higher naturalness and intelligibility, with similar prosody. All of our experiments are conducted on publicly available models, and findings in this work are backed by large-scale subjective tests and objective measures. Code and 200 pruned models are made available to facilitate future research on efficiency in TTS.
DDS: A new device-degraded speech dataset for speech enhancement
Sep 28, 2021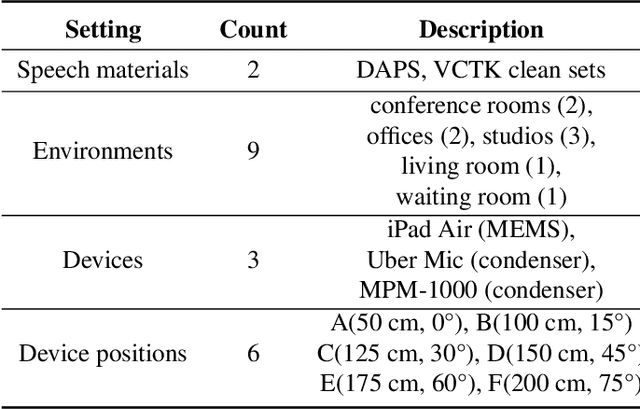
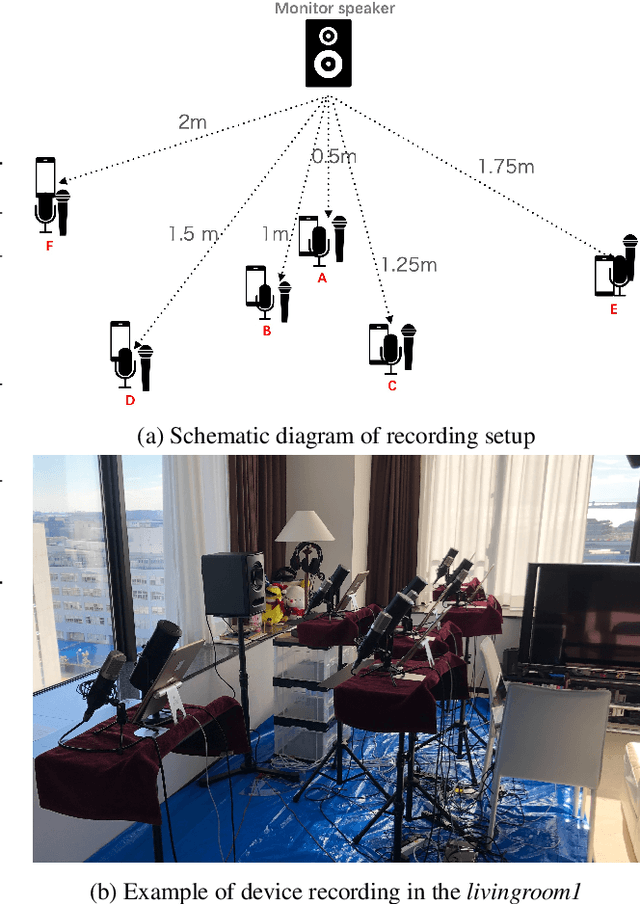
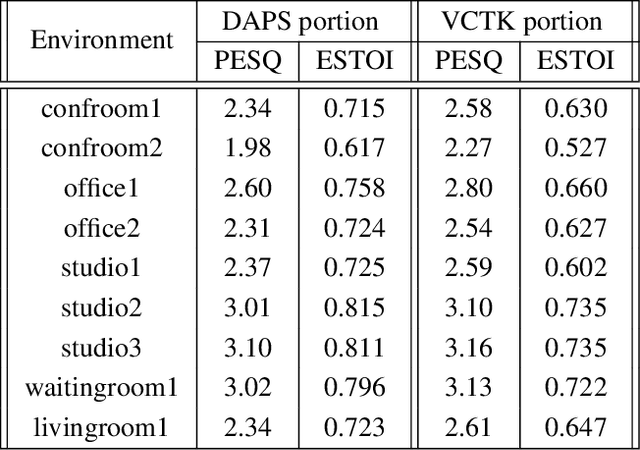
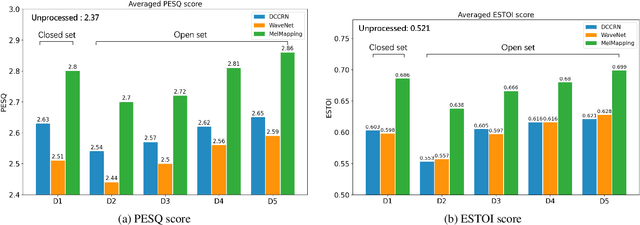
A large and growing amount of speech content in real-life scenarios is being recorded on common consumer devices in uncontrolled environments, resulting in degraded speech quality. Transforming such low-quality device-degraded speech into high-quality speech is a goal of speech enhancement (SE). This paper introduces a new speech dataset, DDS, to facilitate the research on SE. DDS provides aligned parallel recordings of high-quality speech (recorded in professional studios) and a number of versions of low-quality speech, producing approximately 2,000 hours speech data. The DDS dataset covers 27 realistic recording conditions by combining diverse acoustic environments and microphone devices, and each version of a condition consists of multiple recordings from six different microphone positions to simulate various signal-to-noise ratio (SNR) and reverberation levels. We also test several SE baseline systems on the DDS dataset and show the impact of recording diversity on performance.
Master Face Attacks on Face Recognition Systems
Sep 08, 2021
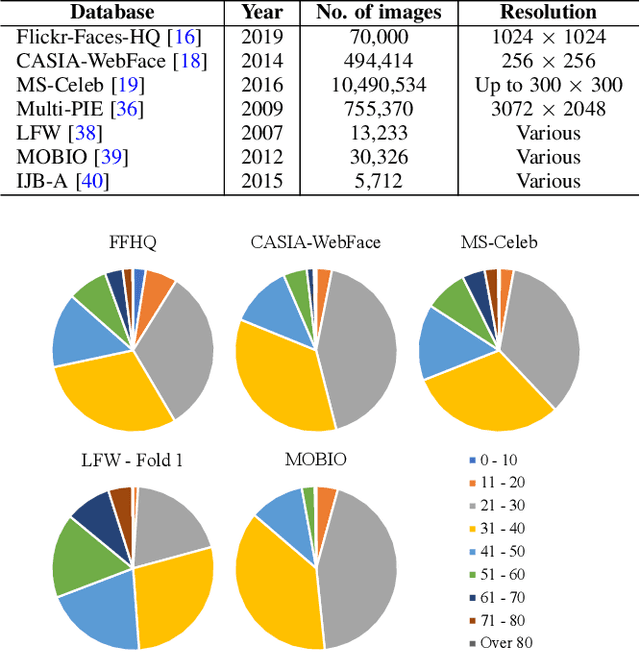
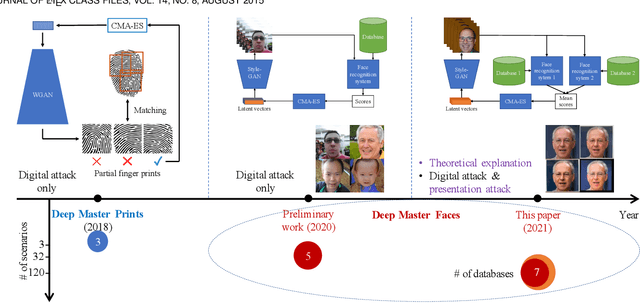

Face authentication is now widely used, especially on mobile devices, rather than authentication using a personal identification number or an unlock pattern, due to its convenience. It has thus become a tempting target for attackers using a presentation attack. Traditional presentation attacks use facial images or videos of the victim. Previous work has proven the existence of master faces, i.e., faces that match multiple enrolled templates in face recognition systems, and their existence extends the ability of presentation attacks. In this paper, we perform an extensive study on latent variable evolution (LVE), a method commonly used to generate master faces. We run an LVE algorithm for various scenarios and with more than one database and/or face recognition system to study the properties of the master faces and to understand in which conditions strong master faces could be generated. Moreover, through analysis, we hypothesize that master faces come from some dense areas in the embedding spaces of the face recognition systems. Last but not least, simulated presentation attacks using generated master faces generally preserve the false-matching ability of their original digital forms, thus demonstrating that the existence of master faces poses an actual threat.
The VoicePrivacy 2020 Challenge: Results and findings
Sep 01, 2021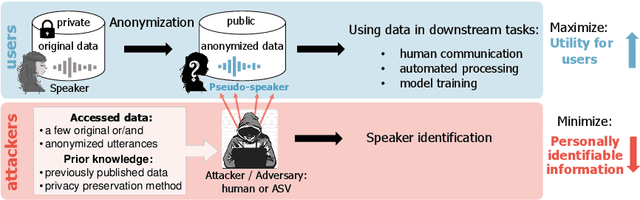
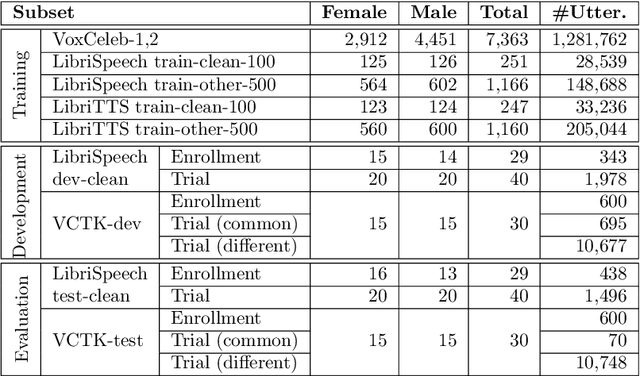
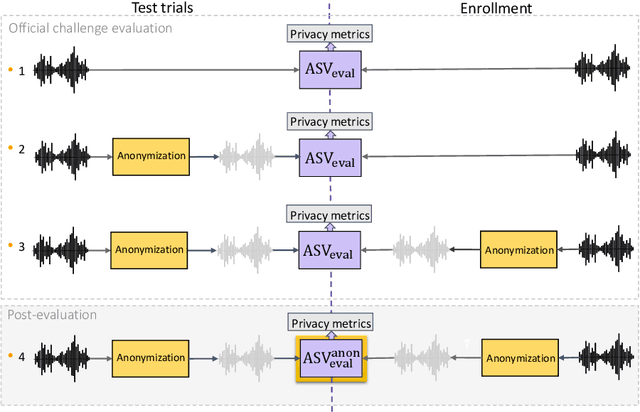
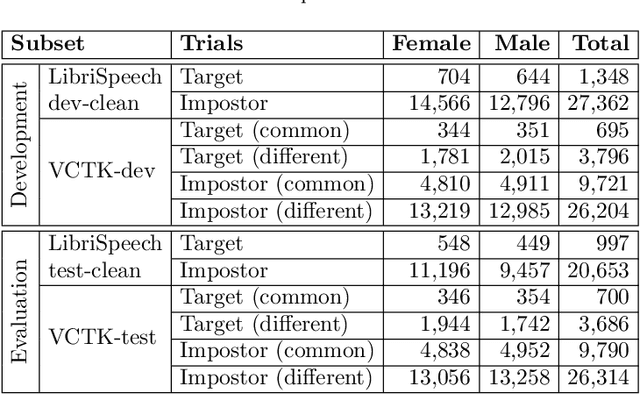
This paper presents the results and analyses stemming from the first VoicePrivacy 2020 Challenge which focuses on developing anonymization solutions for speech technology. We provide a systematic overview of the challenge design with an analysis of submitted systems and evaluation results. In particular, we describe the voice anonymization task and datasets used for system development and evaluation. Also, we present different attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and provide a summary description of the anonymization systems developed by the challenge participants. We report objective and subjective evaluation results for baseline and submitted systems. In addition, we present experimental results for alternative privacy metrics and attack models developed as a part of the post-evaluation analysis. Finally, we summarize our insights and observations that will influence the design of the next VoicePrivacy challenge edition and some directions for future voice anonymization research.
ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection
Sep 01, 2021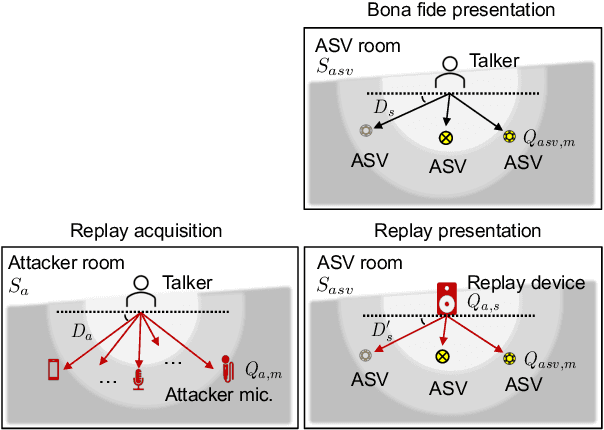
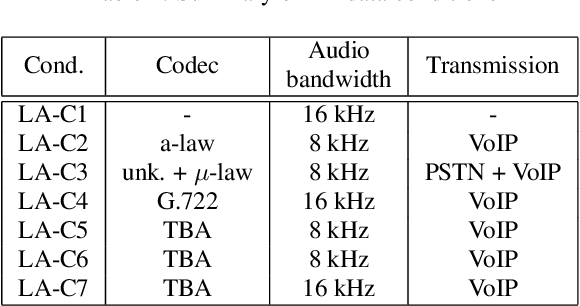
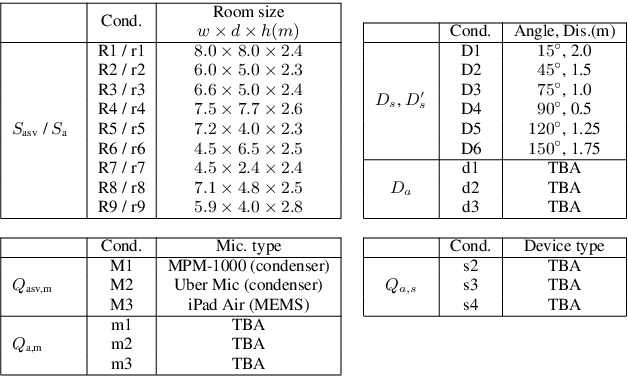
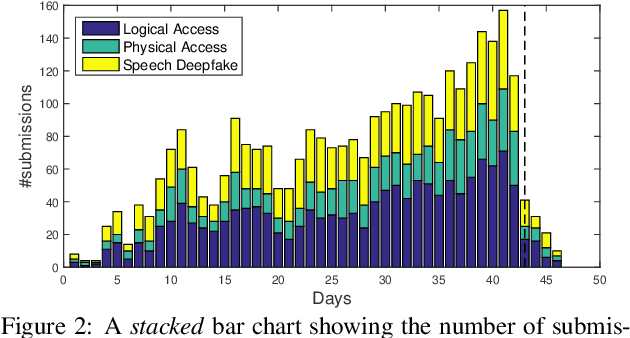
ASVspoof 2021 is the forth edition in the series of bi-annual challenges which aim to promote the study of spoofing and the design of countermeasures to protect automatic speaker verification systems from manipulation. In addition to a continued focus upon logical and physical access tasks in which there are a number of advances compared to previous editions, ASVspoof 2021 introduces a new task involving deepfake speech detection. This paper describes all three tasks, the new databases for each of them, the evaluation metrics, four challenge baselines, the evaluation platform and a summary of challenge results. Despite the introduction of channel and compression variability which compound the difficulty, results for the logical access and deepfake tasks are close to those from previous ASVspoof editions. Results for the physical access task show the difficulty in detecting attacks in real, variable physical spaces. With ASVspoof 2021 being the first edition for which participants were not provided with any matched training or development data and with this reflecting real conditions in which the nature of spoofed and deepfake speech can never be predicated with confidence, the results are extremely encouraging and demonstrate the substantial progress made in the field in recent years.