 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers
May 17, 2020
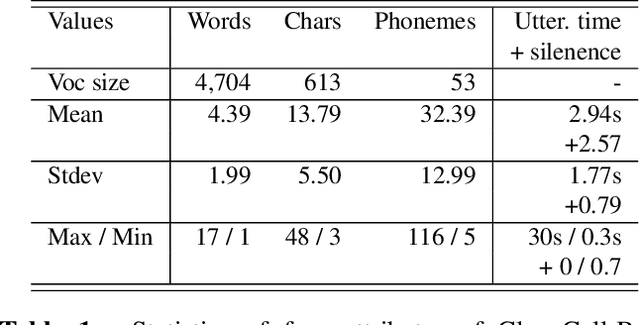
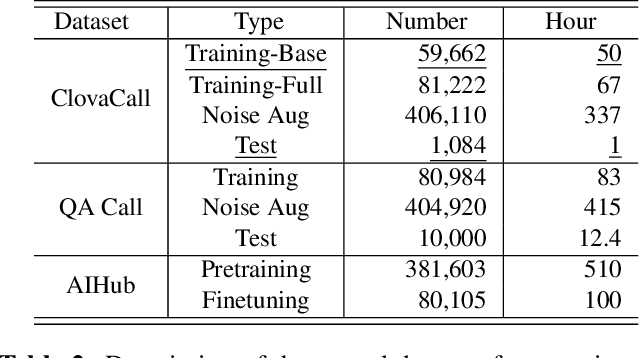
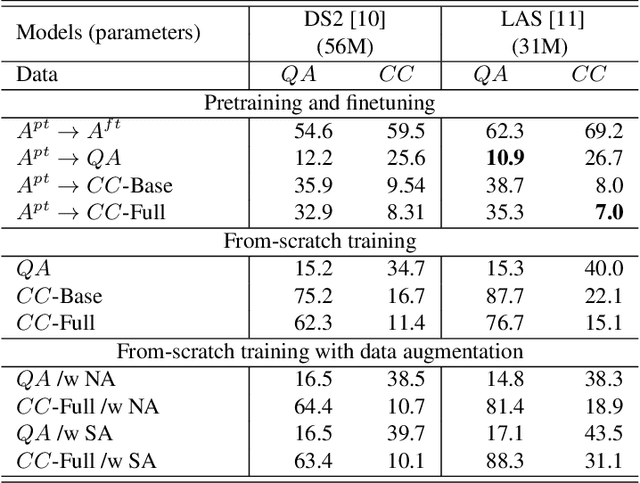
Automatic speech recognition (ASR) via call is essential for various applications, including AI for contact center (AICC) services. Despite the advancement of ASR, however, most publicly available call-based speech corpora such as Switchboard are old-fashioned. Also, most existing call corpora are in English and mainly focus on open domain dialog or general scenarios such as audiobooks. Here we introduce a new large-scale Korean call-based speech corpus under a goal-oriented dialog scenario from more than 11,000 people, i.e., ClovaCall corpus. ClovaCall includes approximately 60,000 pairs of a short sentence and its corresponding spoken utterance in a restaurant reservation domain. We validate the effectiveness of our dataset with intensive experiments using two standard ASR models. Furthermore, we release our ClovaCall dataset and baseline source codes to be available via https://github.com/ClovaAI/ClovaCall.
Modeling Musical Onset Probabilities via Neural Distribution Learning
Feb 10, 2020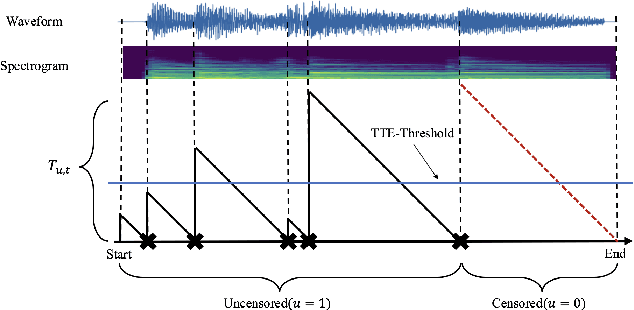

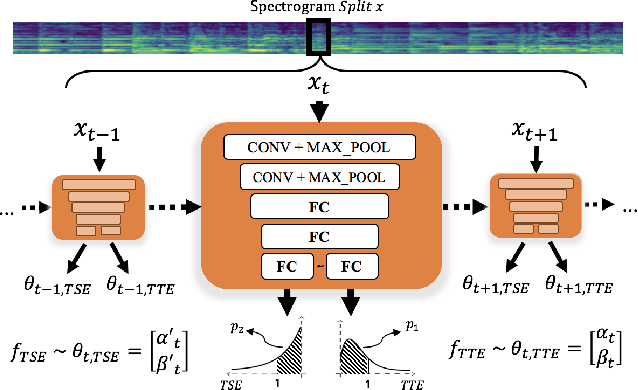
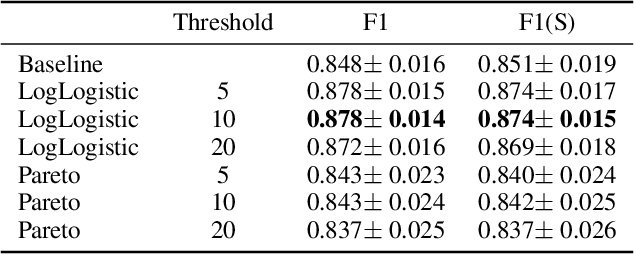
Musical onset detection can be formulated as a time-to-event (TTE) or time-since-event (TSE) prediction task by defining music as a sequence of onset events. Here we propose a novel method to model the probability of onsets by introducing a sequential density prediction model. The proposed model estimates TTE & TSE distributions from mel-spectrograms using convolutional neural networks (CNNs) as a density predictor. We evaluate our model on the Bock dataset show-ing comparable results to previous deep-learning models.
StarGAN v2: Diverse Image Synthesis for Multiple Domains
Dec 04, 2019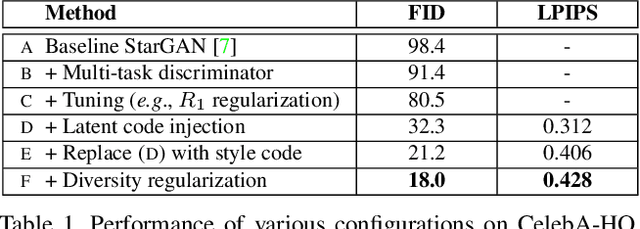
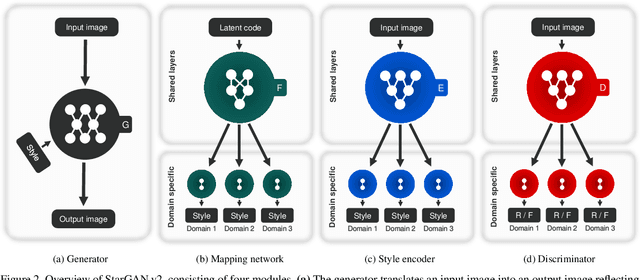
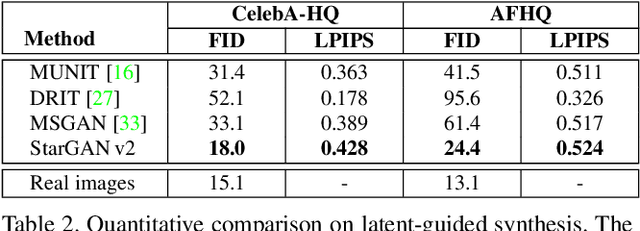
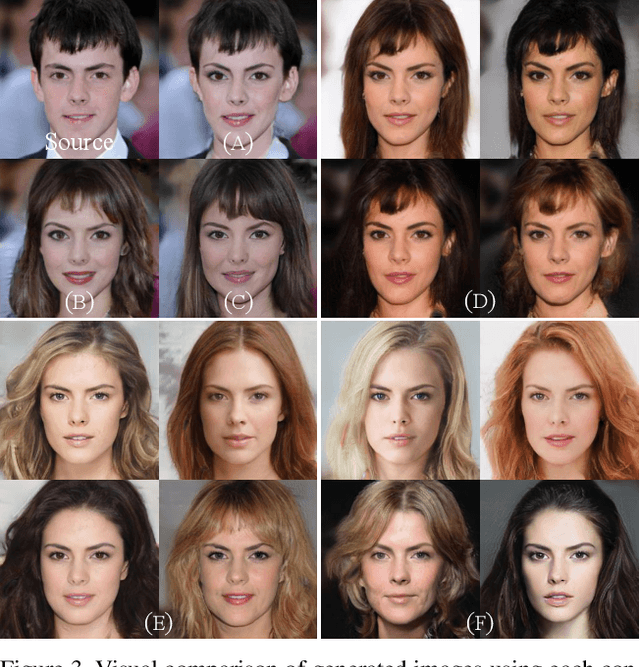
A good image-to-image translation model should learn a mapping between different visual domains while satisfying the following properties: 1) diversity of generated images and 2) scalability over multiple domains. Existing methods address either of the issues, having limited diversity or multiple models for all domains. We propose StarGAN v2, a single framework that tackles both and shows significantly improved results over the baselines. Experiments on CelebA-HQ and a new animal faces dataset (AFHQ) validate our superiority in terms of visual quality, diversity, and scalability. To better assess image-to-image translation models, we release AFHQ, high-quality animal faces with large inter- and intra-domain differences. The code, pretrained models, and dataset can be found at https://github.com/clovaai/stargan-v2.
Neural Approximation of an Auto-Regressive Process through Confidence Guided Sampling
Oct 15, 2019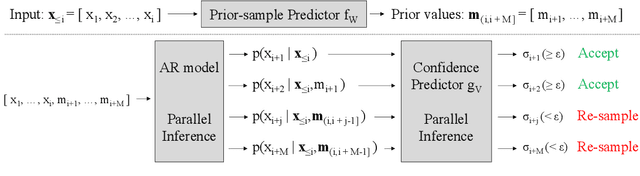

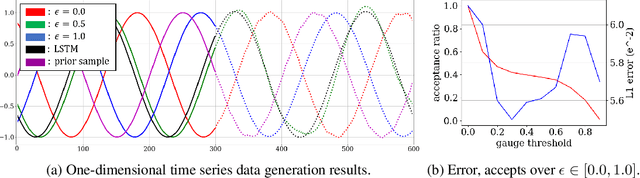
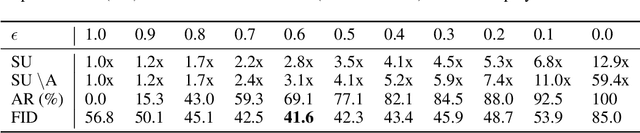
We propose a generic confidence-based approximation that can be plugged in and simplify the auto-regressive generation process with a proved convergence. We first assume that the priors of future samples can be generated in an independently and identically distributed (i.i.d.) manner using an efficient predictor. Given the past samples and future priors, the mother AR model can post-process the priors while the accompanied confidence predictor decides whether the current sample needs a resampling or not. Thanks to the i.i.d. assumption, the post-processing can update each sample in a parallel way, which remarkably accelerates the mother model. Our experiments on different data domains including sequences and images show that the proposed method can successfully capture the complex structures of the data and generate the meaningful future samples with lower computational cost while preserving the sequential relationship of the data.
Which Ads to Show? Advertisement Image Assessment with Auxiliary Information via Multi-step Modality Fusion
Oct 06, 2019
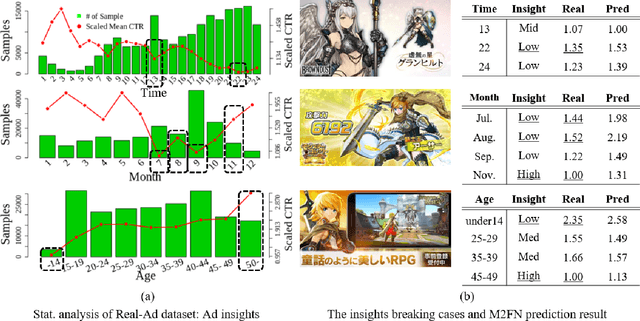
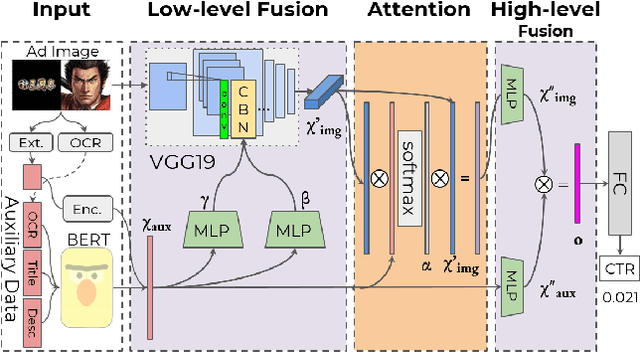
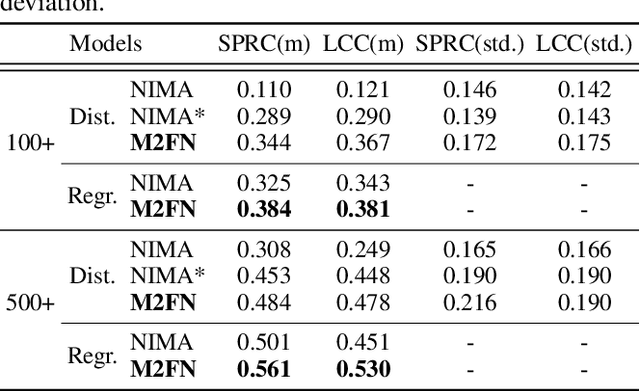
Assessing aesthetic preference is a fundamental task related to human cognition. It can also contribute to various practical applications such as image creation for online advertisements. Despite crucial influences of image quality, auxiliary information of ad images such as tags and target subjects can also determine image preference. Existing studies mainly focus on images and thus are less useful for advertisement scenarios where rich auxiliary data are available. Here we propose a modality fusion-based neural network that evaluates the aesthetic preference of images with auxiliary information. Our method fully utilizes auxiliary data by introducing multi-step modality fusion using both conditional batch normalization-based low-level and attention-based high-level fusion mechanisms, inspired by the findings from statistical analyses on real advertisement data. Our approach achieved state-of-the-art performance on the AVA dataset, a widely used dataset for aesthetic assessment. Besides, the proposed method is evaluated on large-scale real-world advertisement image data with rich auxiliary attributes, providing promising preference prediction results. Through extensive experiments, we investigate how image and auxiliary information together influence click-through rate.
Tripartite Heterogeneous Graph Propagation for Large-scale Social Recommendation
Jul 24, 2019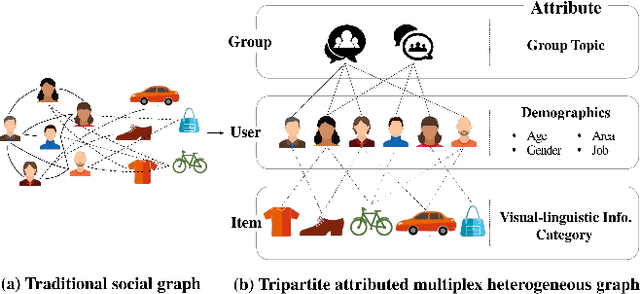
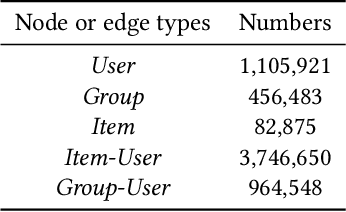
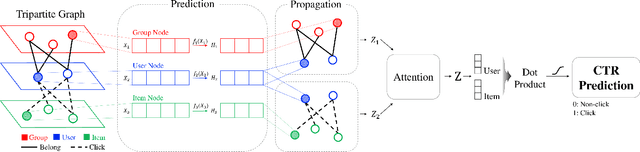
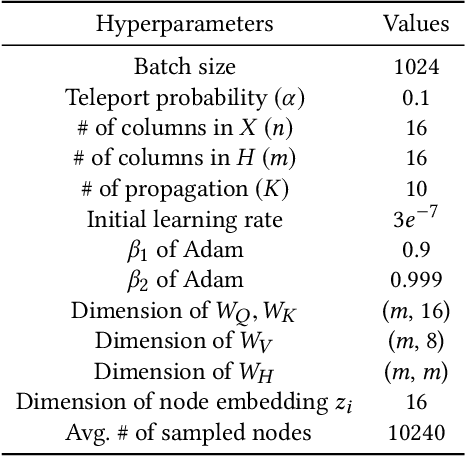
Graph Neural Networks (GNNs) have been emerging as a promising method for relational representation including recommender systems. However, various challenging issues of social graphs hinder the practical usage of GNNs for social recommendation, such as their complex noisy connections and high heterogeneity. The oversmoothing of GNNs is an obstacle of GNN-based social recommendation as well. Here we propose a new graph embedding method Heterogeneous Graph Propagation (HGP) to tackle these issues. HGP uses a group-user-item tripartite graph as input to reduce the number of edges and the complexity of paths in a social graph. To solve the oversmoothing issue, HGP embeds nodes under a personalized PageRank based propagation scheme, separately for group-user graph and user-item graph. Node embeddings from each graph are integrated using an attention mechanism. We evaluate our HGP on a large-scale real-world dataset consisting of 1,645,279 nodes and 4,711,208 edges. The experimental results show that HGP outperforms several baselines in terms of AUC and F1-score metrics.
Phase-aware Speech Enhancement with Deep Complex U-Net
Apr 02, 2019
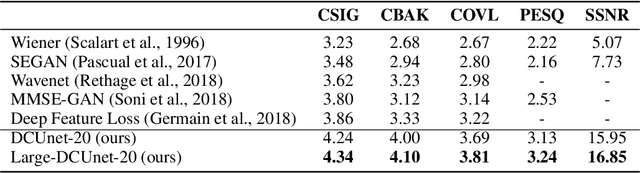

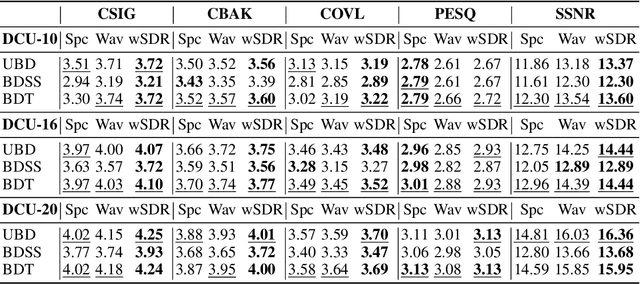
Most deep learning-based models for speech enhancement have mainly focused on estimating the magnitude of spectrogram while reusing the phase from noisy speech for reconstruction. This is due to the difficulty of estimating the phase of clean speech. To improve speech enhancement performance, we tackle the phase estimation problem in three ways. First, we propose Deep Complex U-Net, an advanced U-Net structured model incorporating well-defined complex-valued building blocks to deal with complex-valued spectrograms. Second, we propose a polar coordinate-wise complex-valued masking method to reflect the distribution of complex ideal ratio masks. Third, we define a novel loss function, weighted source-to-distortion ratio (wSDR) loss, which is designed to directly correlate with a quantitative evaluation measure. Our model was evaluated on a mixture of the Voice Bank corpus and DEMAND database, which has been widely used by many deep learning models for speech enhancement. Ablation experiments were conducted on the mixed dataset showing that all three proposed approaches are empirically valid. Experimental results show that the proposed method achieves state-of-the-art performance in all metrics, outperforming previous approaches by a large margin.
Photorealistic Style Transfer via Wavelet Transforms
Mar 23, 2019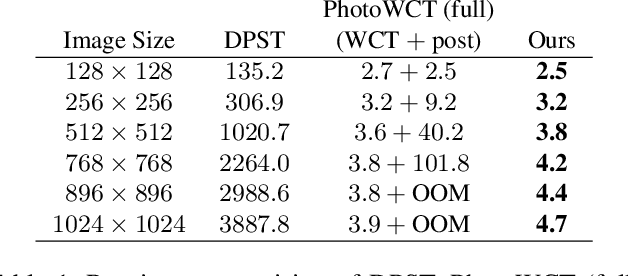
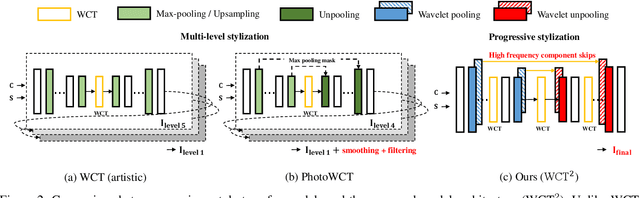
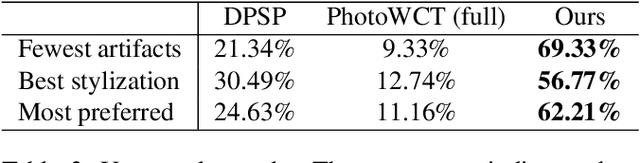
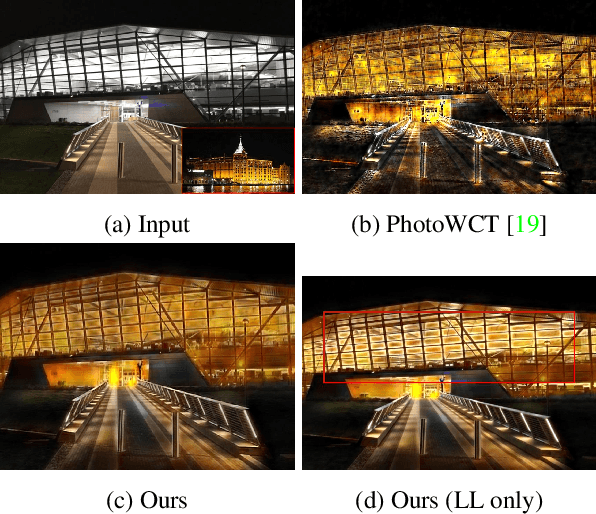
Recent style transfer models have provided promising artistic results. However, given a photograph as a reference style, existing methods are limited by spatial distortions or unrealistic artifacts, which should not happen in real photographs. We introduce a theoretically sound correction to the network architecture that remarkably enhances photorealism and faithfully transfers the style. The key ingredient of our method is wavelet transforms that naturally fits in deep networks. We propose a wavelet corrected transfer based on whitening and coloring transforms (WCT$^2$) that allows features to preserve their structural information and statistical properties of VGG feature space during stylization. This is the first and the only end-to-end model that can stylize $1024\times1024$ resolution image in 4.7 seconds, giving a pleasing and photorealistic quality without any post-processing. Last but not least, our model provides a stable video stylization without temporal constraints. The code, generated images, supplementary materials, and pre-trained models are all available at https://github.com/ClovaAI/WCT2.
Large-Scale Answerer in Questioner's Mind for Visual Dialog Question Generation
Feb 22, 2019

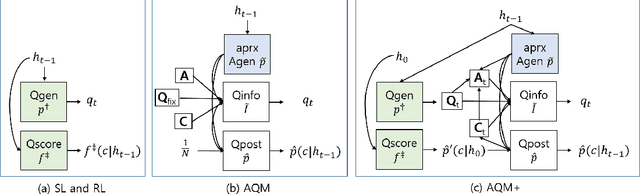

Answerer in Questioner's Mind (AQM) is an information-theoretic framework that has been recently proposed for task-oriented dialog systems. AQM benefits from asking a question that would maximize the information gain when it is asked. However, due to its intrinsic nature of explicitly calculating the information gain, AQM has a limitation when the solution space is very large. To address this, we propose AQM+ that can deal with a large-scale problem and ask a question that is more coherent to the current context of the dialog. We evaluate our method on GuessWhich, a challenging task-oriented visual dialog problem, where the number of candidate classes is near 10K. Our experimental results and ablation studies show that AQM+ outperforms the state-of-the-art models by a remarkable margin with a reasonable approximation. In particular, the proposed AQM+ reduces more than 60% of error as the dialog proceeds, while the comparative algorithms diminish the error by less than 6%. Based on our results, we argue that AQM+ is a general task-oriented dialog algorithm that can be applied for non-yes-or-no responses.
CHOPT : Automated Hyperparameter Optimization Framework for Cloud-Based Machine Learning Platforms
Oct 16, 2018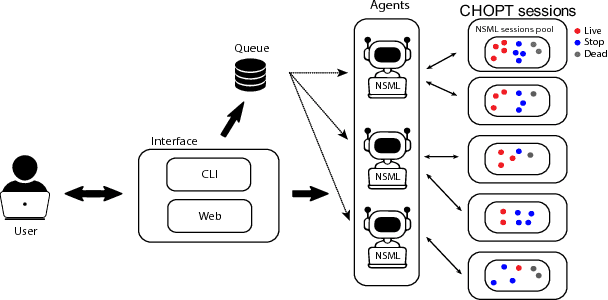

Many hyperparameter optimization (HyperOpt) methods assume restricted computing resources and mainly focus on enhancing performance. Here we propose a novel cloud-based HyperOpt (CHOPT) framework which can efficiently utilize shared computing resources while supporting various HyperOpt algorithms. We incorporate convenient web-based user interfaces, visualization, and analysis tools, enabling users to easily control optimization procedures and build up valuable insights with an iterative analysis procedure. Furthermore, our framework can be incorporated with any cloud platform, thus complementarily increasing the efficiency of conventional deep learning frameworks. We demonstrate applications of CHOPT with tasks such as image recognition and question-answering, showing that our framework can find hyperparameter configurations competitive with previous work. We also show CHOPT is capable of providing interesting observations through its analysing tools