 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualSpeech: Enhancing Speaker-Fidelity and Text-Intelligibility Through Dual Classifier-Free Guidance
Aug 27, 2024


Text-to-Speech (TTS) models have advanced significantly, aiming to accurately replicate human speech's diversity, including unique speaker identities and linguistic nuances. Despite these advancements, achieving an optimal balance between speaker-fidelity and text-intelligibility remains a challenge, particularly when diverse control demands are considered. Addressing this, we introduce DualSpeech, a TTS model that integrates phoneme-level latent diffusion with dual classifier-free guidance. This approach enables exceptional control over speaker-fidelity and text-intelligibility. Experimental results demonstrate that by utilizing the sophisticated control, DualSpeech surpasses existing state-of-the-art TTS models in performance. Demos are available at https://bit.ly/48Ewoib.
Yet Another Generative Model For Room Impulse Response Estimation
Nov 05, 2023Recent neural room impulse response (RIR) estimators typically comprise an encoder for reference audio analysis and a generator for RIR synthesis. Especially, it is the performance of the generator that directly influences the overall estimation quality. In this context, we explore an alternate generator architecture for improved performance. We first train an autoencoder with residual quantization to learn a discrete latent token space, where each token represents a small time-frequency patch of the RIR. Then, we cast the RIR estimation problem as a reference-conditioned autoregressive token generation task, employing transformer variants that operate across frequency, time, and quantization depth axes. This way, we address the standard blind estimation task and additional acoustic matching problem, which aims to find an RIR that matches the source signal to the target signal's reverberation characteristics. Experimental results show that our system is preferable to other baselines across various evaluation metrics.
Towards trustworthy phoneme boundary detection with autoregressive model and improved evaluation metric
Dec 13, 2022



Phoneme boundary detection has been studied due to its central role in various speech applications. In this work, we point out that this task needs to be addressed not only by algorithmic way, but also by evaluation metric. To this end, we first propose a state-of-the-art phoneme boundary detector that operates in an autoregressive manner, dubbed SuperSeg. Experiments on the TIMIT and Buckeye corpora demonstrates that SuperSeg identifies phoneme boundaries with significant margin compared to existing models. Furthermore, we note that there is a limitation on the popular evaluation metric, R-value, and propose new evaluation metrics that prevent each boundary from contributing to evaluation multiple times. The proposed metrics reveal the weaknesses of non-autoregressive baselines and establishes a reliable criterion that suits for evaluating phoneme boundary detection.
NANSY++: Unified Voice Synthesis with Neural Analysis and Synthesis
Nov 17, 2022Various applications of voice synthesis have been developed independently despite the fact that they generate "voice" as output in common. In addition, most of the voice synthesis models still require a large number of audio data paired with annotated labels (e.g., text transcription and music score) for training. To this end, we propose a unified framework of synthesizing and manipulating voice signals from analysis features, dubbed NANSY++. The backbone network of NANSY++ is trained in a self-supervised manner that does not require any annotations paired with audio. After training the backbone network, we efficiently tackle four voice applications - i.e. voice conversion, text-to-speech, singing voice synthesis, and voice designing - by partially modeling the analysis features required for each task. Extensive experiments show that the proposed framework offers competitive advantages such as controllability, data efficiency, and fast training convergence, while providing high quality synthesis. Audio samples: tinyurl.com/8tnsy3uc.
Expressive Singing Synthesis Using Local Style Token and Dual-path Pitch Encoder
Apr 07, 2022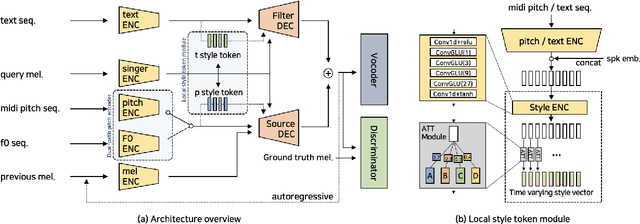
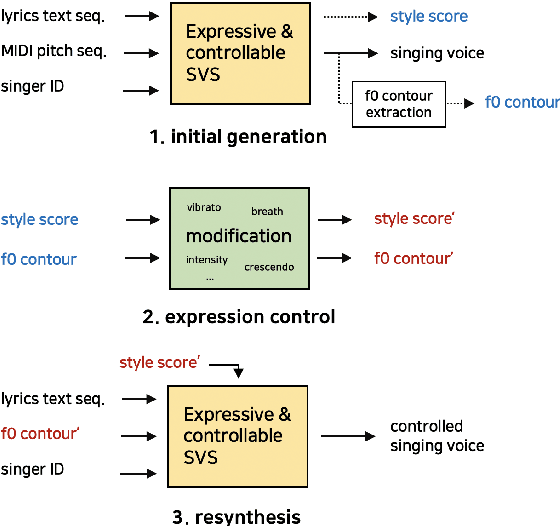
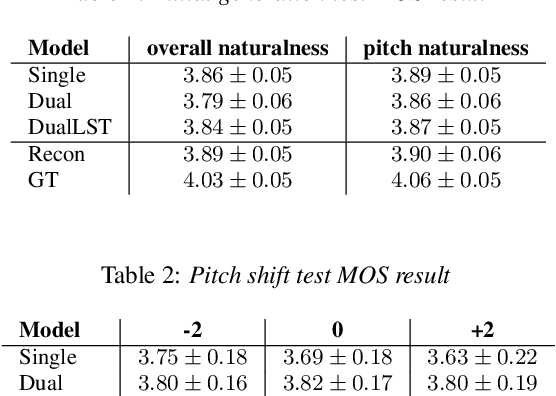
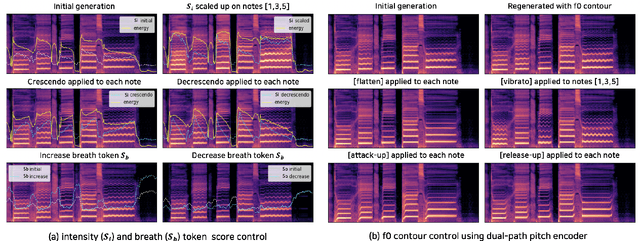
This paper proposes a controllable singing voice synthesis system capable of generating expressive singing voice with two novel methodologies. First, a local style token module, which predicts frame-level style tokens from an input pitch and text sequence, is proposed to allow the singing voice system to control musical expression often unspecified in sheet music (e.g., breathing and intensity). Second, we propose a dual-path pitch encoder with a choice of two different pitch inputs: MIDI pitch sequence or f0 contour. Because the initial generation of a singing voice is usually executed by taking a MIDI pitch sequence, one can later extract an f0 contour from the generated singing voice and modify the f0 contour to a finer level as desired. Through quantitative and qualitative evaluations, we confirmed that the proposed model could control various musical expressions while not sacrificing the sound quality of the singing voice synthesis system.
Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
Oct 28, 2021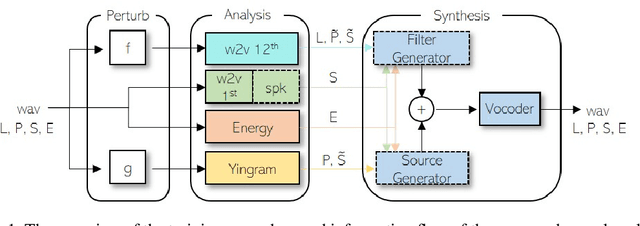

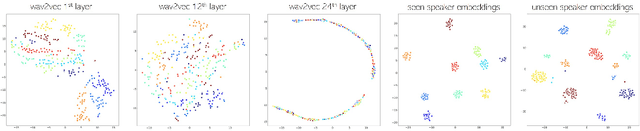
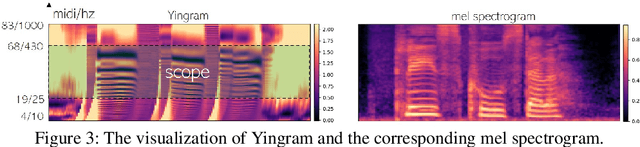
We present a neural analysis and synthesis (NANSY) framework that can manipulate voice, pitch, and speed of an arbitrary speech signal. Most of the previous works have focused on using information bottleneck to disentangle analysis features for controllable synthesis, which usually results in poor reconstruction quality. We address this issue by proposing a novel training strategy based on information perturbation. The idea is to perturb information in the original input signal (e.g., formant, pitch, and frequency response), thereby letting synthesis networks selectively take essential attributes to reconstruct the input signal. Because NANSY does not need any bottleneck structures, it enjoys both high reconstruction quality and controllability. Furthermore, NANSY does not require any labels associated with speech data such as text and speaker information, but rather uses a new set of analysis features, i.e., wav2vec feature and newly proposed pitch feature, Yingram, which allows for fully self-supervised training. Taking advantage of fully self-supervised training, NANSY can be easily extended to a multilingual setting by simply training it with a multilingual dataset. The experiments show that NANSY can achieve significant improvement in performance in several applications such as zero-shot voice conversion, pitch shift, and time-scale modification.
Differentiable Artificial Reverberation
May 28, 2021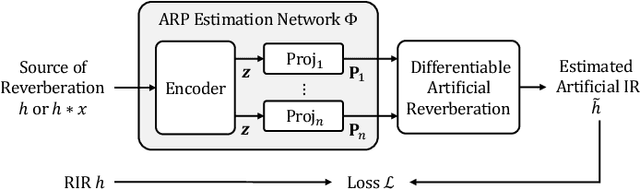
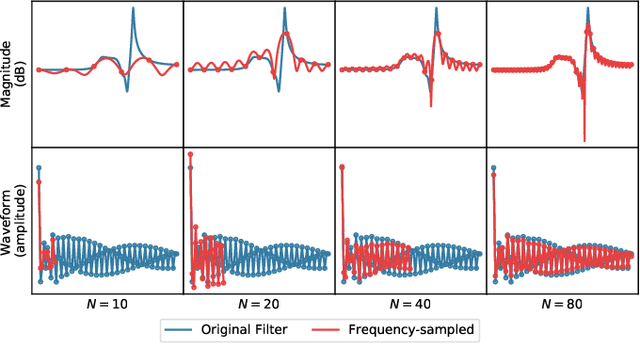
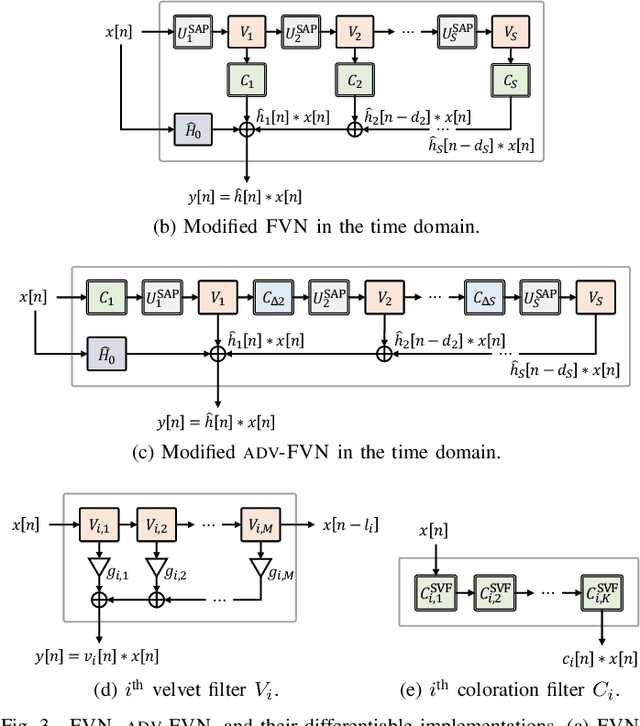
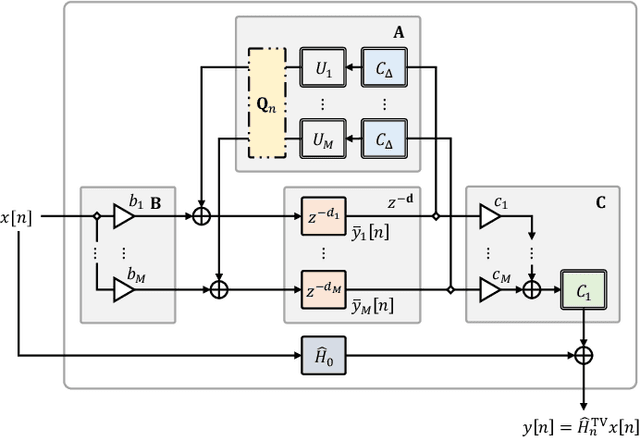
We propose differentiable artificial reverberation (DAR), a family of artificial reverberation (AR) models implemented in a deep learning framework. Combined with the modern deep neural networks (DNNs), the differentiable structure of DAR allows training loss gradients to be back-propagated in an end-to-end manner. Most of the AR models bottleneck training speed when implemented "as is" in the time domain and executed with a parallel processor like GPU due to their infinite impulse response (IIR) filter components. We tackle this by further developing a recently proposed acceleration technique, which borrows the frequency-sampling method (FSM). With the proposed DAR models, we aim to solve an artificial reverberation parameter (ARP) estimation task in a unified approach. We design an ARP estimation network applicable to both analysis-synthesis (RIR-to-ARP) and blind estimation (reverberant-speech-to-ARP) tasks. And using different DAR models only requires slightly a different decoder configuration. This way, the proposed DAR framework overcomes the previous methods' limitations of task-dependency and AR-model-dependency.
Room adaptive conditioning method for sound event classification in reverberant environments
Apr 21, 2021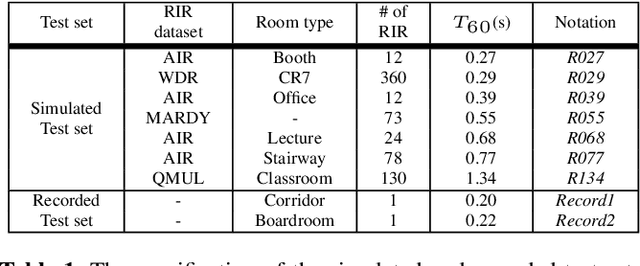
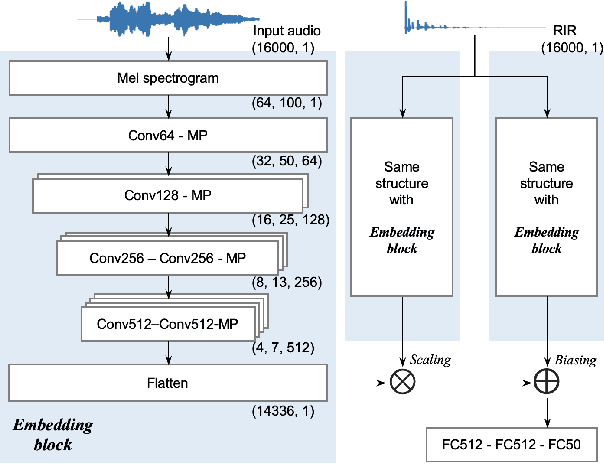
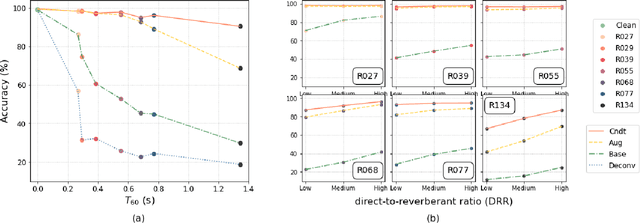
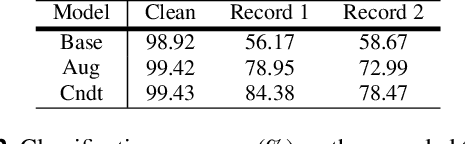
Ensuring performance robustness for a variety of situations that can occur in real-world environments is one of the challenging tasks in sound event classification. One of the unpredictable and detrimental factors in performance, especially in indoor environments, is reverberation. To alleviate this problem, we propose a conditioning method that provides room impulse response (RIR) information to help the network become less sensitive to environmental information and focus on classifying the desired sound. Experimental results show that the proposed method successfully reduced performance degradation caused by the reverberation of the room. In particular, our proposed method works even with similar RIR that can be inferred from the room type rather than the exact one, which has the advantage of potentially being used in real-world applications.
Real-time Denoising and Dereverberation with Tiny Recurrent U-Net
Feb 10, 2021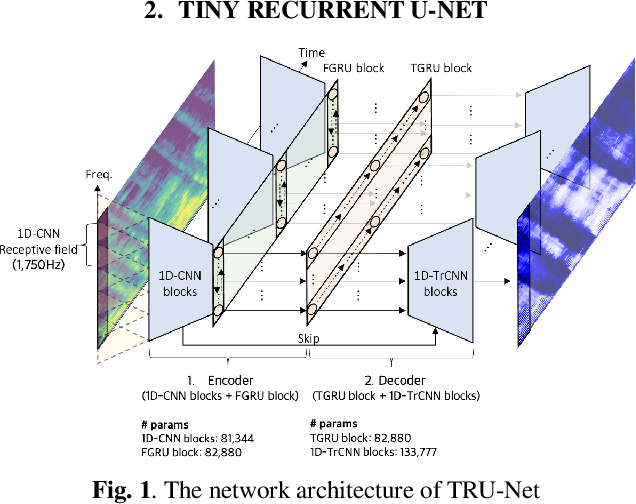
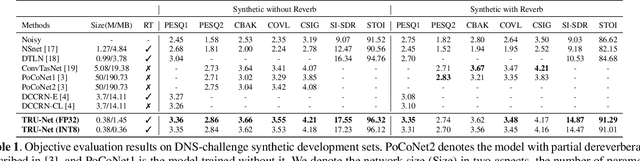
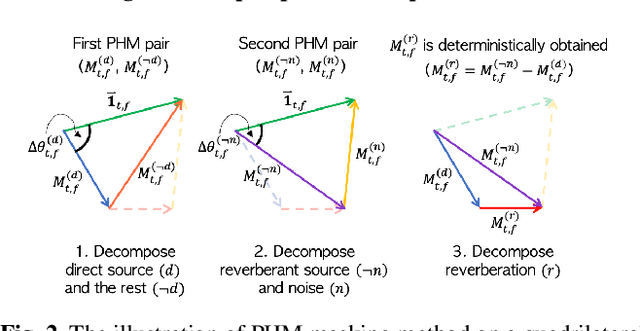
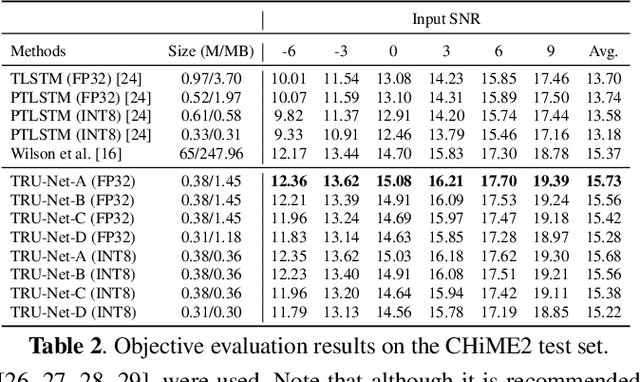
Modern deep learning-based models have seen outstanding performance improvement with speech enhancement tasks. The number of parameters of state-of-the-art models, however, is often too large to be deployed on devices for real-world applications. To this end, we propose Tiny Recurrent U-Net (TRU-Net), a lightweight online inference model that matches the performance of current state-of-the-art models. The size of the quantized version of TRU-Net is 362 kilobytes, which is small enough to be deployed on edge devices. In addition, we combine the small-sized model with a new masking method called phase-aware $\beta$-sigmoid mask, which enables simultaneous denoising and dereverberation. Results of both objective and subjective evaluations have shown that our model can achieve competitive performance with the current state-of-the-art models on benchmark datasets using fewer parameters by orders of magnitude.
From Inference to Generation: End-to-end Fully Self-supervised Generation of Human Face from Speech
Apr 13, 2020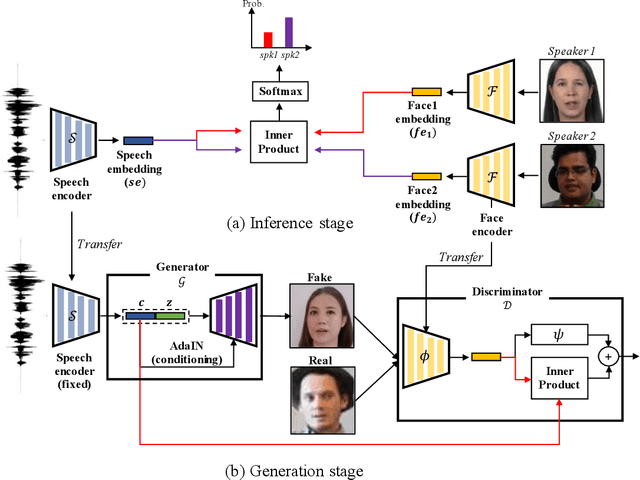
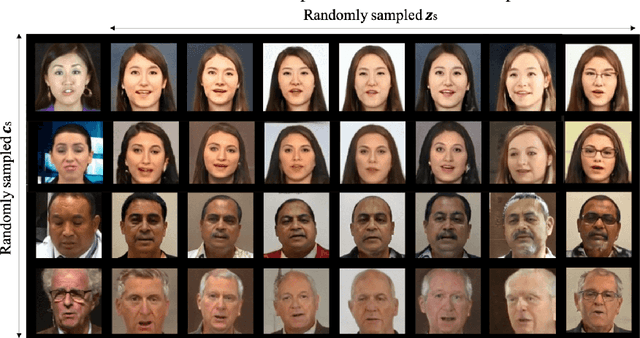

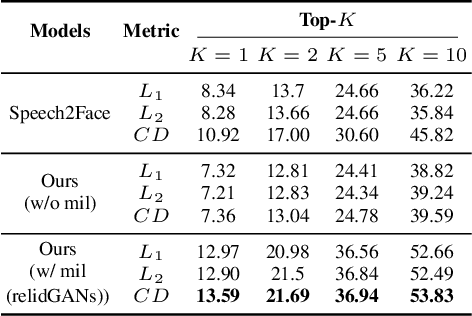
This work seeks the possibility of generating the human face from voice solely based on the audio-visual data without any human-labeled annotations. To this end, we propose a multi-modal learning framework that links the inference stage and generation stage. First, the inference networks are trained to match the speaker identity between the two different modalities. Then the trained inference networks cooperate with the generation network by giving conditional information about the voice. The proposed method exploits the recent development of GANs techniques and generates the human face directly from the speech waveform making our system fully end-to-end. We analyze the extent to which the network can naturally disentangle two latent factors that contribute to the generation of a face image - one that comes directly from a speech signal and the other that is not related to it - and explore whether the network can learn to generate natural human face image distribution by modeling these factors. Experimental results show that the proposed network can not only match the relationship between the human face and speech, but can also generate the high-quality human face sample conditioned on its speech. Finally, the correlation between the generated face and the corresponding speech is quantitatively measured to analyze the relationship between the two modalities.