 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverconfidence and Calibration in Medical VQA: Empirical Findings and Hallucination-Aware Mitigation
Apr 02, 2026As vision-language models (VLMs) are increasingly deployed in clinical decision support, more than accuracy is required: knowing when to trust their predictions is equally critical. Yet, a comprehensive and systematic investigation into the overconfidence of these models remains notably scarce in the medical domain. We address this gap through a comprehensive empirical study of confidence calibration in VLMs, spanning three model families (Qwen3-VL, InternVL3, LLaVA-NeXT), three model scales (2B--38B), and multiple confidence estimation prompting strategies, across three medical visual question answering (VQA) benchmarks. Our study yields three key findings: First, overconfidence persists across model families and is not resolved by scaling or prompting, such as chain-of-thought and verbalized confidence variants. Second, simple post-hoc calibration approaches, such as Platt scaling, reduce calibration error and consistently outperform the prompt-based strategy. Third, due to their (strict) monotonicity, these post-hoc calibration methods are inherently limited in improving the discriminative quality of predictions, leaving AUROC at the same level. Motivated by these findings, we investigate hallucination-aware calibration (HAC), which incorporates vision-grounded hallucination detection signals as complementary inputs to refine confidence estimates. We find that leveraging these hallucination signals improves both calibration and AUROC, with the largest gains on open-ended questions. Overall, our findings suggest post-hoc calibration as standard practice for medical VLM deployment over raw confidence estimates, and highlight the practical usefulness of hallucination signals to enable more reliable use of VLMs in medical VQA.
Test-Time-Scaling for Zero-Shot Diagnosis with Visual-Language Reasoning
Jun 11, 2025As a cornerstone of patient care, clinical decision-making significantly influences patient outcomes and can be enhanced by large language models (LLMs). Although LLMs have demonstrated remarkable performance, their application to visual question answering in medical imaging, particularly for reasoning-based diagnosis, remains largely unexplored. Furthermore, supervised fine-tuning for reasoning tasks is largely impractical due to limited data availability and high annotation costs. In this work, we introduce a zero-shot framework for reliable medical image diagnosis that enhances the reasoning capabilities of LLMs in clinical settings through test-time scaling. Given a medical image and a textual prompt, a vision-language model processes a medical image along with a corresponding textual prompt to generate multiple descriptions or interpretations of visual features. These interpretations are then fed to an LLM, where a test-time scaling strategy consolidates multiple candidate outputs into a reliable final diagnosis. We evaluate our approach across various medical imaging modalities -- including radiology, ophthalmology, and histopathology -- and demonstrate that the proposed test-time scaling strategy enhances diagnostic accuracy for both our and baseline methods. Additionally, we provide an empirical analysis showing that the proposed approach, which allows unbiased prompting in the first stage, improves the reliability of LLM-generated diagnoses and enhances classification accuracy.
Know What You Don't Know: Uncertainty Calibration of Process Reward Models
Jun 11, 2025Process reward models (PRMs) play a central role in guiding inference-time scaling algorithms for large language models (LLMs). However, we observe that even state-of-the-art PRMs can be poorly calibrated and often overestimate success probabilities. To address this, we present a calibration approach, performed via quantile regression, that adjusts PRM outputs to better align with true success probabilities. Leveraging these calibrated success estimates and their associated confidence bounds, we introduce an \emph{instance-adaptive scaling} (IAS) framework that dynamically adjusts the inference budget based on the estimated likelihood that a partial reasoning trajectory will yield a correct final answer. Unlike conventional methods that allocate a fixed number of reasoning trajectories per query, this approach successfully adapts to each instance and reasoning step when using our calibrated PRMs. Experiments on mathematical reasoning benchmarks show that (i) our PRM calibration method successfully achieves small calibration error, outperforming the baseline methods, (ii) calibration is crucial for enabling effective adaptive scaling, and (iii) the proposed IAS strategy reduces inference costs while maintaining final answer accuracy, utilizing less compute on more confident problems as desired.
Identifying Reliable Predictions in Detection Transformers
Dec 02, 2024



DEtection TRansformer (DETR) has emerged as a promising architecture for object detection, offering an end-to-end prediction pipeline. In practice, however, DETR generates hundreds of predictions that far outnumber the actual number of objects present in an image. This raises the question: can we trust and use all of these predictions? Addressing this concern, we present empirical evidence highlighting how different predictions within the same image play distinct roles, resulting in varying reliability levels across those predictions. More specifically, while multiple predictions are often made for a single object, our findings show that most often one such prediction is well-calibrated, and the others are poorly calibrated. Based on these insights, we demonstrate identifying a reliable subset of DETR's predictions is crucial for accurately assessing the reliability of the model at both object and image levels. Building on this viewpoint, we first tackle the shortcomings of widely used performance and calibration metrics, such as average precision and various forms of expected calibration error. Specifically, they are inadequate for determining which subset of DETR's predictions should be trusted and utilized. In response, we present Object-level Calibration Error (OCE), which is capable of assessing the calibration quality both across different models and among various configurations within a specific model. As a final contribution, we introduce a post hoc Uncertainty Quantification (UQ) framework that predicts the accuracy of the model on a per-image basis. By contrasting the average confidence scores of positive (i.e., likely to be matched) and negative predictions determined by OCE, the framework assesses the reliability of the DETR model for each test image.
A Scalable and Transferable Time Series Prediction Framework for Demand Forecasting
Feb 29, 2024



Time series forecasting is one of the most essential and ubiquitous tasks in many business problems, including demand forecasting and logistics optimization. Traditional time series forecasting methods, however, have resulted in small models with limited expressive power because they have difficulty in scaling their model size up while maintaining high accuracy. In this paper, we propose Forecasting orchestra (Forchestra), a simple but powerful framework capable of accurately predicting future demand for a diverse range of items. We empirically demonstrate that the model size is scalable to up to 0.8 billion parameters. The proposed method not only outperforms existing forecasting models with a significant margin, but it could generalize well to unseen data points when evaluated in a zero-shot fashion on downstream datasets. Last but not least, we present extensive qualitative and quantitative studies to analyze how the proposed model outperforms baseline models and differs from conventional approaches. The original paper was presented as a full paper at ICDM 2022 and is available at: https://ieeexplore.ieee.org/document/10027662.
Representation Reliability and Its Impact on Downstream Tasks
May 31, 2023



Self-supervised pre-trained models extract general-purpose representations from data, and quantifying how reliable they are is crucial because many downstream models use these representations as input for their own tasks. To this end, we first introduce a formal definition of representation reliability: the representation for a given test input is considered to be reliable if the downstream models built on top of that representation can consistently generate accurate predictions for that test point. It is desired to estimate the representation reliability without knowing the downstream tasks a priori. We provide a negative result showing that existing frameworks for uncertainty quantification in supervised learning are not suitable for this purpose. As an alternative, we propose an ensemble-based method for quantifying representation reliability, based on the concept of neighborhood consistency in the representation spaces across various pre-trained models. More specifically, the key insight is to use shared neighboring points as anchors to align different representation spaces. We demonstrate through comprehensive numerical experiments that our method is capable of predicting representation reliability with high accuracy.
VQ-AR: Vector Quantized Autoregressive Probabilistic Time Series Forecasting
May 31, 2022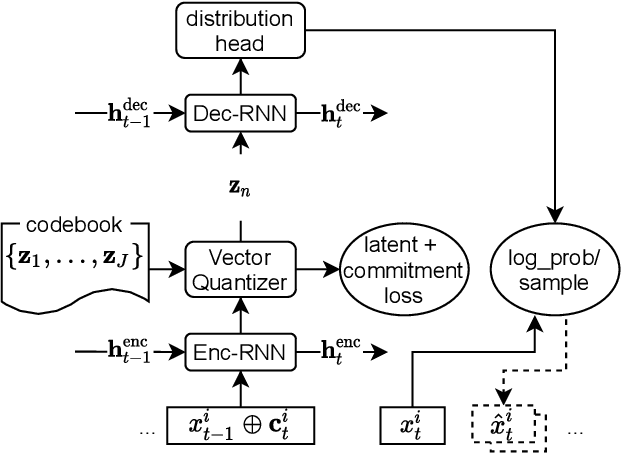
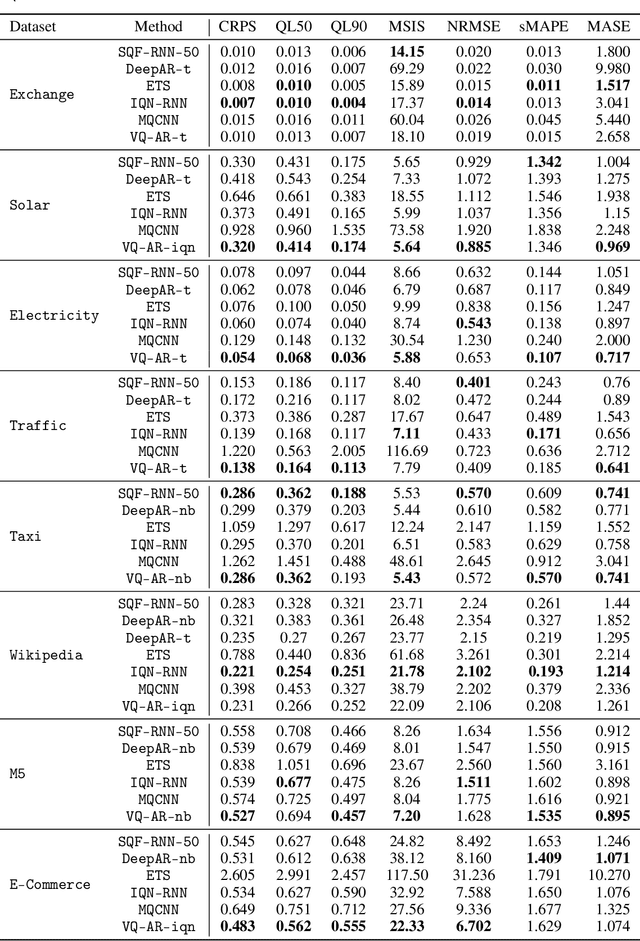
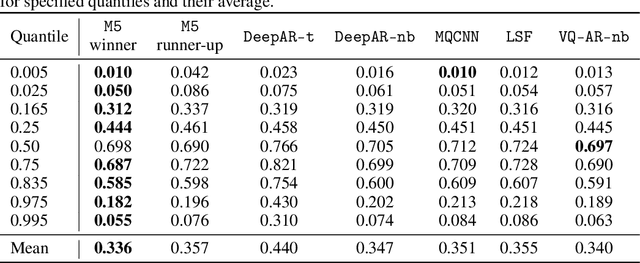
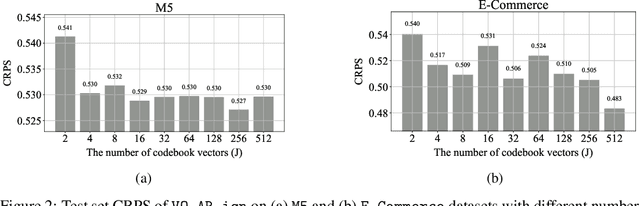
Time series models aim for accurate predictions of the future given the past, where the forecasts are used for important downstream tasks like business decision making. In practice, deep learning based time series models come in many forms, but at a high level learn some continuous representation of the past and use it to output point or probabilistic forecasts. In this paper, we introduce a novel autoregressive architecture, VQ-AR, which instead learns a \emph{discrete} set of representations that are used to predict the future. Extensive empirical comparison with other competitive deep learning models shows that surprisingly such a discrete set of representations gives state-of-the-art or equivalent results on a wide variety of time series datasets. We also highlight the shortcomings of this approach, explore its zero-shot generalization capabilities, and present an ablation study on the number of representations. The full source code of the method will be available at the time of publication with the hope that researchers can further investigate this important but overlooked inductive bias for the time series domain.
Global-Local Item Embedding for Temporal Set Prediction
Sep 05, 2021
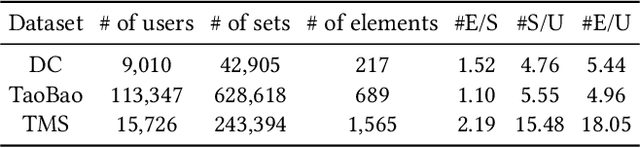
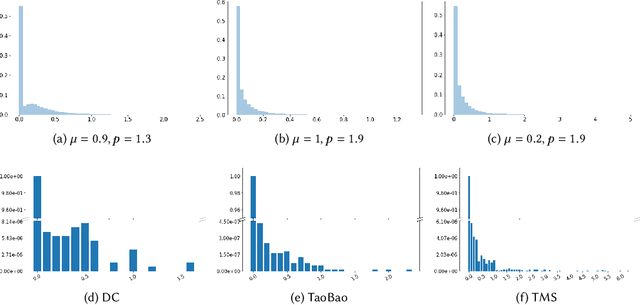
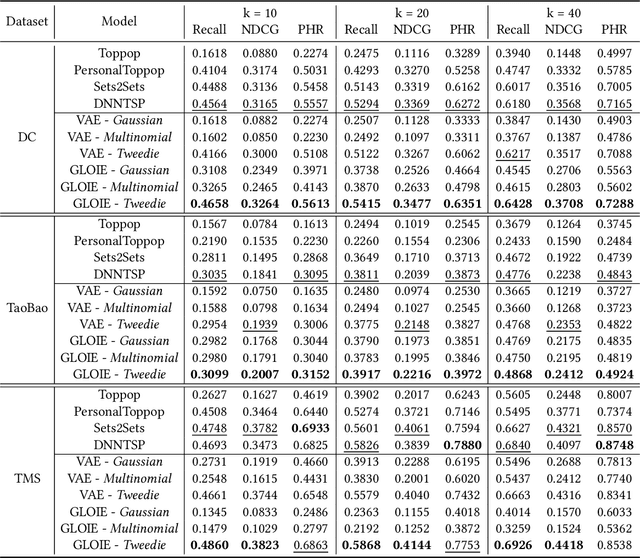
Temporal set prediction is becoming increasingly important as many companies employ recommender systems in their online businesses, e.g., personalized purchase prediction of shopping baskets. While most previous techniques have focused on leveraging a user's history, the study of combining it with others' histories remains untapped potential. This paper proposes Global-Local Item Embedding (GLOIE) that learns to utilize the temporal properties of sets across whole users as well as within a user by coining the names as global and local information to distinguish the two temporal patterns. GLOIE uses Variational Autoencoder (VAE) and dynamic graph-based model to capture global and local information and then applies attention to integrate resulting item embeddings. Additionally, we propose to use Tweedie output for the decoder of VAE as it can easily model zero-inflated and long-tailed distribution, which is more suitable for several real-world data distributions than Gaussian or multinomial counterparts. When evaluated on three public benchmarks, our algorithm consistently outperforms previous state-of-the-art methods in most ranking metrics.
One4all User Representation for Recommender Systems in E-commerce
May 24, 2021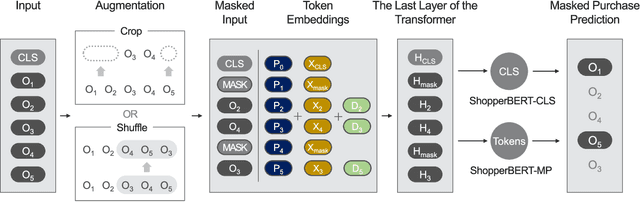

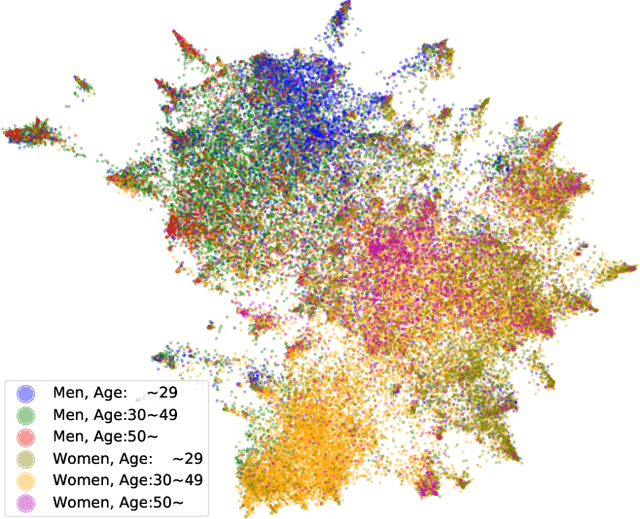
General-purpose representation learning through large-scale pre-training has shown promising results in the various machine learning fields. For an e-commerce domain, the objective of general-purpose, i.e., one for all, representations would be efficient applications for extensive downstream tasks such as user profiling, targeting, and recommendation tasks. In this paper, we systematically compare the generalizability of two learning strategies, i.e., transfer learning through the proposed model, ShopperBERT, vs. learning from scratch. ShopperBERT learns nine pretext tasks with 79.2M parameters from 0.8B user behaviors collected over two years to produce user embeddings. As a result, the MLPs that employ our embedding method outperform more complex models trained from scratch for five out of six tasks. Specifically, the pre-trained embeddings have superiority over the task-specific supervised features and the strong baselines, which learn the auxiliary dataset for the cold-start problem. We also show the computational efficiency and embedding visualization of the pre-trained features.
A Worrying Analysis of Probabilistic Time-series Models for Sales Forecasting
Nov 21, 2020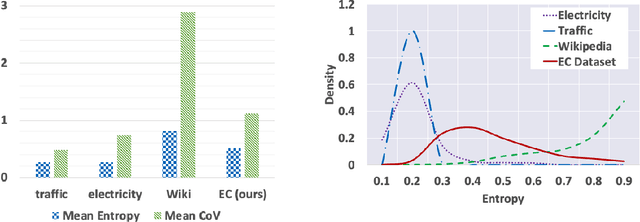
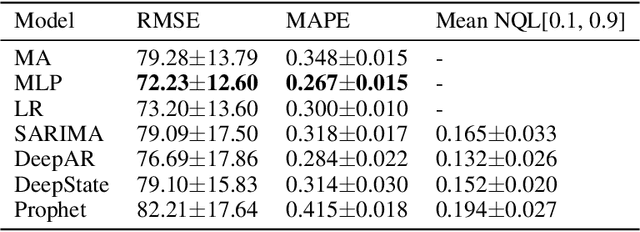
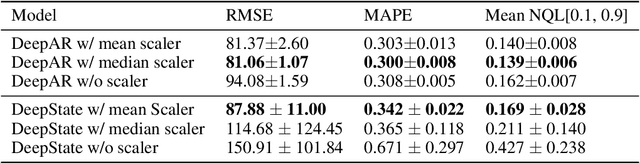

Probabilistic time-series models become popular in the forecasting field as they help to make optimal decisions under uncertainty. Despite the growing interest, a lack of thorough analysis hinders choosing what is worth applying for the desired task. In this paper, we analyze the performance of three prominent probabilistic time-series models for sales forecasting. To remove the role of random chance in architecture's performance, we make two experimental principles; 1) Large-scale dataset with various cross-validation sets. 2) A standardized training and hyperparameter selection. The experimental results show that a simple Multi-layer Perceptron and Linear Regression outperform the probabilistic models on RMSE without any feature engineering. Overall, the probabilistic models fail to achieve better performance on point estimation, such as RMSE and MAPE, than comparably simple baselines. We analyze and discuss the performances of probabilistic time-series models.