 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven topology design based on principal component analysis for 3D structural design problems
Sep 03, 2024Topology optimization is a structural design methodology widely utilized to address engineering challenges. However, sensitivity-based topology optimization methods struggle to solve optimization problems characterized by strong non-linearity. Leveraging the sensitivity-free nature and high capacity of deep generative models, data-driven topology design (DDTD) methodology is considered an effective solution to this problem. Despite this, the training effectiveness of deep generative models diminishes when input size exceeds a threshold while maintaining high degrees of freedom is crucial for accurately characterizing complex structures. To resolve the conflict between the both, we propose DDTD based on principal component analysis (PCA). Its core idea is to replace the direct training of deep generative models with material distributions by using a principal component score matrix obtained from PCA computation and to obtain the generated material distributions with new features through the restoration process. We apply the proposed PCA-based DDTD to the problem of minimizing the maximum stress in 3D structural mechanics and demonstrate it can effectively address the current challenges faced by DDTD that fail to handle 3D structural design problems. Various experiments are conducted to demonstrate the effectiveness and practicability of the proposed PCA-based DDTD.
ChipExpert: The Open-Source Integrated-Circuit-Design-Specific Large Language Model
Jul 26, 2024The field of integrated circuit (IC) design is highly specialized, presenting significant barriers to entry and research and development challenges. Although large language models (LLMs) have achieved remarkable success in various domains, existing LLMs often fail to meet the specific needs of students, engineers, and researchers. Consequently, the potential of LLMs in the IC design domain remains largely unexplored. To address these issues, we introduce ChipExpert, the first open-source, instructional LLM specifically tailored for the IC design field. ChipExpert is trained on one of the current best open-source base model (Llama-3 8B). The entire training process encompasses several key stages, including data preparation, continue pre-training, instruction-guided supervised fine-tuning, preference alignment, and evaluation. In the data preparation stage, we construct multiple high-quality custom datasets through manual selection and data synthesis techniques. In the subsequent two stages, ChipExpert acquires a vast amount of IC design knowledge and learns how to respond to user queries professionally. ChipExpert also undergoes an alignment phase, using Direct Preference Optimization, to achieve a high standard of ethical performance. Finally, to mitigate the hallucinations of ChipExpert, we have developed a Retrieval-Augmented Generation (RAG) system, based on the IC design knowledge base. We also released the first IC design benchmark ChipICD-Bench, to evaluate the capabilities of LLMs across multiple IC design sub-domains. Through comprehensive experiments conducted on this benchmark, ChipExpert demonstrated a high level of expertise in IC design knowledge Question-and-Answer tasks.
Revealing the evanescent components in Kronecker-product based codebooks: insights and implications
Jul 09, 2024



The orthogonal bases of discrete Fourier transform (DFT) has been recognized as the standard spatial-domain bases for Type I, Type II and enhanced Type II codewords by the 3rd Generation Partnership Project (3GPP). For uniform planar arrays, these spatial-domain bases are derived as the Kronecker product of one-dimensional DFT bases. Theoretically, each spatial basis corresponds to a beam directed towards a specific angle of departure and the set of bases represent the orthogonal beams that cover the front hemisphere of an array. While the Kronecker-product based precoding scheme facilitates the concise indexing of a codeword in the codebooks through precoding matrix indicators (PMIs) in channel state information feedback, it introduces redundant spatial beams characterized by high spatial-frequency components. This paper investigates the presence of codewords representing high spatial-frequency components within the Kronecker-product based codebooks. Through theoretical analysis and simulations, we confirm the redundancy of these codewords in MIMO communications, advocating for their removal from the codebooks to enhance system performance. Several topics relevant to the high spatial components are also involved in the discussion. Practical suggestions regarding future standard design are provided based on our theoretical analysis and simulation results.
RepoQA: Evaluating Long Context Code Understanding
Jun 10, 2024


Recent advances have been improving the context windows of Large Language Models (LLMs). To quantify the real long-context capabilities of LLMs, evaluators such as the popular Needle in a Haystack have been developed to test LLMs over a large chunk of raw texts. While effective, current evaluations overlook the insight of how LLMs work with long-context code, i.e., repositories. To this end, we initiate the RepoQA benchmark to evaluate LLMs on long-context code understanding. Traditional needle testers ask LLMs to directly retrieve the answer from the context without necessary deep understanding. In RepoQA, we built our initial task, namely Searching Needle Function (SNF), which exercises LLMs to search functions given their natural-language description, i.e., LLMs cannot find the desired function if they cannot understand the description and code. RepoQA is multilingual and comprehensive: it includes 500 code search tasks gathered from 50 popular repositories across 5 modern programming languages. By evaluating 26 general and code-specific LLMs on RepoQA, we show (i) there is still a small gap between the best open and proprietary models; (ii) different models are good at different languages; and (iii) models may understand code better without comments.
NeB-SLAM: Neural Blocks-based Salable RGB-D SLAM for Unknown Scenes
May 24, 2024



Neural implicit representations have recently demonstrated considerable potential in the field of visual simultaneous localization and mapping (SLAM). This is due to their inherent advantages, including low storage overhead and representation continuity. However, these methods necessitate the size of the scene as input, which is impractical for unknown scenes. Consequently, we propose NeB-SLAM, a neural block-based scalable RGB-D SLAM for unknown scenes. Specifically, we first propose a divide-and-conquer mapping strategy that represents the entire unknown scene as a set of sub-maps. These sub-maps are a set of neural blocks of fixed size. Then, we introduce an adaptive map growth strategy to achieve adaptive allocation of neural blocks during camera tracking and gradually cover the whole unknown scene. Finally, extensive evaluations on various datasets demonstrate that our method is competitive in both mapping and tracking when targeting unknown environments.
Flexible Active Safety Motion Control for Robotic Obstacle Avoidance: A CBF-Guided MPC Approach
May 20, 2024



A flexible active safety motion (FASM) control approach is proposed for the avoidance of dynamic obstacles and the reference tracking in robot manipulators. The distinctive feature of the proposed method lies in its utilization of control barrier functions (CBF) to design flexible CBF-guided safety criteria (CBFSC) with dynamically optimized decay rates, thereby offering flexibility and active safety for robot manipulators in dynamic environments. First, discrete-time CBFs are employed to formulate the novel flexible CBFSC with dynamic decay rates for robot manipulators. Following that, the model predictive control (MPC) philosophy is applied, integrating flexible CBFSC as safety constraints into the receding-horizon optimization problem. Significantly, the decay rates of the designed CBFSC are incorporated as decision variables in the optimization problem, facilitating the dynamic enhancement of flexibility during the obstacle avoidance process. In particular, a novel cost function that integrates a penalty term is designed to dynamically adjust the safety margins of the CBFSC. Finally, experiments are conducted in various scenarios using a Universal Robots 5 (UR5) manipulator to validate the effectiveness of the proposed approach.
Efficient Multi-agent Reinforcement Learning by Planning
May 20, 2024Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($\lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
Tailoring Vaccine Messaging with Common-Ground Opinions
May 17, 2024



One way to personalize chatbot interactions is by establishing common ground with the intended reader. A domain where establishing mutual understanding could be particularly impactful is vaccine concerns and misinformation. Vaccine interventions are forms of messaging which aim to answer concerns expressed about vaccination. Tailoring responses in this domain is difficult, since opinions often have seemingly little ideological overlap. We define the task of tailoring vaccine interventions to a Common-Ground Opinion (CGO). Tailoring responses to a CGO involves meaningfully improving the answer by relating it to an opinion or belief the reader holds. In this paper we introduce TAILOR-CGO, a dataset for evaluating how well responses are tailored to provided CGOs. We benchmark several major LLMs on this task; finding GPT-4-Turbo performs significantly better than others. We also build automatic evaluation metrics, including an efficient and accurate BERT model that outperforms finetuned LLMs, investigate how to successfully tailor vaccine messaging to CGOs, and provide actionable recommendations from this investigation. Code and model weights: https://github.com/rickardstureborg/tailor-cgo Dataset: https://huggingface.co/datasets/DukeNLP/tailor-cgo
Guarding Force: Safety-Critical Compliant Control for Robot-Environment Interaction
May 08, 2024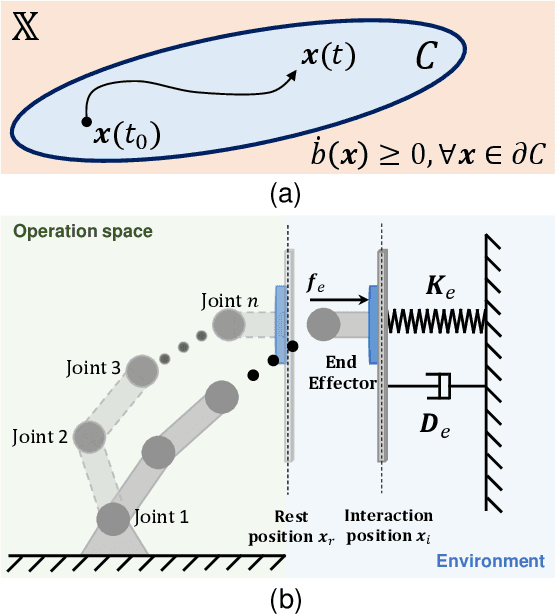
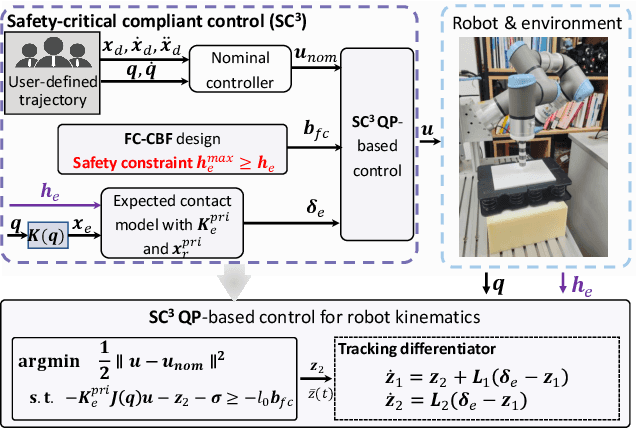
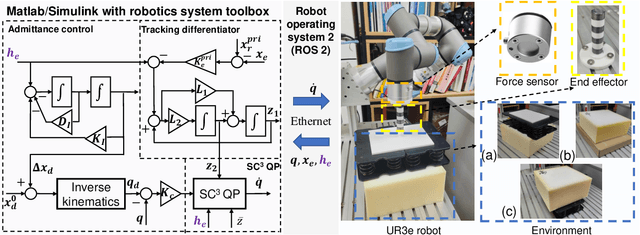
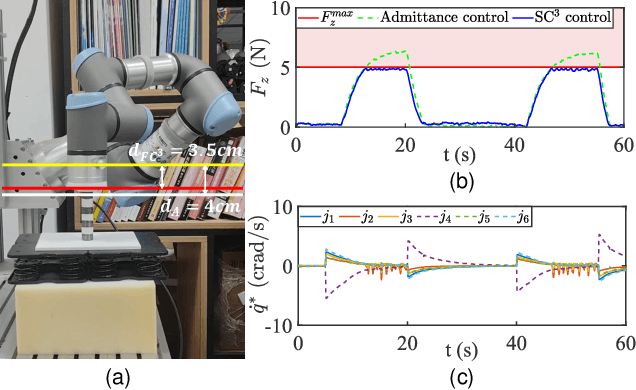
In this study, we propose a safety-critical compliant control strategy designed to strictly enforce interaction force constraints during the physical interaction of robots with unknown environments. The interaction force constraint is interpreted as a new force-constrained control barrier function (FC-CBF) by exploiting the generalized contact model and the prior information of the environment, i.e., the prior stiffness and rest position, for robot kinematics. The difference between the real environment and the generalized contact model is approximated by constructing a tracking differentiator, and its estimation error is quantified based on Lyapunov theory. By interpreting strict interaction safety specification as a dynamic constraint, restricting the desired joint angular rates in kinematics, the proposed approach modifies nominal compliant controllers using quadratic programming, ensuring adherence to interaction force constraints in unknown environments. The strict force constraint and the stability of the closed-loop system are rigorously analyzed. Experimental tests using a UR3e industrial robot with different environments verify the effectiveness of the proposed method in achieving the force constraints in unknown environments.
Harnessing Optical Imaging Limit through Atmospheric Scattering Media
Apr 23, 2024



Recording and identifying faint objects through atmospheric scattering media by an optical system are fundamentally interesting and technologically important. In this work, we introduce a comprehensive model that incorporates contributions from target characteristics, atmospheric effects, imaging system, digital processing, and visual perception to assess the ultimate perceptible limit of geometrical imaging, specifically the angular resolution at the boundary of visible distance. The model allows to reevaluate the effectiveness of conventional imaging recording, processing, and perception and to analyze the limiting factors that constrain image recognition capabilities in atmospheric media. The simulations were compared with the experimental results measured in a fog chamber and outdoor settings. The results reveal general good agreement between analysis and experimental, pointing out the way to harnessing the physical limit for optical imaging in scattering media. An immediate application of the study is the extension of the image range by an amount of 1.2 times with noise reduction via multi-frame averaging, hence greatly enhancing the capability of optical imaging in the atmosphere.