 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Need Adversarial Supervision for Semantic Image Synthesis
Dec 08, 2020
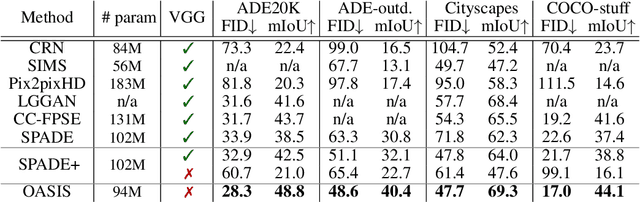

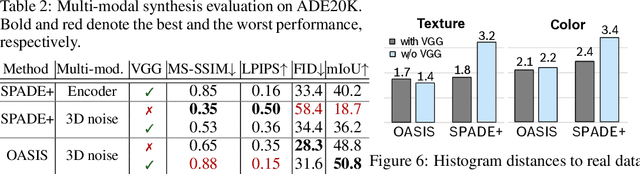
Despite their recent successes, GAN models for semantic image synthesis still suffer from poor image quality when trained with only adversarial supervision. Historically, additionally employing the VGG-based perceptual loss has helped to overcome this issue, significantly improving the synthesis quality, but at the same time limiting the progress of GAN models for semantic image synthesis. In this work, we propose a novel, simplified GAN model, which needs only adversarial supervision to achieve high quality results. We re-design the discriminator as a semantic segmentation network, directly using the given semantic label maps as the ground truth for training. By providing stronger supervision to the discriminator as well as to the generator through spatially- and semantically-aware discriminator feedback, we are able to synthesize images of higher fidelity with better alignment to their input label maps, making the use of the perceptual loss superfluous. Moreover, we enable high-quality multi-modal image synthesis through global and local sampling of a 3D noise tensor injected into the generator, which allows complete or partial image change. We show that images synthesized by our model are more diverse and follow the color and texture distributions of real images more closely. We achieve an average improvement of $6$ FID and $5$ mIoU points over the state of the art across different datasets using only adversarial supervision.
3D CNNs with Adaptive Temporal Feature Resolutions
Nov 17, 2020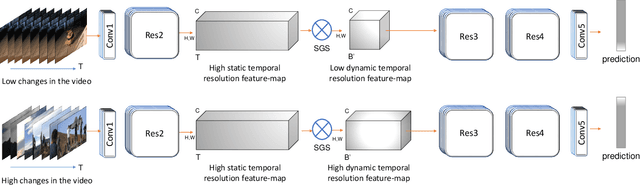

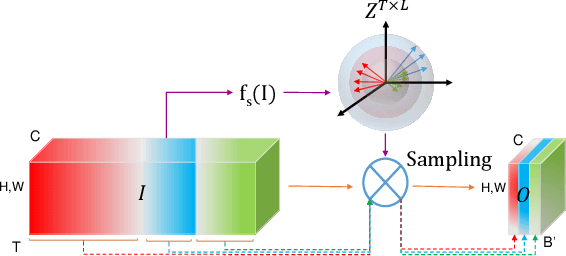

While state-of-the-art 3D Convolutional Neural Networks (CNN) achieve very good results on action recognition datasets, they are computationally very expensive and require many GFLOPs. While the GFLOPs of a 3D CNN can be decreased by reducing the temporal feature resolution within the network, there is no setting that is optimal for all input clips. In this work, we, therefore, introduce a differentiable Similarity Guided Sampling (SGS) module, which can be plugged into any existing 3D CNN architecture. SGS empowers 3D CNNs by learning the similarity of temporal features and grouping similar features together. As a result, the temporal feature resolution is not anymore static but it varies for each input video clip. By integrating SGS as an additional layer within current 3D CNNs, we can convert them into much more efficient 3D CNNs with adaptive temporal feature resolutions (ATFR). Our evaluations show that the proposed module improves the state-of-the-art by reducing the computational cost (GFLOPs)by half while preserving or even improving the accuracy. We evaluate our module by adding it to multiple state-of-the-art 3D CNNs on various datasets such as Kinetics-600, Kinetics-400, mini-Kinetics, Something-Something V2, UCF101, and HMDB51
PoseTrackReID: Dataset Description
Nov 12, 2020Current datasets for video-based person re-identification (re-ID) do not include structural knowledge in form of human pose annotations for the persons of interest. Nonetheless, pose information is very helpful to disentangle useful feature information from background or occlusion noise. Especially real-world scenarios, such as surveillance, contain a lot of occlusions in human crowds or by obstacles. On the other hand, video-based person re-ID can benefit other tasks such as multi-person pose tracking in terms of robust feature matching. For that reason, we present PoseTrackReID, a large-scale dataset for multi-person pose tracking and video-based person re-ID. With PoseTrackReID, we want to bridge the gap between person re-ID and multi-person pose tracking. Additionally, this dataset provides a good benchmark for current state-of-the-art methods on multi-frame person re-ID.
Unsupervised Video Representation Learning by Bidirectional Feature Prediction
Nov 11, 2020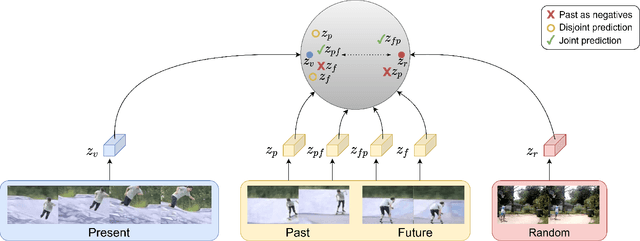
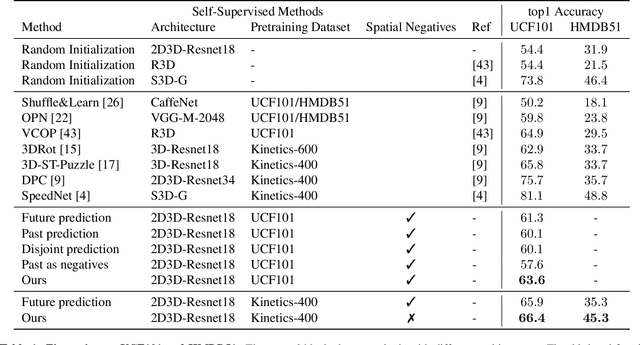
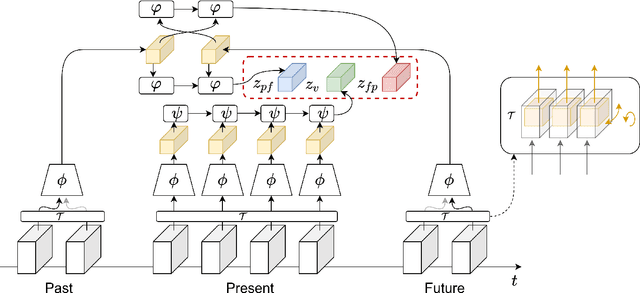
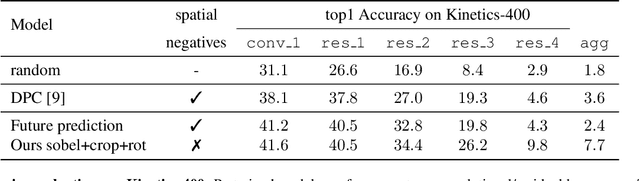
This paper introduces a novel method for self-supervised video representation learning via feature prediction. In contrast to the previous methods that focus on future feature prediction, we argue that a supervisory signal arising from unobserved past frames is complementary to one that originates from the future frames. The rationale behind our method is to encourage the network to explore the temporal structure of videos by distinguishing between future and past given present observations. We train our model in a contrastive learning framework, where joint encoding of future and past provides us with a comprehensive set of temporal hard negatives via swapping. We empirically show that utilizing both signals enriches the learned representations for the downstream task of action recognition. It outperforms independent prediction of future and past.
Pose Refinement Graph Convolutional Network for Skeleton-based Action Recognition
Oct 14, 2020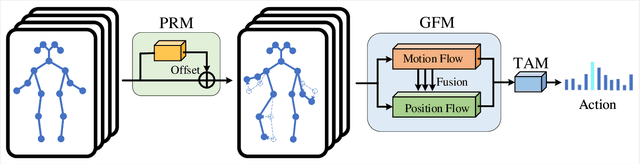
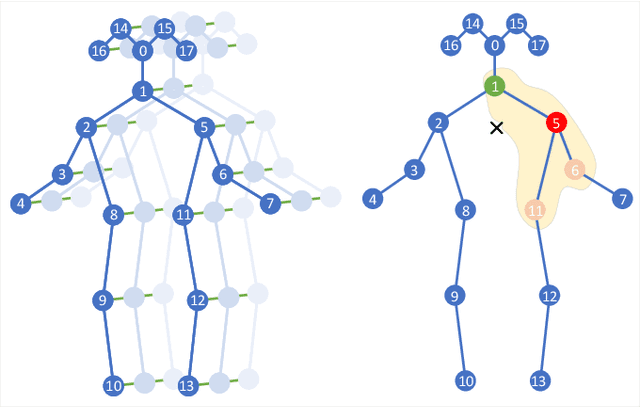
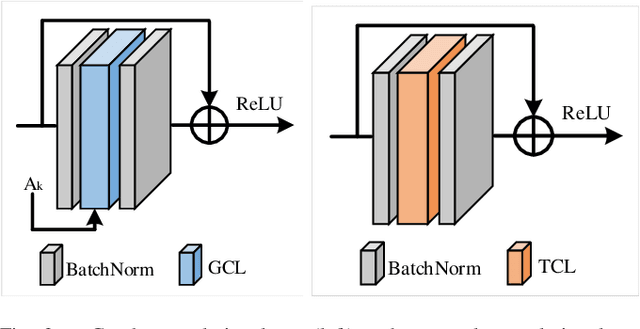
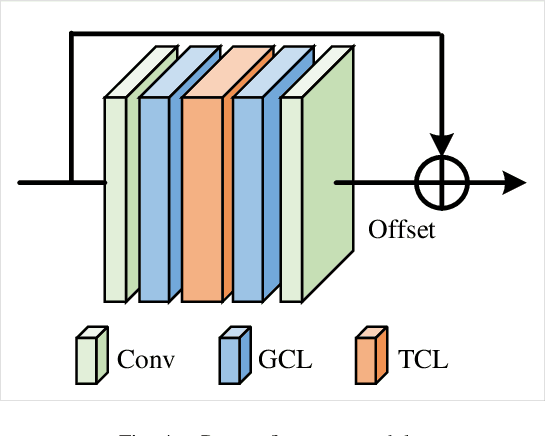
With the advances in capturing 2D or 3D skeleton data, skeleton-based action recognition has received an increasing interest over the last years. As skeleton data is commonly represented by graphs, graph convolutional networks have been proposed for this task. While current graph convolutional networks accurately recognize actions, they are too expensive for robotics applications where limited computational resources are available. In this paper, we therefore propose a highly efficient graph convolutional network that addresses the limitations of previous works. This is achieved by a parallel structure that gradually fuses motion and spatial information and by reducing the temporal resolution as early as possible. Furthermore, we explicitly address the issue that human poses can contain errors. To this end, the network first refines the poses before they are further processed to recognize the action. We therefore call the network Pose Refinement Graph Convolutional Network. Compared to other graph convolutional networks, our network requires 86\%-93\% less parameters and reduces the floating point operations by 89%-96% while achieving a comparable accuracy. It therefore provides a much better trade-off between accuracy, memory footprint and processing time, which makes it suitable for robotics applications.
Long-Term Anticipation of Activities with Cycle Consistency
Sep 02, 2020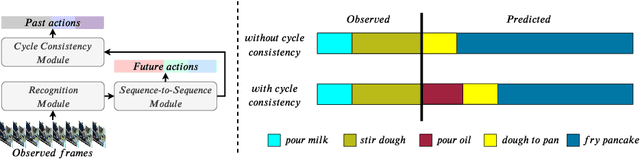
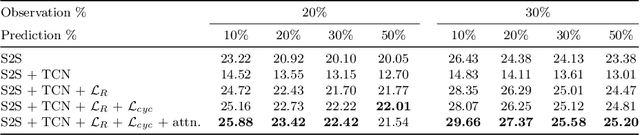
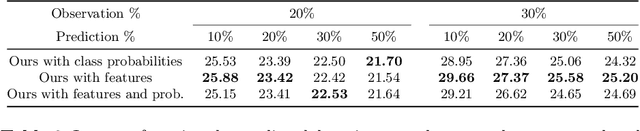
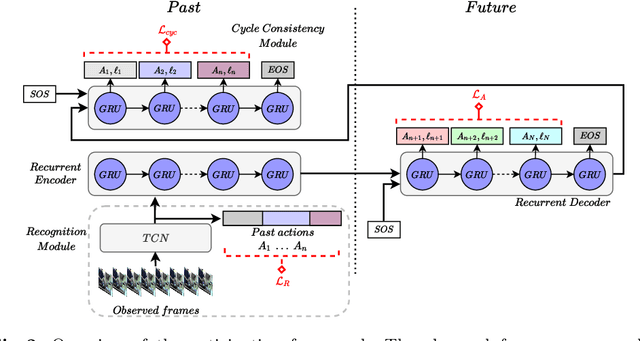
With the success of deep learning methods in analyzing activities in videos, more attention has recently been focused towards anticipating future activities. However, most of the work on anticipation either analyzes a partially observed activity or predicts the next action class. Recently, new approaches have been proposed to extend the prediction horizon up to several minutes in the future and that anticipate a sequence of future activities including their durations. While these works decouple the semantic interpretation of the observed sequence from the anticipation task, we propose a framework for anticipating future activities directly from the features of the observed frames and train it in an end-to-end fashion. Furthermore, we introduce a cycle consistency loss over time by predicting the past activities given the predicted future. Our framework achieves state-of-the-art results on two datasets: the Breakfast dataset and 50Salads.
Multi-scale Interaction for Real-time LiDAR Data Segmentation on an Embedded Platform
Aug 20, 2020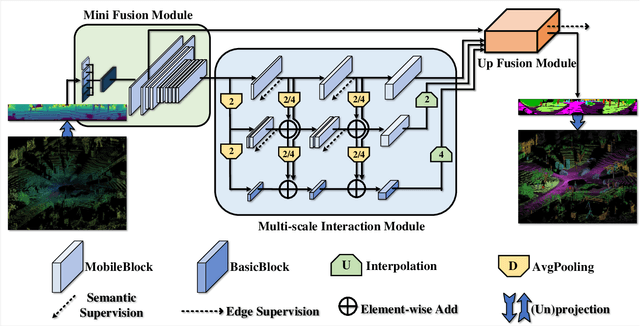
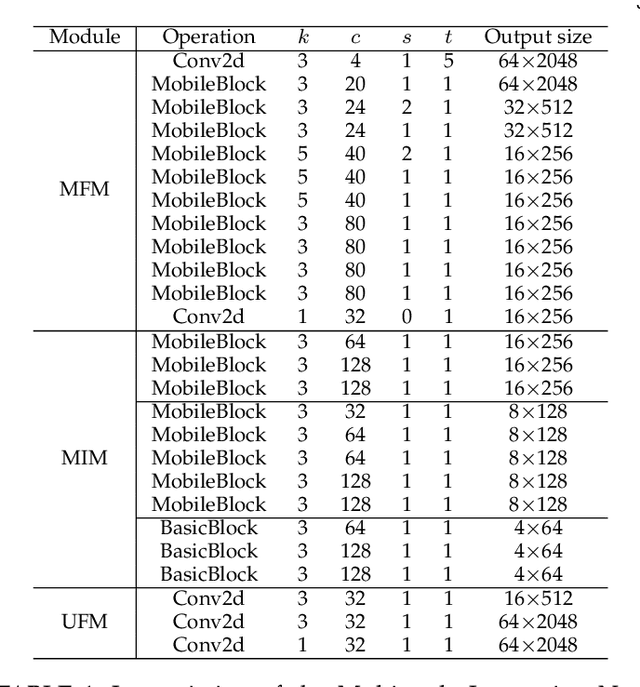
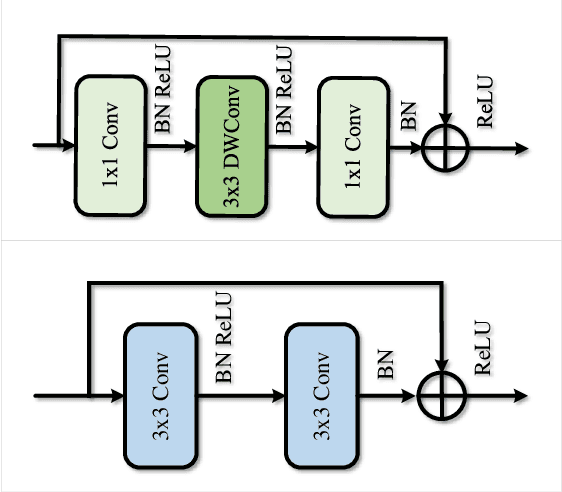

Real-time semantic segmentation of LiDAR data is crucial for autonomously driving vehicles, which are usually equipped with an embedded platform and have limited computational resources. Approaches that operate directly on the point cloud use complex spatial aggregation operations, which are very expensive and difficult to optimize for embedded platforms. They are therefore not suitable for real-time applications with embedded systems. As an alternative, projection-based methods are more efficient and can run on embedded platforms. However, the current state-of-the-art projection-based methods do not achieve the same accuracy as point-based methods and use millions of parameters. In this paper, we therefore propose a projection-based method, called Multi-scale Interaction Network (MINet), which is very efficient and accurate. The network uses multiple paths with different scales and balances the computational resources between the scales. Additional dense interactions between the scales avoid redundant computations and make the network highly efficient. The proposed network outperforms point-based, image-based, and projection-based methods in terms of accuracy, number of parameters, and runtime. Moreover, the network processes more than 24 scans per second on an embedded platform, which is higher than the framerates of LiDAR sensors. The network is therefore suitable for autonomous vehicles.
Audio- and Gaze-driven Facial Animation of Codec Avatars
Aug 11, 2020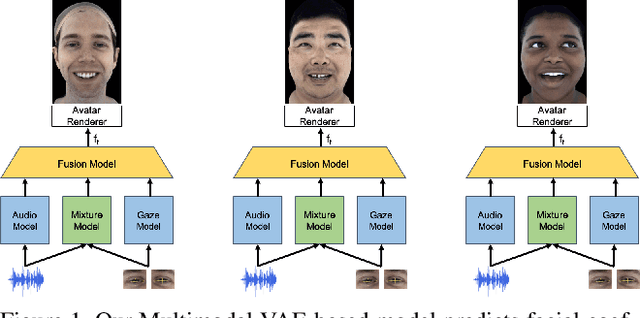
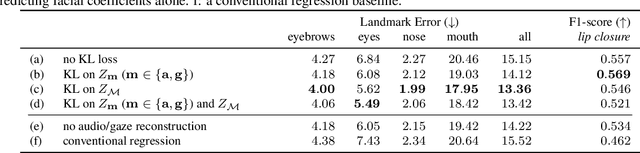
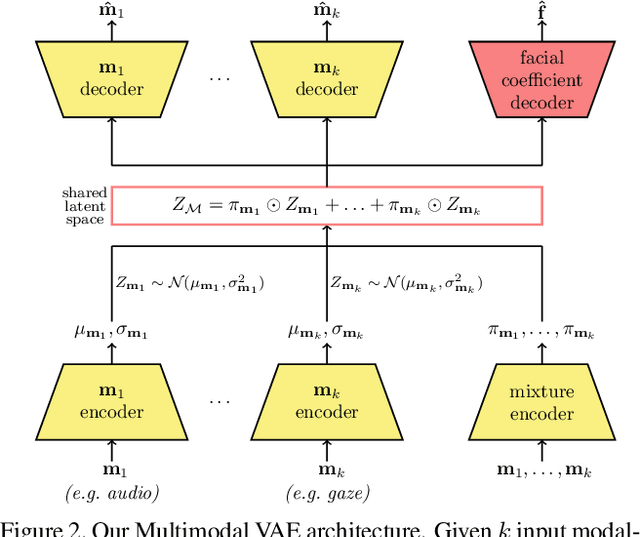
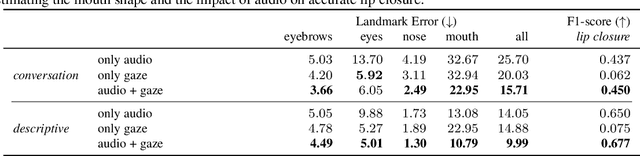
Codec Avatars are a recent class of learned, photorealistic face models that accurately represent the geometry and texture of a person in 3D (i.e., for virtual reality), and are almost indistinguishable from video. In this paper we describe the first approach to animate these parametric models in real-time which could be deployed on commodity virtual reality hardware using audio and/or eye tracking. Our goal is to display expressive conversations between individuals that exhibit important social signals such as laughter and excitement solely from latent cues in our lossy input signals. To this end we collected over 5 hours of high frame rate 3D face scans across three participants including traditional neutral speech as well as expressive and conversational speech. We investigate a multimodal fusion approach that dynamically identifies which sensor encoding should animate which parts of the face at any time. See the supplemental video which demonstrates our ability to generate full face motion far beyond the typically neutral lip articulations seen in competing work: https://research.fb.com/videos/audio-and-gaze-driven-facial-animation-of-codec-avatars/
Projected-point-based Segmentation: A New Paradigm for LiDAR Point Cloud Segmentation
Aug 10, 2020
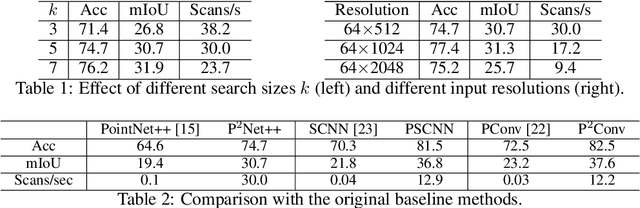
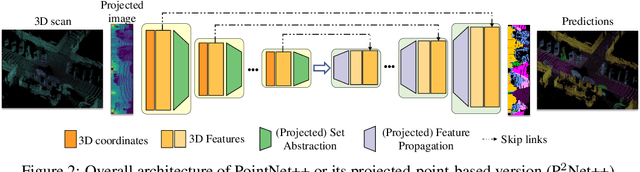

Most point-based semantic segmentation methods are designed for indoor scenarios, but many applications such as autonomous driving vehicles require accurate segmentation for outdoor scenarios. For this goal, light detection and ranging (LiDAR) sensors are often used to collect outdoor environmental data. The problem is that directly applying previous point-based segmentation methods to LiDAR point clouds usually leads to unsatisfactory results due to the domain gap between indoor and outdoor scenarios. To address such a domain gap, we propose a new paradigm, namely projected-point-based methods, to transform point-based methods to a suitable form for LiDAR point cloud segmentation by utilizing the characteristics of LiDAR point clouds. Specifically, we utilize the inherent ordered information of LiDAR points for point sampling and grouping, thus reducing unnecessary computation. All computations are carried out on the projected image, and there are only pointwise convolutions and matrix multiplication in projected-point-based methods. We compare projected-point-based methods with point-based methods on the challenging SemanticKITTI dataset, and experimental results demonstrate that projected-point-based methods achieve better accuracy than all baselines more efficiently. Even with a simple baseline architecture, projected-point-based methods perform favorably against previous state-of-the-art methods. The code will be released upon paper acceptance.
MS-TCN++: Multi-Stage Temporal Convolutional Network for Action Segmentation
Jun 16, 2020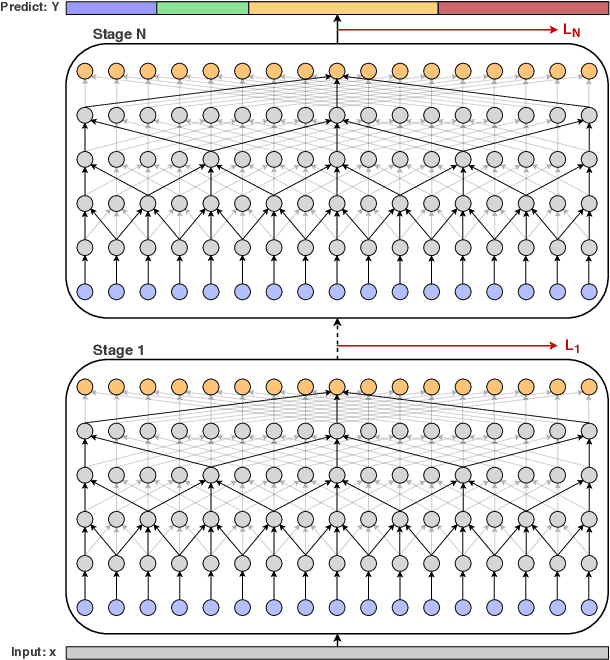
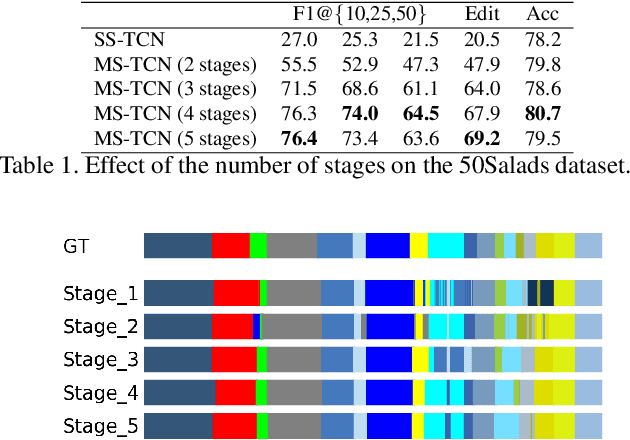
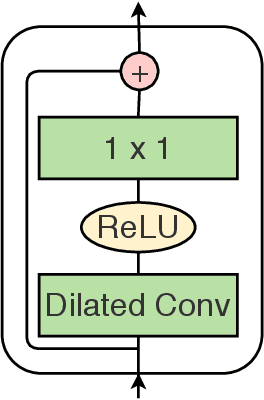

With the success of deep learning in classifying short trimmed videos, more attention has been focused on temporally segmenting and classifying activities in long untrimmed videos. State-of-the-art approaches for action segmentation utilize several layers of temporal convolution and temporal pooling. Despite the capabilities of these approaches in capturing temporal dependencies, their predictions suffer from over-segmentation errors. In this paper, we propose a multi-stage architecture for the temporal action segmentation task that overcomes the limitations of the previous approaches. The first stage generates an initial prediction that is refined by the next ones. In each stage we stack several layers of dilated temporal convolutions covering a large receptive field with few parameters. While this architecture already performs well, lower layers still suffer from a small receptive field. To address this limitation, we propose a dual dilated layer that combines both large and small receptive fields. We further decouple the design of the first stage from the refining stages to address the different requirements of these stages. Extensive evaluation shows the effectiveness of the proposed model in capturing long-range dependencies and recognizing action segments. Our models achieve state-of-the-art results on three datasets: 50Salads, Georgia Tech Egocentric Activities (GTEA), and the Breakfast dataset.