 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInHabit: Leveraging Image Foundation Models for Scalable 3D Human Placement
Apr 21, 2026Training embodied agents to understand 3D scenes as humans do requires large-scale data of people meaningfully interacting with diverse environments, yet such data is scarce. Real-world motion capture is costly and limited to controlled settings, while existing synthetic datasets rely on simple geometric heuristics that ignore rich scene context. In contrast, 2D foundation models trained on internet-scale data have implicitly acquired commonsense knowledge of human-environment interactions. To transfer this knowledge into 3D, we introduce InHabit, a fully automatic and scalable data generator for populating 3D scenes with interacting humans. InHabit follows a render-generate-lift principle: given a rendered 3D scene, a vision-language model proposes contextually meaningful actions, an image-editing model inserts a human, and an optimization procedure lifts the edited result into physically plausible SMPL-X bodies aligned with the scene geometry. Applied to Habitat-Matterport3D, InHabit produces the first large-scale photorealistic 3D human-scene interaction dataset, containing 78K samples across 800 building-scale scenes with complete 3D geometry, SMPL-X bodies, and RGB images. Augmenting standard training data with our samples improves RGB-based 3D human-scene reconstruction and contact estimation, and in a perceptual user study our data is preferred in 78% of cases over the state of the art.
Are Pose Estimators Ready for the Open World? STAGE: Synthetic Data Generation Toolkit for Auditing 3D Human Pose Estimators
Aug 28, 2024



The estimation of 3D human poses from images has progressed tremendously over the last few years as measured on standard benchmarks. However, performance in the open world remains underexplored, as current benchmarks cannot capture its full extent. Especially in safety-critical systems, it is crucial that 3D pose estimators are audited before deployment, and their sensitivity towards single factors or attributes occurring in the operational domain is thoroughly examined. Nevertheless, we currently lack a benchmark that would enable such fine-grained analysis. We thus present STAGE, a GenAI data toolkit for auditing 3D human pose estimators. We enable a text-to-image model to control the 3D human body pose in the generated image. This allows us to create customized annotated data covering a wide range of open-world attributes. We leverage STAGE and generate a series of benchmarks to audit the sensitivity of popular pose estimators towards attributes such as gender, ethnicity, age, clothing, location, and weather. Our results show that the presence of such naturally occurring attributes can cause severe degradation in the performance of pose estimators and leads us to question if they are ready for open-world deployment.
Domain-Aware Fine-Tuning of Foundation Models
Jul 03, 2024Foundation models (FMs) have revolutionized computer vision, enabling effective learning across different domains. However, their performance under domain shift is yet underexplored. This paper investigates the zero-shot domain adaptation potential of FMs by comparing different backbone architectures and introducing novel domain-aware components that leverage domain related textual embeddings. We propose domain adaptive normalization, termed as Domino, which explicitly leverages domain embeddings during fine-tuning, thus making the model domain aware. Ultimately, Domino enables more robust computer vision models that can adapt effectively to various unseen domains.
Label-free Neural Semantic Image Synthesis
Jul 01, 2024
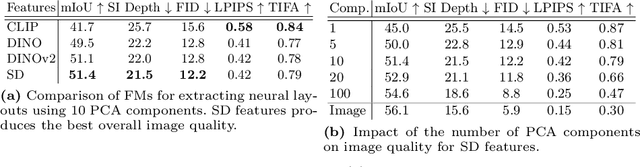
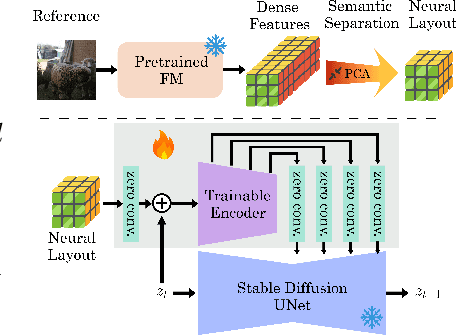
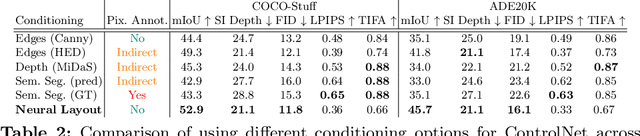
Recent work has shown great progress in integrating spatial conditioning to control large, pre-trained text-to-image diffusion models. Despite these advances, existing methods describe the spatial image content using hand-crafted conditioning inputs, which are either semantically ambiguous (e.g., edges) or require expensive manual annotations (e.g., semantic segmentation). To address these limitations, we propose a new label-free way of conditioning diffusion models to enable fine-grained spatial control. We introduce the concept of neural semantic image synthesis, which uses neural layouts extracted from pre-trained foundation models as conditioning. Neural layouts are advantageous as they provide rich descriptions of the desired image, containing both semantics and detailed geometry of the scene. We experimentally show that images synthesized via neural semantic image synthesis achieve similar or superior pixel-level alignment of semantic classes compared to those created using expensive semantic label maps. At the same time, they capture better semantics, instance separation, and object orientation than other label-free conditioning options, such as edges or depth. Moreover, we show that images generated by neural layout conditioning can effectively augment real data for training various perception tasks.
ETHER: Efficient Finetuning of Large-Scale Models with Hyperplane Reflections
May 30, 2024Parameter-efficient finetuning (PEFT) has become ubiquitous to adapt foundation models to downstream task requirements while retaining their generalization ability. However, the amount of additionally introduced parameters and compute for successful adaptation and hyperparameter searches can explode quickly, especially when deployed at scale to serve numerous individual requests. To ensure effective, parameter-efficient, and hyperparameter-robust adaptation, we propose the ETHER transformation family, which performs Efficient fineTuning via HypErplane Reflections. By design, ETHER transformations require a minimal number of parameters, are less likely to deteriorate model performance, and exhibit robustness to hyperparameter and learning rate choices. In particular, we introduce ETHER and its relaxation ETHER+, which match or outperform existing PEFT methods with significantly fewer parameters ($\sim$$10$-$100$ times lower than LoRA or OFT) across multiple image synthesis and natural language tasks without exhaustive hyperparameter tuning. Finally, we investigate the recent emphasis on Hyperspherical Energy retention for adaptation and raise questions on its practical utility. The code is available at https://github.com/mwbini/ether.
VSTAR: Generative Temporal Nursing for Longer Dynamic Video Synthesis
Mar 20, 2024Despite tremendous progress in the field of text-to-video (T2V) synthesis, open-sourced T2V diffusion models struggle to generate longer videos with dynamically varying and evolving content. They tend to synthesize quasi-static videos, ignoring the necessary visual change-over-time implied in the text prompt. At the same time, scaling these models to enable longer, more dynamic video synthesis often remains computationally intractable. To address this challenge, we introduce the concept of Generative Temporal Nursing (GTN), where we aim to alter the generative process on the fly during inference to improve control over the temporal dynamics and enable generation of longer videos. We propose a method for GTN, dubbed VSTAR, which consists of two key ingredients: 1) Video Synopsis Prompting (VSP) - automatic generation of a video synopsis based on the original single prompt leveraging LLMs, which gives accurate textual guidance to different visual states of longer videos, and 2) Temporal Attention Regularization (TAR) - a regularization technique to refine the temporal attention units of the pre-trained T2V diffusion models, which enables control over the video dynamics. We experimentally showcase the superiority of the proposed approach in generating longer, visually appealing videos over existing open-sourced T2V models. We additionally analyze the temporal attention maps realized with and without VSTAR, demonstrating the importance of applying our method to mitigate neglect of the desired visual change over time.
Adversarial Supervision Makes Layout-to-Image Diffusion Models Thrive
Jan 16, 2024Despite the recent advances in large-scale diffusion models, little progress has been made on the layout-to-image (L2I) synthesis task. Current L2I models either suffer from poor editability via text or weak alignment between the generated image and the input layout. This limits their usability in practice. To mitigate this, we propose to integrate adversarial supervision into the conventional training pipeline of L2I diffusion models (ALDM). Specifically, we employ a segmentation-based discriminator which provides explicit feedback to the diffusion generator on the pixel-level alignment between the denoised image and the input layout. To encourage consistent adherence to the input layout over the sampling steps, we further introduce the multistep unrolling strategy. Instead of looking at a single timestep, we unroll a few steps recursively to imitate the inference process, and ask the discriminator to assess the alignment of denoised images with the layout over a certain time window. Our experiments show that ALDM enables layout faithfulness of the generated images, while allowing broad editability via text prompts. Moreover, we showcase its usefulness for practical applications: by synthesizing target distribution samples via text control, we improve domain generalization of semantic segmentation models by a large margin (~12 mIoU points).
Divide & Bind Your Attention for Improved Generative Semantic Nursing
Jul 20, 2023



Emerging large-scale text-to-image generative models, e.g., Stable Diffusion (SD), have exhibited overwhelming results with high fidelity. Despite the magnificent progress, current state-of-the-art models still struggle to generate images fully adhering to the input prompt. Prior work, Attend & Excite, has introduced the concept of Generative Semantic Nursing (GSN), aiming to optimize cross-attention during inference time to better incorporate the semantics. It demonstrates promising results in generating simple prompts, e.g., ``a cat and a dog''. However, its efficacy declines when dealing with more complex prompts, and it does not explicitly address the problem of improper attribute binding. To address the challenges posed by complex prompts or scenarios involving multiple entities and to achieve improved attribute binding, we propose Divide & Bind. We introduce two novel loss objectives for GSN: a novel attendance loss and a binding loss. Our approach stands out in its ability to faithfully synthesize desired objects with improved attribute alignment from complex prompts and exhibits superior performance across multiple evaluation benchmarks. More videos and updates can be found on the project page \url{https://sites.google.com/view/divide-and-bind}.
Intra- & Extra-Source Exemplar-Based Style Synthesis for Improved Domain Generalization
Jul 02, 2023



The generalization with respect to domain shifts, as they frequently appear in applications such as autonomous driving, is one of the remaining big challenges for deep learning models. Therefore, we propose an exemplar-based style synthesis pipeline to improve domain generalization in semantic segmentation. Our method is based on a novel masked noise encoder for StyleGAN2 inversion. The model learns to faithfully reconstruct the image, preserving its semantic layout through noise prediction. Using the proposed masked noise encoder to randomize style and content combinations in the training set, i.e., intra-source style augmentation (ISSA) effectively increases the diversity of training data and reduces spurious correlation. As a result, we achieve up to $12.4\%$ mIoU improvements on driving-scene semantic segmentation under different types of data shifts, i.e., changing geographic locations, adverse weather conditions, and day to night. ISSA is model-agnostic and straightforwardly applicable with CNNs and Transformers. It is also complementary to other domain generalization techniques, e.g., it improves the recent state-of-the-art solution RobustNet by $3\%$ mIoU in Cityscapes to Dark Z\"urich. In addition, we demonstrate the strong plug-n-play ability of the proposed style synthesis pipeline, which is readily usable for extra-source exemplars e.g., web-crawled images, without any retraining or fine-tuning. Moreover, we study a new use case to indicate neural network's generalization capability by building a stylized proxy validation set. This application has significant practical sense for selecting models to be deployed in the open-world environment. Our code is available at \url{https://github.com/boschresearch/ISSA}.
Discovering Class-Specific GAN Controls for Semantic Image Synthesis
Dec 02, 2022



Prior work has extensively studied the latent space structure of GANs for unconditional image synthesis, enabling global editing of generated images by the unsupervised discovery of interpretable latent directions. However, the discovery of latent directions for conditional GANs for semantic image synthesis (SIS) has remained unexplored. In this work, we specifically focus on addressing this gap. We propose a novel optimization method for finding spatially disentangled class-specific directions in the latent space of pretrained SIS models. We show that the latent directions found by our method can effectively control the local appearance of semantic classes, e.g., changing their internal structure, texture or color independently from each other. Visual inspection and quantitative evaluation of the discovered GAN controls on various datasets demonstrate that our method discovers a diverse set of unique and semantically meaningful latent directions for class-specific edits.