 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUME: A Unified Meta-Generalization Framework for Cross-Domain ETA
May 31, 2026Accurate Estimated Time of Arrival (ETA) prediction on checkout page is crucial in instant logistics for enhancing user satisfaction, optimizing dispatching, and controlling operational costs. In international on-demand delivery platforms, where ETA data originates from diverse countries or regions with different patterns, multi-domain modeling is of great importance and has been widely adopted. However, existing methods still face three critical challenges in real-world deployment. First, current multi-domain models struggle to generalize to completely unseen domains, failing to achieve zero-shot prediction during the initial cold-start phase. Second, cross-domain feature spaces are often assumed to be consistent, whereas new domains commonly suffer from structural missingness of offline (statistical) features due to the lack of historical data. Third, such feature missingness often compels industrial systems to model mature and cold-start domains separately, hindering knowledge transfer and increasing maintenance overhead. To address these challenges, we propose \textbf{UME}, a \textbf{U}nified \textbf{M}eta-generalization framework for \textbf{E}TA. Specifically, UME integrates a unified dual-branch architecture with a novel meta-learning mechanism that employs a hypernetwork-based meta learner. By leveraging domain-level knowledge and instance-level context, the meta learner empowers three meta modules to dynamically modulate feature gating, expert attention, and final prediction, capturing cross-domain correlations and facilitating intra-domain adaptation. A knowledge distillation strategy is further introduce to enhance performance. UME has now been deployed in Meituan-keeta delivery platform (the largest international food delivery platform in China). Extensive offline experiments and online A/B tests demonstrate that UME significantly outperforms existing baselines.
RedSage: A Cybersecurity Generalist LLM
Jan 29, 2026Cybersecurity operations demand assistant LLMs that support diverse workflows without exposing sensitive data. Existing solutions either rely on proprietary APIs with privacy risks or on open models lacking domain adaptation. To bridge this gap, we curate 11.8B tokens of cybersecurity-focused continual pretraining data via large-scale web filtering and manual collection of high-quality resources, spanning 28.6K documents across frameworks, offensive techniques, and security tools. Building on this, we design an agentic augmentation pipeline that simulates expert workflows to generate 266K multi-turn cybersecurity samples for supervised fine-tuning. Combined with general open-source LLM data, these resources enable the training of RedSage, an open-source, locally deployable cybersecurity assistant with domain-aware pretraining and post-training. To rigorously evaluate the models, we introduce RedSage-Bench, a benchmark with 30K multiple-choice and 240 open-ended Q&A items covering cybersecurity knowledge, skills, and tool expertise. RedSage is further evaluated on established cybersecurity benchmarks (e.g., CTI-Bench, CyberMetric, SECURE) and general LLM benchmarks to assess broader generalization. At the 8B scale, RedSage achieves consistently better results, surpassing the baseline models by up to +5.59 points on cybersecurity benchmarks and +5.05 points on Open LLM Leaderboard tasks. These findings demonstrate that domain-aware agentic augmentation and pre/post-training can not only enhance cybersecurity-specific expertise but also help to improve general reasoning and instruction-following. All models, datasets, and code are publicly available.
DeepSTA: A Spatial-Temporal Attention Network for Logistics Delivery Timely Rate Prediction in Anomaly Conditions
May 01, 2025



Prediction of couriers' delivery timely rates in advance is essential to the logistics industry, enabling companies to take preemptive measures to ensure the normal operation of delivery services. This becomes even more critical during anomaly conditions like the epidemic outbreak, during which couriers' delivery timely rate will decline markedly and fluctuates significantly. Existing studies pay less attention to the logistics scenario. Moreover, many works focusing on prediction tasks in anomaly scenarios fail to explicitly model abnormal events, e.g., treating external factors equally with other features, resulting in great information loss. Further, since some anomalous events occur infrequently, traditional data-driven methods perform poorly in these scenarios. To deal with them, we propose a deep spatial-temporal attention model, named DeepSTA. To be specific, to avoid information loss, we design an anomaly spatio-temporal learning module that employs a recurrent neural network to model incident information. Additionally, we utilize Node2vec to model correlations between road districts, and adopt graph neural networks and long short-term memory to capture the spatial-temporal dependencies of couriers. To tackle the issue of insufficient training data in abnormal circumstances, we propose an anomaly pattern attention module that adopts a memory network for couriers' anomaly feature patterns storage via attention mechanisms. The experiments on real-world logistics datasets during the COVID-19 outbreak in 2022 show the model outperforms the best baselines by 12.11% in MAE and 13.71% in MSE, demonstrating its superior performance over multiple competitive baselines.
Learning to Estimate Package Delivery Time in Mixed Imbalanced Delivery and Pickup Logistics Services
May 01, 2025Accurately estimating package delivery time is essential to the logistics industry, which enables reasonable work allocation and on-time service guarantee. This becomes even more necessary in mixed logistics scenarios where couriers handle a high volume of delivery and a smaller number of pickup simultaneously. However, most of the related works treat the pickup and delivery patterns on couriers' decision behavior equally, neglecting that the pickup has a greater impact on couriers' decision-making compared to the delivery due to its tighter time constraints. In such context, we have three main challenges: 1) multiple spatiotemporal factors are intricately interconnected, significantly affecting couriers' delivery behavior; 2) pickups have stricter time requirements but are limited in number, making it challenging to model their effects on couriers' delivery process; 3) couriers' spatial mobility patterns are critical determinants of their delivery behavior, but have been insufficiently explored. To deal with these, we propose TransPDT, a Transformer-based multi-task package delivery time prediction model. We first employ the Transformer encoder architecture to capture the spatio-temporal dependencies of couriers' historical travel routes and pending package sets. Then we design the pattern memory to learn the patterns of pickup in the imbalanced dataset via attention mechanism. We also set the route prediction as an auxiliary task of delivery time prediction, and incorporate the prior courier spatial movement regularities in prediction. Extensive experiments on real industry-scale datasets demonstrate the superiority of our method. A system based on TransPDT is deployed internally in JD Logistics to track more than 2000 couriers handling hundreds of thousands of packages per day in Beijing.
Video-Panda: Parameter-efficient Alignment for Encoder-free Video-Language Models
Dec 24, 2024



We present an efficient encoder-free approach for video-language understanding that achieves competitive performance while significantly reducing computational overhead. Current video-language models typically rely on heavyweight image encoders (300M-1.1B parameters) or video encoders (1B-1.4B parameters), creating a substantial computational burden when processing multi-frame videos. Our method introduces a novel Spatio-Temporal Alignment Block (STAB) that directly processes video inputs without requiring pre-trained encoders while using only 45M parameters for visual processing - at least a 6.5$\times$ reduction compared to traditional approaches. The STAB architecture combines Local Spatio-Temporal Encoding for fine-grained feature extraction, efficient spatial downsampling through learned attention and separate mechanisms for modeling frame-level and video-level relationships. Our model achieves comparable or superior performance to encoder-based approaches for open-ended video question answering on standard benchmarks. The fine-grained video question-answering evaluation demonstrates our model's effectiveness, outperforming the encoder-based approaches Video-ChatGPT and Video-LLaVA in key aspects like correctness and temporal understanding. Extensive ablation studies validate our architectural choices and demonstrate the effectiveness of our spatio-temporal modeling approach while achieving 3-4$\times$ faster processing speeds than previous methods. Code is available at \url{https://github.com/jh-yi/Video-Panda}.
MV-Match: Multi-View Matching for Domain-Adaptive Identification of Plant Nutrient Deficiencies
Sep 02, 2024



An early, non-invasive, and on-site detection of nutrient deficiencies is critical to enable timely actions to prevent major losses of crops caused by lack of nutrients. While acquiring labeled data is very expensive, collecting images from multiple views of a crop is straightforward. Despite its relevance for practical applications, unsupervised domain adaptation where multiple views are available for the labeled source domain as well as the unlabeled target domain is an unexplored research area. In this work, we thus propose an approach that leverages multiple camera views in the source and target domain for unsupervised domain adaptation. We evaluate the proposed approach on two nutrient deficiency datasets. The proposed method achieves state-of-the-art results on both datasets compared to other unsupervised domain adaptation methods. The dataset and source code are available at https://github.com/jh-yi/MV-Match.
Rethinking temporal self-similarity for repetitive action counting
Jul 12, 2024



Counting repetitive actions in long untrimmed videos is a challenging task that has many applications such as rehabilitation. State-of-the-art methods predict action counts by first generating a temporal self-similarity matrix (TSM) from the sampled frames and then feeding the matrix to a predictor network. The self-similarity matrix, however, is not an optimal input to a network since it discards too much information from the frame-wise embeddings. We thus rethink how a TSM can be utilized for counting repetitive actions and propose a framework that learns embeddings and predicts action start probabilities at full temporal resolution. The number of repeated actions is then inferred from the action start probabilities. In contrast to current approaches that have the TSM as an intermediate representation, we propose a novel loss based on a generated reference TSM, which enforces that the self-similarity of the learned frame-wise embeddings is consistent with the self-similarity of repeated actions. The proposed framework achieves state-of-the-art results on three datasets, i.e., RepCount, UCFRep, and Countix.
SSGVS: Semantic Scene Graph-to-Video Synthesis
Nov 17, 2022As a natural extension of the image synthesis task, video synthesis has attracted a lot of interest recently. Many image synthesis works utilize class labels or text as guidance. However, neither labels nor text can provide explicit temporal guidance, such as when an action starts or ends. To overcome this limitation, we introduce semantic video scene graphs as input for video synthesis, as they represent the spatial and temporal relationships between objects in the scene. Since video scene graphs are usually temporally discrete annotations, we propose a video scene graph (VSG) encoder that not only encodes the existing video scene graphs but also predicts the graph representations for unlabeled frames. The VSG encoder is pre-trained with different contrastive multi-modal losses. A semantic scene graph-to-video synthesis framework (SSGVS), based on the pre-trained VSG encoder, VQ-VAE, and auto-regressive Transformer, is proposed to synthesize a video given an initial scene image and a non-fixed number of semantic scene graphs. We evaluate SSGVS and other state-of-the-art video synthesis models on the Action Genome dataset and demonstrate the positive significance of video scene graphs in video synthesis. The source code will be released.
Pose Refinement Graph Convolutional Network for Skeleton-based Action Recognition
Oct 14, 2020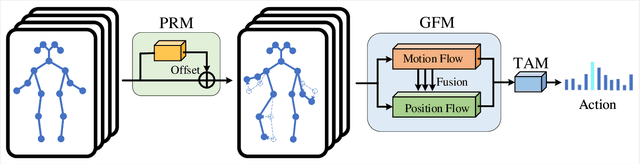
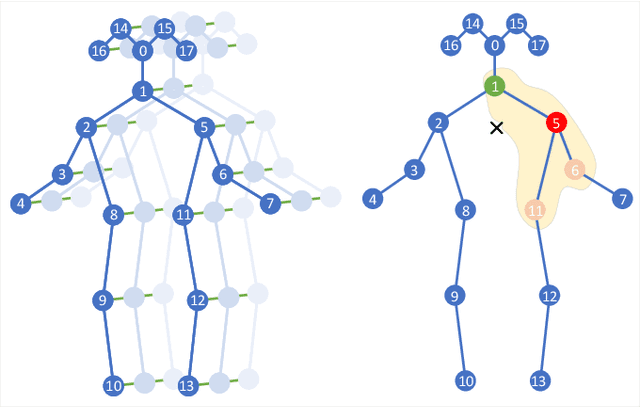
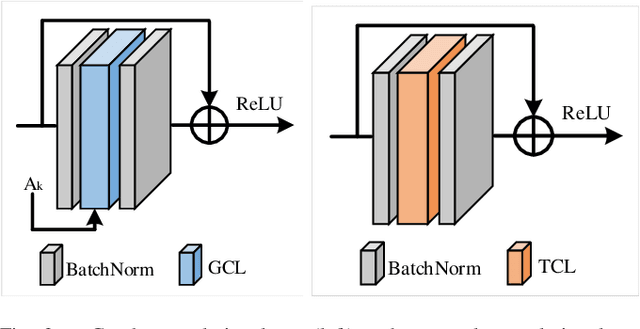
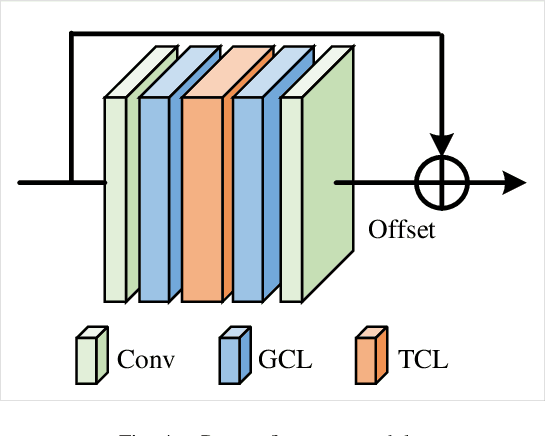
With the advances in capturing 2D or 3D skeleton data, skeleton-based action recognition has received an increasing interest over the last years. As skeleton data is commonly represented by graphs, graph convolutional networks have been proposed for this task. While current graph convolutional networks accurately recognize actions, they are too expensive for robotics applications where limited computational resources are available. In this paper, we therefore propose a highly efficient graph convolutional network that addresses the limitations of previous works. This is achieved by a parallel structure that gradually fuses motion and spatial information and by reducing the temporal resolution as early as possible. Furthermore, we explicitly address the issue that human poses can contain errors. To this end, the network first refines the poses before they are further processed to recognize the action. We therefore call the network Pose Refinement Graph Convolutional Network. Compared to other graph convolutional networks, our network requires 86\%-93\% less parameters and reduces the floating point operations by 89%-96% while achieving a comparable accuracy. It therefore provides a much better trade-off between accuracy, memory footprint and processing time, which makes it suitable for robotics applications.