 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Domain Adaptation via Clustering Uncertainty-weighted Embeddings
Oct 16, 2020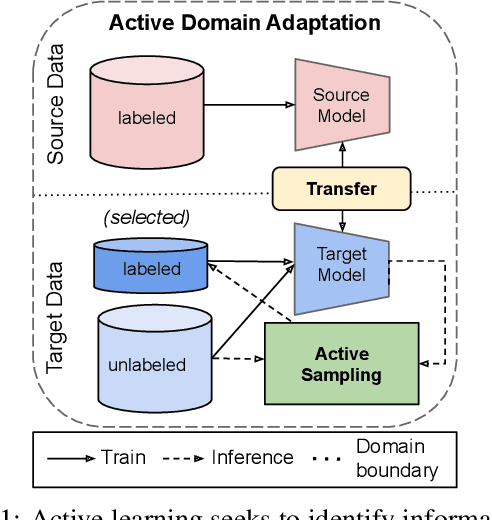
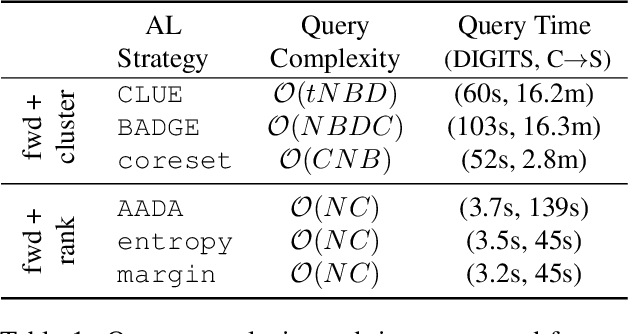
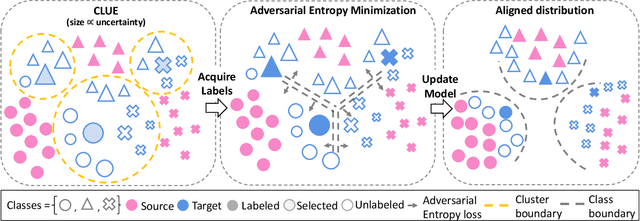
Generalizing deep neural networks to new target domains is critical to their real-world utility. In practice, it may be feasible to get some target data labeled, but to be cost-effective it is desirable to select a maximally-informative subset via active learning (AL). We study this problem of AL under a domain shift. We empirically demonstrate how existing AL approaches based solely on model uncertainty or representative sampling are suboptimal for active domain adaptation. Our algorithm, Active Domain Adaptation via CLustering Uncertainty-weighted Embeddings (ADA-CLUE), i) identifies diverse datapoints for labeling that are both uncertain under the model and representative of unlabeled target data, and ii) leverages the available source and target data for adaptation by optimizing a semi-supervised adversarial entropy loss that is complementary to our active sampling objective. On standard image classification benchmarks for domain adaptation, ADA-CLUE consistently performs as well or better than competing active adaptation, active learning, and domain adaptation methods across shift severities, model initializations, and labeling budgets.
Auxiliary Task Reweighting for Minimum-data Learning
Oct 16, 2020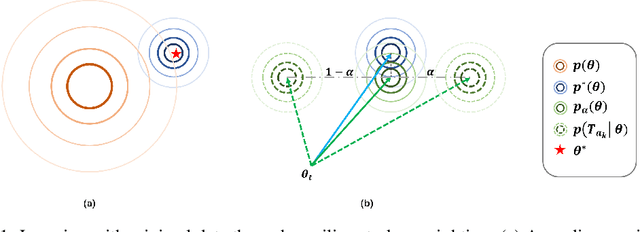
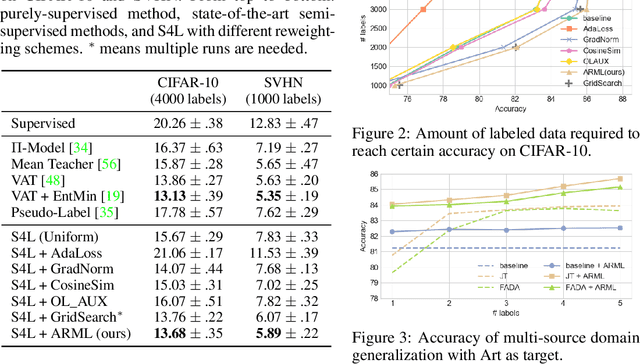
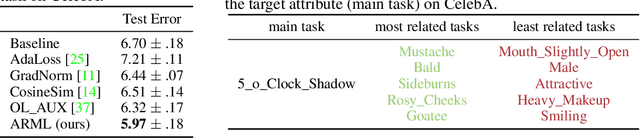
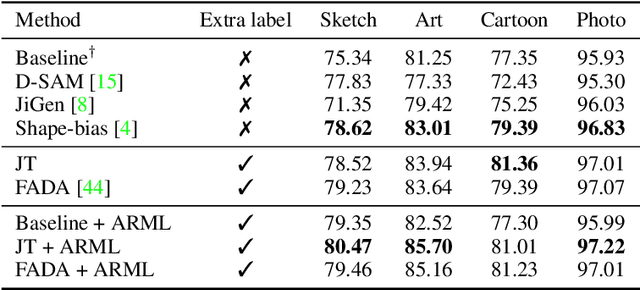
Supervised learning requires a large amount of training data, limiting its application where labeled data is scarce. To compensate for data scarcity, one possible method is to utilize auxiliary tasks to provide additional supervision for the main task. Assigning and optimizing the importance weights for different auxiliary tasks remains an crucial and largely understudied research question. In this work, we propose a method to automatically reweight auxiliary tasks in order to reduce the data requirement on the main task. Specifically, we formulate the weighted likelihood function of auxiliary tasks as a surrogate prior for the main task. By adjusting the auxiliary task weights to minimize the divergence between the surrogate prior and the true prior of the main task, we obtain a more accurate prior estimation, achieving the goal of minimizing the required amount of training data for the main task and avoiding a costly grid search. In multiple experimental settings (e.g. semi-supervised learning, multi-label classification), we demonstrate that our algorithm can effectively utilize limited labeled data of the main task with the benefit of auxiliary tasks compared with previous task reweighting methods. We also show that under extreme cases with only a few extra examples (e.g. few-shot domain adaptation), our algorithm results in significant improvement over the baseline.
Integrating Egocentric Localization for More Realistic Point-Goal Navigation Agents
Sep 07, 2020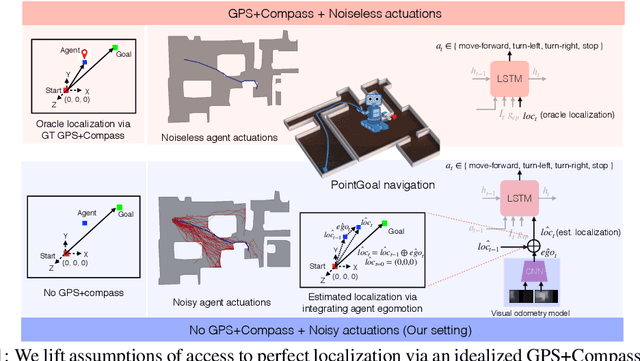
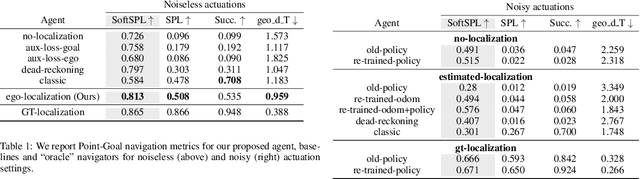
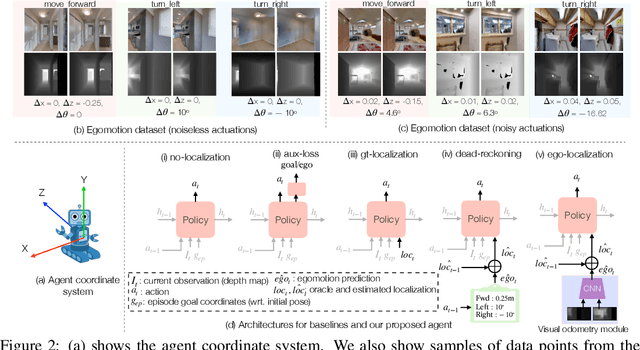
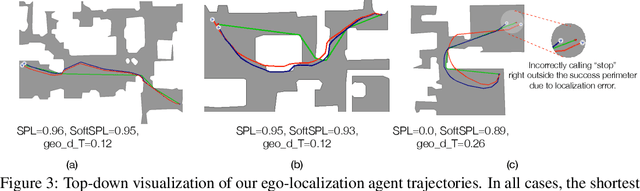
Recent work has presented embodied agents that can navigate to point-goal targets in novel indoor environments with near-perfect accuracy. However, these agents are equipped with idealized sensors for localization and take deterministic actions. This setting is practically sterile by comparison to the dirty reality of noisy sensors and actuations in the real world -- wheels can slip, motion sensors have error, actuations can rebound. In this work, we take a step towards this noisy reality, developing point-goal navigation agents that rely on visual estimates of egomotion under noisy action dynamics. We find these agents outperform naive adaptions of current point-goal agents to this setting as well as those incorporating classic localization baselines. Further, our model conceptually divides learning agent dynamics or odometry (where am I?) from task-specific navigation policy (where do I want to go?). This enables a seamless adaption to changing dynamics (a different robot or floor type) by simply re-calibrating the visual odometry model -- circumventing the expense of re-training of the navigation policy. Our agent was the runner-up in the PointNav track of CVPR 2020 Habitat Challenge.
TIDE: A General Toolbox for Identifying Object Detection Errors
Aug 31, 2020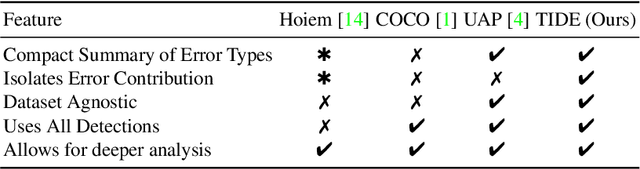
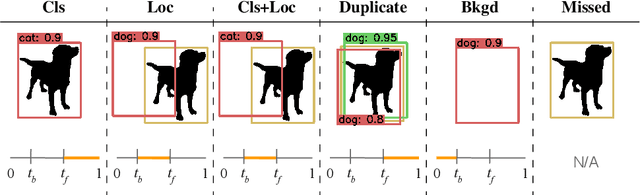
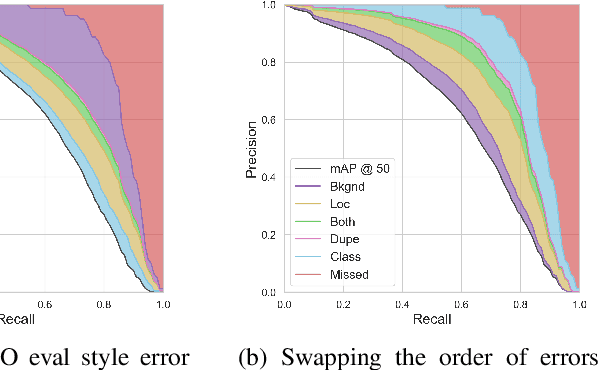
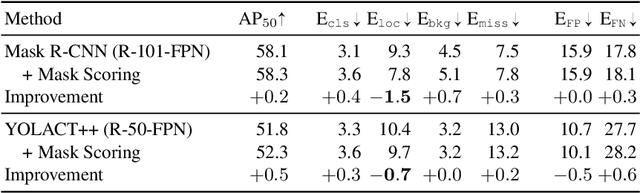
We introduce TIDE, a framework and associated toolbox for analyzing the sources of error in object detection and instance segmentation algorithms. Importantly, our framework is applicable across datasets and can be applied directly to output prediction files without required knowledge of the underlying prediction system. Thus, our framework can be used as a drop-in replacement for the standard mAP computation while providing a comprehensive analysis of each model's strengths and weaknesses. We segment errors into six types and, crucially, are the first to introduce a technique for measuring the contribution of each error in a way that isolates its effect on overall performance. We show that such a representation is critical for drawing accurate, comprehensive conclusions through in-depth analysis across 4 datasets and 7 recognition models. Available at https://dbolya.github.io/tide/
Learning to Balance Specificity and Invariance for In and Out of Domain Generalization
Aug 28, 2020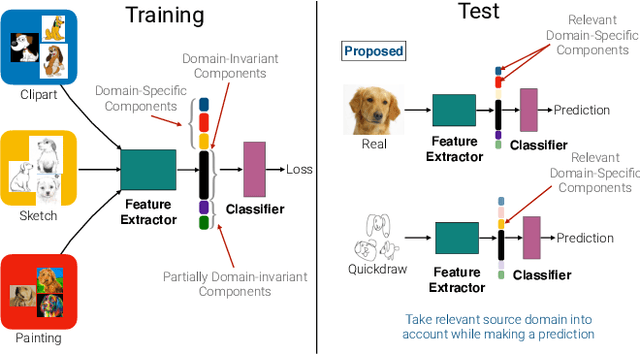
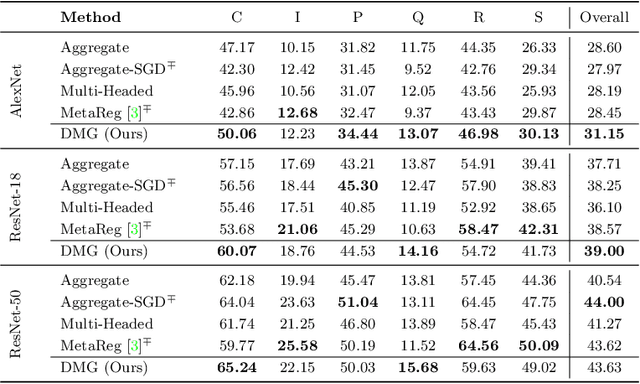
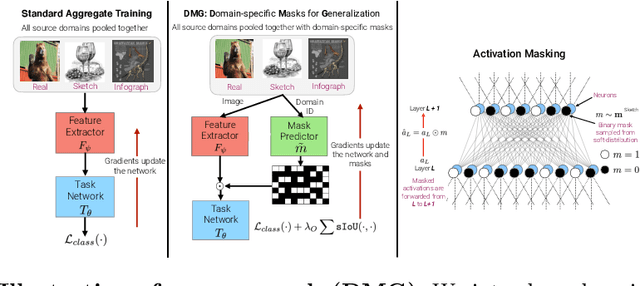
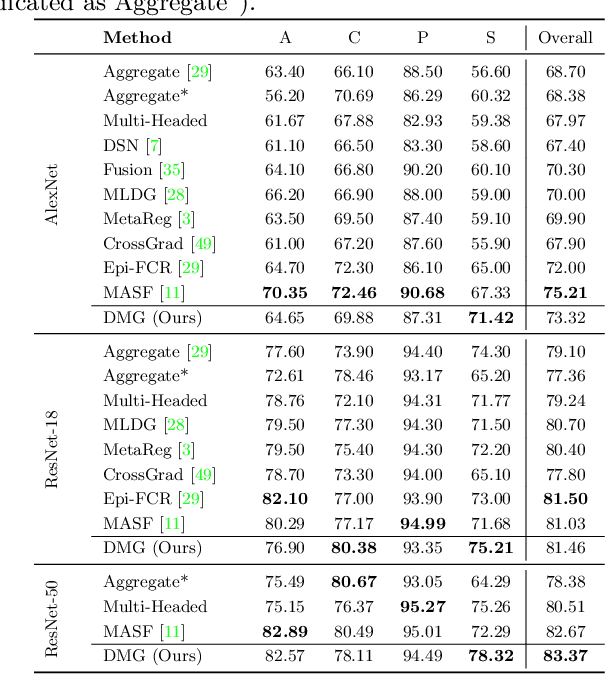
We introduce Domain-specific Masks for Generalization, a model for improving both in-domain and out-of-domain generalization performance. For domain generalization, the goal is to learn from a set of source domains to produce a single model that will best generalize to an unseen target domain. As such, many prior approaches focus on learning representations which persist across all source domains with the assumption that these domain agnostic representations will generalize well. However, often individual domains contain characteristics which are unique and when leveraged can significantly aid in-domain recognition performance. To produce a model which best generalizes to both seen and unseen domains, we propose learning domain specific masks. The masks are encouraged to learn a balance of domain-invariant and domain-specific features, thus enabling a model which can benefit from the predictive power of specialized features while retaining the universal applicability of domain-invariant features. We demonstrate competitive performance compared to naive baselines and state-of-the-art methods on both PACS and DomainNet.
Likelihood Landscapes: A Unifying Principle Behind Many Adversarial Defenses
Aug 25, 2020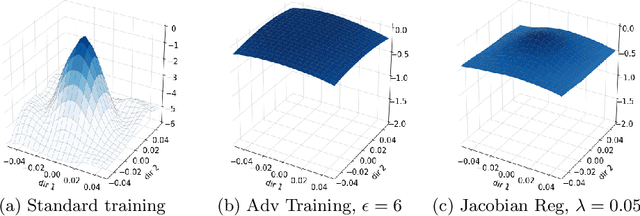
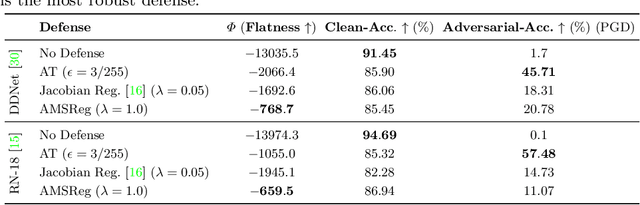
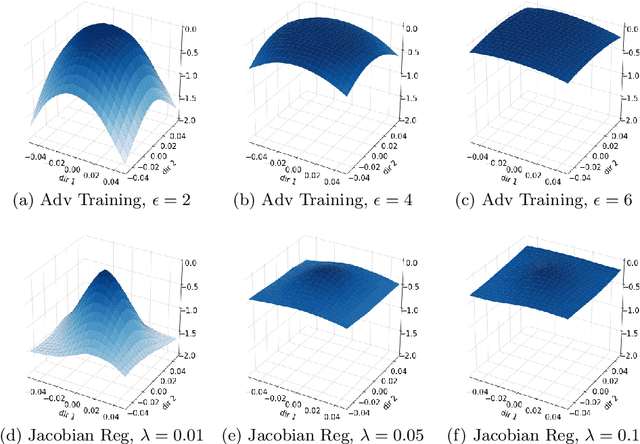
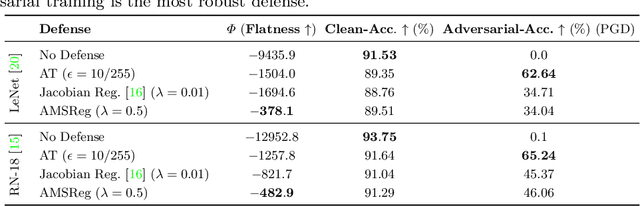
Convolutional Neural Networks have been shown to be vulnerable to adversarial examples, which are known to locate in subspaces close to where normal data lies but are not naturally occurring and of low probability. In this work, we investigate the potential effect defense techniques have on the geometry of the likelihood landscape - likelihood of the input images under the trained model. We first propose a way to visualize the likelihood landscape leveraging an energy-based model interpretation of discriminative classifiers. Then we introduce a measure to quantify the flatness of the likelihood landscape. We observe that a subset of adversarial defense techniques results in a similar effect of flattening the likelihood landscape. We further explore directly regularizing towards a flat landscape for adversarial robustness.
Analyzing Visual Representations in Embodied Navigation Tasks
Mar 12, 2020
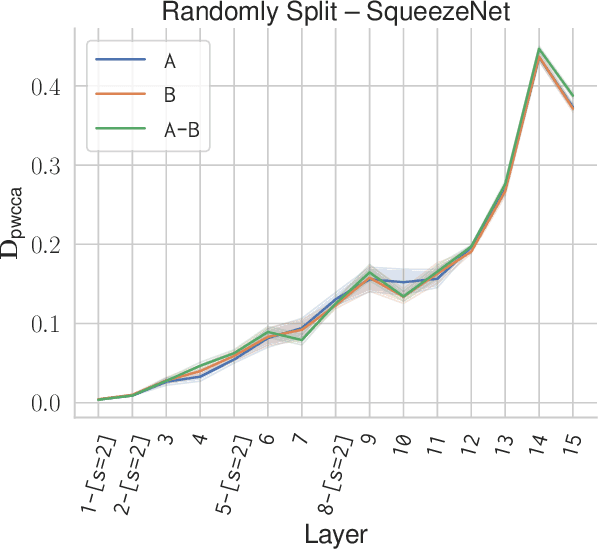
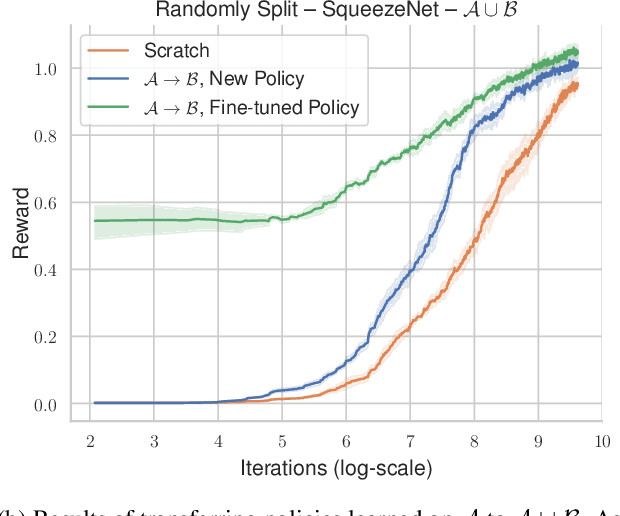
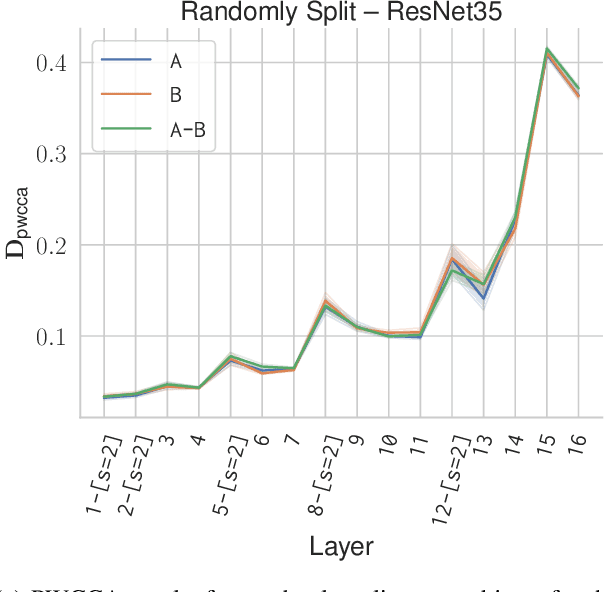
Recent advances in deep reinforcement learning require a large amount of training data and generally result in representations that are often over specialized to the target task. In this work, we present a methodology to study the underlying potential causes for this specialization. We use the recently proposed projection weighted Canonical Correlation Analysis (PWCCA) to measure the similarity of visual representations learned in the same environment by performing different tasks. We then leverage our proposed methodology to examine the task dependence of visual representations learned on related but distinct embodied navigation tasks. Surprisingly, we find that slight differences in task have no measurable effect on the visual representation for both SqueezeNet and ResNet architectures. We then empirically demonstrate that visual representations learned on one task can be effectively transferred to a different task.
Representation Learning Through Latent Canonicalizations
Feb 26, 2020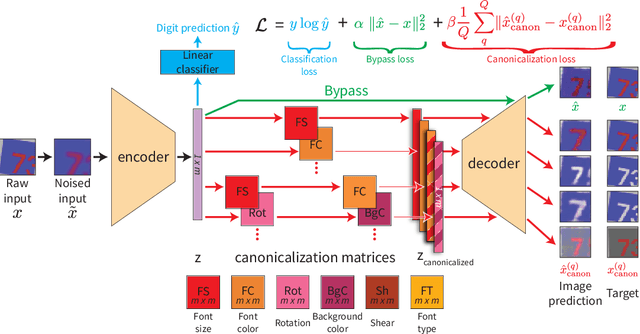
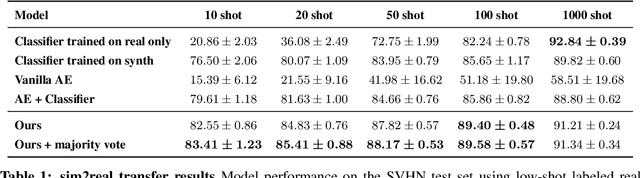

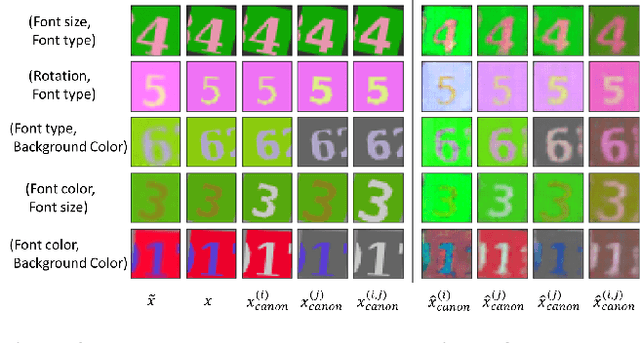
We seek to learn a representation on a large annotated data source that generalizes to a target domain using limited new supervision. Many prior approaches to this problem have focused on learning "disentangled" representations so that as individual factors vary in a new domain, only a portion of the representation need be updated. In this work, we seek the generalization power of disentangled representations, but relax the requirement of explicit latent disentanglement and instead encourage linearity of individual factors of variation by requiring them to be manipulable by learned linear transformations. We dub these transformations latent canonicalizers, as they aim to modify the value of a factor to a pre-determined (but arbitrary) canonical value (e.g., recoloring the image foreground to black). Assuming a source domain with access to meta-labels specifying the factors of variation within an image, we demonstrate experimentally that our method helps reduce the number of observations needed to generalize to a similar target domain when compared to a number of supervised baselines.
Instance adaptive adversarial training: Improved accuracy tradeoffs in neural nets
Oct 17, 2019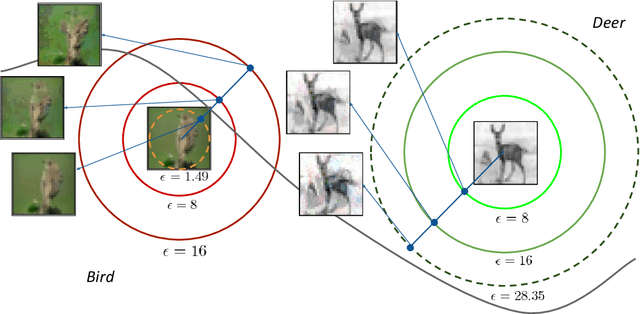
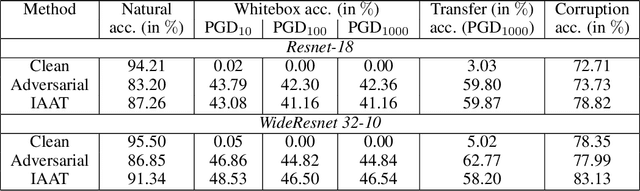

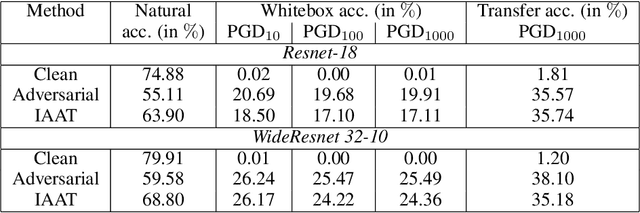
Adversarial training is by far the most successful strategy for improving robustness of neural networks to adversarial attacks. Despite its success as a defense mechanism, adversarial training fails to generalize well to unperturbed test set. We hypothesize that this poor generalization is a consequence of adversarial training with uniform perturbation radius around every training sample. Samples close to decision boundary can be morphed into a different class under a small perturbation budget, and enforcing large margins around these samples produce poor decision boundaries that generalize poorly. Motivated by this hypothesis, we propose instance adaptive adversarial training -- a technique that enforces sample-specific perturbation margins around every training sample. We show that using our approach, test accuracy on unperturbed samples improve with a marginal drop in robustness. Extensive experiments on CIFAR-10, CIFAR-100 and Imagenet datasets demonstrate the effectiveness of our proposed approach.
Robust Learning with Jacobian Regularization
Aug 07, 2019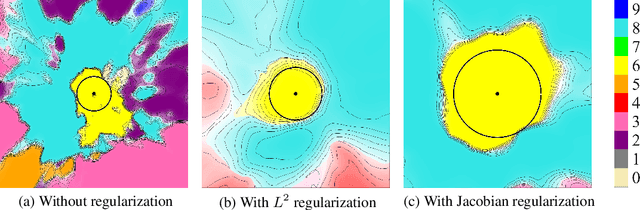
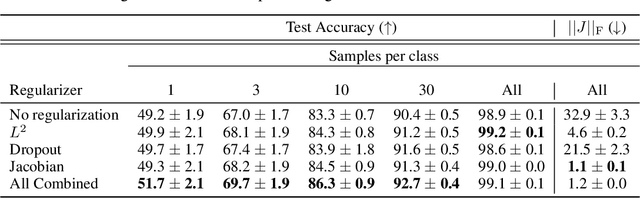
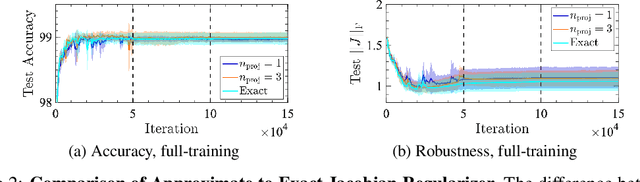
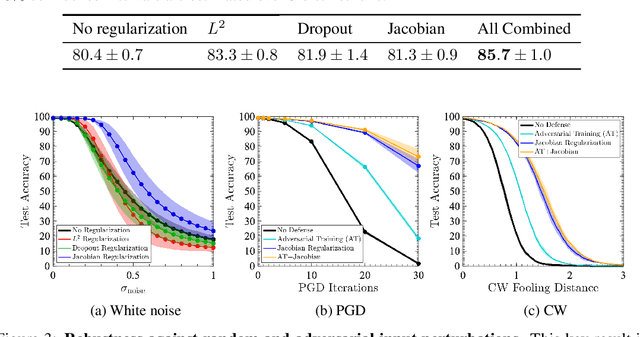
Design of reliable systems must guarantee stability against input perturbations. In machine learning, such guarantee entails preventing overfitting and ensuring robustness of models against corruption of input data. In order to maximize stability, we analyze and develop a computationally efficient implementation of Jacobian regularization that increases classification margins of neural networks. The stabilizing effect of the Jacobian regularizer leads to significant improvements in robustness, as measured against both random and adversarial input perturbations, without severely degrading generalization properties on clean data.