 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with Sequence Models through Iterative Energy Minimization
Mar 28, 2023Recent works have shown that sequence modeling can be effectively used to train reinforcement learning (RL) policies. However, the success of applying existing sequence models to planning, in which we wish to obtain a trajectory of actions to reach some goal, is less straightforward. The typical autoregressive generation procedures of sequence models preclude sequential refinement of earlier steps, which limits the effectiveness of a predicted plan. In this paper, we suggest an approach towards integrating planning with sequence models based on the idea of iterative energy minimization, and illustrate how such a procedure leads to improved RL performance across different tasks. We train a masked language model to capture an implicit energy function over trajectories of actions, and formulate planning as finding a trajectory of actions with minimum energy. We illustrate how this procedure enables improved performance over recent approaches across BabyAI and Atari environments. We further demonstrate unique benefits of our iterative optimization procedure, involving new task generalization, test-time constraints adaptation, and the ability to compose plans together. Project website: https://hychen-naza.github.io/projects/LEAP
Is Conditional Generative Modeling all you need for Decision-Making?
Dec 07, 2022



Recent improvements in conditional generative modeling have made it possible to generate high-quality images from language descriptions alone. We investigate whether these methods can directly address the problem of sequential decision-making. We view decision-making not through the lens of reinforcement learning (RL), but rather through conditional generative modeling. To our surprise, we find that our formulation leads to policies that can outperform existing offline RL approaches across standard benchmarks. By modeling a policy as a return-conditional diffusion model, we illustrate how we may circumvent the need for dynamic programming and subsequently eliminate many of the complexities that come with traditional offline RL. We further demonstrate the advantages of modeling policies as conditional diffusion models by considering two other conditioning variables: constraints and skills. Conditioning on a single constraint or skill during training leads to behaviors at test-time that can satisfy several constraints together or demonstrate a composition of skills. Our results illustrate that conditional generative modeling is a powerful tool for decision-making.
Discovering Generalizable Spatial Goal Representations via Graph-based Active Reward Learning
Nov 24, 2022In this work, we consider one-shot imitation learning for object rearrangement tasks, where an AI agent needs to watch a single expert demonstration and learn to perform the same task in different environments. To achieve a strong generalization, the AI agent must infer the spatial goal specification for the task. However, there can be multiple goal specifications that fit the given demonstration. To address this, we propose a reward learning approach, Graph-based Equivalence Mappings (GEM), that can discover spatial goal representations that are aligned with the intended goal specification, enabling successful generalization in unseen environments. Specifically, GEM represents a spatial goal specification by a reward function conditioned on i) a graph indicating important spatial relationships between objects and ii) state equivalence mappings for each edge in the graph indicating invariant properties of the corresponding relationship. GEM combines inverse reinforcement learning and active reward learning to efficiently improve the reward function by utilizing the graph structure and domain randomization enabled by the equivalence mappings. We conducted experiments with simulated oracles and with human subjects. The results show that GEM can drastically improve the generalizability of the learned goal representations over strong baselines.
Designing Perceptual Puzzles by Differentiating Probabilistic Programs
Apr 26, 2022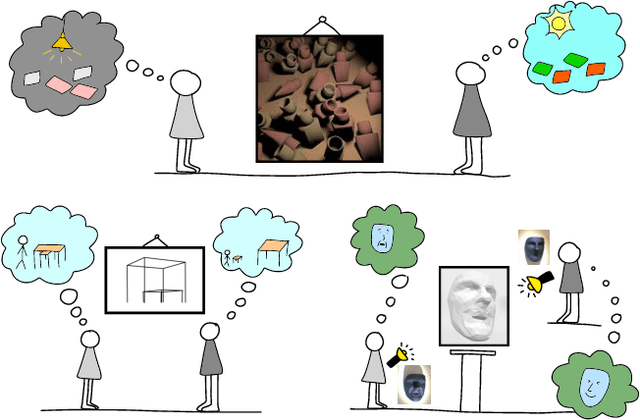

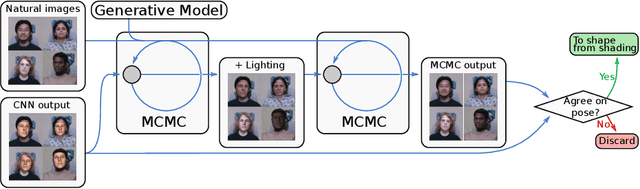
We design new visual illusions by finding "adversarial examples" for principled models of human perception -- specifically, for probabilistic models, which treat vision as Bayesian inference. To perform this search efficiently, we design a differentiable probabilistic programming language, whose API exposes MCMC inference as a first-class differentiable function. We demonstrate our method by automatically creating illusions for three features of human vision: color constancy, size constancy, and face perception.
Inventing Relational State and Action Abstractions for Effective and Efficient Bilevel Planning
Mar 17, 2022

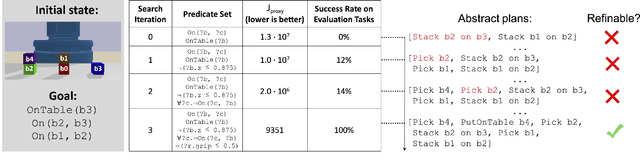

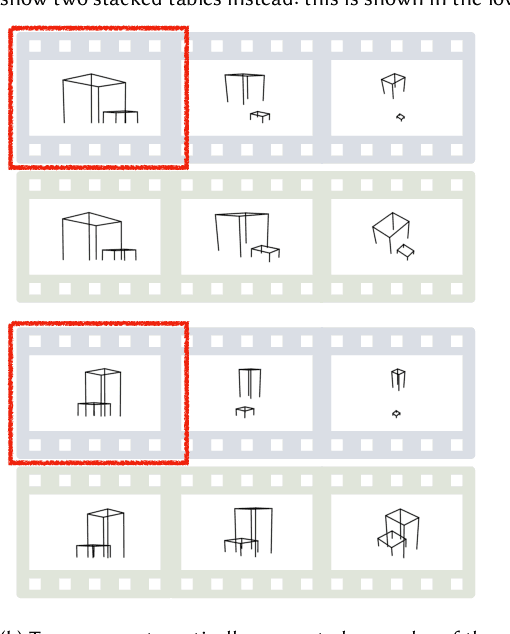
Effective and efficient planning in continuous state and action spaces is fundamentally hard, even when the transition model is deterministic and known. One way to alleviate this challenge is to perform bilevel planning with abstractions, where a high-level search for abstract plans is used to guide planning in the original transition space. In this paper, we develop a novel framework for learning state and action abstractions that are explicitly optimized for both effective (successful) and efficient (fast) bilevel planning. Given demonstrations of tasks in an environment, our data-efficient approach learns relational, neuro-symbolic abstractions that generalize over object identities and numbers. The symbolic components resemble the STRIPS predicates and operators found in AI planning, and the neural components refine the abstractions into actions that can be executed in the environment. Experimentally, we show across four robotic planning environments that our learned abstractions are able to quickly solve held-out tasks of longer horizons than were seen in the demonstrations, and can even outperform the efficiency of abstractions that we manually specified. We also find that as the planner configuration varies, the learned abstractions adapt accordingly, indicating that our abstraction learning method is both "task-aware" and "planner-aware." Code: https://tinyurl.com/predicators-release
Building 3D Generative Models from Minimal Data
Mar 04, 2022

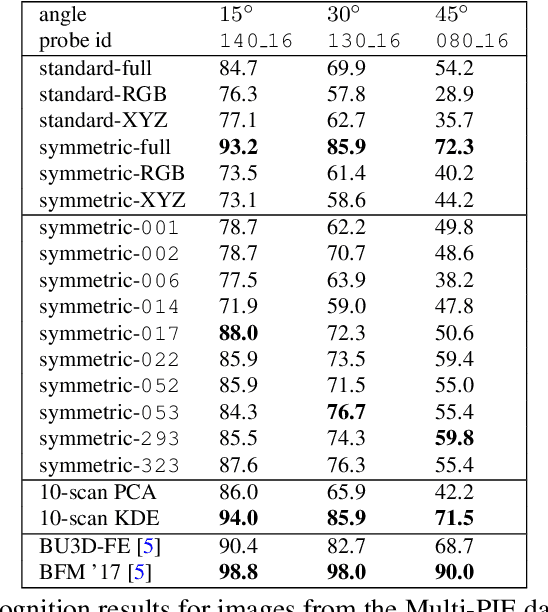
We propose a method for constructing generative models of 3D objects from a single 3D mesh and improving them through unsupervised low-shot learning from 2D images. Our method produces a 3D morphable model that represents shape and albedo in terms of Gaussian processes. Whereas previous approaches have typically built 3D morphable models from multiple high-quality 3D scans through principal component analysis, we build 3D morphable models from a single scan or template. As we demonstrate in the face domain, these models can be used to infer 3D reconstructions from 2D data (inverse graphics) or 3D data (registration). Specifically, we show that our approach can be used to perform face recognition using only a single 3D template (one scan total, not one per person). We extend our model to a preliminary unsupervised learning framework that enables the learning of the distribution of 3D faces using one 3D template and a small number of 2D images. This approach could also provide a model for the origins of face perception in human infants, who appear to start with an innate face template and subsequently develop a flexible system for perceiving the 3D structure of any novel face from experience with only 2D images of a relatively small number of familiar faces.
When Is It Acceptable to Break the Rules? Knowledge Representation of Moral Judgement Based on Empirical Data
Jan 19, 2022One of the most remarkable things about the human moral mind is its flexibility. We can make moral judgments about cases we have never seen before. We can decide that pre-established rules should be broken. We can invent novel rules on the fly. Capturing this flexibility is one of the central challenges in developing AI systems that can interpret and produce human-like moral judgment. This paper details the results of a study of real-world decision makers who judge whether it is acceptable to break a well-established norm: ``no cutting in line.'' We gather data on how human participants judge the acceptability of line-cutting in a range of scenarios. Then, in order to effectively embed these reasoning capabilities into a machine, we propose a method for modeling them using a preference-based structure, which captures a novel modification to standard ``dual process'' theories of moral judgment.
Noether Networks: Meta-Learning Useful Conserved Quantities
Dec 06, 2021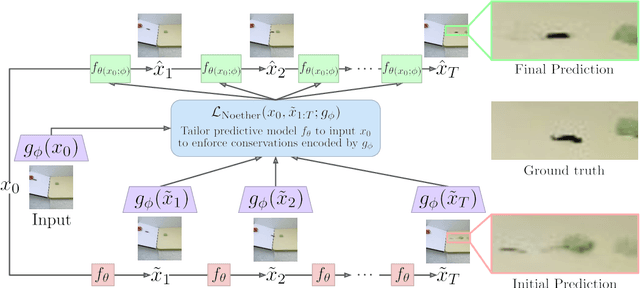
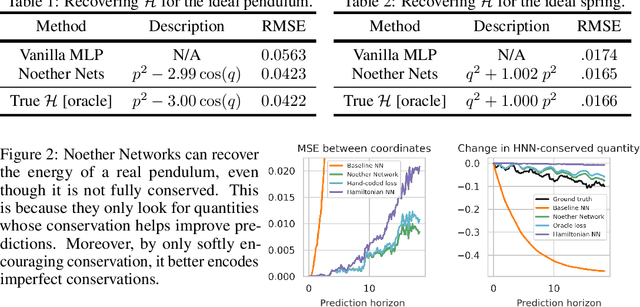
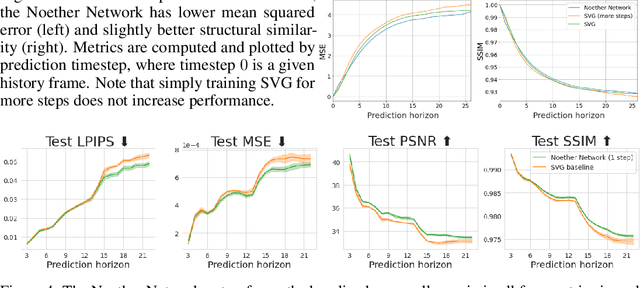

Progress in machine learning (ML) stems from a combination of data availability, computational resources, and an appropriate encoding of inductive biases. Useful biases often exploit symmetries in the prediction problem, such as convolutional networks relying on translation equivariance. Automatically discovering these useful symmetries holds the potential to greatly improve the performance of ML systems, but still remains a challenge. In this work, we focus on sequential prediction problems and take inspiration from Noether's theorem to reduce the problem of finding inductive biases to meta-learning useful conserved quantities. We propose Noether Networks: a new type of architecture where a meta-learned conservation loss is optimized inside the prediction function. We show, theoretically and experimentally, that Noether Networks improve prediction quality, providing a general framework for discovering inductive biases in sequential problems.
Identity-Expression Ambiguity in 3D Morphable Face Models
Sep 29, 2021

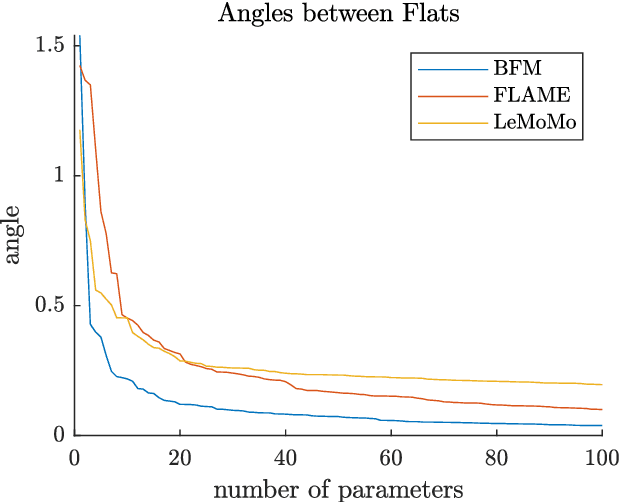
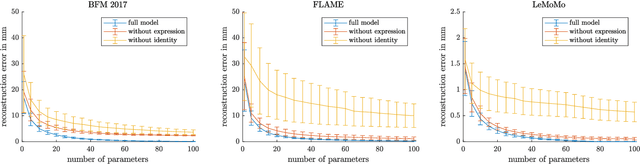
3D Morphable Models are a class of generative models commonly used to model faces. They are typically applied to ill-posed problems such as 3D reconstruction from 2D data. Several ambiguities in this problem's image formation process have been studied explicitly. We demonstrate that non-orthogonality of the variation in identity and expression can cause identity-expression ambiguity in 3D Morphable Models, and that in practice expression and identity are far from orthogonal and can explain each other surprisingly well. Whilst previously reported ambiguities only arise in an inverse rendering setting, identity-expression ambiguity emerges in the 3D shape generation process itself. We demonstrate this effect with 3D shapes directly as well as through an inverse rendering task, and use two popular models built from high quality 3D scans as well as a model built from a large collection of 2D images and videos. We explore this issue's implications for inverse rendering and observe that it cannot be resolved by a purely statistical prior on identity and expression deformations.
Probabilistic Programming Bots in Intuitive Physics Game Play
Apr 05, 2021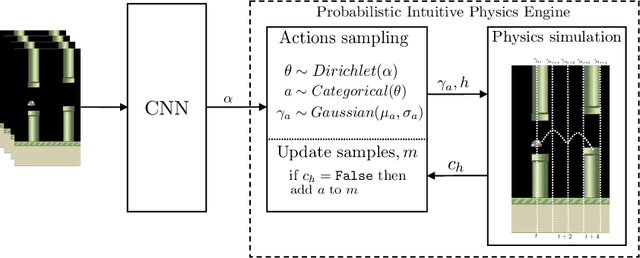
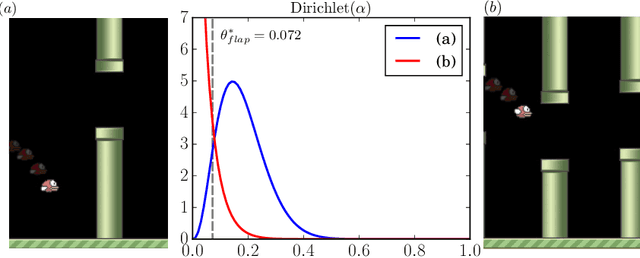
Recent findings suggest that humans deploy cognitive mechanism of physics simulation engines to simulate the physics of objects. We propose a framework for bots to deploy probabilistic programming tools for interacting with intuitive physics environments. The framework employs a physics simulation in a probabilistic way to infer about moves performed by an agent in a setting governed by Newtonian laws of motion. However, methods of probabilistic programs can be slow in such setting due to their need to generate many samples. We complement the model with a model-free approach to aid the sampling procedures in becoming more efficient through learning from experience during game playing. We present an approach where combining model-free approaches (a convolutional neural network in our model) and model-based approaches (probabilistic physics simulation) is able to achieve what neither could alone. This way the model outperforms an all model-free or all model-based approach. We discuss a case study showing empirical results of the performance of the model on the game of Flappy Bird.