 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRareAct: A video dataset of unusual interactions
Aug 03, 2020


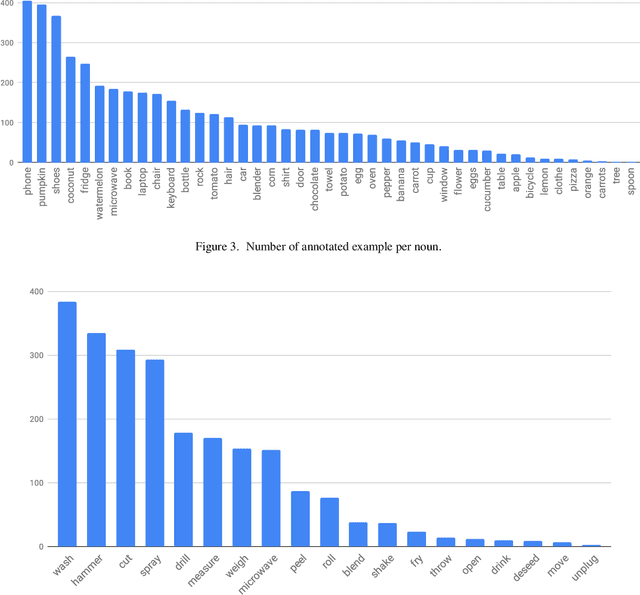
This paper introduces a manually annotated video dataset of unusual actions, namely RareAct, including actions such as "blend phone", "cut keyboard" and "microwave shoes". RareAct aims at evaluating the zero-shot and few-shot compositionality of action recognition models for unlikely compositions of common action verbs and object nouns. It contains 122 different actions which were obtained by combining verbs and nouns rarely co-occurring together in the large-scale textual corpus from HowTo100M, but that frequently appear separately. We provide benchmarks using a state-of-the-art HowTo100M pretrained video and text model and show that zero-shot and few-shot compositionality of actions remains a challenging and unsolved task.
Occlusion resistant learning of intuitive physics from videos
Apr 30, 2020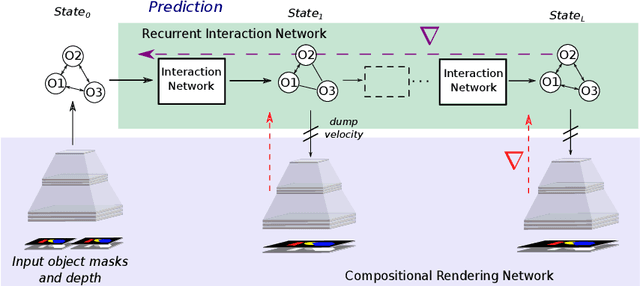
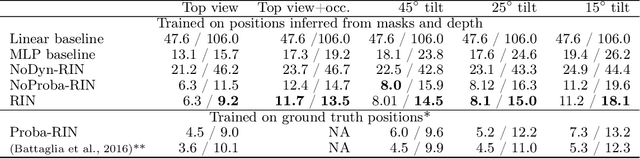


To reach human performance on complex tasks, a key ability for artificial systems is to understand physical interactions between objects, and predict future outcomes of a situation. This ability, often referred to as intuitive physics, has recently received attention and several methods were proposed to learn these physical rules from video sequences. Yet, most of these methods are restricted to the case where no, or only limited, occlusions occur. In this work we propose a probabilistic formulation of learning intuitive physics in 3D scenes with significant inter-object occlusions. In our formulation, object positions are modeled as latent variables enabling the reconstruction of the scene. We then propose a series of approximations that make this problem tractable. Object proposals are linked across frames using a combination of a recurrent interaction network, modeling the physics in object space, and a compositional renderer, modeling the way in which objects project onto pixel space. We demonstrate significant improvements over state-of-the-art in the intuitive physics benchmark of IntPhys. We apply our method to a second dataset with increasing levels of occlusions, showing it realistically predicts segmentation masks up to 30 frames in the future. Finally, we also show results on predicting motion of objects in real videos.
Efficient Neighbourhood Consensus Networks via Submanifold Sparse Convolutions
Apr 22, 2020
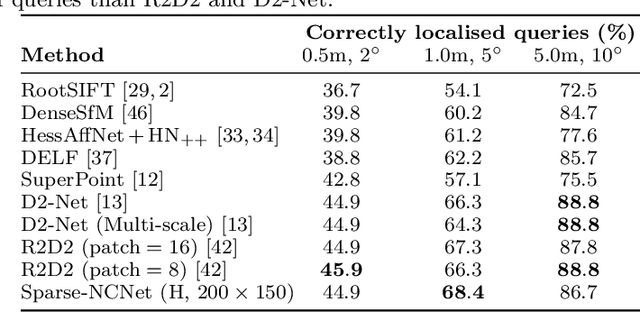
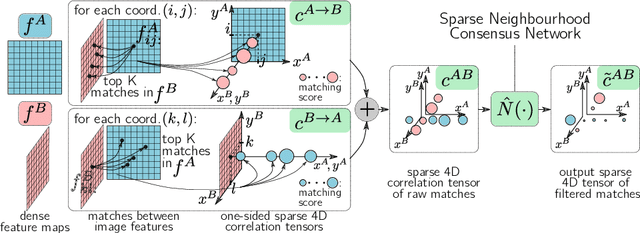
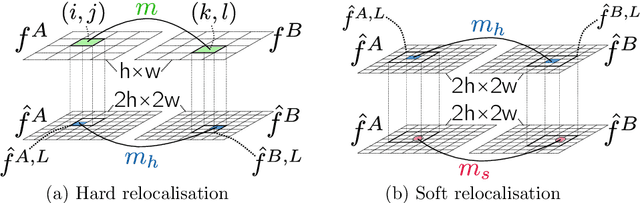
In this work we target the problem of estimating accurately localised correspondences between a pair of images. We adopt the recent Neighbourhood Consensus Networks that have demonstrated promising performance for difficult correspondence problems and propose modifications to overcome their main limitations: large memory consumption, large inference time and poorly localised correspondences. Our proposed modifications can reduce the memory footprint and execution time more than $10\times$, with equivalent results. This is achieved by sparsifying the correlation tensor containing tentative matches, and its subsequent processing with a 4D CNN using submanifold sparse convolutions. Localisation accuracy is significantly improved by processing the input images in higher resolution, which is possible due to the reduced memory footprint, and by a novel two-stage correspondence relocalisation module. The proposed Sparse-NCNet method obtains state-of-the-art results on the HPatches Sequences and InLoc visual localisation benchmarks, and competitive results in the Aachen Day-Night benchmark.
End-to-End Learning of Visual Representations from Uncurated Instructional Videos
Jan 17, 2020

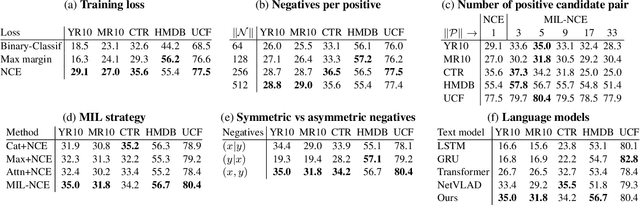
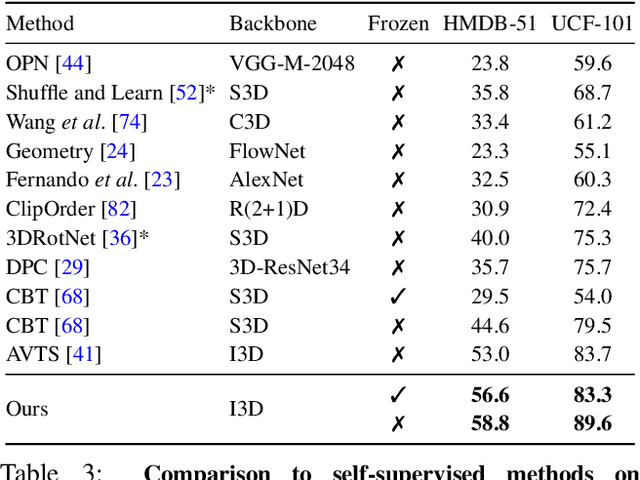
Annotating videos is cumbersome, expensive and not scalable. Yet, many strong video models still rely on manually annotated data. With the recent introduction of the HowTo100M dataset, narrated videos now offer the possibility of learning video representations without manual supervision. In this work we propose a new learning approach, MIL-NCE, capable of addressing misalignments inherent to narrated videos. With this approach we are able to learn strong video representations from scratch, without the need for any manual annotation. We evaluate our representations on a wide range of four downstream tasks over eight datasets: action recognition (HMDB-51, UCF-101, Kinetics-700), text-to-video retrieval (YouCook2, MSR-VTT), action localization (YouTube-8M Segments, CrossTask) and action segmentation (COIN). Our method outperforms all published self-supervised approaches for these tasks as well as several fully supervised baselines.
Evolving Structures in Complex Systems
Nov 04, 2019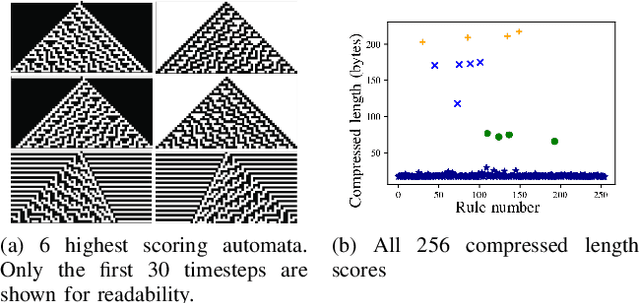



In this paper we propose an approach for measuring growth of complexity of emerging patterns in complex systems such as cellular automata. We discuss several ways how a metric for measuring the complexity growth can be defined. This includes approaches based on compression algorithms and artificial neural networks. We believe such a metric can be useful for designing systems that could exhibit open-ended evolution, which itself might be a prerequisite for development of general artificial intelligence. We conduct experiments on 1D and 2D grid worlds and demonstrate that using the proposed metric we can automatically construct computational models with emerging properties similar to those found in the Conway's Game of Life, as well as many other emergent phenomena. Interestingly, some of the patterns we observe resemble forms of artificial life. Our metric of structural complexity growth can be applied to a wide range of complex systems, as it is not limited to cellular automata.
* IEEE Symposium Series on Computational Intelligence 2019 (IEEE SSCI 2019)
Is This The Right Place? Geometric-Semantic Pose Verification for Indoor Visual Localization
Sep 02, 2019
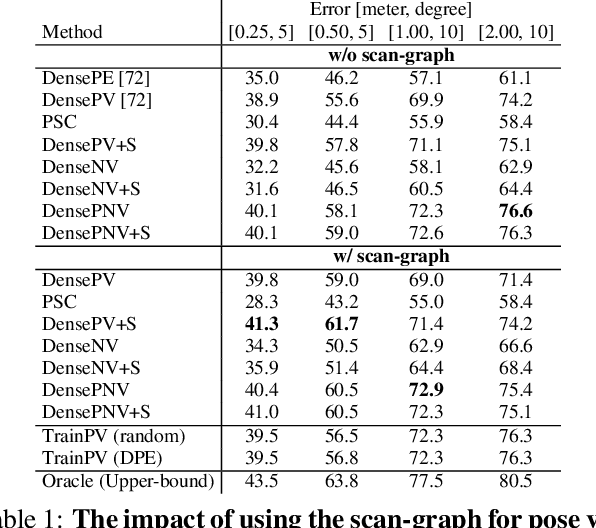
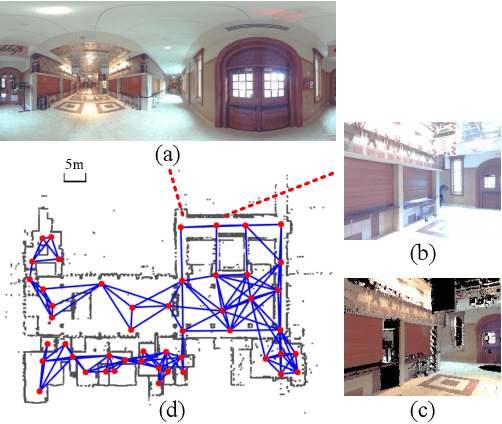
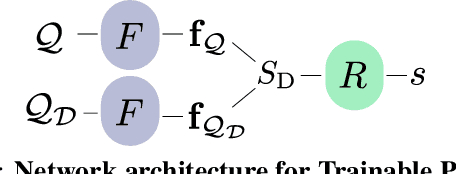
Visual localization in large and complex indoor scenes, dominated by weakly textured rooms and repeating geometric patterns, is a challenging problem with high practical relevance for applications such as Augmented Reality and robotics. To handle the ambiguities arising in this scenario, a common strategy is, first, to generate multiple estimates for the camera pose from which a given query image was taken. The pose with the largest geometric consistency with the query image, e.g., in the form of an inlier count, is then selected in a second stage. While a significant amount of research has concentrated on the first stage, there is considerably less work on the second stage. In this paper, we thus focus on pose verification. We show that combining different modalities, namely appearance, geometry, and semantics, considerably boosts pose verification and consequently pose accuracy. We develop multiple hand-crafted as well as a trainable approach to join into the geometric-semantic verification and show significant improvements over state-of-the-art on a very challenging indoor dataset.
Combining learned skills and reinforcement learning for robotic manipulations
Aug 02, 2019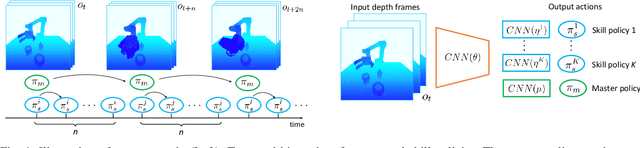

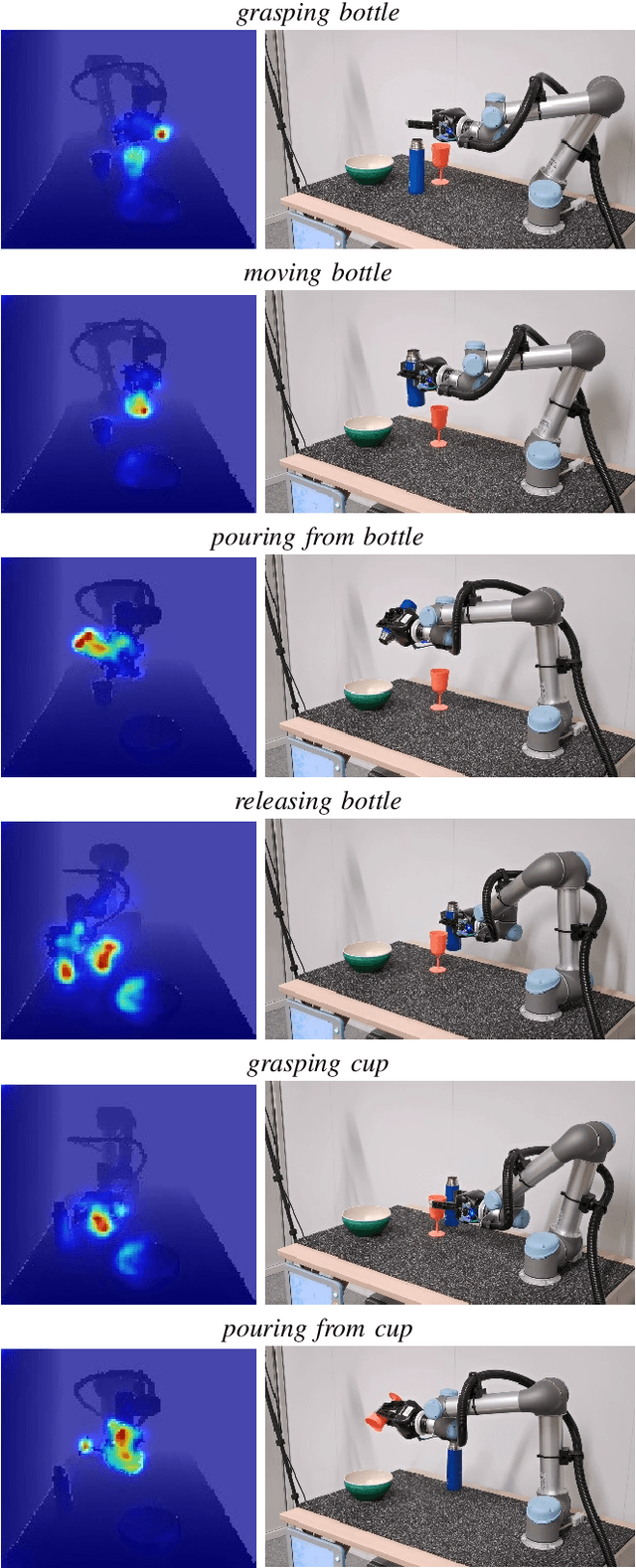

Manipulation tasks such as preparing a meal or assembling furniture remain highly challenging for robotics and vision. The supervised approach of imitation learning can handle short tasks but suffers from compounding errors and the need of many demonstrations for longer and more complex tasks. Reinforcement learning (RL) can find solutions beyond demonstrations but requires tedious and task-specific reward engineering for multi-step problems. In this work we address the difficulties of both methods and explore their combination. To this end, we propose a RL policies operating on pre-trained skills, that can learn composite manipulations using no intermediate rewards and no demonstrations of full tasks. We also propose an efficient training of basic skills from few synthetic demonstrated trajectories by exploring recent CNN architectures and data augmentation. We show successful learning of policies for composite manipulation tasks such as making a simple breakfast. Notably, our method achieves high success rates on a real robot, while using synthetic training data only.
HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips
Jul 31, 2019
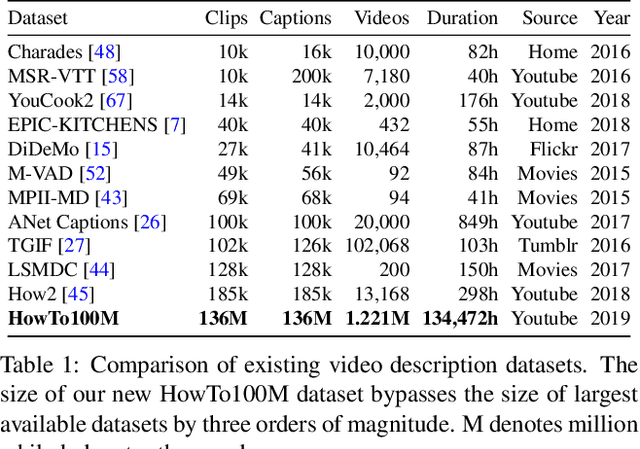

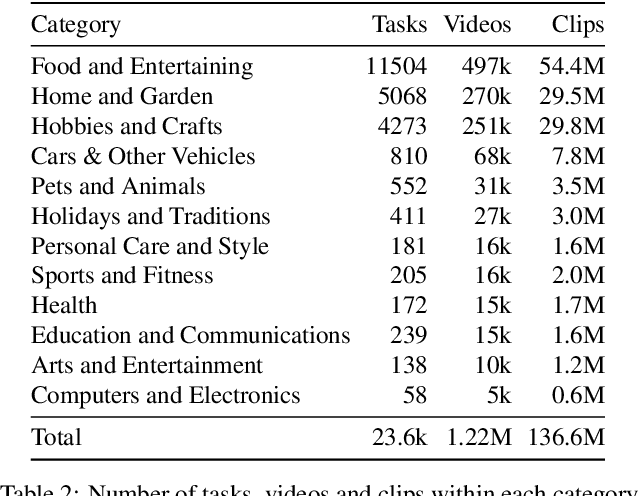
Learning text-video embeddings usually requires a dataset of video clips with manually provided captions. However, such datasets are expensive and time consuming to create and therefore difficult to obtain on a large scale. In this work, we propose instead to learn such embeddings from video data with readily available natural language annotations in the form of automatically transcribed narrations. The contributions of this work are three-fold. First, we introduce HowTo100M: a large-scale dataset of 136 million video clips sourced from 1.22M narrated instructional web videos depicting humans performing and describing over 23k different visual tasks. Our data collection procedure is fast, scalable and does not require any additional manual annotation. Second, we demonstrate that a text-video embedding trained on this data leads to state-of-the-art results for text-to-video retrieval and action localization on instructional video datasets such as YouCook2 or CrossTask. Finally, we show that this embedding transfers well to other domains: fine-tuning on generic Youtube videos (MSR-VTT dataset) and movies (LSMDC dataset) outperforms models trained on these datasets alone. Our dataset, code and models will be publicly available at: www.di.ens.fr/willow/research/howto100m/.
Temporal Localization of Moments in Video Collections with Natural Language
Jul 30, 2019

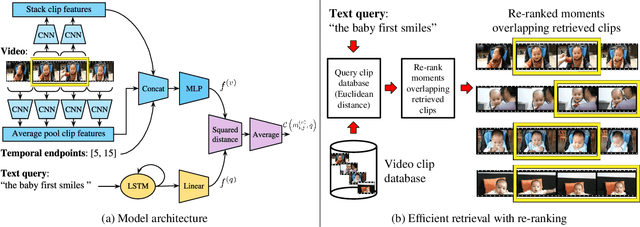
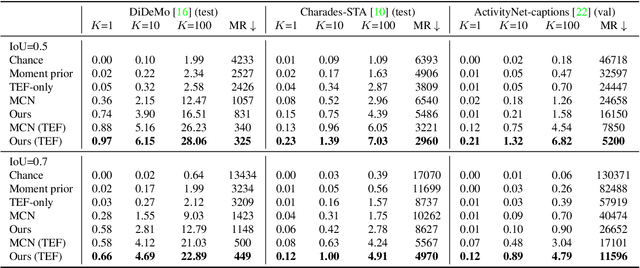
In this paper, we introduce the task of retrieving relevant video moments from a large corpus of untrimmed, unsegmented videos given a natural language query. Our task poses unique challenges as a system must efficiently identify both the relevant videos and localize the relevant moments in the videos. This task is in contrast to prior work that localizes relevant moments in a single video or searches a large collection of already-segmented videos. For our task, we introduce Clip Alignment with Language (CAL), a model that aligns features for a natural language query to a sequence of short video clips that compose a candidate moment in a video. Our approach goes beyond prior work that aggregates video features over a candidate moment by allowing for finer clip alignment. Moreover, our approach is amenable to efficient indexing of the resulting clip-level representations, which makes it suitable for moment localization in large video collections. We evaluate our approach on three recently proposed datasets for temporal localization of moments in video with natural language extended to our video corpus moment retrieval setting: DiDeMo, Charades-STA, and ActivityNet-captions. We show that our CAL model outperforms the recently proposed Moment Context Network (MCN) on all criteria across all datasets on our proposed task, obtaining an 8%-85% and 11%-47% boost for average recall and median rank, respectively, and achieves 5x faster retrieval and 8x smaller index size with a 500K video corpus.
D2-Net: A Trainable CNN for Joint Detection and Description of Local Features
May 09, 2019
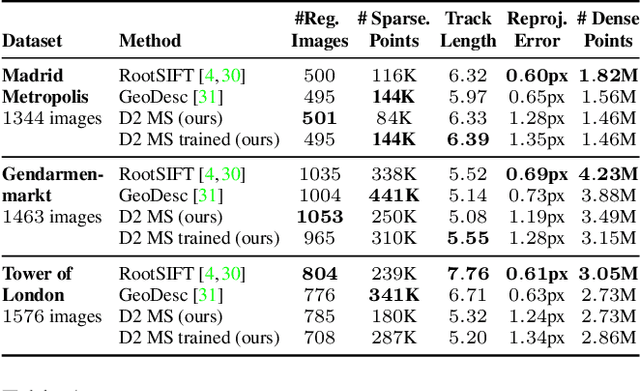
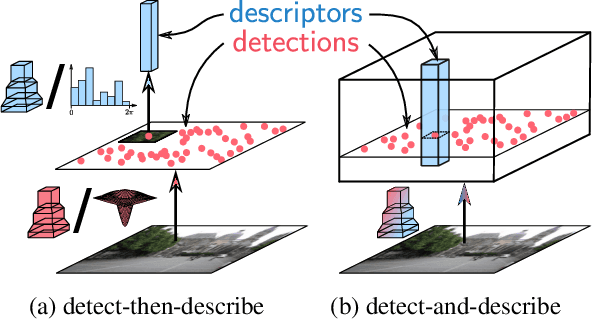
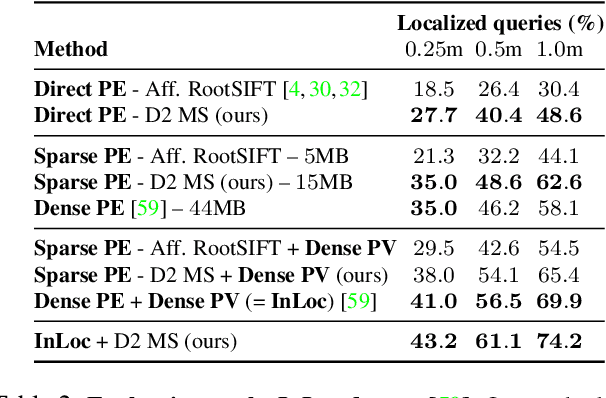
In this work we address the problem of finding reliable pixel-level correspondences under difficult imaging conditions. We propose an approach where a single convolutional neural network plays a dual role: It is simultaneously a dense feature descriptor and a feature detector. By postponing the detection to a later stage, the obtained keypoints are more stable than their traditional counterparts based on early detection of low-level structures. We show that this model can be trained using pixel correspondences extracted from readily available large-scale SfM reconstructions, without any further annotations. The proposed method obtains state-of-the-art performance on both the difficult Aachen Day-Night localization dataset and the InLoc indoor localization benchmark, as well as competitive performance on other benchmarks for image matching and 3D reconstruction.